AI notes
1/78
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
79 Terms
The Precision, also called positive predicted value is computed using which equation?
Precision = TP / (TP+FP)

18
TP = 18: There are 18 current clients who provided referrals that received a free massage that were correctly classified in the model

1 − [(FP + FN) ÷ (TP + TN + FP + FN)]
1 − (14 + 14) ÷ (18 + 54 + 14 + 14) = 1 − 0.28 = 0.72
Given that the true target is 0 (or actually negative), the probability that the result is accurate (so predicting a 0) is called the:
Specificity
Feature Engineering is the art of combining multiple features to make fewer “better” features.
T or F
True
The more complicated a (non-neural network) model is, the more it tends to overfit
T or F
True
What is the Rule of Parsimony?
values simpler models over more complicated ones, assuming they explain the data equally well. So complicated models are not preferred unless necessary.
Given that there are 10 movies and 6 people, what is the maximum number of rankings?
60
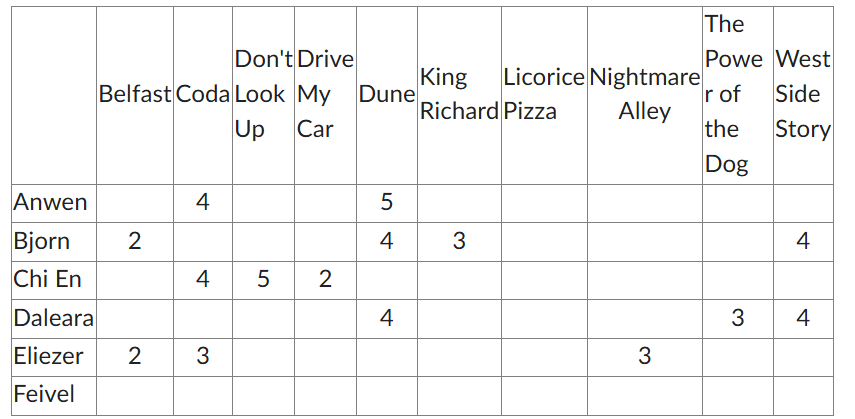
The movie recommender has a “cold start” problem with which person?
Feivel
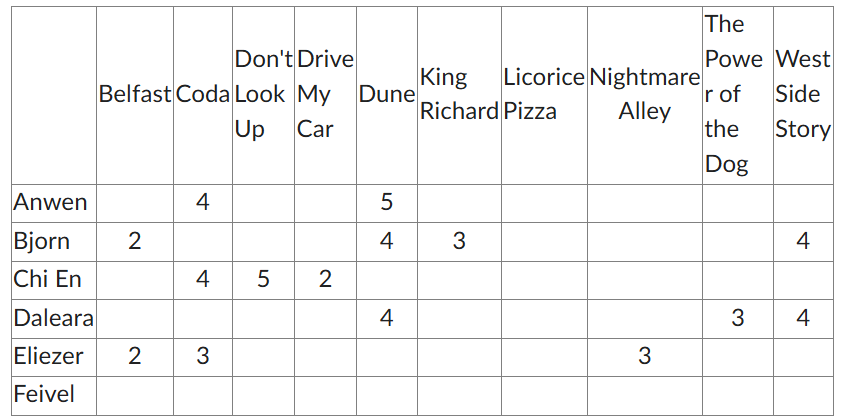
Looking at the matrix, the percentage of non-zero entries is what?
15 filled boxes / 60 total boxes
25%
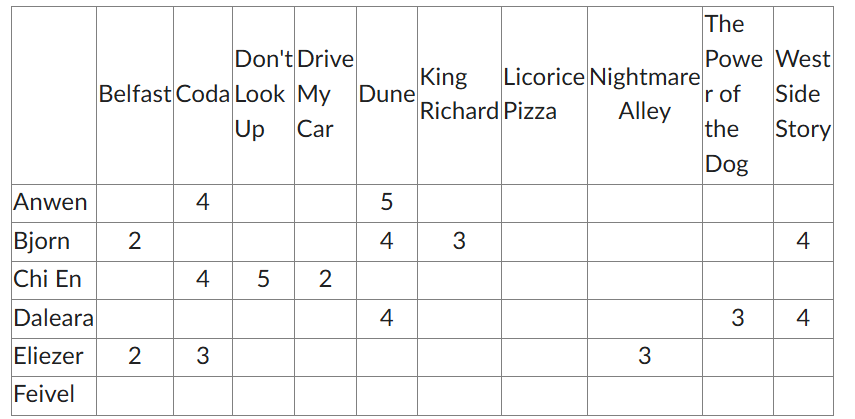
Which movie will not be recommended by any algorithm?
