Data management and analytics Clare notes python
1/79
Earn XP
Description and Tags
pour ma liefje
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
80 Terms
Give the definition of Moore’s Law
States that the number of transistors in ICs has doubled approximately every two years. This improves a computer’s ability to collect, process, and store data.
Give the definition of big data
The emergence of large, complex datasets for which traditional data processing approaches are inadequate. It is a result of the exponential growth of digital information.
When are unsupervised problems used and when are supervised problems used?
Unsupervised: used when there is no specific purpose or target. The goal is often to see if data points naturally fall into different groups. These tasks are considered exploratory, and the results are not guaranteed to be meaningful.
Supervised: used when a specific purpose or target is defined. For example, finding customers who are likely to cancel their contracts. These tasks require having data on the target itself.
What are the 6 crucial steps of the data mining / analytic process?
Business understanding
Data understanding
Data preparation
Modeling
Evaluation
Deployment
Explain business understanding and it’s goal
The initial phase focused on understanding the project objectives and requirements from a business perspective.
Goal: Translate business goals into a data mining problem definition and create a preliminary plan.
Explain data understanding and it’s activities
Involves initial data collection and activities to get familiar with and understand the data.
Activities: Identify data quality problems, discover initial insights, estimate costs/benefits of data sources, and form hypotheses.
Explain data preparation and it’s activities
The phase that covers all activities to construct the final dataset for modeling from the initial raw data.
Activities: Includes table, record, and attribute selection, as well as the crucial steps of data transformation and cleaning.
Explain the modeling phase and what is it’s output?
The phase where various modeling techniques are selected and applied.
Output = A model, which is a pattern that captures regularities in the data.
Explain why evaluation is important
A critical step to assess the model and ensure the results are valid and align with the business objectives defined in the first phase.
Explain the deployment stage and what is it’s output?
The final stage where the model and the knowledge gained are integrated into the business process. This is rarely the end of the project.
Output: Can range from a simple report to a complex, repeatable data scoring system used in day-to-day operations.
What are properties for the File Processing System
Each department has its own set of files, leading to data redundancy, inconsistency, poor security, and isolated data. (The old way)
What is different when using the Database Approach instead of the File Processing System?
Uses a single repository to maintain data, which is defined once and accessed by various users.
Give the advantages of databases over flat files:
1. Databases offer more persistency & durability.
2. More efficient structure for storing and searching data.
3. Concurrency – multiple users can access / modify data simultaneously without interference.
4. Consistency – Provides rules to protect data integrity.
5. Offers a flexible query language (e.g. SQL) for complete data retrieval.
What problems does a database adress?
Redundancy: duplicated copies.
Inconsistency: multiple / concurrent updates.
Integrity: enforcing constraints.
Incompatibility: multiple format.
Inflexibility: hard to apply changes.
Insecurity: unauthorised access
What is the Database Management System? (DBMS)
A software package or system used to manage databases. It facilitates Defining, Constructing, Manipulating, and Sharing data.
What is the Database System?
The database and the DBMS software together.
What is Metadata
“Data about data”. The description of the database structure, types, and constraints, stored in the database catalogue. This makes the database system self-describing. It provides context and details about a dataset, file or resource.
What is Data Abstraction / Program-Data Independence
The structure of the data (meta-data) is stored separately from the access programs meaning that the internal structure of the data can change without affecting the programs that use it.
What is a transaction in this context?
An atomic unit of processing. It’s a program/process that reads or writes data. All transactions must have ACID properties.
What are the 4 ACID Properties?
Atomicity =>The transaction executes in its entirety or not at all. It's an "all or nothing" operation.
Consistency => A transaction, when executed in isolation, moves the database from one valid (consistent) state to another.
Isolation => Concurrent transactions should not interfere with each other. The result should be the same as if they were executed serially.
Durability (or Persistency) => The effects of a successfully completed transaction must be permanent and not be lost due to a system failure.
What is a Data Model?
