Decision Trees: Entropy and Information Gain in Data Mining
1/24
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
25 Terms
Information Gain
Reduction in entropy after a data split.
Pure Group
Group with one dominant class present.
Impure Group
Group with no dominant class present.
Entropy Formula
H = -Σ(p_i * log2(p_i)).
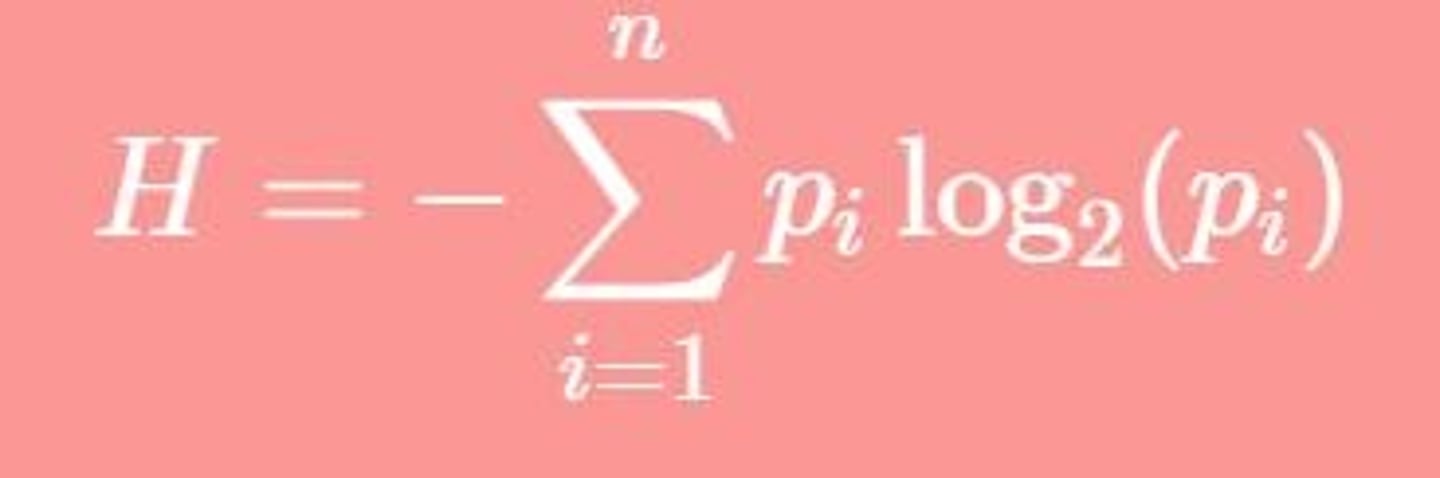
Maximum Entropy
Occurs when all classes are equally probable.
Minimum Entropy
Occurs when one class is certain (p=1).
Decision Tree
Algorithm for supervised machine learning tasks.
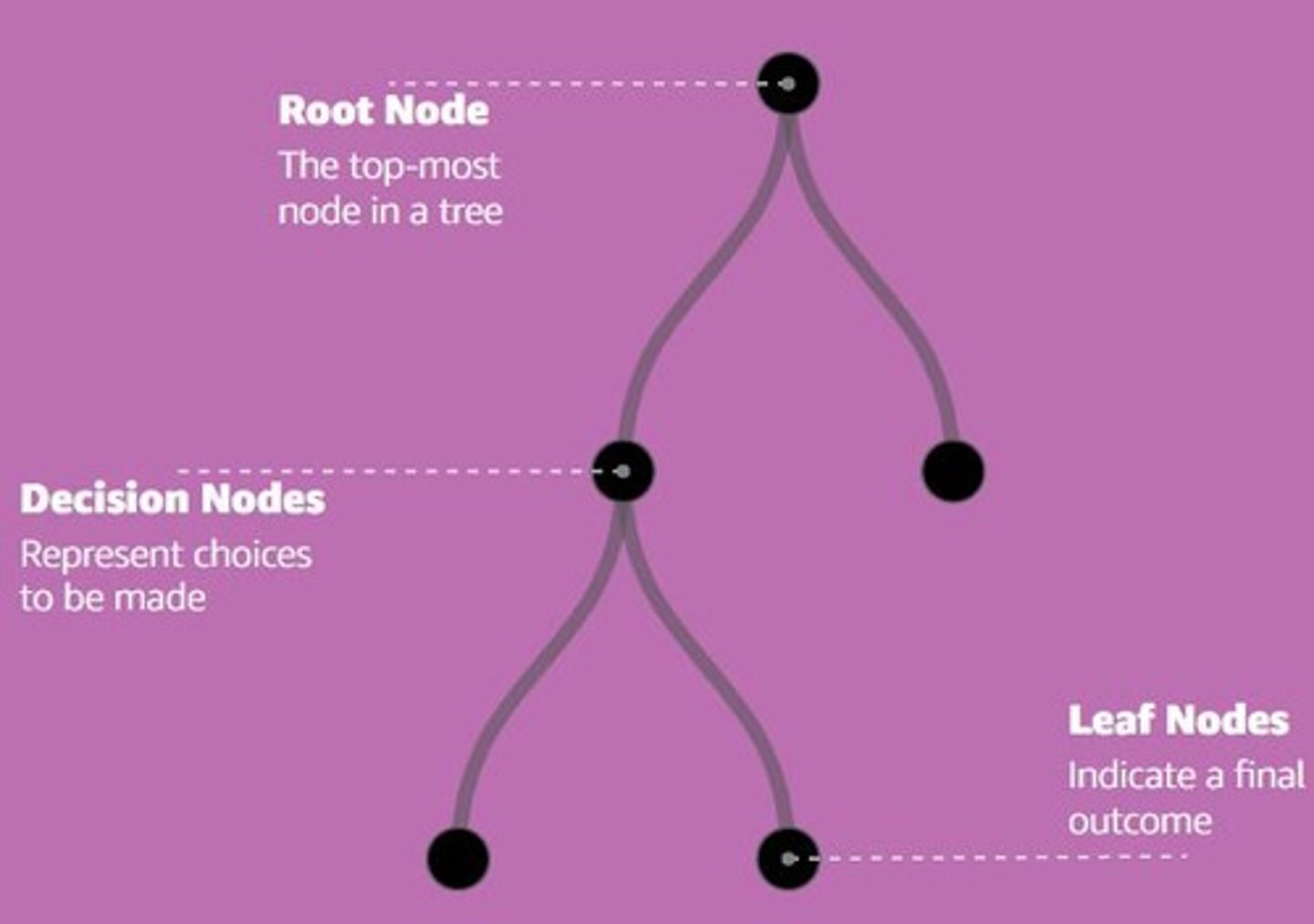
Decision Node
