System Design
1/55
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
56 Terms
OSI Layer 4
Transport Layer
TCP: Connection-oriented, reliable delivery, flow control, congestion control.
UDP: Connectionless, no guarantee of delivery, no ordering, lower latency.
OSI Layer 7
Application Layer
HTTP
REST
GraphQL: Good for when frontend teams need to iterate quickly and adjust.
gRPC: Binary encoding (more efficient than JSON). Good for internal service-to-service communication when network performance is critical.
Server-Sent Events (SSE): Server can stream messages over time in a single response. Tricky to deal with limitations (connection lifetime). Good for real-time push communication.
WebSockets: For high-frequency, persistent, bi-directional communication
WebRTC: Direct UDP peer-to-peer communication between clients.
Consistent Hashing
Multiple virtual nodes for each physical node (e.g. database shard) are hashed and distributed around a hash ring. Data is hashed by its key to a location on the ring and assigned to the nearest virtual node in a clockwise direction.
Used by Redis, Cassandra, DynamoDB, CDNs.
2025 Caching Metrics (latency, ops/s, memory)
~1 ms latency
100k+ operations/second
Memory-bound up to 1TB
2025 Database Metrics (latency, TPS, storage)
Sub-5ms read latency (cached)
Up to 50k transactions/second (less than 10k writes/second)
64+ TiB storage
2025 Application Server Metrics (concurrent connections, cores, RAM)
100k+ concurrent connections
8-64 cores
64-512GB RAM standard, up to 2TB
2025 Message Queue Metrics (latency, TPS, storage, partitions)
Sub-5ms end-to-end latency.
Up to 1 million messages/s per broker.
Up to 50TB storage.
4k partitions per broker, 200k partitions per cluster.
DB Index Types
B-Tree Indexes
Hash Indexes
Geospatial Indexes
Inverted Indexes
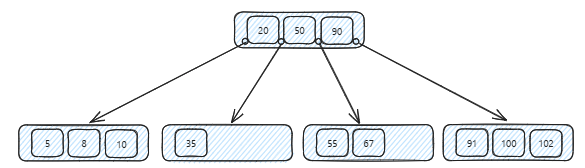
B Tree Indexes
Maintain sorted order (efficient range queries and ORDER BY operations)
Self-balancing (predictable performance even as data grows)
Minimize disk I/O by matching their structure to how databases store data
Handle both equality searches (email = 'x') and range searches (age > 25) equally well
Remain balanced even with random inserts and deletes, avoiding the performance cliffs you might see with simpler tree structures
Hash Indexes
Only choose when
You need the absolute fastest possible exact-match lookups
You'll never need range queries or sorting
You have plenty of memory (hash indexes tend to be larger than B-trees)
Geospatial Indexes
Geohash
Divide the world into nested levels of four squares (labeled 0-3) and convert to base32 string.
Encoded strings stored in B-tree index.
Used by Redis and MongoDB.
Quadtree
When a square contains more points than threshold, split it into four equal quadrants.
Requires specialized tree structures (not popular).
R-Tree
Adapt rectangles to data, with possibility of overlap
Efficiently handle both points and larger shapes.
Used by PostgreSQL and MySQL.
Inverted Indexes
Maps tokens to the list of documents containing those tokens.
Necessary for sophisticated text search.
Require substantial storage and updating overhead.
Composite Indexes
B-tree index where a key is a tuple.
Convert two-dimensional queries (e.g. user ID and time) into a one-dimensional scan through ordered index entries. Filtering and sorting are handled by a single index scan.
Order matters. A composite index won’t help with a query that only filters on the 2nd column.
Covering Indexes
Includes all columns needed by a query to prevent fetching the actual data.
Increase read performance at the cost of space.
Niche optimization, only use if you have a very good reason.
Real-Time Updates from Server to Client
Simple Polling: Client sends normal queries on a loop.
Long Polling: Client sends queries, server holds connections open until an event occurs or they’re about to timeout.
Server-Sent Events (SSE): Client sends queries, server uses special Transfer-Encoding: chunked header and holds connections open streaming data back as events occur without closing the HTTP connection.
WebSockets: Takes an existing HTTP request’s TCP connection and changes the protocol from HTTP to WebSocket to allow bi-directional binary messages.
WebRTC: Clients talk to central “signaling” server to get information about peers and opens direct peer-to-peer connection. Session Traversal Utilities for NAT (STUN) server helps peers establish publicly routable addesses+ports and Traversal Using Relays around NAT (TURN) server is a fallback relay to allow clients to bounce messages through a central server.