A collection of concepts for describing data, its relationships, and its constraints. It is a form of data abstraction.
What are the 3 types of data models?
1. High-level (Conceptual) => Concepts are close to how users perceive data (e.g., Entity-Relationship model).
2. Low-level (Physical) => Describes the details of how data is stored on disk.
3. Representational => An intermediate model that is understandable to end-users but also not too far from the physical storage.
Shortly explain the Relational Model
Proposed by Tedd Code. Represents a database as a collection of relations.
What is a Relation in context of the relational model?
A table of values
What is a Tuple?
A row in a table, representing a single entity or record.
What is an Attribute
A column in a table, representing a property of the entity.
What is a Domain
The set of permissible, atomic
What does a Relation Schema contain?
The name of the relation and its list of attributes:
RELATION_NAME(Attribute1, Attribute2, …)
Degree (or Arity)
The number of attributes in a relation.
What is the Relation State?
The set of tuples in a relation at a specific point in time. The DBMS ensures every state is valid by enforicing constraints.
What is a NULL Value
Represents a value that is unknown, not applicable, or not specified. It is important to know that in comparisons, NULL is considered different from every other NULL value.
What are Relational Integrity Constraints?
These are rules that must hold on every valid relation state. They ensure data accuracy, consistency and reliability in a relational data base.
What is a Domain Constraint?
The value of each attribute in a tuple must be an atomic value from its defined domain.
What are Implicit Constraints
Restrictions or rules that inherent in the data model. (Often not explicitely defined but understood or implied by the nature of the problem or solution)
What are Explicit Constraints
Rules that can be expressed in the schema of the data model (Integrity constraints)
What are Semantic Constraints?
Rules that cannot be explicitly expressed in the scheme. Enforced by the application program. (e.g., cleaning fee cannot be higher than booking price).
What are Key Constraints?
Rules that ensure unique identification of tuples.
What is a Superkey?
An attribute or a set of attributes whose values uniquely identify each tuple in a relation. The set of all attributes is always a superkey.
What is a Key (in terms of a superkey)?
A minimal superkey. A superkey from which no attribute can be removed while still maintaining the uniqueness property.
What is meant with a Candidate Key?
Any of the possible keys of a relation. Relations can have more than one.
What is the Primary Key (PK)
The one candidate key that is chosen to be the main identifier for tuples in a relation.
What is the Entity Integrity Constraint?
It is the rule that states the primary key attributes cannot have NULL values. This is because the PK is used to identify each tuple uniquely.
What is the Referential Integrity Constraint?
It maintains consistency between tuples in two relations. (It ensures that relationships between tables remeen consistent.)
What is a Foreign Key (FK)
An attribute (or set of attributes) in one relation that refers to the Primary Key of another (or the same) relation.
What is The Rule in the context of constraints?
The value of a Foreign Key in a tuple must either math the value of a primary key in some tuple of the referenced relation and be NULL.
What are the 3 basic operations of SQL that change the state of the relations in the database?
1. Insert – insert one or more tuples in a relation
2. Update – change the value of some attributes in existing tuples.
3. Delete – delete tuples
What does the JOIN SQL operation do?
It combines rows from two or more tables into a single result set. This combination is based on a join condition that specifies how the tables are related, typically by matching values in a common column (like a foreign key in one table and a primary key in another).
What is the difference between INNER JOIN, LEFT OUTER JOIN, RIGHT JOIN and FULL OUTER JOIN, and what do they do?
INNER JOIN => Returns only the set of records that have matching values in both tables being joined. It represents the intersection of the two tables.
LEFT OUTER JOIN (or LEFT JOIN) => Returns all records from the left table, along with the matched records from the right table. If there is no match for a record from the left table, the columns of the right table will contain NULL values in the result set.
RIGHT JOIN => Returns all records from the right table, along with the matched records from the left table. If there is no match, the columns of the left table will be NULL.
