Machine Learning Review Questions Week 10
1/75
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
76 Terms
What is deep learning?
Deep learning is a subset of machine learning that utilizes artificial neural networks with multiple layers to process data. It enables computers to learn complex patterns and make predictions based on large datasets, much like the human brain.
What are some applications of deep learning?
Medical image analysis, object recognition for self-driving cars, natural language processing, and robotics.
What is the main difference between traditional machine learning and deep learning?
In traditional ML, features are manually extracted from the data, and the model is trained.
In deep learning, the data is fed into the system, features are extracted, and the model is learned.
What primary function do V1 brain cells perform, and how does this relate to the function of early layers in a convolutional neural network (CNN)?
V1 cells primarily detect locally oriented edges and features in visual input. This is analogous to the early layers of a CNN, which also extract fundamental features, such as edges and textures, through convolution operations.
What are the main types of machine learning models?
Supervised
Unsupervised
Reinforcement.
What is reinforcement learning?
Reinforcement learning (RL) is a type of machine learning in which an agent learns to make decisions by interacting with an environment, receiving rewards for positive actions and penalties for negative ones.
What are the key components of a reinforcement learning system?
An agent, an environment, a state, an action, and a reward.
Which of the following is NOT listed as a main type of machine learning model?
B) Feature Maps
Which activation function is primarily used when a model needs to output
probabilities for multiple classes that sum to one?
C) Softmax
What is representation learning?
Representation learning is a category of methods that automatically extract meaningful patterns from raw data. They allow the model to learn its features instead of relying on manual feature engineering.
Name five activation functions.
Sigmoid,
Tanh,
ReLU,
Leaky ReLU,
Softmax
Is ReLU piecewise linear? Explain your answer.
ReLU is a piecewise linear function that consists of two linear pieces: one that cuts off negative values, where the output is zero, and one that provides a continuous linear mapping for non-negative values.
What are the sigmoid, tanh, and ReLU gradients? Which one could cause a vanishing gradient?
The following diagram shows the gradients of three activation functions. The vanishing gradient is avoided by using ReLU, as the gradient remains at 1 when the neuron is active. When we use sigmoid or tanh, we observe that the gradient can be zero even when the neuron is active, which can cause a vanishing gradient.
How does ReLU help sparsity of activation?
ReLU promotes sparsity of activation by setting any negative input to zero, essentially "turning off" a significant portion of neurons in a neural network. This would result in a sparse representation where only some neurons are actively firing, making the network more efficient and less prone to overfitting.
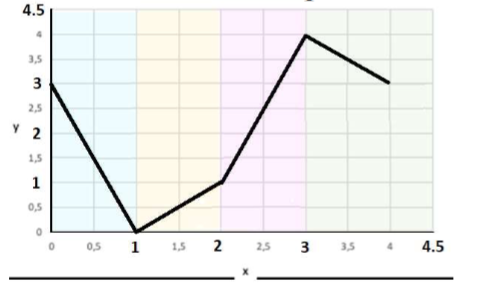
How can we produce the following non-linear output in a neural network?
This output is nonlinear, while it is piecewise linear. We can use a single hidden layer with four neurons, each having a ReLU activation function. Then, a neuron in the output layer combines them and produces this piecewise linear shape.
Each neuron has one input, x, and one w parameter and a bias, b.
What is the primary purpose of the softmax activation function?
The softmax function converts a vector of the last hidden layer into a probability distribution, where each value represents the probability of a particular class.
In what machine learning problem is the softmax function commonly used?
The softmax function is commonly used in multi-class classification problems, where the goal is to assign an input to one of multiple possible categories.
Lasso (L1) regularization is generally preferred when the goal is to:
B) Select a small subset of essential features.
Which concept is mentioned as a difference between CNNs and MLPs?
D) Local receptive field
Which of the following is an activation function?
C) Leaky ReLU
When is L2 regularization (Ridge) typically used?
B) To stabilize the model by shrinking all coefficients slightly.
Which type of machine learning model learns from labeled data to make predictions?
C) Supervised learning
Data augmentation is used primarily to:
C) Prevent overfitting by increasing data diversity.
