Lectures 11 & 12 Databases Quiz - File Storage and Indexing
1/56
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
57 Terms
where are databases typically stored?
on magnetic disks; accessed using physical database file structures
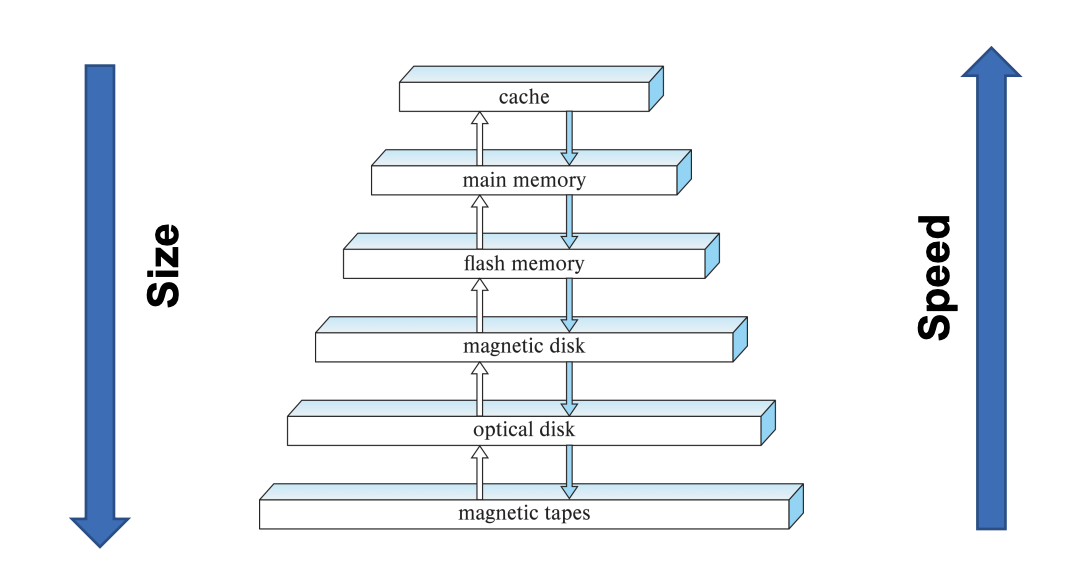
storage hierarchy
primary storage (CPU main memory, cache memory)
secondary storage (magnetic disks, flash memory, solid-state drives)
tertiary storage (removable media)
memory hierarchies and storage devices
cache memory (static RAM, DRAM)
mass storage (magnetic disks- CD ROM, DVD, tape drives)
flash memory (nonvolatile)
storage hierarchy diagram
primary storage
fastest media but volatile (cache, main memory)
secondary storage
next level in hierarchy, non-volatile, moderately fast access time; also called on-line storage; ex: flash memory, magnetic disks
tertiary storage
lowest level in hierarchy, non-volatile, slow access time; also called off-line storage and used for archival storage; ex: magnetic tape, optical storage
magnetic tape
sequential access, 1 to 12 TB capacity; a few drives with many types; juke boxes with petabytes (thousands of TBs) of storage
storage organization of databases
persistent data (most databases)
transient data (exists only during program execution)
file organization (determines how records are physically placed on the disk and how they are accessed)
why do we not only use main memory?
it is possible that the database might not fit into main memory. main memory is volatile.
main memory vs disk
given available main memory, when do we keep which part of the database in main memory?
buffer manager- component of DBMS that decides when to move data between disk and main memory
how do we ensure transaction property durability?
buffer manager needs to make sure data written by committed transactions is written to disk to ensure durability
blocks
a database file is partitioned into fixed-length storage units called blocks. blocks are units of both storage allocation and data transfer
Database system seeks to minimize the number of block transfers between the disk and memory. We can reduce the number of disk accesses by keeping as many blocks as possible in main memory.
buffer
portion of main memory available to store copies of disk blocks
buffer
portion of main memory available to store copies of disk blocks
buffer manager
subsystem responsible for allocating buffer space in main memory; programs call on the buffer manager when they need a block from disk.
