Q8 NLP CH 11 Fine-Tuning and Masked LM
1/39
Earn XP
Description and Tags
PG 242-263
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
40 Terms
______ processes both directions of a sentence to capture surrounding words.
generates embeddings that reflect the meaning of words in their specific context within the sentence
“_____” embeddings, meaning they adapt based on the surrounding words
Bidirectional encoders
contextualized
Bert stands for ________
first model to eliminate ____ and exclusive use layers of ______
subword vocab with 30k token generated using _______
hidden layers each of size 768
12 layers of _____ each with 12 ______ layers
two sizes
BERT_base: 110 M params
BERT_large: 340 M params
Bidirectional Encoder Representations from
Transformers
recurrent
transformer blocks
WordPiece
Transformer blocks
multihead attention
_______ was created using knowledge _____: trained to reproduce by predicting the behavior off a large model
same vocab as BERT
number of layers reduced by a factor of ____
____M params
reduces the size of BERT by 40% but claims to keep 97% of its performance benchmarks
Distilbert
distillation
2
66
Transformer blocks have the following layers
self attention
layer norm
FF

Pretrained language models based on ________ can be learned using a ________ objective where a model is trained to guess the missing information from an input
bidirectional encoders
masked LM
Pretrained language models can be _____ for specific applications by adding ________ layers on top of the outputs of the pretrained model
fine tuned
lightweight classifier
Bidirectional Encoder Architecture
each word in the input sequence is converted into an _______ and combined with _________ to retain the order of words in a sequence
each layer uses _______ to capture relations between words across the sentence
each head processes the word representations independently
which are combined and processed by the ____ layer, consisting of dense layers with activation functions, introduces nonlinearity allowing the model to learn more complex patterns in data
__________ stabilize training and preserves information by bypassing each sublayer directly to its output
_________ changes the output of each layer to have zero mean and unit variance, helps stabilize and speed up training
_____ Multiple layers allow the model to learn increasingly complex input representations by refining the contextual information in each successive layer.
final output is a ________ for each word, understand the entire sentence context
_______ summarizes the whole input for downstream tasks
embedding
positional
Muti head self-attention
FNN
residual connection
layer normalization
Stacking
contextualized embedding
classification token/CLS
Bidirectional Encoder
embeddings = ________ + _______
______(Q,K,V) = ___(QKT/ √dk)V
______(Q,K,V) = ____(head1, … ,headh)WO
____(x) = ____(xW1+b1) +W2+b2
output = _____(x + _____(x))
word E positional E
attention softmax
multhead concat
fnn relu
layernorm sublayer
as with causal transformers, the ________ dictates the complexity of the model
both time and memory requirement in a transformer grow _______ with the length of the input
to balance performance and computational feasibility, a _______ is set. It should be long enough to capture sufficient context without overwhelming the system
for BERT and XLR-RoBERTs, __#__ subword tokens was used
input layer size
quadratically
fixed input length
512
In the_______, certain words in a sentence are randomly "masked" or hidden, and the model is trained to predict these missing words based on the remaining context in the sentence.
cloze task
training bidirectional encoders is done using ______, Given a series of sentences from the training corpus, from each training sequence a random sample of tokens is chosen.
Once choses, the token is used is one of the following 3 ways:
__________
__________
__________
MLM
replaced with [MASK]
replaced with random token
unchanged
In BERT,
___% of the input tokens in a training sequence are sampled for learning.
Of these,
___% are replaced with _____
___% are replaced with _____
__ % are _______
15
80 [MASK]
10 random tokens
10 unchanged
in MLM training, the objective is to predict the original words for each masked token using a _________
the ______ measures the accuracy of these predictions, guiding the training of all model parameters
only the _____ tokens are used to calc
in each training, some tokens are sampled for masking which contributes to the learning process
ALL tokens go through the ______ mechanism, allowing the model to consider full-sentence context
bidirectional encoder
ce loss
masked
self attention
Training MLM
given a training sequence, samples words are masked and/or replaced and/or unchanged
the resulting embeddings are passed through a stack of _________
To produce a prob dist. for each masked token
yi = ____(Wv*zi)
zi is ______ from ______ layer
Wv is learned classification weight matrix
____ is used to calc error between the predicted and actual masked tokens by taking the ______ prob of the correct word
LMLM = -1/M sum( log P(xi|zi)
bidirectional transformer block
softmax
output vector final transformer
ce loss
negative log
In MLM like BERT, the primary objective is to predict words from their surrounding context, which helps create meaningful ____ level representations. For tasks that require an understanding of ______ between pairs of sentences, an additional training objective called _______ is used.