FULL OUTER JOIN => Returns all records when there is a match in either the left or the right table. It effectively combines the results of both a LEFT JOIN and a RIGHT JOIN.
What are the limitations of RDMBS for Big Data
Difficulty to Scale
Difficulty with Unstructered Data
Inefficient Search
Inefficient Computation
What is NoSQL and what are its key characteristics?
Class of databases that provides mechanisms for storage and retrieval of data that is modelled differently than the tabular relations used in RDBMS (Relational Database Management Systems)
Key characteristics:
- Designed for distributed storage and computation.
- Can handle Big Data efficiently.
- Rose in popularity in the early 200s, driven by the needs of Web 2.0 companies like Google and Amazon
What is a Key-Value Store and its characteristics?
simplest NoSQL data model where data is represented as a collection of key-value pairs, similar to a dictionary or hash map. Each data record (value) is stored and retrieved using a unique key.
Characteristics:
- Schema less (doesn't require a predefined schema like relational databases)
- Memory inefficient
- The value can be a simple type or a complex object with its own internal fields.
What is a Document Store and it’s characteristics?
Type of NoSQL database designed for storing, retrieving, and managing document-oriented information (semi-structured data). Data and its associated metadata are encapsulated into "documents," which are identified by a unique key (e.g., _id). These documents are typically stored in standard formats like JSON, BSON, or XML.
Characteristics:
- Flexible scheme
- Subclass of key-value: can be seen as a key-value store, but with a key difference: the database understands the structure of the value (the document), allowing it to be queried.
What is a Column store?
Database that stores data in columns rather than rows
What is a Graph database and it’s characteristics?
A database that uses graph structures with nodes (entities) and relationshsips (or edges) to represent and store data.
Characteristics:
- Relationship focused
- Easy traversal
- Applications: social networks, recommendation engines, fraud detection network.
What is Scalability?
The capability of a system, network, or process to handle a growing amount of work by increasing its output when more resources are added.
What are the 2 methods of scaling?
1. Vertical scaling (scale-up) => increasing the resources (CPU, RAM, Disk) of a single server. This is the traditional approach but is limited and expensive.
2. Horizontal scaling (scale-out) => adding more computers (nodes) to a system to distribute the load. This is the preferred method for Big Data.
What is Distributed Scale-Out Architecture?
Architecture where multiple computers communicate over a network, sharing resources to achieve a common goal. Most NoSQL databases are designed for this.
What are the advantages of Distributed Scale-Out Architecture?
Scalability
Reliability
Speed
Cost
What are the disadvantages of Distributed Scale-Out Architecture?
Responsibility Shift - The responsibility for ensuring a safe environment (transactions, consistency) is transferred from the DBMS to the developer.
No ACID Transactions
Less Expressive Queries
What does BASE stand for?
Basically Available, Soft State, Eventual consistency
What does Basically available stand for in BASE?
The system stays operational even if nodes fail. It guarantees a response to every request (though the response might be a failure or stale data).
What does Soft State stand for in BASE?
The state of the system may change over time, even without new input, as it works towards consistency.
What does Basically available stand for in BASE?
The system will eventually become consistent once all inputs have been processed. Data will be replicated to all nodes, but this may take time.
What is the CAP Theorem?
fundamental theorem for distributed systems which states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
1. Consistency: Every read receives the most recent write or an error. All nodes see the same data at the same time.
2. Availability: Every request receives a non-error response, without the guarantee that it contains the most recent write. The system is always up.
3. Partition Tolerance: The system continues to operate despite an arbitrary number of messages being dropped or delayed between nodes (i.e., a network failure).
The trade-off is that in a distributed system, network partitions are a fact of life, so Partition Tolerance (P) is mandatory. Therefore, a system must choose between strong consistency and high availability.
What is the method of Direct Data and what is the process?
most straightforward method, involving the direct download of documents or files from a source.
Process:
Download the data file from the source (e.g., a government open data portal).