Licorice Pizza
Which of the following are examples of Recommendation Algorithms?
Which of the following are examples of Recommendation Algorithms?
(Select all that apply)
image recognition movie selector
Stock market prediction
Market Segmentation
phone texting auto-complete
online shopping "you may want"
Movie Selector
Phone texting auto-complete
Online shopping “you may want”
The simple linear regression model y = β0 + β1x + ɛ implies that if x ________, we expect y to change by β1, irrespective of the value of x.
goes up by one unit
In the following equation ŷ = 30,000 + 4x with given sales (γ in $500) and marketing (x in dollars), what does the equation imply?
An increase of $1 in marketing is associated with an increase of $32,000 in sales.
An increase of $1 in marketing is associated with an increase of $2,000 in sales.
An increase of $4 in marketing is associated with an increase of $2,000 in sales.
An increase of $4 in marketing is associated with an increase of $32,000 in sales.
An increase of $1 in marketing is associated with an increase of $2,000 in sales. (option 2)
30,000 + 4x; ŷ = 30,000 + 4(500). Thus, a $1 increase is a $2,000 increase in sales.
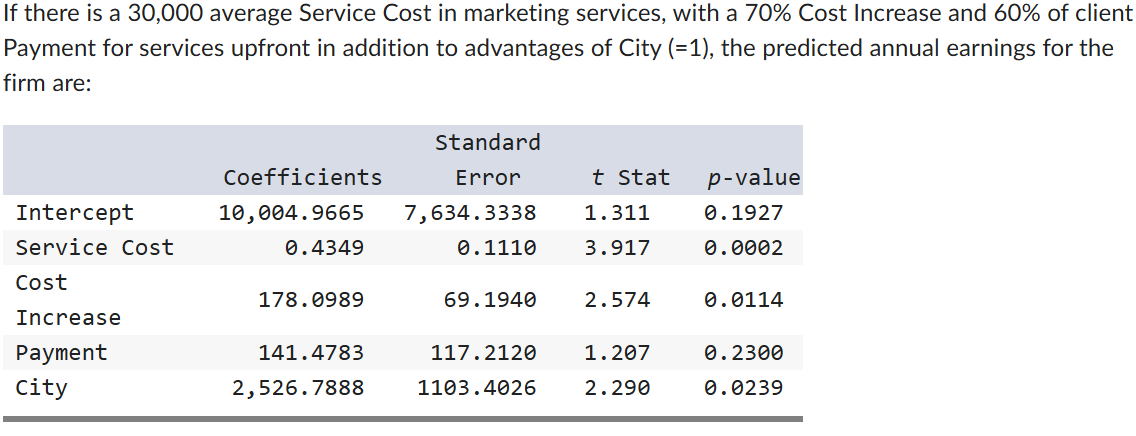
$46,534.38
10,004.9665 + 0.4349 × 30,000 + 178.0989 × 70 + 141.4783 × 60 + 2,526.7888 × 1 = 46,534.376 or $46,534.38.
Regression analysis captures the relationship between only two distinct variables
T or F?
False
Regression analysis captures the relationship between 2 or more variables
The slope coefficient β, is called:
beta
The slope coefficient β is read as beta and represents the population slope coefficient to be estimated.
Reducing the number of features used in a model by creating a newer, smaller set of features using the original features as input, is:
Feature Engineering
Reducing the number of features used in a model by dropping some of the features.
Feature Selection
Which of the following is NOT a method of reducing the number of features?
SelectKBest
Variance Threshold
PCA
KNN
KNN
Is the following an example of Feature Selection or Feature Engineering? Backwards Selection
Feature Selection
Feature Engineering
Neither
Both
Feature Selection
Backward selection starts with all features and iteratively removes the least useful one based on impact until only the most relevant features remain.
A good feature selection method is to drop features with high variance
T or F?
False
Assume we have Training Data X and new data Z
Many models are trained on different subsets of the data, then the mean of the results is used as the prediction is:
Bagging
One model is trained on the data, then the predictions are added to the data to make a new training set. Then we train a new model on that data set. Repeat. is:
Boosting
Many models are trained on the data, than the mode of the results is used as the prediction is:
voting
Anya trained four models on the NumSet number data. When she evaluated a new datapoint, her models came up with the following set of predictions.