given a pair of sentences, the model must predict whether each pair consists of an actual adjacent sentence or two unrelated sentences
the model uses the [___] tokens output vector from the final transformation layer to make a 2-class prediction(true pair or random pair)
prediction achieved through a softmax layer and a learned set of classification weights
y = ___________
CE loss is used to calc NSPloss, which measures the model’s ability to correctly identify sentence relationships
word
relationships
NSP (next sentence prediction)
CLS
softmax(WNSPzCLS)
BERT introduces special tokens:
_____: Placed at the start of each input sentence pair; its output vector is used for _____ classificaiton
_____: Placed between the two sentences and at the end of the second sentence to mark boundaries.
_________: Added to help the model distinguish the first sentence from the second by marking each segment.
[CLS]
NSP
[SEP]
segment embeddings
BERT training used pairs of sentences sampled with a 50/50 scheme for the _____ task.
Sentences were masked following the MLM objective , and a __________ from MLM and NSP drove training.
_____ over the dataset were necessary for BERT to converge.
NSP
combined loss
40 epochs
_______ removed the NSP objective and trained on _______ text sequence instead of paired sentences. This change simplified training, allowing for larger _______ s (8K–32K tokens).
RoBERTa
continous
batch size
Multilingual models face unique challenges in building a _______ across multiple languages, especially when some languages are underrepresented.
A common solution is to _______ less-represented languages by adjusting sampling probabilities, ensuring these languages have fair representation in tokenization and vocabulary.
This reweighting process is controlled by a parameter (e.g., α/___=0.3), which gives a higher probability to rare language samples.
“curse of multilinguality” : As the number of languages grows, multilingualism performance decreases
additionally models tend to carry _________ from high resourse languages (ex English) making outputs slightly English like for low resource languages
balanced vocab
upweight
alpha
grammatical biases
In pre-trained language models, each token in an input sentence is assigned a ___________—a vector that captures the token's meaning within the sentence’s context.
provides a unique vector for each ______ (word used in a specific context)
allows it to adapt to nuances of each sentence
can also be used for tasks where understanding word meaning in context is crucial
like semantic similarity tasks (measuring the similarity between words in context)
For a token xi in a sentence of tokens xi, … xn, the ____________ zi provides a contextualized representation of that token’s meaning in the sentence.
can take the average of the output vectors for each token using multiple layers
contextual embedding
word instance
final layer output vector
Words are _______, meaning they can have multiple distinct sense or meanings depending on the context.
mouse1: small rodent | mouse2: computer device
thesauruses like _____ provide a ______ list of sense
embeddings from modern models like _____ capture word meaning in a ______ high dimensional space where
words with different senses cluster around diff. points or regions
(embeddings can be clustered to show different senses, they don’t form strictly separated or discrete categories.Instead, they offer a flexible, context-sensitive model of meaning that captures subtle variations, allowing for a more nuanced understanding of polysemous words.)
polysemous
WordNet discrete
BERT continuous
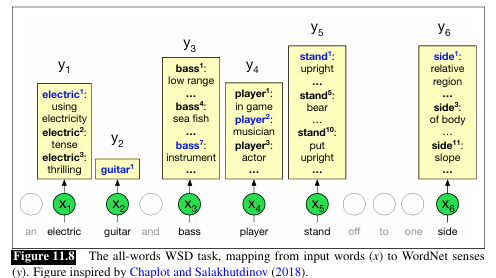
_________ is the task of selecting the correct sense for a word
given a word in context and a fixed inventory of potential word sense, it outputs the correct word sense in the context
___________ hypnosis suggests that in a single doc, a word usually maintains a single sense
simplifies WSD by limiting the senses a word might have within a single text
Sense embeddings Vs are vector representations of specific meanings (or senses) of a word.
