H15: sequences - RNN & CNNs
1/7
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
8 Terms
RNN
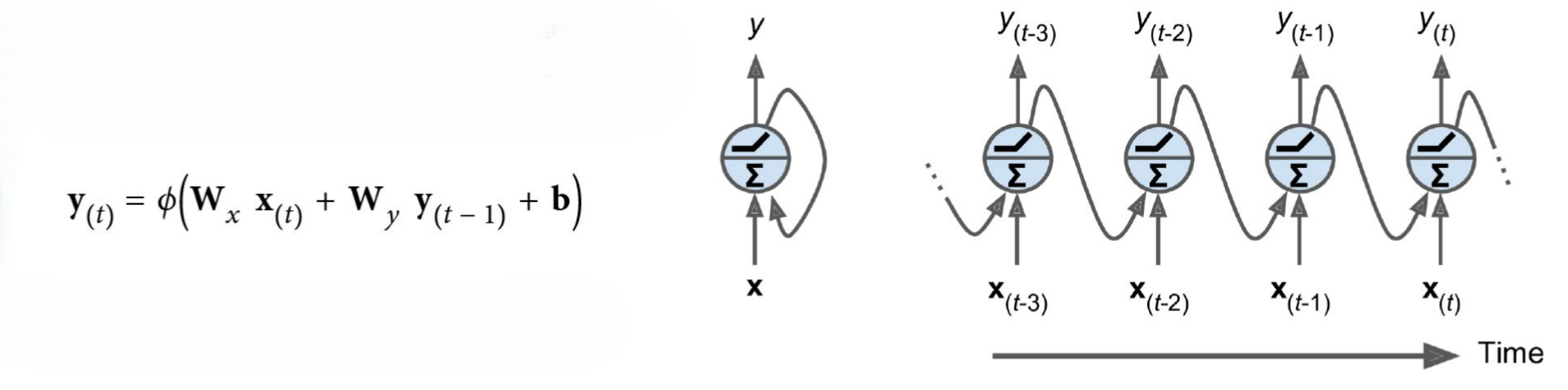
Recurrent Neural networks (RNNs):
neurons hebben connecties die achterwaarts wijzen
De output van step t is gegeven samen met de input op step t+1
We kunnen het netwerk uitrollen doorheen de tijd
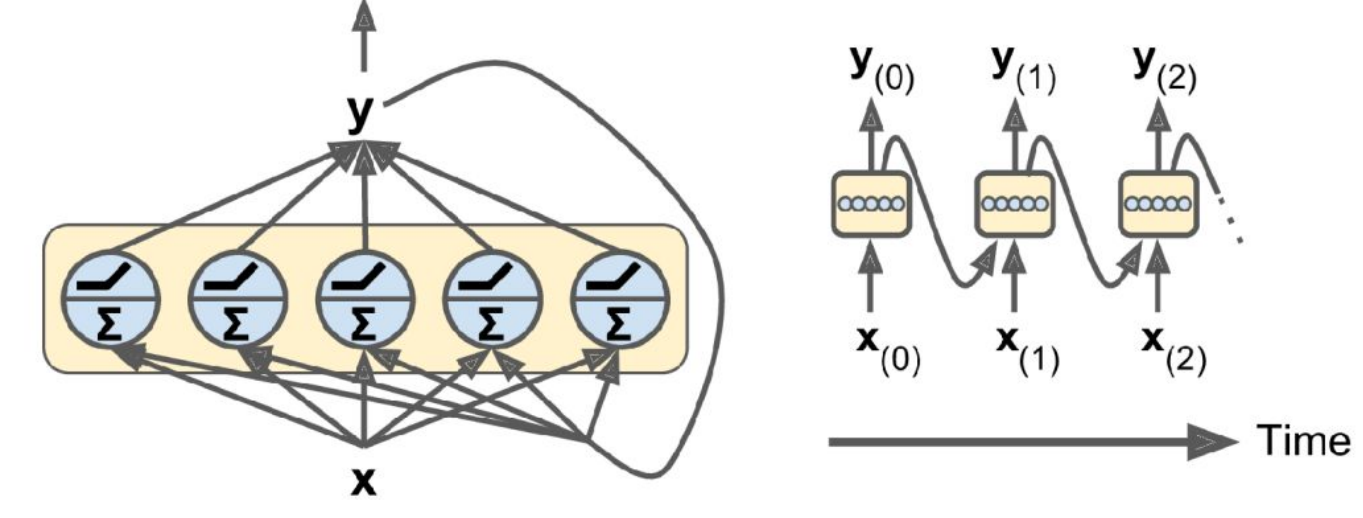
We kunnen recurrente neuronen combineren into een laag
op de volgende tijdstap, ontvangt de laag de (vector) output van de vorige tijdstap
de laag heeft 2 setten van gewichten: 1 voor de input en 1 voor de vorige output
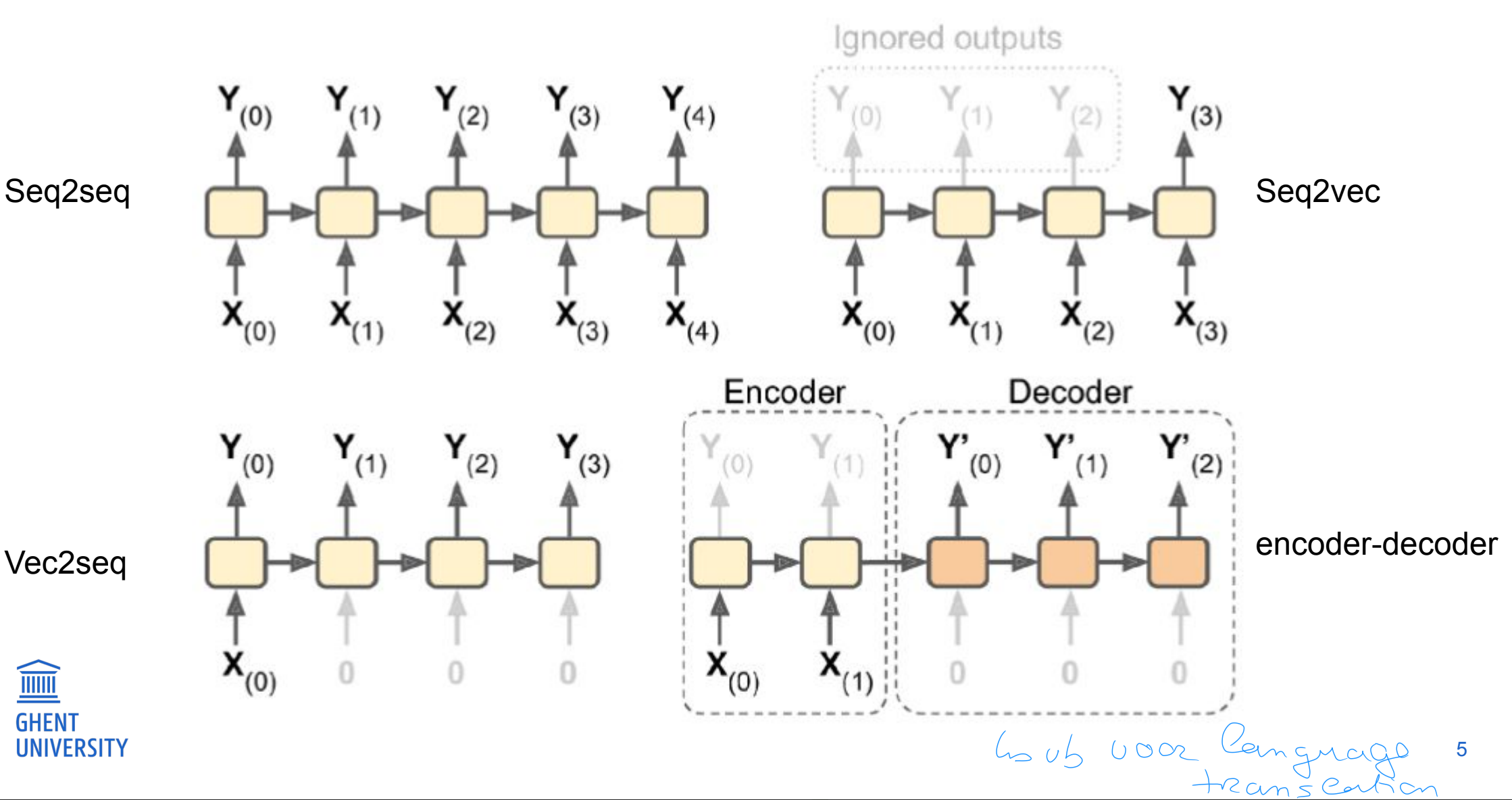
voorbeelden:
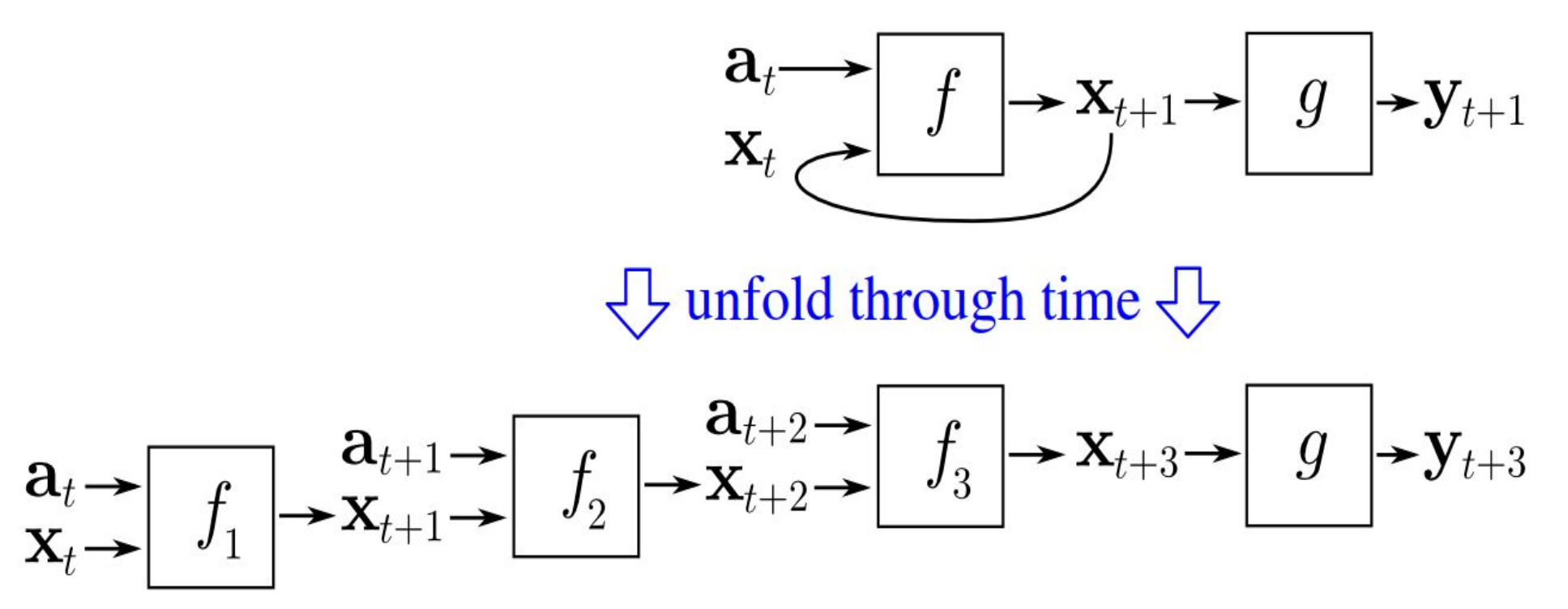
Backpropagatie doorheen de tijd