Real-Time Updates from Source to Server
Pulling with Simple Polling: If client uses simple polling to get updates from the server, the same requests can be forwarded by the server to the source (e.g. database).
Pushing via Consistent Hashes: Clients are assigned to a server by consistent hashing (tracked by a coordination service like Zookeeper) and updates for those clients are sent to the applicable server by consistent hashing.
Pushing via Pub/Sub: The source publishes updates to a single service (Redis/Kafa) which broadcastings them to all necessary servers, which forward them to interested clients.
Bloom Filter
Probabilistic data structure for determining if an element might be in a set. No false negatives but false positives.
Bit array that uses multiple hash functions, where each hash function maps an element to an index in the bit array.
Like a single paper where everyone uses their unique stamp on top of each others’ stamps. It can tell you definitively who has not stamped, but it can not guarantee who has stamped.
Count-Min Sketch
Probabilistic data structure for estimating counts. Can determine upper bounds of counts for an element but not always determine lower bounds.
2D array of counters with multiple hash functions.
Like multiple holes that people throw stones into, where each person is assigned two holes they throw into.
HyperLogLog
Probabilistic data structure for estimating count of unique elements in a set (i.e. cardinality estimation).
List of buckets, each bucket contains the max count of leading 0s seen for a given hash function.
Like flipping a coin many times, the max amount of tails in a row gives a hint to how many times the coin has been flipped.
Redis Hot Key Issue
In a cluster, if a particular key becomes extremely popular then the load on one server is dramatically higher than the load on other servers.
Potential Solutions
Add in-memory cache in clients.
Store same data in multiple keys and randomize requests so they are spread across the cluster.
Add read replicas and dynamically scale with load.
Elasticsearch Terminology (document, index, mapping)
Terminology
Document: Individual unit of data, essentially a JSON object.
Index: Collection of documents, like a database table.
Mapping: Schema of the searchable fields.
Elasticsearch Relevance Sorting
Uses an algorithm similar to Term Frequency - Inverse Document Frequency (TF-IDF), which ranks a word by how often it appears in a document and its rarity across all documents.
Elasticsearch Pagination
Pagination can use simple indexing with from. For efficient deep pagination use search_after. A cursor can be used by creating a point in time (PIT) and using the PIT in conjunction with search_after.
Elasticsearch Node Types
Master Node: Admin node of the cluster.
Data Node: Stores data.
Coordinating Node: Coordinates search requests. “Frontend” of the cluster.
Ingest Node: Ingests data, transforming it to prepare it for indexing.
Machine Learning Node
Elasticsearch Data Node Internals
Contain indices which are composed of shards and their replicas. Inside a shard is a single Lucene index which is made up of Lucene segments.
Lucene Segments
Immutable containers of indexed data.
Insertions are batched, a new segment is created with all new documents and flushed to disk.
Deletions are processed by marking documents as deleted and pretending they don’t exist. When segments are merged, soft deleted documents are cleaned up.
Updates include soft deleting the existing document in an existing segment and inserting a new document into a new segment.
Inverted Index
Heart of Lucene. Mapping of content (word or number) to its locations in a database.
Allow for O(1) lookup of documents containing specific content.
Doc Values
Columnar, contiguous representation of a single field for all documents across the segment.
Makes filtering, sorting, and aggregations fast.
Elasticsearch Coordinating Nodes
Parse queries and run query planner algorithms that utilize statistics to determine the most efficient way to execute a query (e.g. get IDs for multiple words and perform a union vs get IDs for word with fewer documents and search those documents for other word).
Elasticsearch Usage Considerations
Not a good primary database due to consistency and durability.
Designed for read-heavy workloads. If system is write-heavy, consider other options or implementing a write buffer (e.g. for likes on a post), or omit write-heavy fields during transformation.
Data should be denormalized (not a relational DB).
Not necessary for small datasets or infrequently changed data.
Data synchronization issues require care.
Kafka Terminology (broker, partition, topic)
Broker: Individual server responsible for storing data and serving clients. Has a number of partitions.
Partition: Ordered, immutable sequence of messages that is continually appended to.
Topic: Logic grouping of partitions.
Kafka Message
A message (i.e. record) consists of a value and optionally a key, timestamp, and headers. Key determines partition, timestamp used to order messages with a partition, and headers are key-value pairs for metadata.