At test time, given a token of a target word t in context, we compute its contextual embedding t a
_______ is used to compare the context embedding of the word with its sense embeddings, and ______ selects the sense with the highest similarity score.
word sense disambiguation /wsd
one sense per discourse
Cosine similarity
argmax
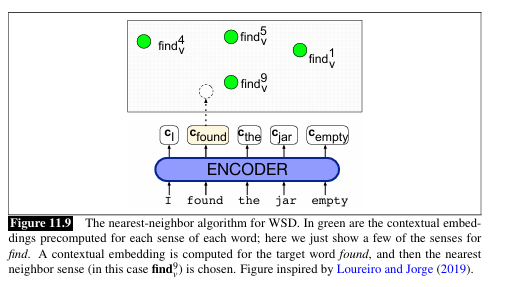
_______ is used to measure how close two word representations (embeddings) are, based on the ____ between their _____ .
When a word appears in a particular sense, its embedding will be closer to other instances of that same sense in context. This similarity in embedding space lets us gauge meaning similarity geometrically.
Cosine similarity
angle
vectors
________ is the property where embeddings in a model tend to point in similar directions, making even unrelated words appear similar due to high ___ values.
This issue arises in embeddings from contextual models (like ___), where vectors for different words show _______ and tend to point in a few dominant directions rather than being evenly spread out.
To reduce ^^ , standardize the embeddings by _____
formula : _________
helps balance the embeddings, making them less dependent on a few dominant dimensions and more directionally diverse.
Anisotropy
high cosine
BERT
cosine similarity
z scoring
z=(x-mean)/SD

In an ______ (uniform) embedding space, vectors would point in all directions equally, and the expected cosine similarity between random embeddings would be ____.
because of this, certain “_______” dimensions dominate, leading to unusually high cosine values for unrelated words.
isotropic
zero
rogue
_______ allows us to measure word meaning similarity, but contextual embeddings exhibit _______, skewing similarity measurements. ________ addresses some of this by balancing the embedding dimensions, making them more ______ and better suited for accurately measuring similarity. This process improves the usefulness of contextual embeddings in downstream NLP applications, where they serve as reliable, context-aware representations of words and sentences.
cosine similarity
anisotropy
z scoring
isotropic
The strength of pretrained language models lies in their capacity to learn general patterns from vast amounts of text, making them adaptable to many different tasks. There are two primary ways to apply these generalizations:
______ which involves using natural language prompts to guide the models responses in a context-aware way
________ involves adapting pre-trained models to specific applications by adding a few new parameters tailored to the task at hand
and uses labeled data for the task to train these added parameters, while either freezing or minimally adjusting the original model’s parameters.
preserves the model’s general knowledge while allowing it to specialize for specific applications.
prompting
fine tuning
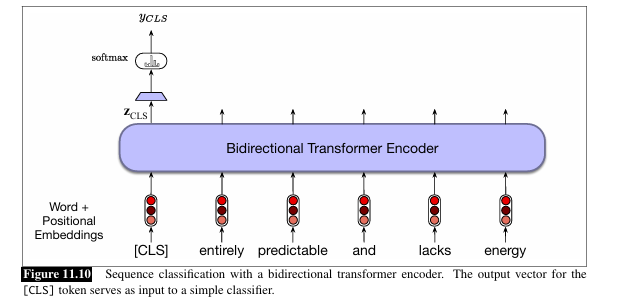
In _______ tasks, a model must classify an entire input sequence into specific categories, such as sentiment or topic
_______ add a special token at the start of each sequence {CLS} which is treated as a sentence embedding
Input text passes through the pre-trained model to generate ____ (output vector of the [CLS] token)
zCLS is passed through a ______ (a simple classifier, like logistic regression or a neural network) to make the final decision.
This vector is multiplied by Wc then passed through _____ to convert scores into prob over classes to classify the sequence.
fine tuning on ______ adjusts Wc and possibly the language model’s final layers for optimal classification.
sequence classification
transformers
zCLS
classification head
softmax
labeled data
__________ Classification involves classifying the _______ between two input sentences and is essential for tasks like paraphrase detection, logical entailment, and discourse coherence.
Fine-tuning for these tasks involves
passing labeled sentence pairs through the model, with [CLS] at the beginning and [SEP] separating the sentences.
The output vector of [CLS] represents the model’s understanding of the sentence pair.