Among CNNs and MLPs, which one has a "local receptive field"?
B) CNNs
If the softmax activation function is deployed, what type of loss is typically
used?
C) Cross-Entropy Loss
What is a key characteristic of the output values produced by the softmax
function?
The output values of the softmax function are all between 0 and 1, and they sum up to 1, representing a valid probability distribution.
Why is the derivative of the softmax function important in neural network
training?
The derivative is essential for backpropagation, updating the network's weights during training. It allows the network to learn by calculating the gradient of the loss function with respect to the weights.
What type of loss is used when softmax is deployed?
Cross entropy is used, hence we need to find the log of the softmax.
Our dataset consists of three classes. We use a neural network that has three neurons in its output layer. The final hidden layer produces f1, f2, and f3. We use the SoftMax activation function in the output layer, which produces s1, s2, and s3.
Please answer the following questions for this scenario. What is the cross-entropy loss for class 2?
The cross-entropy loss is log(s2).
What is an adaptive learning rate, and provide an example?
An adaptive learning rate is a method that dynamically adjusts the learning rate during neural network training. This helps optimize convergence by tailoring the learning rate to the specific characteristics of the data and the learning process. For example, AdaGrad adapts the learning rate by dividing it by the square root of the accumulated squared gradients. Hence, the rate keeps reducing as the gradient of the loss converges to zero.
Which training method is better, batch processing or stochastic gradient
descent (SGD)?
When considering training methods, Stochastic Gradient Descent (SGD) is generally favored, especially for large datasets. SGD is much faster because it updates the model's parameters using just one data point at a time, making it highly efficient. Batch processing, conversely, requires going through the entire dataset for each update, which can be very slow. A common compromise is mini-batch gradient descent, which updates parameters based on small subsets of data. This offers a balance between SGD's speed and batch processing's stability, often proving to be the most practical approach.
Briefly explain the two primary regularizing methods.
In the L1 (Lasso) method, the sum of all absolute values of parameters is added to the training loss. In the L2 (Ridge) loss, the sum of squares of the parameters is added to the loss.
When do we use L1 and when L2 regularization?
Lasso (L1) is generally better when we need to select a small subset of essential features from a large set of variables (feature selection).
Ridge aims to stabilize the model by shrinking all coefficients slightly.
What is data augmentation, and why do we use it?
Augmentation is a technique where we artificially increase the size and diversity of a training dataset by creating modified copies of existing data. This is done to prevent overfitting and improve the model's generalization.
For what types of data can we perform augmentation?
Data augmentation can be applied to various data types, including images, text, audio, and time series. We can augment these types of data by applying transformations to create variations while maintaining the core characteristics of the original data and improving model generalization and robustness.
What is early stopping?
Early stopping is a strategy employed to counteract overfitting during model training. It involves keeping tabs on the model's performance using a dedicated validation dataset as training progresses. Should the model's performance on this validation set (measured by metrics such as accuracy or loss) cease to improve for a certain number of training cycles, known as "patience," the training is then stopped.
What is “dropout” and why is it performed?
Dropout" is a regularization technique in which a random subset of neurons is temporarily "dropped out" (set to zero) during each training iteration. This technique prevents the network from becoming overly reliant on specific neurons, thus enhancing its ability to generalize to unseen data and effectively reducing overfitting.
One of the differences between CNNs and MLPs is the “local receptive field.”
Which one has a local receptive field, and which has a global one?
CNNs have local receptive fields because neurons in convolutional layers only connect to a small, local input region (the receptive field). On the other hand, in MLPs, neurons connect to all neurons in the previous layer, thus creating a global receptive field.
What are the five main differences between MLPs and CNNs?
CNNs have a local receptive field.
CNNs use parameter sharing.
Pooling layers are used in CNNs.
CNNs have a sparsity of connections.
CNNs have equivariance to translation.
What is equivariance to translation?
Equivariance to translation means that a change in the input's position results in an equivalent change in the output's position. For example, if an object in an image is shifted in object detection, the detected bounding box will shift by the same amount. Image classification typically aims for translation invariance, where a shift in the input image does not change the classification result.