Point where a decision is made in tree.
Leaf Node
Terminal node representing prediction output.
Entropy
Measure of uncertainty or impurity in data.
Parent Entropy
Entropy before data split in decision tree.
Child Entropy
Entropy after data split in decision tree.
Balance Feature
Feature indicating financial balance status.
Residence Feature
Feature indicating living situation (OWN, RENT, OTHER).
Information Gain Calculation
IG = H(parent) - H(children).
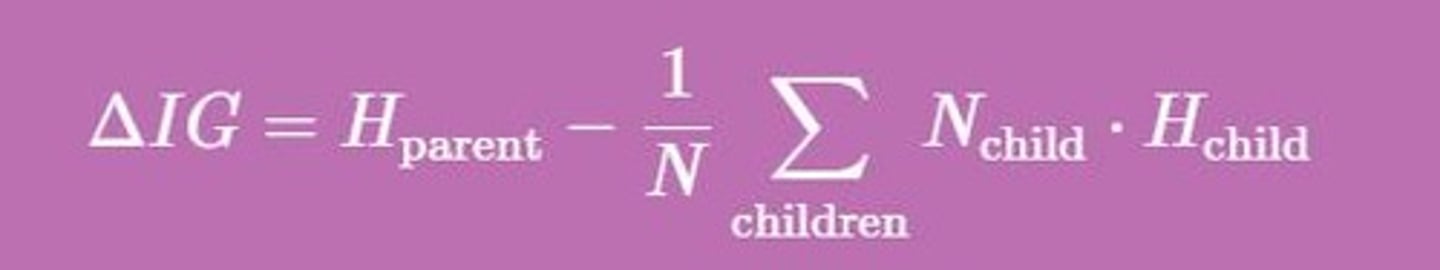
Entropy Value Range
Entropy ranges from 0 to log2(n).
Entropy Interpretation
Higher value indicates more uncertainty in data.
