nucleic acid and dna replication
1/16
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
17 Terms
structure of nucleotides
nucleic acids are a class of biomolecules, and there are two types of nucleic acids:
DNA ⇒ deoxyribonucleic acid
RNA ⇒ ribonucleic acid
nucleic acids are polymers made from monomers known as nucleotides
a nucleotide is made up of 3 components: a phosphate group (gives acidic character and negative charge), a pentose sugar (5 carbon sugar and a nitrogenous base)
formed via a condensation reaction ⇒ removes two water molecules
pentose sugar is bonded to a nitrogenous base at carbon 1
phosphate group is bonded to the pentose sugar molecule at carbon 5
DNA and RNA differ in the type of pentose they contain
ribose (RNA): carbon 2 is attached to a hydroxyl group (-OH)
deoxyribose (DNA): carbon 2 is attached to a hydrogen atom → due to absence of OH group at carbon 2 in deoxyribose sugar, DNA is less reactive than RNA
there are 5 different types of nitrogenous bases found in nucleic acids → classified as purines or pyrimidines
purines → 2 rings
adenine (A), guanine (G)
pyrimidines → 1 ring
thymine (T) [in DNA only], cytosine (C), uracil (U) [in RNA only]
structure and formation of polynucleotides
nucleic acids are formed by joining nucleotides together
-OH group on carbon 3 of pentose sugar of a nucleotide
phosphate group on carbon 5 of pentose sugar of an adjacent nucleotide
via condensation reaction
bond formed ⇒ phosphodiester bond
addition of many nucleotides produces a long polynucleotide chain/strand with a backbone of alternating sugar and phosphate groups and bases projecting sideways from the sugars
the two ends of a polynucleotide chain are different from each other ⇒ polynucleotide chains have directionality along its sugar phosphate backbone, from 5’ to 3’
5’ end: a free phosphate attached to a carbon 5 of a pentose sugar
3’ end: a free hydroxyl group on a carbon 3 of a pentose sugar
each polynucleotide strand consists of only 1 type of monomer→ DNA or RNA
structure of DNA
each DNA molecule is made up of 2 strands of polynucleotides
each polynucleotide strand is made up of deoxyribonucleotides joined by phosphodiester bonds
2 strands of polynucleotides are wound to form a double helix
two strands are anti-parallel (i.e. opposite directions) to each other ⇒ 5’→3’ direction for one strand, 3’→5’ direction for the other strand
one complete turn of DNA double helix consists of 10 base pairs → distance of 3.4nm
sugar-phosphate backbone of each strand is on the exterior of the helix, while the nitrogenous bases are paired in the interior of the helix
the winding of the molecule creates major and minor grooves
DNA molecule has a uniform width of 2 nm ⇒ the width of a base pair, consisting of the width of a purine and a pyrimidine
hydrogen bonds between complementary bases hold the two chains together
2 hydrogen bonds between Adenine and Thymine
3 hydrogen bonds between Cytosine and Guanine
since the two strands are complementary to each other, the ratio is
A : T = 1 : 1
G : C = 1 : 1
Purines (A+G) : Pyrimidines (T+C) = 1:1
hydrophobic interactions between stacked nitrogenous bases stabilises the double helix
structure-function relationship of DNA
DNA function as genetic material that is passed from one generation of cells to the next (hereditary material), the structure of DNA must allow for:
accurate DNA replication and DNA repair
structure
function
double helix consisting of 2 strands
each DNA parental strand acts as a template for the
• synthesis of the daughter strand ⇒ ensures accurate