The above code scales the train and test data. It uses an MLP with two hidden layers.
There are ten neurons in each hidden layer. It uses the alpha regularization factor. Increasing alpha could reduce overfitting.
Neurons in the hidden layers use ReLU activation and Adam optimizer.
We use .fit() to train the network and the predict() function to perform the test phase.
The precision, recall, and accuracy are reported at the end.

It uses TensorFlow to form an MLP classifier with one hidden layer of 512 neurons and an output layer of 10 neurons. The Flatten layer converts the input matrix into a one-dimensional vector. The Dropout layer randomly deactivates the outputs of 20 percent of the neurons. A Dense layer is a fully connected layer.
If the input of the above MLP is a 28 by 28 matrix, how many parameters does the first layer have?
The first hidden layer has 28*28*512 +512 parameters. The output layer has 10*512 +10 parameters.
In the context of deep learning, what is an optimizer?
An optimizer finds optimum values of coefficients during the backpropagation operation.
What are two examples of optimizers?
Stochastic Gradient Descent (SGD) Adaptive Moment Estimation (Adam) are examples of optimizers.
(Other optimizers commonly used in CNNs include Adagrad, Adadelta, and Nadam. The choice of optimizer can depend on the specific task, the network's architecture, and the training dataset's size and complexity.)
What is the difference between dropout and drop-connect methods?
In dropout, we assume that the output of a neuron is zero. This is considered during the forward pass and backpropagation. The weights are updated for all neurons.
In the drop-connect method, we set a fraction of weights to zero, which affects the network’s output during the forward pass. During backpropagation, we only update the weights that were not considered zero.
Which options can be used to reduce overfitting in deep learning models?
a) Add more data
b) Use data augmentation
c) Use an architecture that generalizes well
d) Add regularization
e) Reduce architectural complexity
f) All of the above
Which of the following is a data augmentation technique used in image
recognition tasks?
a) Horizontal flipping
b) Random cropping
c) Random scaling
d) Color jittering (randomly changing the brightness, contrast, and saturation)
e) Random translation (shift pixel (x,y) positions.)
f) All of the above
What are the main layers in a CNN model?
Convolutional, Pooling, and fully connected layers
What is convolution in a CNN?
Convolution is an operation where a kernel (filter) slides over an input, performing element-wise multiplications and summations to produce a feature map.
What is a kernel (filter) in a convolutional layer?
A kernel is a small matrix of weights used to extract features from the input. Weights are parameters that will be determined during the training process.
How does kernel size affect the features learned by a CNN?
Kernel size determines the spatial extent of features that the network can detect. Larger kernels capture broader features, while smaller kernels capture finer details.
What is the relationship between kernel size and the size of the produced feature map?
Larger kernels result in smaller feature maps.
What is a stride in a convolutional layer, and how does it affect the output
feature map size?
Stride is the number of pixels the kernel shifts at each step—a larger stride results in a smaller feature map.
What happens to the feature map size if the kernel size is larger than the input size?
The convolution operation is impossible, as the kernel cannot fit within the input.
How does the number of kernels in a convolutional layer affect the output?
The number of kernels determines the number of output feature maps, each
representing a different learned feature.


An input matrix is 5×5. This matrix is zero-padded and becomes 7×7. A filter with a 3×3 is convolved with this matrix. The convolution is of stride 1. What is the size of the convolution output?
The input is now 7×7, and the output will be (7-2)×(7-2).