{4, 4, 9, 7}
Using the averaging method, what is the prediction?
6
(4+4+9+7) / 4
24/4
= 6
Bootstrapping means sampling from a dataset with replacement
T or F
True
I've invented a new Boosting method for prediction on the single variable X:
First, I do linear regression. On my data, I came up with the function
Y = 3X + 7
Next, I take the result, Y, and put it into the following equation:
PREDICTION = X × Y
What is the prediction when X = 27?
3(27) + 7
= 88
88 × 27
= 2,376
I'm bootstrapping from the set:
{1, 2, 3, 4}
Is it possible to get the set {4, 4, 5}?
Bootstrapping involves sampling with replacement from the original dataset. Since the original set is {1, 2, 3, 4}, you cannot get a 5 from it — so {4, 4, 5} is not possible.
The function can be drawn without lifting up your pencil.
CONTINUOUS | |
2. | DIFFERENTIABLE |
3. | CONVEX |
Continuous
The function is always like an upside-down spoon
1. | CONTINUOUS |
2. | DIFFERENTIABLE |
3. | CONVEX |
3. CONVEX
The function has no sharp points, just smooth curves
1. | CONTINUOUS |
2. | DIFFERENTIABLE |
3. | CONVEX |
Differentiable
What is a recommendation system?
an algorithm or model that predicts items (e.g., products, movies) a user might like based on their preferences, behavior, or similarities with other users/items.
What is collaborative filtering?
Uses user-item interactions (e.g., ratings) to find patterns. It can be user-based (similar users) or item-based (similar items).
Netflix recommends movies like Stranger Things to you because you rated similar sci-fi shows highly, and other users who liked those shows also enjoyed Stranger Things (item-based collaborative filtering).
What is content-based filtering?
Recommends items based on item features (e.g., genre, description) and user preferences.
Collaborative filtering recommends items based on what similar users liked.
Content-based filtering recommends items based on similarity to what the user liked before.
What is a user-item matrix?
A matrix where rows represent items, columns represent users, and entries are ratings
What is a sparse matrix?
Most entries are zero (unrated items), making sparse representations efficient for large datasets.
How do we solve the cold start problem?
recommending top-rated items to new users with no history.
What are some ML techniques in Recommendation Systems?
KNN
Clustering
PCA
What is Random Walks?
a mathematical concept describing a path formed by a sequence of random steps in some space. Each step is independent and determined by a certain probability
On eBay, if you view a laptop, a random walk model might predict you’ll next view a laptop case, based on a transition matrix built from users’ browsing sequences (e.g., laptop → case → charger).
What is an initialization vector?
method of setting the starting weights before training begins.
What are markov chains?
models that describe systems where the next state depends only on the current state, not the past history.
When shopping on Walmart’s website, if you add milk to your cart, a Markov chain model might recommend cereal next, as it’s a common follow-up item based on recent cart additions by other users.
Markov chains model sequential user behaviour like:
clicking from one product to another
What is a vector?
A matrix with one column or row.
What is a transition matrix?
A transition matrix is a table of probabilities showing how likely it is to move from each state to every other state in a Markov Chain
What is reinforcement learning (RL)?
A type of machine learning where an agent learns by interacting with an environment, receiving rewards or penalties based on its actions.
What is the goal of a reinforcement learning agent?
To learn a policy that maximizes cumulative reward over time.
What is the difference between exploration and exploitation?
A: Exploration is trying new actions to discover their effects; exploitation is choosing known actions that yield the highest reward.
What is the role of feedback in reinforcement learning?
A: Feedback in the form of rewards or penalties helps the agent evaluate its actions and improve its policy.
What is the main goal of regression?
A: To find the best-fitting relationship between input features and a continuous target variable.
What is multicollinearity in regression?
A: When input features are highly correlated with each other, making it hard to isolate their individual effects.
Content Filtering relies only on user ratings of items.
Question 2 options:
True
False
False
Content filtering relies on item features or attributes, not just user ratings.
It's about recommending items similar to what a user liked based on the content (e.g., genre, keywords), not based on other users' preferences.
The more complicated a (non-Neural Network) model is, the more it tends to Underfit.
Question 4 options:
True
False
false
In Divisive Hierarchical Clustering, we start with every data point in a single cluster, then divide a cluster at each step.