Kafka Replication
Each partition has a leader replica which handles all read/write requests for the partition. For each partition, several follower replicas exist on different brokers, passively replicating data from the leader replica and available to be promoted to be the new leader if the current leader replica fails.
Kafka Hot Partition Issue
Potential Solutions
Random partitioning with no key. If order of messages does not matter.
Random salting. Add random number or timestamp to the ID.
Compound key. Combine ID and another attribute (e.g. region), maintaining order within that attribute.
Back pressure. Slow down the producer.
Kafka Fault Tolerance & Durability
Durability is ensured by replicating partitions across multiple brokers, and the producer acknowledgment setting can be set to ensure that a message is acknowledged only when all replicas have received it (acks=all).
Kafka Error Handling
Producers can be configured to automatically retry failures when adding messages to Kafka.
Consumer retries require custom implementation, such as a separate topic where failed messages are sent and a dead letter queue where messages that fail too many times are sent.
Kafka Performance Optimizations
Enable producer message batching.
Enable producer message compression.
Choose a good partition strategy to maximize parallelism.
Cassandra Data Model
Keyspace: Like a database. Contain tables.
Table: Contain rows.
Row: Primary key and columns.
Column: Data represented by a name, type, and value. Columns can vary per row in a table. Each column has timestamp metadata, write conflicts between replicas are resolved via “last write wins”. Types can be flat or nested.
Cassandra Primary Key
Consists of partition and cluster key.
Partition Key: One or more columns that are used to determine what partition the row is in.
Cluster Key: Zero or more columns that are used to determine the sorted order of rows in a table.
Cassandra Partitioning and Replication
Partitioning: Uses consistent hashing to determine destination partition for data.
Replication: Leverages consistent hashing to identify where to replicate a specific virtual node, scanning clockwise to find X number of other virtual nodes (skipping virtual nodes that are on the same physical node as the virtual node being replicated).
SimpleStrategy: Determines replicas by scanning clockwise and nothing else.
NetworkTopologyStrategy: Data center and rack aware to store replicas in multiple data centers and different racks in a data center.
Cassandra Consistency
Multiple consistency levels.
ONE: Single replica needs to respond for a read/write to succeed.
ALL: All replicas need to respond for a read/write to succeed.
QUORUM: A majority of replicas need to respond for a read/write to succeed. Guarantees that writes are visible to reads because at least 1 overlapping node is guaranteed to participate in both the write and the read.
Cassandra Storage Model
Favors write speed over read speed with every create/update/delete being a new entry and using the ordering of entries to determine the state of a row.
Log Structured Merge Tree (LSM tree) index instead of B-tree index.
Commit log: Write-ahead log to ensure durability of writes.
Memtable: In-memory, sorted data structure that stores write data.
SSTable: Sorted string table; immutable file on disk containing data flushed from a previous memtable sorted by primary key.
Writing: Write to commit log, then write to memtable, eventually flush memtable to disk as an SSTable and remove commit log messages corresponding to flushed memtable entries.
Reading: Read memtable and possibly use bloom filter to identify SSTables and read them in order from newest to oldest.
Cassandra Query Routing and Fault Tolerance
Query Routing: Any node can service a client query because all nodes can assume role of a query coordinator. Nodes know about each other because of gossip protocol and can determine where data lives by running the consistent hashing algorithm.
Fault Tolerance: If a node is considered offline by the cluster, a coordinator node attempting to write to the offline node temporarily stores the write data, called a “hint”. When the offline node is detected online, the node(s) with hints send that data to the previously-offline node.
Cassandra Secondary Indexes
Cassandra secondary indexes are local, not global, and will not be performant if a query does not contain the partition key.
Cassandra Usage Considerations
Good if prioritizing availability over consistency and have high scalability needs.
Good if workloads are write-heavy.
Good for clear access patterns, bad for advanced query patterns (multi-table JOINs, adhoc aggregations).
DynamoDB Data Model
Table: Contains items identified by primary key. Supports secondary indexes.
Item: Like a row. Primary key plus attributes, up to 400KB of data.
Attribute: Key-value pair of data. Can be scalar and set types, can be flat or nested. Attributes can vary between items in a table.
DynamoDB Primary Key
Partition Key: A single attribute that is used to determine what partition to store the item.
Sort Key: An optional attribute that is used to order items with the same partition key.
Consistent hashing for partition keys, B-trees for sort keys.