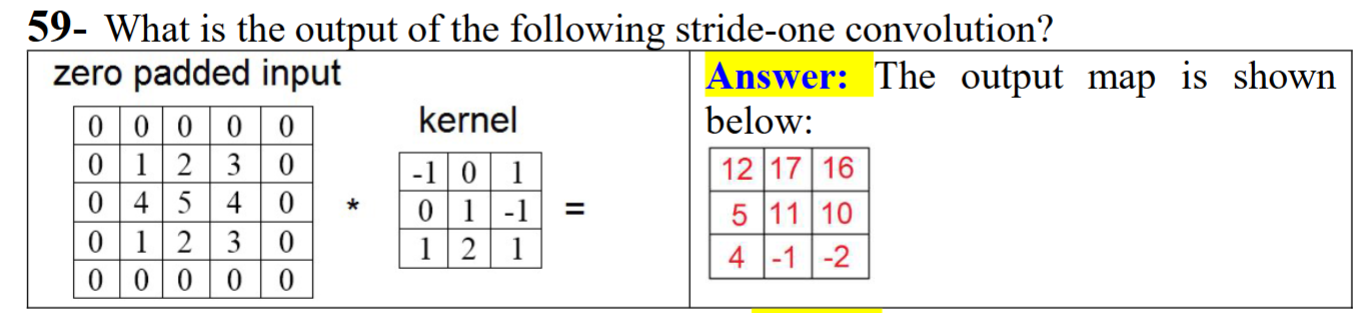
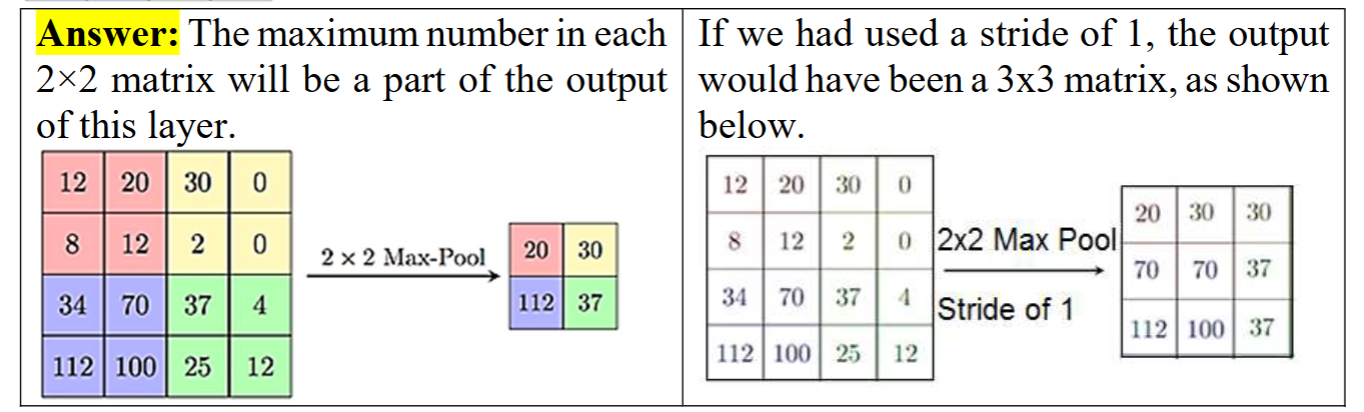
What is the purpose of pooling layers?
To generate features with a broader view.

Method 1 is known as “max-pooling,” which identifies the maximum value within a specified window.
Method 2 is “average pooling,” which calculates the average of k numbers in a window.


eee (TODO)
Backpropagation works by calculating the gradient of ___ and then propagating it backward
B) The sum of squared error with respect to weights
Sigmoid, Tanh, and ReLU are all examples of activation functions.
True
The primary purpose of L1 regularization (Lasso) is to slightly
shrink all coefficients to stabilize the model.
False
Reinforcement learning is one of the main types of machine
learning models.
True
Data augmentation is primarily used to decrease the size of the
training dataset.
False
MLPs (Multi-Layer Perceptrons) have a local receptive field.
False
Softmax is an activation function used for binary classification
problems.
False
L2 regularization is generally better when you need to select a small
subset of essential features.
False
The main difference between traditional machine learning and deep
learning (DL) is that DL uses many layers.
True
Equivariance to translation is a characteristic of MLPs.
False
Unsupervised learning models require labeled data for training.
False

The receptive field in layer 1 has three inputs, while layer 2 has five inputs.
The receptive field refers to the number of input points that a neuron receives. In the first layer, h3 is influenced by x2, x3, and x4. Each neuron in the second layer is affected by five data points. For instance, g3 is connected to three neurons from the first layer, and those three neurons receive five inputs from x1 to x5. Therefore, g3 is connected to five inputs, resulting in a receptive field of 5.