Lvl2: Quantitative Methods
1/59
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
60 Terms
Dependent variable is continuous vs discrete
Continuous: the traditional regression model
Discrete: logistic regression
Regression Process
Analyze the residuals
Examine the goodness of fit - significance of fit
Assumptions in a simple regression
Linearity - Dependent & independent
Homoskedasticity - same variance of regression residuals
Independence of errors - observations are independent; regression residuals are uncorrelated
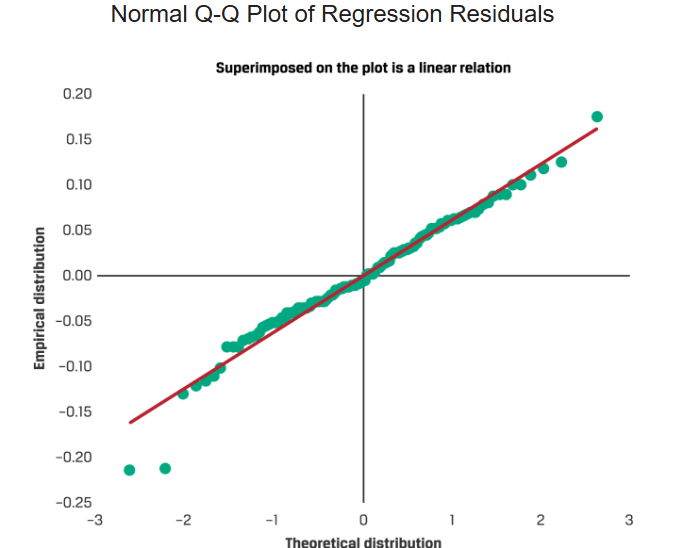
Normality - regression residuals normal distribution
Independence of independent variables - not random; no linear relation between ind variables
normal Q-Q plot
visualize the distribution of a variable (regression residual) by comparing it to a normal distribution
coefficient of determination (R-squared)
ratio of the variation of the dependent variable explained by the independent variables (sum of squares regression) to the total variation of the dependent variable (sum of squares total)
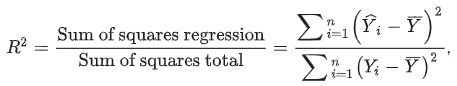
Disadvantages of R-squared
cannot provide information on whether the coefficients are statistically significant
biases in the estimated coefficients and predictions
cannot tell whether the model fit is good - bad model may have a high R2 due to overfitting and biases in the model
overfitting
model is too complex - too many independent variables relative to the number of observations in the sample
adjusted R-squared
does not automatically increase when another independent variable is added to a regression
R2 is strictly greater than adjusted R2
adjusted R2 may be negative, whereas the R2 has a minimum of zero
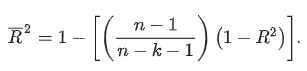
Akaike’s information criterion (AIC)
lower AIC indicates a better-fitting model
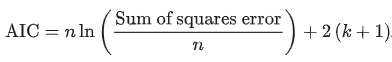
Schwarz’s Bayesian information criterion (BIC)
BIC assesses a greater penalty for having more parameters in a model
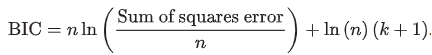
AIC vs BIC
AIC is preferred if the model is used for prediction purposes
BIC is preferred when the best goodness of fit is desired
Test whether a variable is significant in explaining the dependent variable’s variation
H0: bj = 0 and Ha: bj ≠ 0
F-distributed test statistic
q is the number of restrictions
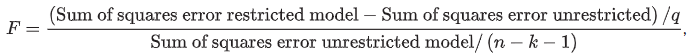
How to test for significance
Define hypothesis
Find critical value
Reject the null if calculated statistic exceeds critical value
If fail to reject the null i.e. null is correct
general linear F-test
test the null hypothesis that slope coefficients on all variables are equal to zero
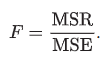
Omitted variable bias
omission of an important independent variable
If the omitted variable is uncorrelated with X1, the coefficient for X1 will still be estimated correctly
Misspecified Regression
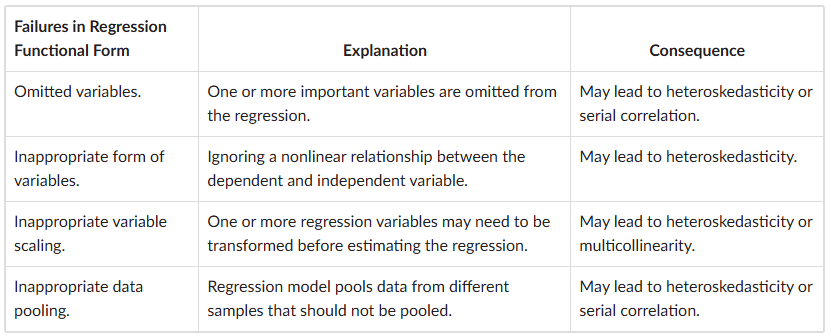
Unconditional heteroskedasticity
error variance is not correlated with the regression’s independent variables - no major problems for statistical inference
Conditional heteroskedasticity
error variance is correlated with (conditional on) the values of the independent variables
t-statistics will be inflated
tend to find significant relationships where none actually exist
more Type I errors (rejecting the null hypothesis when it is actually true)
Breusch-Pagan (BP) test
test for conditional heteroskedasticity
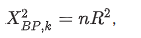
heteroskedasticity-consistent standard errors
robust standard errors
adjust the standard errors of the regression’s estimated coefficients to account for the heteroskedasticity
serial correlation or autocorrelation