replication so that the daughter cells have identical DNA molecules as the parental cell
• proofreading and repair of damaged strand if mutation occurs, so that the DNA sequence can be maintainedstability of hereditary material to remain unchanged
structure
function
antiparallel strands
allows many hydrogen bonds to form between complementary bases, and hold the two polynucleotide chains together
complementary base pairing between purines and pyrimidines
• hold two polynucleotide chains together
• ensure a constant width of 2.0nm maintaining a stable structure
• stable structure maintains DNA sequence throughout the lifespan of cell
• allow each strand to act as a template during DNA replication → (a)(i)stacked nitrogenous bases
hydrophobic interactions formed between stacked bases
stabilises structure of double helixdeoxyribose sugar in DNA nucleotide
less chemically reactive and more resistant to hydrolysis. ⇒ DNA sequence is maintained
phosphodiester bonds between adjacent nucleotides within each strand
strong covalent bonds stabilise structure of the double helix
DNA also functions to store genetic information for gene expression
structure
function
sequence of bases forms genes
• code for functional gene products (e.g. polypeptide, tRNA, rRNA)
• either strand acts as a template for the synthesis of RNA via complementary base pairingmajor and minor grooves formed from winding of DNA molecule
major grooves allow for binding of proteins (transcription factors) that regulate gene expression
semi-conservative DNA replication
process by which a double-stranded DNA molecule is copied to produce two identical DNA molecules
sequence of the bases is the same
[FAQ] semi-conservative because:
after hydrogen bonds between bases break and 2 parental strands separate,
each parental DNA strand is used as template to synthesize a new daughter strand
each new DNA molecule is a hybrid of 1 parental strand and 1 daughter strand
before mitosis or meiosis, the doubling of DNA content needs to occur during S phase of interphase in eukaryotes
mitosis: the doubling ensures that daughter cells has identical copies of DNA and thus are genetically identical to the parental cells
before DNA replication begins → during G1 phase of interphase
the following materials are imported from the cytoplasm into the nucleus via the nuclear pores
free deoxyribonucleotides ⇒ provided as nucleoside triphosphates e.g. ATP, GTP, CTP, TTP → these are also known as activated nucleotides (bases attached to phosphate groups)
free ribonucleotides ⇒ to form RNA primers
enzymes → helicase, primase, DNA polymerase, ligase
ATP
DNA replication begins at sites on the DNA known as origin of replication
prokaryotes: one origin of replication
eukaryotes: many origins of replication
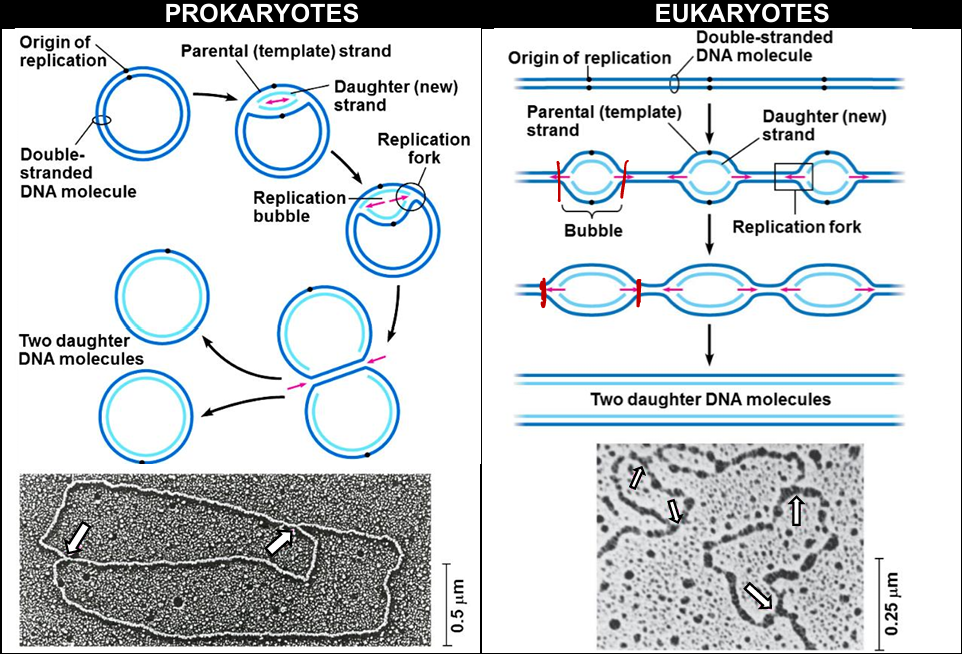
separating the double helix → dna replication
helicase binds to DNA molecule at the origin of replication, and disrupts hydrogen bonds between complementary bases
helicase separates/unzips parental strands
single-strand binding proteins stabilize the unwound helix and prevent rewinding of double helix
a replication bubble with two Y-shaped replication forks are formed
replication proceeds in BOTH directions (bidirectional) from the origin until the entire DNA molecule is replicated
synthesis of RNA primers → dna replication
primase synthesises RNA primer using free ribonucleotides (RNA) in the 5’→3’ direction [DNA template is read in the 3’ to 5’ direction]
occurs via complementary base pairing with the parental strand which acts as a template
[FAQ] why are primers needed for DNA synthesis?
