2-3 stochastic bandits
1/18
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
19 Terms
Describe the stochastic multi-armed bandit setup

Pseudo regret for the stoc multi-armed bandit setup
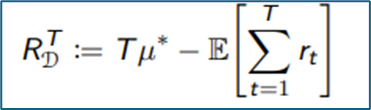
Performance measures: optimal arm, best arm, suboptimality gap

Regret decomposition lemma

Regret simple strategy exploration
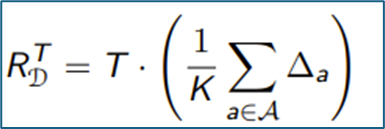
Regret simple strategy explotation FTL
\omega (T)
ETC - give outline of algorithm

UB Regret ETC

General LB Regret for any Bandit Algorithm

Best-arm idenfication- what is it and what is the bound on at least how many rounds T we need?

epsilon-greedy algorithm - give outline of algorithm
do exploration w.p. epsilon
do exploitation w.p 1-epsilon => pick the arm with highest empirical mean so far

LB regret e-greedy
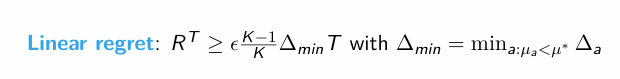
UCB - outline of general algorithm
In UCB we try to be greedy but use optimism to encourage exploration
The idea is to pick the arm with highest UCB - the arm we’re most optimistic of
if we played an arm many times, the confidence interval gets narrow
it eventually concentrates to the best arm - but only does so by exploring
UCB encourages exploration without the need of explicit randomness

Lemma Clean event - calculation
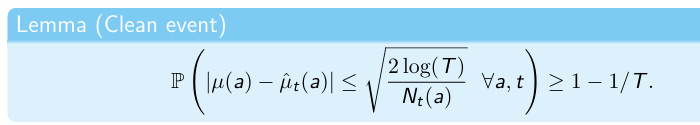
How many times do we play an sub-optimal arm?
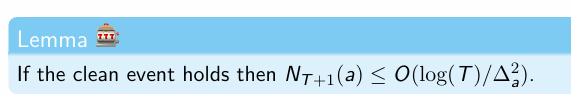
UCB: regret instance-dependent bound
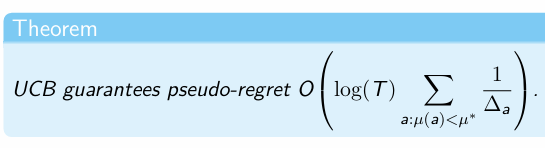
UCB: regret instance-INdependent bound

Define the Optimism Paradigm

Describe Thompson Sampling