This [CLS] vector is then multiplied by a set of classification weights and passed through softmax to produce a probability distribution over the possible labels.
For ____________ , also known as recognizing textual entailment, the sentence pairs are processed through the bidirectional encoder. The [CLS] vector from the final layer is fed to a ________, trained on labeled data from the MultiNLI dataset, allowing the model to learn how to the relationship into one of three categories
_____, _____, _____
Pair Wise Sequence relationship
Natural Language Inference/ NLI
three-way classifier
entails contradicts neural
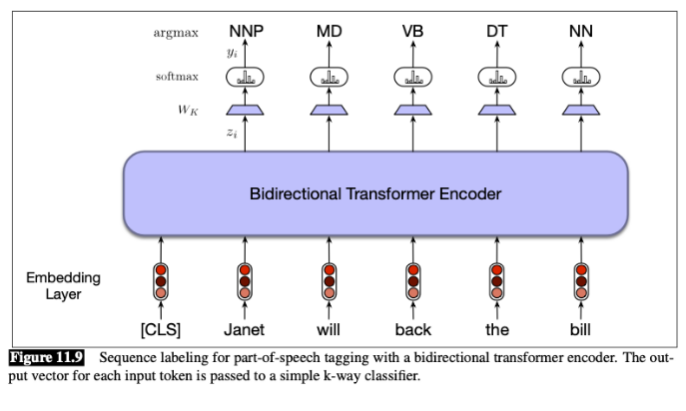
________ tasks involve assigning tags to each token in a sequence. (part-of-speech (POS) tagging and named entity recognition (NER) using the BIO format (Beginning, Inside, Outside) for entities)
token wise classification
zi : vector for token i
Wk, learned weights
size depends on the number of possible tags
yi = __formula____
____ approach tags each token independently, using the highest probability tag (argmax) for each token.
Alternatively, a CRF layer can follow the softmax output, taking into account global tag transitions for a more coherent tag sequence.
Models like BERT use ________ methods (e.g., WordPiece, Byte-Pair Encoding) that break words into subword units. This can create _______ with word-level BIO tags in the labeled training data.
handled by: During training, each subword token derived from a word inherits the ______ tag for the full word.
During decoding, the model can use the first subword token’s tag as the tag for the entire word, or, in more complex approaches, combine probabilities across all subword tokens to derive the most likely word-level tag.
sequence labeling
argmax(softmax(wkzi)
greedy
subword tokenization
misalignment
gold standard
In NLP, some tasks, ( such as question answering, syntactic parsing, coreference resolution, and semantic role labeling), require contextual learning for longer sequences. In SpanBERT
in _________ contiguous sequences of words (called spans) are selected for masking
A span length is randomly chosen, usually from a distribution favoring ___ spans (with a maximum of 10 tokens). The starting point is selected uniformly within the input.
Once chosen, all tokens in the span are masked together
80% replaced by [MASK] 10% replaced by random vocab words 10% unchanged
The total masking is limited to ___% of the input sequence to avoid excessive masking.
the __________ is an additional learning objective
for each span, the model derives boundary tokens. It then tries to predict each masked token within the span using these boundary embeddings.
To predict a token xi within a span, the model uses:
embeddings of the left boundary token zs-1
the right boundary token ze-1
A relative position embedding representing xi position within the span.
These three embeddings are ______ and passed through a ______ to produce a probability distribution over the vocabulary
The final loss for SpanBERT
L(x) = ______ + _____ (x)
span masking
shorter
15
Span Boundary Objective (SBO)
concatenated
FNN
MLM loss SBO loss
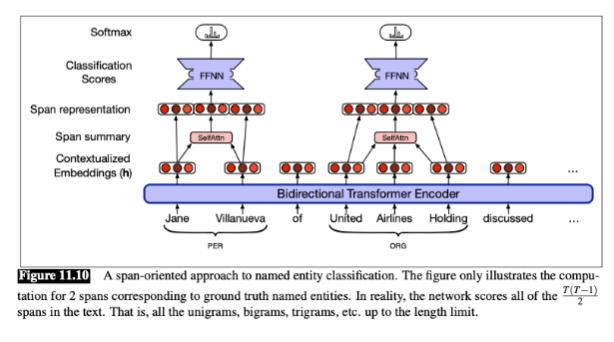
Span-based fine-tuning is a method for identifying and classifying sequences of words (spans) within a text it focus on contiguous phrases rather than individual tokens or the entire sequence. (tasks like named entity recognition (NER), question answering, coreference resolution, and syntactic parsing)
generate span by
boundary representation
content summary
simple: _____ the start and end embeddings with the ____ of embeddings within the span
learned: use ______ to improve accuracy by distinguishing the roles of start and end tokens.