Question 6 options:
True
False
true
A convex everywhere function has only one minima. Question 7 options:
True
False
true
In an AI context, we judge the effectiveness of our methods and data with real-world improvements in our metrics.
Question 8 options:
True
False
True
Which of the following is NOT a problem that a recommendation algorithm could solve? (Select all that apply)
Question 9 options:
What Movie to suggest
Convert handwritten notes to text.
Autofill a web form
Correct spelling in a document
handwritten notes to text
A Decision Tree is a type of Ensemble Method.
Question 11 options:
True
False
False
A Decision Tree is a single model, not an ensemble method.
Ensemble methods like Random Forest or Gradient Boosting use multiple decision trees to improve accuracy.
Bootstrapping means sampling from a dataset with replacement.
Question 12 options:
True
False
True
Given a positive result (or prediction of 1), the probability that the result is accurate (so the answer really is 1) is called the:
Question 13 options:
Sensitivity
Precision
Specificity
None of the above
precision
Since a reinforcement learning algorithm learns and grows more accurate over time, we need to worry that it will soon become a true Generalized AI
Question 14 options:
True
False
False
RainCity Umbrellas wants to make their social media ads different for different potential customers. The Machine Learning technique they would use is
Question 15 options:
Guessing
Classification
Regression
Clustering
Clustering
The K-nearest Neighbours Algorithm is an example of:
Question 16 options:
Neural Networks
Reinforcement Learning
Supervised Learning
Unsupervised Learning
supervised learning
What is the term for this:
Given that the model predicts that a customer will buy a second item and get free shipping, the probability that they will add a second item: P(Actual 1|1 predicted)
Question 22 options:
Sensitivity
Precision
Specificity
Accuracy
None of the Above
Precision
![<p>Initially, the algorithm chooses each page with equal probability. Choose the correct probability vector for option [page 21, page 144]:</p><p>Question 18 options:</p><p>Impossible to answer, given the information given.</p><p>[0.33, 0.67]</p><p>[0,1]</p><p>[0.5, 0.5]</p><p>[1,1]</p><p>[0.67, 0.33]</p>](https://knowt-user-attachments.s3.amazonaws.com/c1972fa5-d5a5-43a3-91c2-d737762b3561.png)
Initially, the algorithm chooses each page with equal probability. Choose the correct probability vector for option [page 21, page 144]:
Question 18 options:
Impossible to answer, given the information given.
[0.33, 0.67]
[0,1]
[0.5, 0.5]
[1,1]
[0.67, 0.33]
[0.5,0.5]
algorithm initially chooses each page with equal probability, and there are two options: page 21 (meet the President) or page 114 (watch the football game). Since there are only two choices and they are equally likely, the probability of choosing each page is 1/2
What is the term for this:
Given that a customer will buy a second item and get free shipping, the probability that the algorithm correctly predicts: P(Predicted 1|1 actual)
Question 24 options:
Sensitivity
Precision
Specificity
Accuracy
None of the Above
Sensitivity
It measures how well the model identifies actual positives — in this case, how often the algorithm correctly predicts when a customer will buy a second item
Put the following process in order:
Question 29 options:
Explore the Data through visualizing and summarizing
the data, by scaling or creating dummy variables
Choose the best model
Train your model on the full training set – no Cross Validation
Clean the Data
Test your model on the Test Data
Test different algorithms, with different hyperparameters, using Cross Validation
Test/Train/split, and segregate your test data
Clean the Data
Explore the Data through visualizing and summarizing
Preprocess the data, by scaling or creating dummy variables
Test/Train/split, and segregate your test data
Test different algorithms, with different hyperparameters, using Cross Validation
Choose the best model
Train your model on the full training set – no Cross Validation
Test your model on the Test
Im bootstrapping from the set: {1, 2, 3, 4} Is it possible to get the set {4, 4, 3}?