regression errors are correlated across observations
incorrect estimate of the regression coefficients’ standard errors
no adjustment required if none of the regressors is a lagged value of the dependent variable
more Type I errors
positive vs negative serial correlation
positive residual for one observation increases the chance of a positive residual in a subsequent observation
a positive residual for one observation increases the chance of a negative residual for another observation
Durbin-Watson (DW) test
measure of autocorrelation
compares the squared differences of successive residuals with the sum of the squared residuals
applies only to testing for first-order serial correlation
ranges from 0 to 4 (~2 = no autocorrelation, < 2 positive. >2 negative)
Breusch-Godfrey (BG) test
can detect autocorrelation up to a pre-designated order p, where the error in period t is correlated with the error in period t – p
n – p – k – 1 and p degrees of freedom, where p is the number of lags
serial -correlation consistent standard errors
adjust the coefficient standard errors to account for the serial correlation
multicollinearity
when two or more independent variables are highly correlated or when there is an approximate linear relationship among independent variables
impossible to distinguish the individual impacts of the independent variables
diminished t-statistics, so t-tests of coefficients have little power (ability to reject the null hypothesis)
Variance inflation factor (VIF)
VIFj > 5 warrants further investigation of the given independent variable
VIFj >10 indicates serious multicollinearity requiring correction
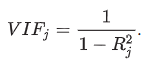
correct for multicollinearity
excluding one or more of the regression variables
using a different proxy for one of the variables
increasing the sample size
influential observation
an observation whose inclusion may significantly alter regression results
high-leverage point
data point having an extreme value of an independent variable
outlier data point
data point having an extreme value of the dependent variable
leverage (hii) - detecting high-leverage point
distance between the value of the ith observation of that independent variable and the mean value of that variable across all n observations
value between 0 and 1
if an observation’s leverage exceeds
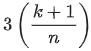
studentized residuals - detecting outliers
compared to the critical value of the t-distributed statistic with (n − k − 2) degrees of freedom
|ti*| > 3 - outlier
|ti*| > critical value of t-statistic - potentially influential
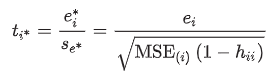
dummy variable
takes on a value of 1 if a particular condition is true and 0 if that condition is false
to distinguish among n categories, we need n − 1 dummy variables - the category not assigned becomes the “base” or “control” group
Logistic regression (logit)
The natural logarithm (ln) of the odds of an event happening
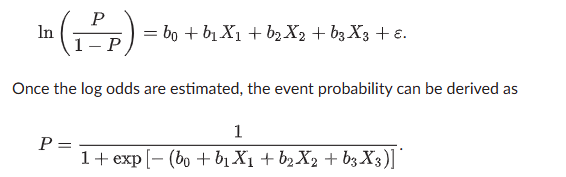
maximum likelihood estimation (MLE) method
estimates logistic regression coefficients
a chi-square-distributed test statistic
likelihood ratio (LR) test
to assess the fit of logistic regression models
LR = −2 × (Log-likelihood restricted model − Log-likelihood unrestricted model)
chi-squared with q degrees of freedom
log-likelihood metric is always negative, so higher values (closer to 0) indicate a better-fitting model
Problems with a time series
serial correlation in the error term causes estimates of the intercept (b0) and slope coefficient (b1) to be inconsistent - independent variable is a lagged variable of the dependent
The mean or variance of the time series changes over time
log-linear model
ln yt = b0 + b1t + εt, t = 1, 2, . . . , T.