The data is typically in a standard format like CSV, TXT, or XLS.
Upload the data into your own database for analysis.
What is the method of Application Programming Interface (API) and what is the process?
A consistent, programmatic method for accessing a resource. Web APIs act like web addresses (endpoints) that are built to perform a specific task when requested. They allow a program to directly ask for data without the presentational overhead (i.e., the visual website) of normal user interfaces.
Process:
A program (the client) sends a request for data to an application's API endpoint.
The application (the server) sends back the requested data as a response, typically in a machine-readable format like JSON or XML.
When should we use an API?
When the data is changing quickly (e.g., stock prices, social media feeds).
When you only want a small piece of a much larger dataset.
When there is repeated computation that the API can handle for you.
What is the method of Web Scraping and what is the process?
Process of programmatically sifting through a web page to gather needed data and preserve its structure, especially when the data is not provided in a practical format like CSV or via an API.
Process:
Fetch Content: Use a library (like Python's requests) to access the HTML page on a website and retrieve its full HTML content.
Extract Data: Use a parsing technology (like XPATH) to navigate the structured HTML document and create a query that automatically retrieves the specific data of interest.
What is the definition of Supervised Methods?
Techniques that work towards a specific purpose by using a dataset where a predefined target variable is specified. The goal is to predict this target for new, unseen data.
What is the definition of Unsupervised Methods?
Techniques used when there is no specific target variable. The goal is to derive structure from the input data itself, such as looking for relationships or grouping similar instances.
e.g. clustering customers into natural groups based on their buying habits.
Give the 2 main supervised tasks.
1. Classification – involves a categorical target. The model predicts which of small set of classes an instance belongs to.
2. Regression – involves a numerical target. The model predicts a continuous number value for an instance (e.g., price of a product, amount of rainfall).
What is Generalisation and what is Induction?
Generalisation is the fundamental goal in supervised learning. The model must learn general rules from the training data that allow it to make accurate predictions on new, unseen data. This process of deriving general rules from specific examples is called induction.
What is the Inductive Bias?
It is the set of assumptions a learning algorithm uses to make predictions on data it has not yet seen.
What is the Hypothesis Space?
The set of all possible functions that a model can represent.
What is entropy and what does high entropy and low entropy mean?
Measure of impurity, uncertainty, or disorder in a set of examples.
High Entropy (max 1) – High uncertainty. The set is evenly split between classes.
Low Entropy (max 0) – Low uncertainty. The set is pure; all instances belong to one class.
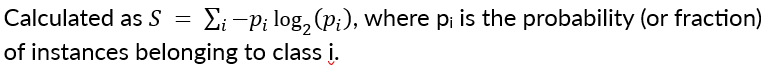
What is the Information Gain?
The measure of the decrease in entropy after a dataset is split on an attribute. It quantifies how much information an attribute gives us about the class. We choose the attribute that provides the maximum information gain (i.e., the one that reduces uncertainty the most).
How does the ID3 algorithm work?
1. Start with the entire training set (the root node).
2. Calculate the Information Gain for every possible attribute.
3. Split the set into subsets using the attribute that provides the maximum Information Gain.
4. Make a decision tree node containing that attribute.
5. Recurse on the subsets using the remaining attributes.
The recursive splitting process stops at a node when one of the following occurs:
1. The node is pure – every instance in the subset belongs to the same class.
2. No more attributes to select – all attributes have been used. In this case, the leaf is labelled with the most common class of the examples in the subset.
3. No instances in the subset – this can happen if no training instances matches a specific path.
Explain Overfitting
occurs when a model learns the training data too well, including its noise and random fluctuations. The decision tree learning process, by aiming to minimize impurity, has a natural tendency to build large, complex trees that perfectly fit the training data but fail to generalize to new, unseen instances.
What are some solutions to overfitting?
Limiting tree growth, stop growing when a split is not statistically significant or growing the full tree first, then pruning subtrees that do not provide significant predictive power.