DynamoDB Secondary Indexes
Global Secondary Index (GSI): An index with a partition key and optional sort key that differs from the table's partition key. Allow querying items based on attributes. Since GSIs use a different partition key, the data is stored on entirely different physical partitions from the base table and is replicated separately.
Local Secondary Index (LSI): An index with the same partition key as the table's primary key but a different sort key. LSIs enable range queries and sorting within a partition. Since LSIs use the same partition key as the base table, they are stored on the same physical partitions as the items they're indexing.
DynamoDB Consistency
Supports transactions.
Supports optimistic locking using version numbers.
Consistency modes:
Eventual Consistency: Default mode, provides highest availability and lowest latency.
Writes are made to primary replica and asynchronously written to secondary replicas. Reads can be served by any replica.
Strong Consistency: Potentially lower availability and higher latency.
Reads are routed to a leader node, which ensures it has the most up-to-date data before responding.
DynamoDB Scalability
Auto-sharding and load balancing is managed by AWS.
Global Tables allow real-time replication across regions, enabling local read/write operations worldwide.
DynamoDB Usage Considerations
Good for most use cases.
Not good for workloads with an extreme amount of reads/writes per second, due to cost.
Not good if usage patterns require complex queries like joins or multi-table transactions.
Not preferable if many GSIs or LSIs are required (use relational DB instead).
Locked into AWS.
PostgreSQL Indexes
Types
B-tree Indexes: Great for exact matches, range queries, and sorting. Automatically created on primary key column.
Generalized Inverted (GIN) Indexes: For full-text search.
PostGIS: Extension for geospatial querying using R-tree indexes.
Queries can leverage multiple index types (e.g. find video posts within 5km that mention “food” in their description and are tagged with “restaurant”).
All indexes are global.
PostgreSQL Limitations
Read Limits
Simple indexed lookups: tens of thousands per second per core.
Complex joins: thousands per second
Write Limits
Simple inserts: ~5,000 per second per core.
Updates with index modifications: ~1,000-2,000 per second per core.
Complex transactions (multiple tables/indexes): Hundreds per second.
Bulk operations: Tens of thousands of rows per second.
Scale
Tables start getting unwieldy past 100M rows.
Full-text search works well up to tens of millions of documents.
Complex joins become challenging with tables >10M rows.
PostgreSQL Replication
For read scaling and reliability.
PostgreSQL Consistency
Writes to replicas can be synchronous (strong consistency/high latency) or asynchronous (eventual consistency/low latency). Can use hybrid approach of small number of synchronous replicas for stronger consistency with additional asynchronous replicas for read scaling.
Transactions ensure atomicity and consistency for a single set of operation, but they don’t necessarily ensure overall consistency when multiple transactions are occurring concurrently (e.g. two bid transactions happening simultaneously can insert bid rows and update the auction’s maxbid, resulting in a $100 bid getting overwritten by a $95 bid).
Ensuring consistency for concurrent transactions:
Optimistic locking can be implemented with version number. Good for transactions with low likelihood to be concurrent, does not block other transactions.
Pessimistic locking using SELECT with FOR UPDATE.
Increase isolation level. Serializable isolation level causes transactions to behave if they were executed sequentially. Only good for transactions which are over complex.
PostgreSQL Usage Considerations
Good default choice due to strong ACID guarantees with effective scaling, handling of both structured & unstructured (JSONB) data, built in solutions for full-text search & geospatial queries.
Good when data has complex relationships.
Good when strong consistency is necessary.
Good for rich querying capabilities.
Good for a mix of structured and unstructured data (JSONB).
Good when needing built-in full-text search or geospatial queries.
Not good for extreme write throughput.
Not good for global multi-region requirements where multiple regions accept writes simultaneously. One region must be the primary writer with other regions acting as read replicas.
Pessimistic/Optimistic Locking vs Distributed Locking
Pessimistic/optimistic locking is for situations that finish in under 1s. Distributed locking is for situations that takes many seconds or longer.
Interview Process
Requirements (~5 minutes)
Functional Requirements
Non-functional Requirements
Capacity Estimation
Core Entities (~2 minutes)
API/System Interface or Data Flow (~5 minutes)
High Level Design (~15 minutes)
Deep Dives (~15 minutes)
Nonfunctional Requirements to Keep in Mind
Availability (9s) vs Consistency (strong or how long for eventual) for Different Operations
Latencies for Different Operations (P99)
Scale & Throughput
Fault Tolerance & Durability
Constraints