simple linear regression
1/19
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
20 Terms
whats Statistical inference?
Trying to reach a conclusion (or answer a question) about a complete set of observations (a population) using a representative subset of observations (the sample)
Correlation ( what it measures, Pearsons coeff formula, hyp test or r , drawback of cor analysis compared to slr)
what it measures: strength + direction of a linear relationship
Calculating pearsons cor coeff : r = SSxy/√SSx√SSy
SSxy = sum ((x-xbar)*(y-ybar))
SSy = sum ((y-ybar)²)
Hyp test to test if r is significant
p → pop cor coeff
H0 : p =0 ; no lin rlts
HA : p≠ 0 ; some lin rlts
T stat → (r√n-2)/√1-r²
(-1 to 1 )
Vs SLR ? → cant make predictions/ predict Y
→ cant forceast effect changing 1 var will have on other (only says strenght of relationship and if its likely real or by chance (H0))
Thresholds for no,low,moderate and high corelation?
0
0.1 to 0.4
0.4 to 0.6
0.6+
Testing if our plotted model (model we made) is significant (good estimate)- R²
R² ( Coefficient of determination ) → how much var in Y explained by my model
R² = SSr/SSt
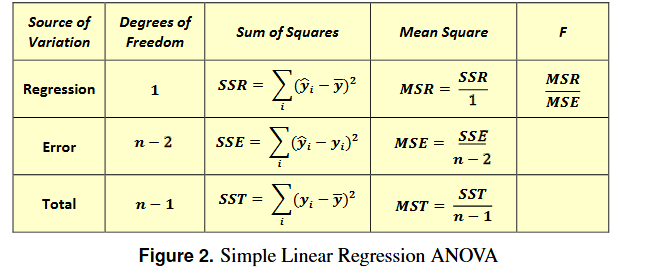
IMPORTANT TO MEMORISE THIS
More SST is made up of SSR means most var in Y captured + explained by our model (good) - model doing good job capturing var in Y
Sample lm and Pop lm equations (error terms - defn, why theres none in sample )
X & Y → continous var
P: Y = b0 (incercept / c) + b1(regression coefficient) x + ei (error term - any var in y thats not becz of x; not all data pts will lie on fitted line exactly)
S : ^Y = ^b0+ ^b1xi
ei= yi^ - yi
why theres no error term for estimates :assumption errors normally dist and expected val of 0
Finding b^ estimates
OLS Algorithim
Minimising Sum of squared error terms
How? - trial and error with different b0 and b1 values that give us the smallest squared error - the results are the most optimal estimates )
b coefficients interpretations
b^0 : avg estimated value of y when x=0
b^1 : avg estimated increase/decrease of y per unit increase in x
Visual check for Model accuracy
looks @ std dev of model residuals /how much response deviate from regression line on avg)
closer tg and more on line pts , more accurate our model is
Checking significance of (beta^ parameter)- Se method , calc test stat by hand, in R output)
in formula sheet se(B^1) = RSE/√SSx → Interpretation → high se relative to size of estimate (number/magitude of value) = NOT good estimate
smaller se(shows how diff sample estimate prolly is from pop estimate) , better
a big se relative with a big b estimate is fine , when they dont go tg its not
Tstat → β^1/se( β^1)) ~ tn-2
P-val In R → 2* pt (q = test stat , df = , lower.tail = F/T)
Hypothesis test on beta parameters to see if there actaully is a relationship between the variables in the population
confidenece intervals interpretation + calculation
95%: if we resample our population we expect 95% of the estimates to be withtin that interval
By hand → in formula sheet

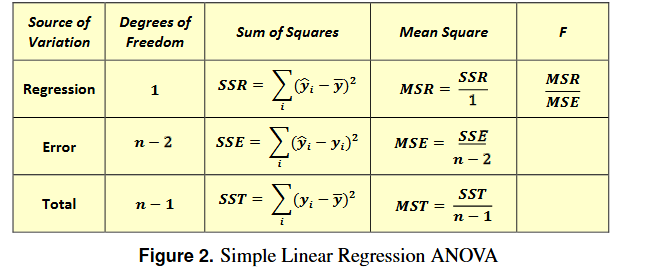
Testing overall model significance - RSE, Hyp test w Fstat & R² method
RSE plotted - std dev of model residuals ie how much responses deviate from lm line
Lower the better
check if its significantly different to a null model(model w only a c ) using F stat (bottom row in summary)
H0: B1 = 0
H1: B1 = 0
Fstat =MSreg/MSresid ~ F n-2
Ftest using Fstat
RSE = √MSresid
R² (coefficient of determination)
looks how much of var in y is explained by x in our model
0 - poor model fit , 1 - good model fit
R² = SSr/SSt

4 linear Model assumptions
Relationship btwn X& Y is LINEAR → check w scatter plot
E ~ N(0, sigma² )
Errors are….Normal dist w mean = 0 → Histogram : want peak around 0
Constant variance
Model errors Independent (no typa pattern going on) →
whats residuals,errors, and residual starndard errors
errors (pop parameter) - any variation in Y thats not because of /explained by x
residuals (sample parameter)- and var in y thats not explained by our model
residual standard error - the standard deviation of the model residuals
Testing if our residuals are normal dist
Norm QQ- plot Sample quantities on Y , Theoretical quantities on X
Pts must stick along the red line , normal to have deviation in the tails
Histogram (Residulas (x), frequency (y)): Must be bell shaped + centred/peak at 0
Testing our errors : Constant variance and INDEPENDENT
Scatter plot of Fitted values (predicted ys from our model) , Residuals ) - Constant var assumption met if even spread of pts around line
Scatter plot - (independent variable, residuals)- independent if NO pattern
Prediction - Predicting a Y val in R
In R → New data.frame where x = …
Predict(model (our lm), newdata= new var where data.frame stored),interval = “prediction”)
after model checks
cant predict for x’s outside outside range give
Confience int and Prediction ints cuz our predictions r just estimates
Predict int wider + symmetric about estimate,
conf int for the average value of y for a given x
Prediction intt of the y value for a specific person given their x value
Conf int for average narrower (smaller) than PI for a certain person cuz more uncertainty in predicting
R studio slr steps
maybe read.csv/ read_excel
Scatter plot to test linear assumption → plot(x,y)
Variance of vars → var(dataset$variable)
Std dev of variables → sd(dataset$variable)
Cor analysis → cor.test(Y (dataset$…), X (dataset$…))
SLR → lm(y ~ x , data = dataset)
Plot()
Summary()
Anova() - this the anova table
Confint(), predictionint()