instead of averaging, a ______ layer focusing on important tokens within the span, especially when no syntactic parse is available.
concan
av
fnn
self attention
Advantages of SpanBased Over BIO Tagging:
bio tagging requires each token within an entity to have the correct tag for the sequence to be judged correctly.
span based methods treat the entire span as _____ , reducing error from ____ tags within ____ entities.
Span-based methods can label ______ entities (e.g., “United Airlines” and “United Airlines Holding”), which is difficult in BIO tagging.
one unit
mismatched
long
overlapping
During training, the model learns from labeled data by adjusting the ______ and content representations to match gold-standard labels. ______ is used to guide these adjustments.
During inference, each span receives a _________ over possible labels, with the highest probability label assigned as the predicted label. A threshold can be applied to improve precision by filtering low-confidence predictions.
span boundary
ce loss
prob dist
_______ like BERT and its variants (RoBERTa, SpanBERT) produce ________ through MLM, NSP, and span-based objectives.
__________ is applied across different tasks—sequence classification, pair-wise classification, sequence labeling, and span-based tasks—to leverage these contextual embeddings for specific applications.
__________ and _______rely on contextual embeddings for meaning analysis, while _______affects embedding similarity measures, influencing ______ accuracy.
bidirectional transformer encoder
context embedding
fine tuning
cosine sim
wsd
anisotropy
downstream
Bidirectional Transformer Encoder Architecture: A transformer architecture that processes sentences in both directions, capturing context from the entire sequence.
_______: A foundational bidirectional transformer model trained on large datasets using ______ and _____ tasks to generate rich contextual embeddings.
_______ A variant of BERT that removes _____ and focuses on more robust MLM training with more data, improving model robustness.
________: Another BERT variant, emphasizing ________ for applications requiring ____-level context (e.g., question answering) and incorporating the ______ to better handle span-based tasks.
BERT MLM NSP
ROBERTA NSP
SpanBERT span masking phrase sbo
training objectives and techniques
_______: A technique where random tokens in a sequence are masked, and the model learns to predict them based on context, enabling rich contextual embeddings.
______: Used in BERT to teach the model sentence ______, especially useful in tasks like natural language inference.
________ Extends MLM by masking ______ word spans instead of individual tokens, suited for tasks that need span-level understanding.
MLM
NSP relationships
span masking continuous
_______: Representations of words based on the entire sentence context, enabling models to differentiate meanings of _______ words.
________ : Using contextual embeddings to determine a word’s meaning in a given context.
______ Measures similarity between embeddings, often used in WSD by comparing the embeddings of words within specific contexts.
_________ : The tendency of embeddings to cluster in certain directions, affecting the effectiveness of cosine similarity. ______ techniques can reduce anisotropy.
context embedding polysemous
polysemous
WSD
cosine similarity
Anisotropy zscoring
Fine-Tuning Language Models (LMs): Adapts pretrained models to specific tasks, either by adding task-specific layers or slightly adjusting existing model parameters.
_________________
Classify the entire sequence
[CLS] token for full sequence
outputs Single label
used for Sentiment analysis, topic classification
____________
Classify the relationship between two sequences
[CLS] for sequence pair relationship
[SEP] separator.
Outputs Single relationship label
used for NLI, paraphrase detection
Sequence Labeling:
Assigns labels to each token in a sequence by Classify each token individually
__________s for each token
Outputs sequence of token labels
used for NER, POS tagging
required to ____ with ______
Fine-Tuning for Span-Based Applications: Focuses on ___________ rather than individual tokens or the whole sequence, improving performance on phrase-oriented tasks (e.g., coreference resolution).
Sequence Class
Pair-Wise Sequence Class
Token embedding
align word labels
contiguous spans