10. Scaling LLM Training II
1/3
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
4 Terms
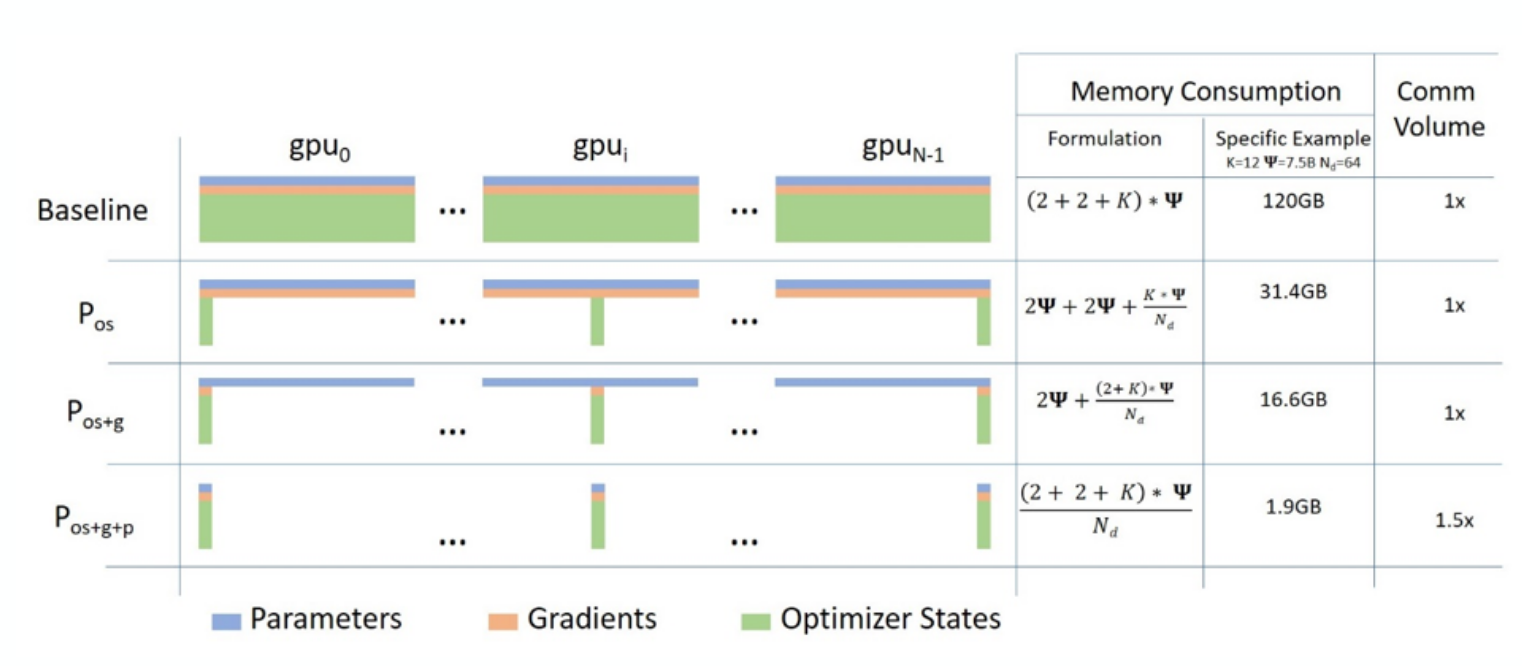
What is the idea of ZeRO Sharding?
Reduces memory redundancy when training on multiple GPUs.
Considers Parameters + Gradients + Optimizer States.
3 different levls - defines what to have on GPU.
=> Reducing memory redundancy increases need for communication between GPUs.
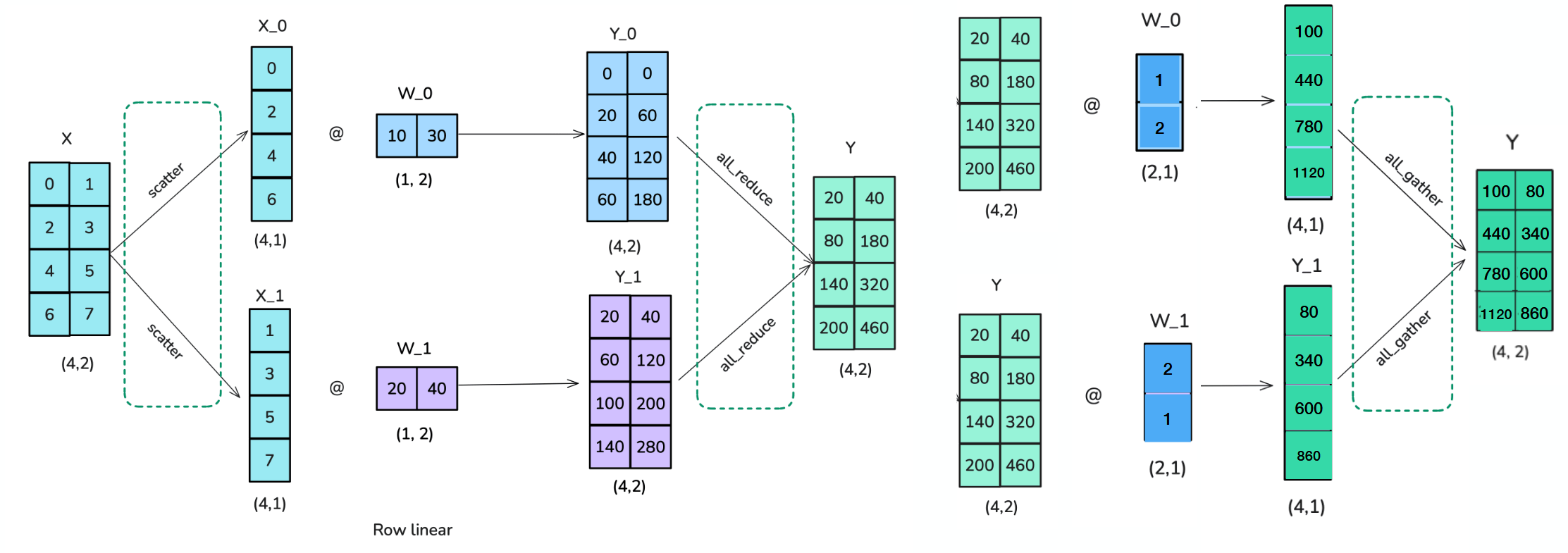
What is the idea of Tensor Parallelism?
Shard weight and activation tensors into groups that are executed on different GPUs.
Can be applied to Attention as well as Linear Layers.
=> However: Many more communications. Becomes issue when going beyond one node.
=> Also: Later operations like dropout or layernorm require unsharded activations.
What is the idea of Ring Attention?
Standard attention layer prevents sequence parallelism, as it requires all tokens to interact.
In Ring Attention GPUs compute own portion of causal mask and then communicate keys and values to next GPU.
=> Drastically increases possible sequence length (context window).

Placeholder
Placeholder