Covariance-Stationary
properties, such as mean and variance, do not change over time
the expected value of the time series must be constant and finite in all periods
variance of the time series must be constant and finite in all periods
covariance of the time series with itself for a fixed number of periods in the past or future must be constant and finite in all periods
standard error of the residual correlation
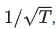
mean-reverting level
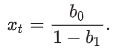
root mean squared error (RMSE)
compare the out-of-sample forecasting performance
square root of the average squared error
smallest RMSE is judged the most accurate
random walk
value of the series in one period is the value of the series in the previous period plus an unpredictable random error
error term, εt, has constant variance and is uncorrelated with the error term in previous periods
b0 = 0 and b1 = 1
the expected value of εt is zero
best forecast of xt that can be made in period t − 1 is xt−1
currency exchange rates
undefined mean-reverting level
for any period t, the variance of xt = (t − 1)σ2
not a covariance-stationary time series, because a covariance-stationary time series must have a finite variance
first-differencing
subtracts the value of the time series in the first prior period from the current value of the time series
mean-reverting level of the first-differenced model as b0/(1 − b1) = 0/1 = 0
variance of yt in each period is var(εt) = σ2
variance and the mean of yt are constant and finite in each period, yt is a covariance-stationary time series
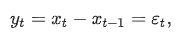
random walk with drft
random walk with drift has b0 ≠ 0, compared to a simple random walk, which has b0 = 0
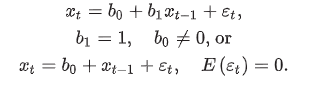
unit root
lag coefficient is equal to 1.0
all random walks, with or without a drift term, have unit roots
not covariance stationary
Dickey and Fuller test
unit root test
xt − xt−1 = b0 + (b1 − 1)xt−1 + εt —→ b0 + g1xt−1 + εt
a test of g1 = 0 is a test of b1 = 1
H0: g1 = 0; Ha: g1 < 0
n-period moving average
to remove short-term fluctuations or noise by smoothing out the time series of sales
moving average of the current and past n − 1 values
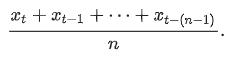
MA(1) - moving-average model of order 1
moving average of εt and εt−1
First: examine the variance of xt and its first two autocorrelations
first autocorrelation is not equal to 0, but the second and higher autocorrelations are equal to 0
MA(1) model has a memory of one period
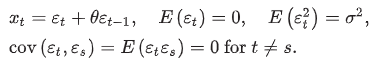
AR vs MA
autocorrelations of most autoregressive time series start large and decline gradually, whereas the autocorrelations of an MA(q) time series suddenly drop to 0 after the first q autocorrelations
autoregressive moving-average (ARMA) model
p autoregressive terms and q moving-average terms, denoted ARMA(p, q)
parameters in ARMA models can be very unstable
criteria for deciding on p and q for a particular time series are far from perfect
Autoregressive Conditional Heteroskedasticity Models (ARCH)
If the estimate of a1 is statistically significantly different from zero, we conclude that the time series is ARCH(1)
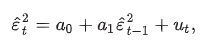
ARCH - predict variance of errors in period t+1
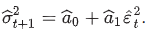
2 time series - one dependent, one independent variable
test for unit root - DF test
one of them has a unit root - not covariance stationary; one or more of linear regression assumptions violated; coefficients and standard error inconsistent; coefficient appears significant but is not
both have a unit root - establish if cointegrated
cointegrated
long-term financial or economic relationship exists between them such that they do not diverge from each other
cointegrated vs not
not; error term not covariance stationary; some regression assumptions will be violated; regression coefficients and standard errors will not be consistent, and we cannot use them for hypothesis tests
yes; error term is covariance stationary; regression coefficients and standard errors will be consistent, and we can use them for hypothesis tests; may not be the best model of the short-term relation
cointegration test
use the critical values computed by Engle and Granger
fails to reject - not cointegrated
reject - cointegrated
expected total holding period cost
trading costs = round-trip commission + bid-ask spread
management fees = fee * period