True
False
True
What is P(Actual 1 | Predicted 1) ?
precision
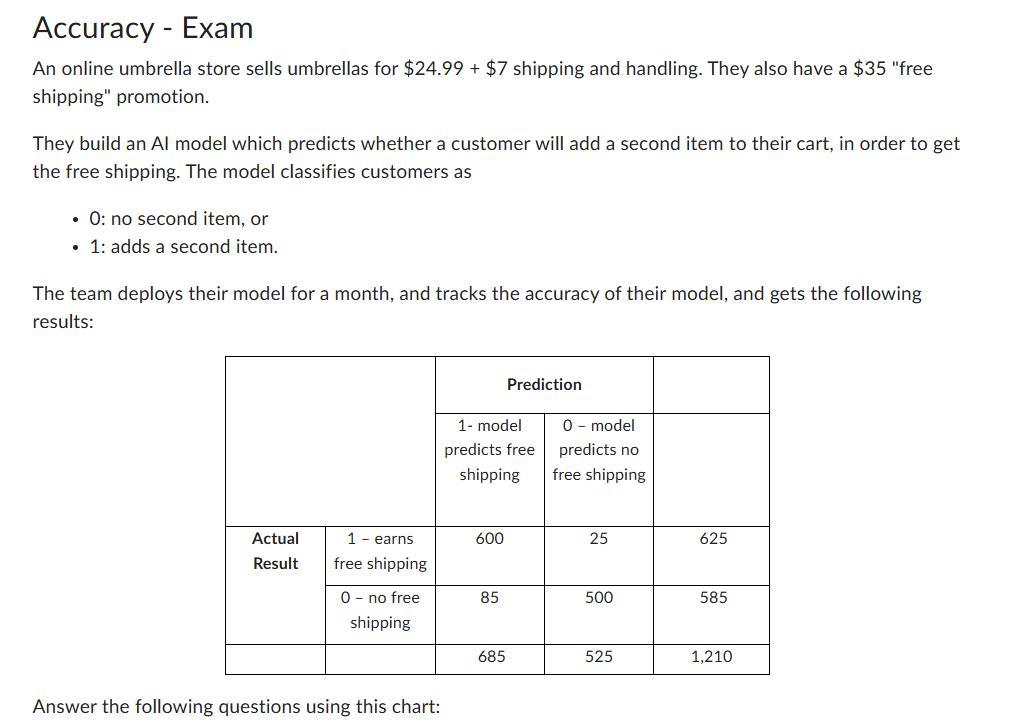
Given that the model predicts that a customer will buy a second item and get free shipping, what is the probability that they will add a second item? (Answer in percent to 2 decimal places)
P(Actual 1|1 predicted)
true positive / total predicted positive
600 / 685
= 0.8759 —> 87.59%
What is p(predicted 1 | 1 actual)
sensitivity
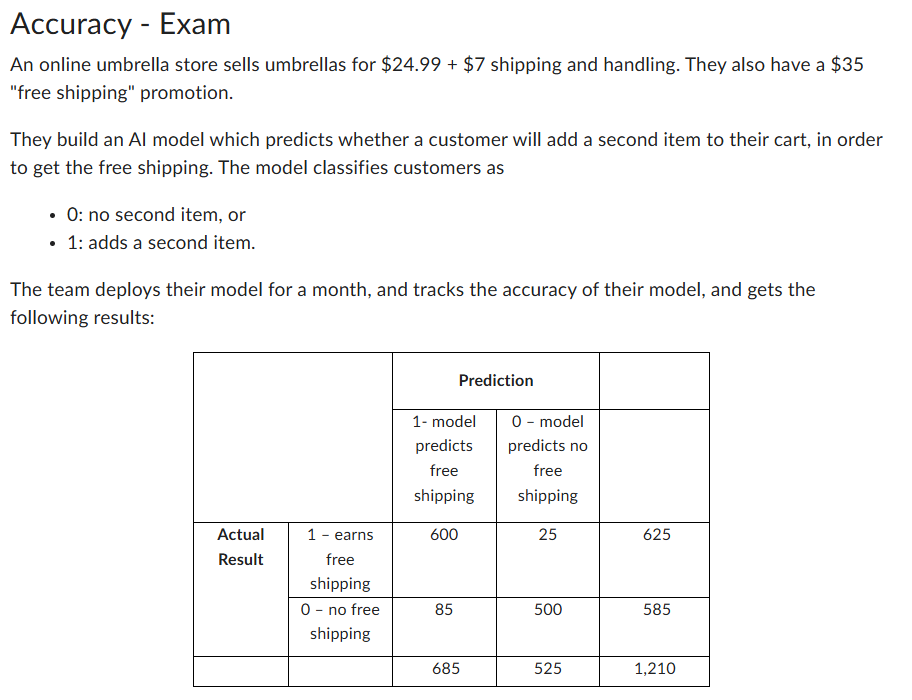
Given that a person is going to purchase a second item and earn free shipping, what is the probability that the algorithm correctly predicts this?