if the block is already in the buffer, the buffer manager returns the address of the block in main memory
if the block is not in the buffer, the buffer manager
allocates space in the buffer for the block
replacing (throwing out) some other block, if required, to make space for the new block
replaced block written back to disk only if it was modified since the most recent time that it was written to/fetched from the disk
reads the block from the disk to the buffer, and returns
least recently used (LRU) strategy
buffer replacement policy; most operating systems replace the block least recently used. Idea behind LRU- use past pattern of block references as a predictor of future references
Queries have well-defined access patterns (such as sequential scans), and a database system can use the information in a user’s query to predict future references
LRU can be a bad strategy from certain access patterns involving repeated scans of data
mixed strategy with hints on replacement strategy provided by the query optimizer is preferable
pinned block
memory block that is not allowed to be written back to disk
toss-immediate strategy
frees the space occupied by a block as soon as the final tuple of that block has been processed
most recently used (MRU) strategy
system must pin the block currently being processed. After the final tuple of that block has been processed, the block is unpinned, and it becomes the most recently used block. Buffer manager can use statistical information regarding the probability that a request will reference a particular relation.
record
collection of related data values or items; values correspond to record fields
binary large objects
BLOBs; unstructured objects
file organization
the database is stored as a collection of files. Each file stores records (tuples from a table.) A record is a sequence of fields (the attributes of a tuple).
reading one record at a time from disk would be very slow (random access)
organize our database files in pages (size of block or larger)
read/write data in units of pages
one page will usually contain several records
one approach:
assume record size is fixed
each file has records of one particular type only
diff files are used for diff relations
this case is easiest to implement
reasons for variable-length records
one or more fields have variable length
one or more fields are repeating
one or more fields are optional
file contains records of diff types
fixed-length records
simple approach
store record i starting from byte n * (i-1) where n is the size of each record
record access is simple, but records may cross blocks
modification: do not allow records to cross block boundaries
deletion of record i: alternatives
move records i+1, … n to i, … n -1
move record n to i
do not move records, but link all free records on a free list
free lists
store the address of the first deleted record in the file header
use this first record to store the address of the second deleted record, and so on
can think of these stored addresses as pointers since they “point” to the location of a record
more space efficient representation: reuse space for normal attributes of free records to store pointers (no pointers stored in in-use records)
variable-length records
variable-length records arise in database systems in several ways:
storage of multiple record types in a file
record types that allow variable lengths for one or more fields such as strings (varchar)
record types that allow repeating fields (used in some older data models)
attributes are stored in order
variable length attributes represented by fixed size (offset, length), with actual data stored after all fixed length attributes
null values represented by null-value bitmap
spanned records
larger than a single block; pointer at end of first block points to block containing remainder of record
unspanned record
records not allowed to cross block boundaries
blocking factor
average number of records per block for the file
allocating file blocks on disk
contiguous allocation
linked allocation
indexed allocation
file header (file descriptor)
contains file information needed by system programs (disk addresses, format descriptions)
heap
a record can be placed anywhere in the file where there is space
sequential
store records in sequential order, based on the value of the search key of each record
hashing
a hash function computed on some attribute of each record; the result specifies in which block of the file the record should be placed
multitable clustering file organization
records of each relation may be stored in a separate file. In a multitable clustering file organization, records of several different relations can be stored in the same file; motivation: store related records on the same block to minimize I/O
files of unordered records (heap files)
heap (or pile) file
records placed in file in order of insertion
inserting a new record is very efficient
searching for a record requires linear search
deletion techniques
rewrite the block
use deletion marker
files of ordered records (sorted files)
ordered (sequential) file
records sorted by ordering field
called ordering key if ordering field is a key field
advantages
reading records in order of ordering key value is extremely efficient
finding next record
binary search technique
access times for various file organizations

bucket
unit of storage containing one or more records. a bucket is typically a disk block
static hashing
in hash file organization we obtain the bucket of a record directly from its search-key value using a hash function
hash function h is a function from the set of all search-key values to the set of all bucket addresses B
hash function is used to locate records for access, insertion, as well as deletion
records with different search-key values may be mapped to the same bucket; thus entire bucket has to be searched sequentially to locate a record
hash functions
worst hash function maps all search-key values to the same bucket; this makes access time proportional to the number of search-key values in the file
an ideal hash function is uniform, meaning each bucket is assigned the same number of search-key values from the set of all possible values
ideal hash function is random, so each bucket will have the same number of records assigned to it irrespective of the actual distribution of search-key values in the file
typical hash functions perform computation on the internal binary representation of the search-key
why can bucket overflow occur?