DNA polymerase cannot initiate DNA synthesis but can only add deoxyribonucleotide to free 3’-OH end of an
existing strand in 5’→3’ directionthis is because shape of DNA polymerase active site is complementary to shape of 5’ phosphate group of in-coming nucleotide and 3’-OH of the last nucleotide of growing daughter strand
therefore, primers (short chains of ribonucleotides) provide free 3’-OH end for DNA polymerase to add deoxyribonucleotides
synthesis of daughter DNA strands → dna replication
DNA polymerase reads template strand in the 3’→5’ direction and synthesizes daughter strand in the 5’→3’ direction
free deoxyribonucleotides complementary base pairs with template strand:
adenine base pairs with thymine, and vice versa (A=T)
cytosine base pairs with guanine, and vice versa (C≡G)
phosphodiester bonds are formed between adjacent deoxyribonucleotides via condensation reactions
DNA polymerase also proofreads as it synthesises the daughter strand
if a nucleotide in the daughter strand is wrongly paired with template, the DNA polymerase will remove and replace with correct nucleotide
leading and lagging strands → dna replication
since the 2 parental strands are anti-parallel, the 2 daughter strands (leading and lagging strands) are synthesized in the opposite direction by DNA polymerases
leading strand is synthesised continuously towards the replication fork
only one primer is needed at the origin of replication
DNA polymerase adds new nucleotides in the 5’ →3’ direction without any breaks
lagging strand is synthesised discontinuously as Okazaki fragments away from the replication fork
as helicase separates DNA strands at the replication fork to expose the DNA templates, new primers will be synthesised by primase
DNA polymerase will add free nucleotides to the primer in the 5’ → 3’ direction, thus forming the Okazaki fragment
the overall direction of replication is still towards the replication fork as helicase separates the double-stranded DNA molecule
[FAQ] why is one daughter strand synthesized continuously while the other synthesized discontinuously?
the two parental strands are anti-parallel
synthesis of daughter DNA strands always starts at the origin of replication
DNA polymerase can only add deoxyribonucleotides to free 3’-OH end of an
existing strand in 5’→3’ directiontherefore, DNA polymerase can only synthesise daughter strand in the 5’ to 3’ direction
leading strand is synthesized towards the replication fork
lagging strand is synthesized as Okazaki fragments away from replication fork
before they are joined together by phosphodiester bonds
replacement of RNA primers with DNA → dna replication
another DNA polymerase replaces the RNA primers with deoxyribonucleotides
DNA ligase seals the gaps (nicks) between the Okazaki fragments by catalysing the formation of phosphodiester bonds between them
at the end, two DNA molecules are formed