Sensitivity: TP / TP + FN
600/625
= 96.00%
Your boss at the online umbrella store has given you access to all of the customer data - dates, times, purchase amounts, customer Id, what they purchased, what ads they saw (thro7ugh Google). They tell you that you should come up with a project that will add value to the business. Read the following questions, then answer the questions.
How should you start coming up with a good Business Questions? Describe how you would start, in around 1 paragraph.
meet key stakeholders, for goals and painpoints
Specific, measurable, actionable
Once you have a Business Question, how would you go about selecting the types of models to try?
based on the type of output needed. For instance, if the question involves predicting a yes/no outcome like “Will a customer add a second item?”, I’d explore classification models like logistic regression, decision trees, or random forests. I’d assess the structure and quality of the data (e.g., labeled vs. unlabeled, numerical vs. categorical), then shortlist models based on their suitability
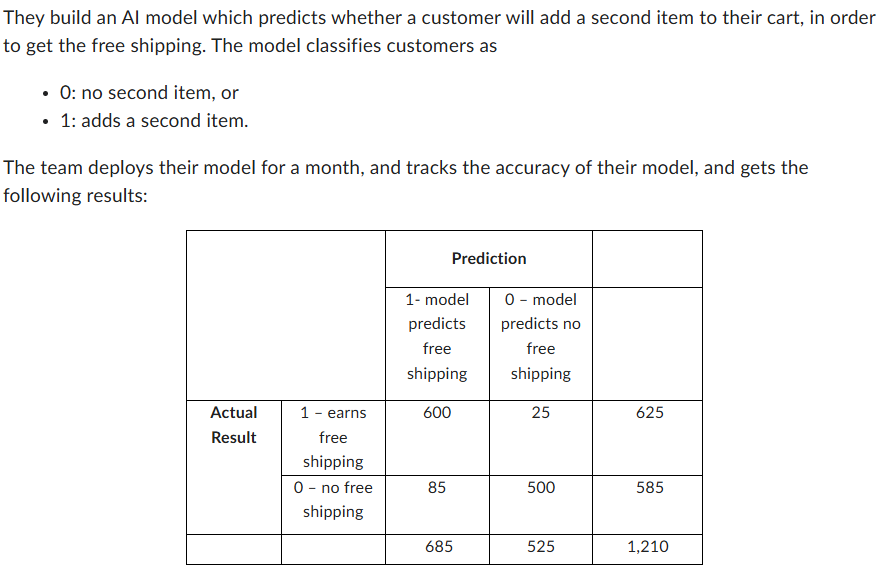
True Positives (TP): 600 — Model correctly predicted customers would add an item.
False Positives (FP): 85 — Model incorrectly predicted they’d add an item (but they didn’t).
False Negatives (FN): 25 — Model missed customers who actually added an item.
True Negatives (TN): 500 — Model correctly predicted no second item.
Explain this question:
A Reinforcement Learning algorithm is being trained on a "Choose Your own Adventure" book.
One option says: "Do you want to go to meet the President, if so turn to page 21. If not go watch the football game and turn to page 114."
In Reinforcement Learning, the algorithm makes choices and learns from the results. In this case, it picks a page (like meeting the President or watching football), sees what happens next, and uses that outcome to learn which choices lead to better results.
Initially, the algorithm chooses each page with equal probability. Choose the correct probability vector for option [page 21, page 144]:
The algorithm doesn’t know which choice is better at first, so it starts by picking each option with equal chance—50/50 or 0.5 and 0.5. It tries both paths, sees the results, and slowly learns which one gives better rewards to make smarter choices later
The algorithm chooses page 114, and gets the following message:
"The Stadium has collapsed! This is the end of your mission"
After finding this failure, the algorithm updates its probabilities. Which of the following are possible updates on the probability vector [page 21, page 114]. Choose ALL possibilitie
Since the algorithm chose page 114 and received a bad outcome, it should lower the probability of choosing page 114 and increase the probability of choosing page 21.
So a new probability vector like (0.67, 0.33) — where page 21 is more likely — is a valid update.
At another juncture, several iterations into the adventure, you come to another choice.
"Where will you head to now? If you choose to visit your aunt, go to page 134. If you decide to go to a concert, go to page 25. If you decide to go to the movies, go to page 105."
Which is a valid probability vector for [page 134, page 25, page 105].
You're at a decision point with 3 choices—each has a probability of being chosen. A valid probability vector must have numbers between 0 and 1 and must add up to 1 (100%).