ELEC 825 Week 9
1/23
Earn XP
Description and Tags
zero-shot learning, domain adaptation, and domain generalization
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
24 Terms
zero-shot learning (ZSL)
training a model that can classify objects of unseen classes (target domain) by transferring knowledge obtained from other seen classes (source domain) with the help of semantic information
generalized zero-shot learning (GZSL)
similar to ZSL but tries to recognize samples from both classes simultaneously rather than classifying only data samples of the unseen classes
why use generalized zero-shot learning?
fine-grained annotation of many samples is laborious and it requires an expert in domain knowledge
many categories lack sufficient labeled samples, especially if data is still in process of being created/observed
data samples of seen classes are often more
common than those from the unseen ones so we want to identify both at the same time
what are the training stages of GZSL?
inductive setting
transductive setting
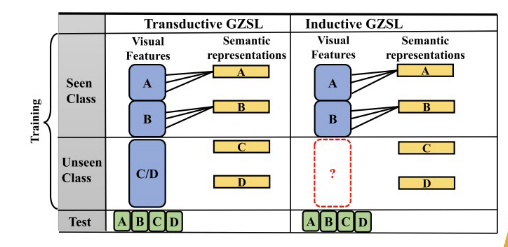
inductive setting
training stage of ZGSL that only has access to the visual features of seen (source) classes
transductive setting
training stage of ZGSL that has access to the visual features of seen (source) classes and the unlabelled visual samples of the unseen classes
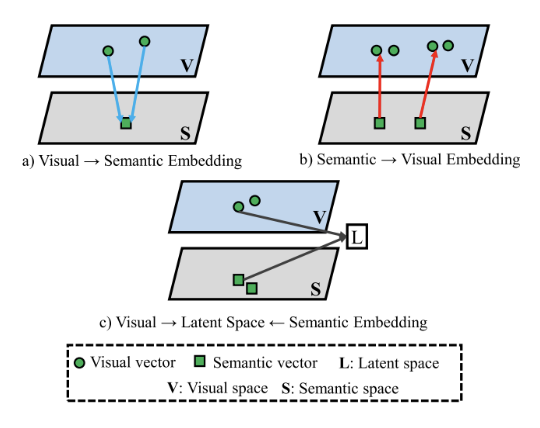
name 3 embedding spaces
visual → semantic embedding
semantic → visual embedding
visual → latent ← semantic embedding
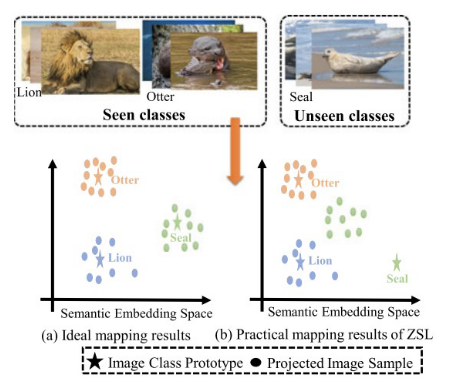
domain shift
distributions of data in the target domain differs from the source domain, which leads to poor model performance
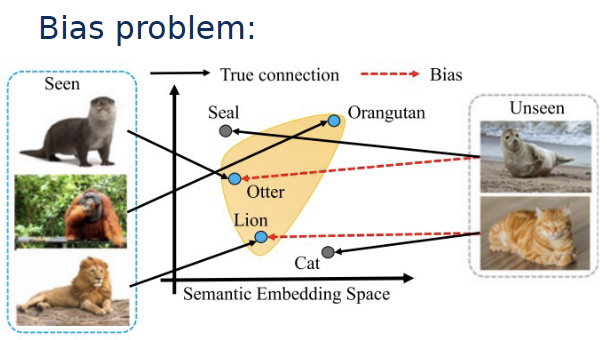
bias problem
model has an inherent bias towards seen classes and is more likely to classify data from unseen classes as belonging to one it knows
what issues are faced by GZSL/ZSL?
bias problem and domain shift
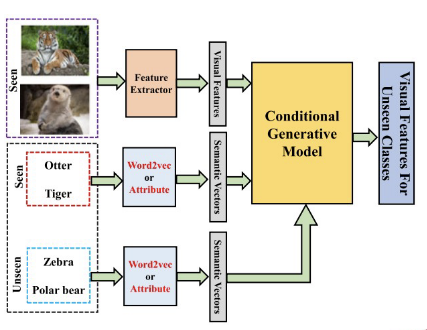
generative based methods
approach zero-shot learning by generating visual features for unseen classes
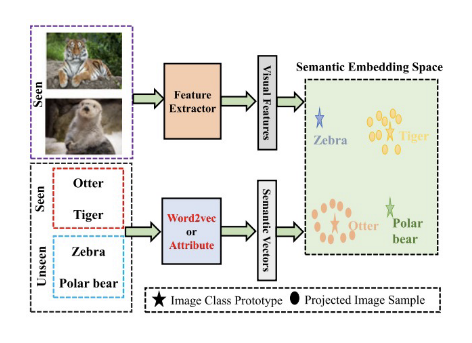
embedding based methods
approach zero-shot learning by learning a mapping function that embeds both seen and unseen classes into a common semantic space
domain adaptation
aims to adapt a model trained on one domain (the source) to perform well on a different, but related domain (the target)
why do we want domain adaptation?
addressing real-world diversity → in the real world, data comes with variability
cost-efficiency → collecting and labeling data for every possible scenario is expensive and impractical
supervised domain adaptation
requires labeled data in both the source and target domains, although the target domain typically has less labeled data
unsupervised domain adaptation
source domain has labeled data, but the target domain has only unlabeled data
what are the challenges in domain adaptation?
domain shift
lack of labelled data → in many target domains,
labeled data may be scarce or unavailable
complexity of adaptation → choosing the right
adaptation strategy often requires domain expertise
how can we overcome the challenges of domain adaptation?
transfer learning → techniques enable the use of pre-trained models that can be fine-tuned on the target domain, even with limited data
adversarial-based methods → use adversarial networks to learn domain-invariant representations
distance-based methods → minimize some measure of distance or discrepancy between the source and target domain distributions in a shared feature space
e.g. Maximum Mean Discrepancy (MMD), Kullback-Leibler (KL) divergence, Wasserstein distance
how does an adversarial network work?
discriminator tries to distinguish between source and target domains, while the feature extractor learns to confuse the discriminator
domain generalization
process by which a machine learning model is trained to generalize well to new, unseen domains

why do we want domain generalization?
in the real world, data can come from various distributions that are not available at the time of model training
we need robust models in applications like where it is impossible to collect comprehensive training data that covers all possible scenarios (e.g. medical diagnostics)
what are the challenges of domain generalization?
domain shift
models usually overfit to the source domains, i.e., they perform well on the source data but poorly on unseen target data
name some methods of domain generalization
Data-Centric Approaches
Data augmentation
Learning from multiple domains
Model-Centric Approaches
Invariant feature learning
Meta-learning
Adversarial learning
Algorithmic Approaches
Regularization techniques
Ensemble methods
what is the difference between domain generalization and domain adaptation?
domain adaptation fine-tunes a model to a new domain with some available data, while domain generalization prepares a model to be robust across any unseen domain without the need for target domain data