each DNA molecule consists of 1 parental strand and 1 daughter strand, which will wind to form a double helix → semi-conservative
after DNA replication
after DNA replication, proteins (histones) associate with the DNA and package to form chromatin
through multiple levels of packing, DNA can fit into the small space in the nucleus
process of dna replication for both prokaryotes and eukaryotes
process of DNA replication is generally the same for both prokaryotes and eukaryotes
prokaryotes
eukaryotes
when DNA replication occurs
prior to binary fission
S phase of interphase
location
cytosol
nucleus
DNA molecule structure
single circular
multiple and linear
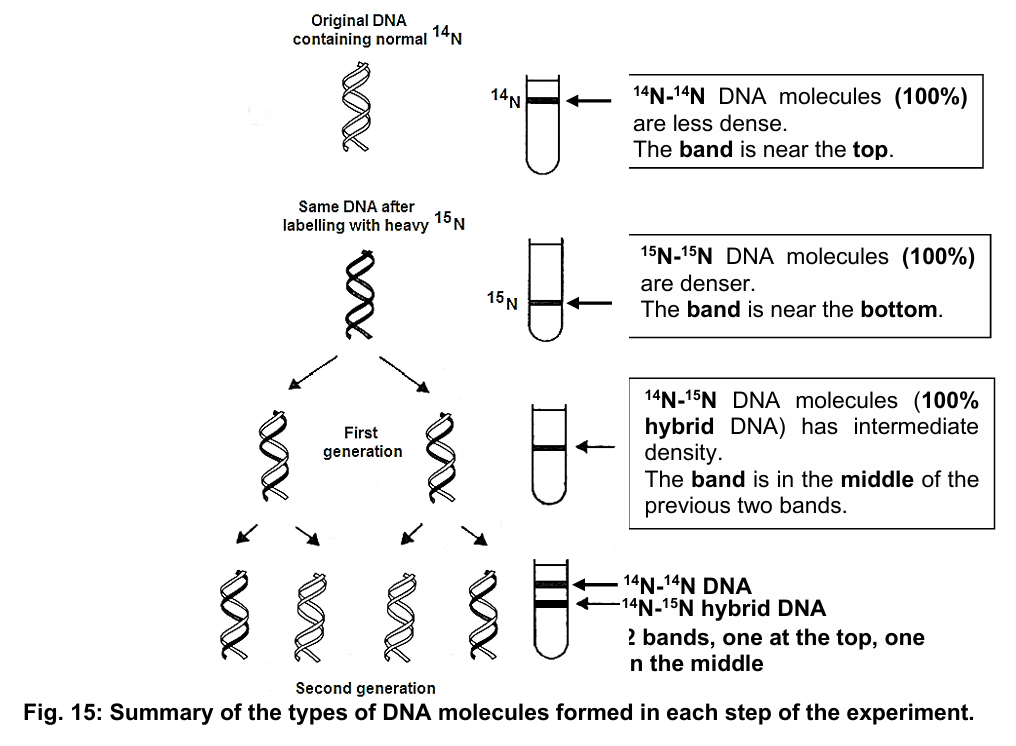
evidence for semi-conservative replication
generation zero cells:
100% 15N-15N DNA
first generation cells:
DNA from first generation cells (grown in 14N medium) forms one band between pure 15N-15N
DNA and pure 14N-14N DNA (14N-14N) in caesium chlorideit supported semi-conservative replication → all DNA (100%) of the “first generation cells” was hybrid ⇒ one 14N strand and one 15N strand
second generation cells:
half (50%) was hybrid 14N-15N DNA, half (50%) was pure 14N-14N DNA
results confirmed semi-conservative model
as bacteria continue to grow in the 14N-containing medium, DNA band with 14N-14N DNA molecules will be thicker, because the percentage of 14N-14N DNA molecules keep increasing in
subsequent generationspercentage of 14N-15N DNA molecules decreases in subsequent generations, this hybrid DNA molecules will always be present due to semi-conservative replication hypothesis
end replication problem
limitations in the DNA polymerase create problems for linear DNA in eukaryotes
DNA polymerase can only add free deoxyribonucleotides to an existing 3’ –OH group
what is the end replication problem
it is the shortening of DNA molecule after each round of DNA replication
this is due to a gap at the 5’ end of the daughter strand after removal of RNA primer located at the 5’ end of daughter strand
the RNA primer cannot be replaced with DNA nucleotides because there is no existing 3’–OH group available [since is the end of the strand] for DNA polymerase to add
deoxynucleotidesas DNA polymerase can only add deoxyribonucleotides to an existing 3’ –OH group
![<ul><li><p>it is the shortening of DNA molecule after each round of DNA replication</p></li><li><p>this is due to a gap at the 5’ end of the daughter strand after removal of RNA primer located at the 5’ end of daughter strand</p></li><li><p>the RNA primer cannot be replaced with DNA nucleotides because there is no existing 3’–OH group available [since is the end of the strand] for DNA polymerase to add<br>deoxynucleotides</p></li><li><p>as DNA polymerase can only add deoxyribonucleotides to an existing 3’ –OH group</p></li></ul><p></p>](https://assets.knowt.com/user-attachments/4ccf61cf-c263-4f92-8cf0-ded0414a5656.png)