Sequential Decisions
Series of if-then rules for data classification.
Data Partitioning
Process of dividing data into subsets.
Weather Example
Entropy higher with 50% rain vs 100% rain.
Group A
70 smokers and 30 non-smokers.
Group B
85 smokers and 15 non-smokers.
Feature Split
Dividing data based on feature values.
Information Gain Example
Calculating IG for loan default prediction.
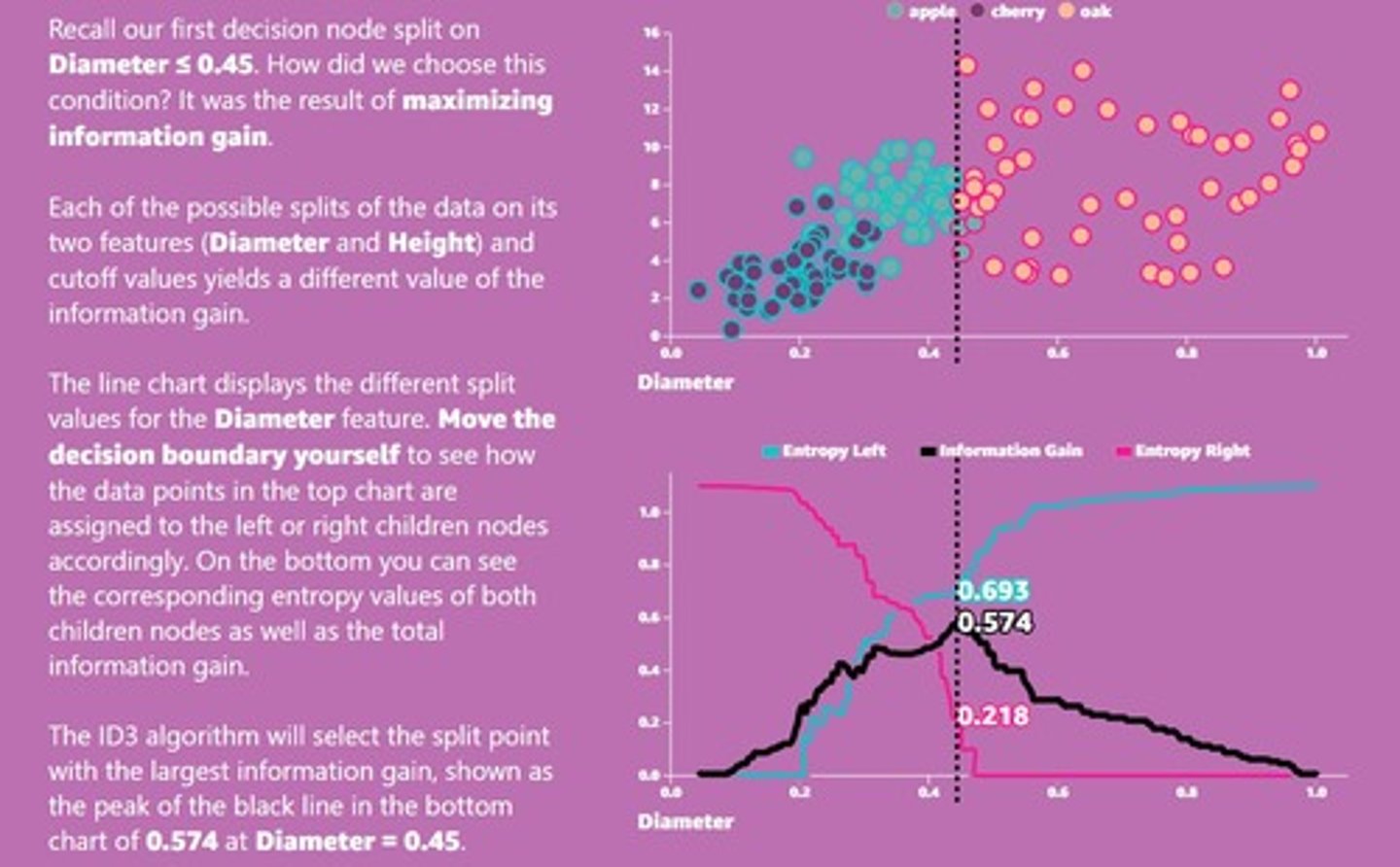
Numerical Feature Binning
Dividing numerical ranges into bins for splits.