insufficient buckets
skew in distribution of records because of two reasons:
multiple records have the same search-key value
chosen hash function produces non-uniform distribution of key values
although the probability of bucket overflow can be reduced, it cannot be eliminated; it is handled using overflow buckets
overflow chaining
the overflow buckets of a given bucket are chained together in a linked list; example of closed hashing
open hashing
does not use overflow buckets; not suitable for database applications
deficiencies of static hashing
if the initial number of buckets is too small, and file grows, performance will degrade due to too much overflows
if space is allocated for anticipated growth, a significant amount of space will be wasted initially (and buckets won’t be full)
if database shrinks, again space will be wasted
one solution: periodic re-organization of the file with a new hash function; this is expensive and disrupts normal operations
better solution: allow the number of buckets to be modified dynamically
indexes
used to speed up record retrieval in response to certain search conditions; index structures provide secondary access paths; any field can be used to create an index, and multiple indexes can be constructed; most indexes based on ordered files organized into tree structures
types of single-level ordered indexes
ordered index similar to index in a textbook
indexing field (attribute)
index stores each value of the index field with list of pointers to all disk blocks that contain records with that field value
values in index are ordered
primary index, clustering index, secondary index
primary index
specified on the ordering key field of ordered file of records
ordered file with two fields
primary key, K(i)
pointer to a disk block, P(i)
one index entry in the index file for each block in the data file
indexes may be dense or sparse
major problem: insertion and deletion of records
move records around and change index values
solutions:
use unordered overflow file
use linked list of overflow records
dense index
has an index entry for every search key value in the data file
sparse index
has entries for only some search values
clustering indexes
clustering field
file records are physically ordered on a nonkey field without a distinct value for each record
ordered file with two fields
same type as clustering field
disk block pointer
secondary indexes
provide secondary means of accessing a data file
some primary access exists
ordering file with two fields
Indexing field K(i)
block pointer or record pointer, P(i)
usually need more storage space and longer search time than primary index
improved search time for arbitrary record
index record points to a bucket that contains pointers to all the actual records with that particular search-key value
secondary indices have to be dense
primary and secondary indices sequential scanning
indices offer substantial benefits when searching for records
BUT: updating indices imposes overhead on database modification — when a file is modified, every index on the file must be updated,
sequential scan using primary index is efficient, but a sequential scan using a secondary index is expensive
each record access may fetch a new block from disk
block fetch requires about 5 to 10 milliseconds, vs about 100 nanoseconds for memory access
multilevel index
if primary index does not fit in memory, access becomes expensive
solution: treat primary index kept on disk as sequential file and construct a sparse index on it
outer index- a sparse index of primary index
inner index- the primary index file
if even outer index is too large to fit in main memory, yet another level of index can be created, and so on
indices at all levels must be updated on insertion or deletion from the file
designed to greatly reduce remaining search space as search is conducted
index file- considered first (or base level) of multilevel index
second level- primary index to the first level
third level- primary index to the second level
dynamic multilevel indexes using B+ trees
tree data structure terminology
tree is formed of nodes
each node (except root) has one parent and zero or more child nodes
leaf node has no child node
unbalance if leaf nodes occur at different levels
nonleaf node called internal node
subtree of node consists of node and all descendant nodes
B+ trees
data pointers stored only at the leaf nodes
leaf nodes have an entry for every value of the search field, and a data pointer to the record if search field is a key field
for a nonkey search field, the pointer points to a block containing pointers to the data file records
internal nodes
some search field values from the leaf nodes repeated to guide search
B+ tree index files
B+ tree indices are an alternative to indexed-sequential files
disadvantage of indexed-sequential files:
performance degrades as file grows, since many overflow blocks get created
periodic reorganization of entire file is required
advantages of B+ tree index files:
automatically reorganizes itself with small, local, changes in the face of insertions and deletions
reorganization of entire file is not required to maintain performance
(minor) disadvantage of B+ trees:
extra insertion and deletion overhead, space overhead
advantages of B+ trees outweigh disadvantages, so B+ trees are used extensively