Om een RNN te trainen, ontplooien we het over tijd en daarna trainen we het als een feedforward model.
Training problemen en typische gebruiken
RNNs zijn vaak traag en onstabiel om te trainen, zeker voor langere sequenties
Meeste tricks gebruikt in feed-forward nn, kunnen ook toegepast worden op RNNs (initialisatie, versch optimizers, dropout, regularisatie,...)
Saturerende activatie functies (tanh, sigmoid) worden typisch gebruikt ipv ReLU
dezelfde gewichten worden gebruikt in elke tijdstap. We moeten zeker zijn dat de output nie blijft stijgen
Ipv batchnorm, gebruiken we typisch LayerNorm
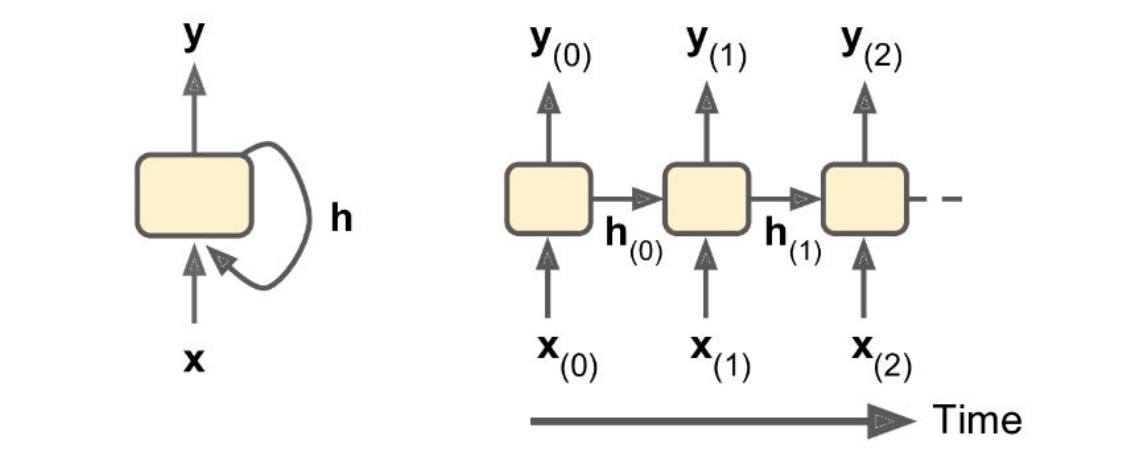
memory cells
De output van een neural op een zekere tijdstap is een functie van alle inputs op vorige tijdstappen
De model heeft een geheugen (het behoud staat)
in een basis RNN, komt de staat overeen met de huidige output
meer complexe varianten hebben een aparte state en output en kunnen selectief opslaan of returnen van informatie
Deze kunnen informatie "onthouden" voor langere periodes
LSTMs
wat & kernidee
In RNNs, is de ouput afhankelijk van de input van alle vorige tijdstappen. Maar niet voor lange sequenties, RNNs hebben de gewoonte om de eerste inputs te "vergeten".
Long-short term memory (LSTM) modellen definieren expliciet een geheugen slot
Hoofd idee
2 geheugens
short term (vorige output)
long term
het model beslist welke informatie op te slaan in het long term geheugen
de output is gebaseerd op de huidige input en beide geheugens
LSTMs
werking
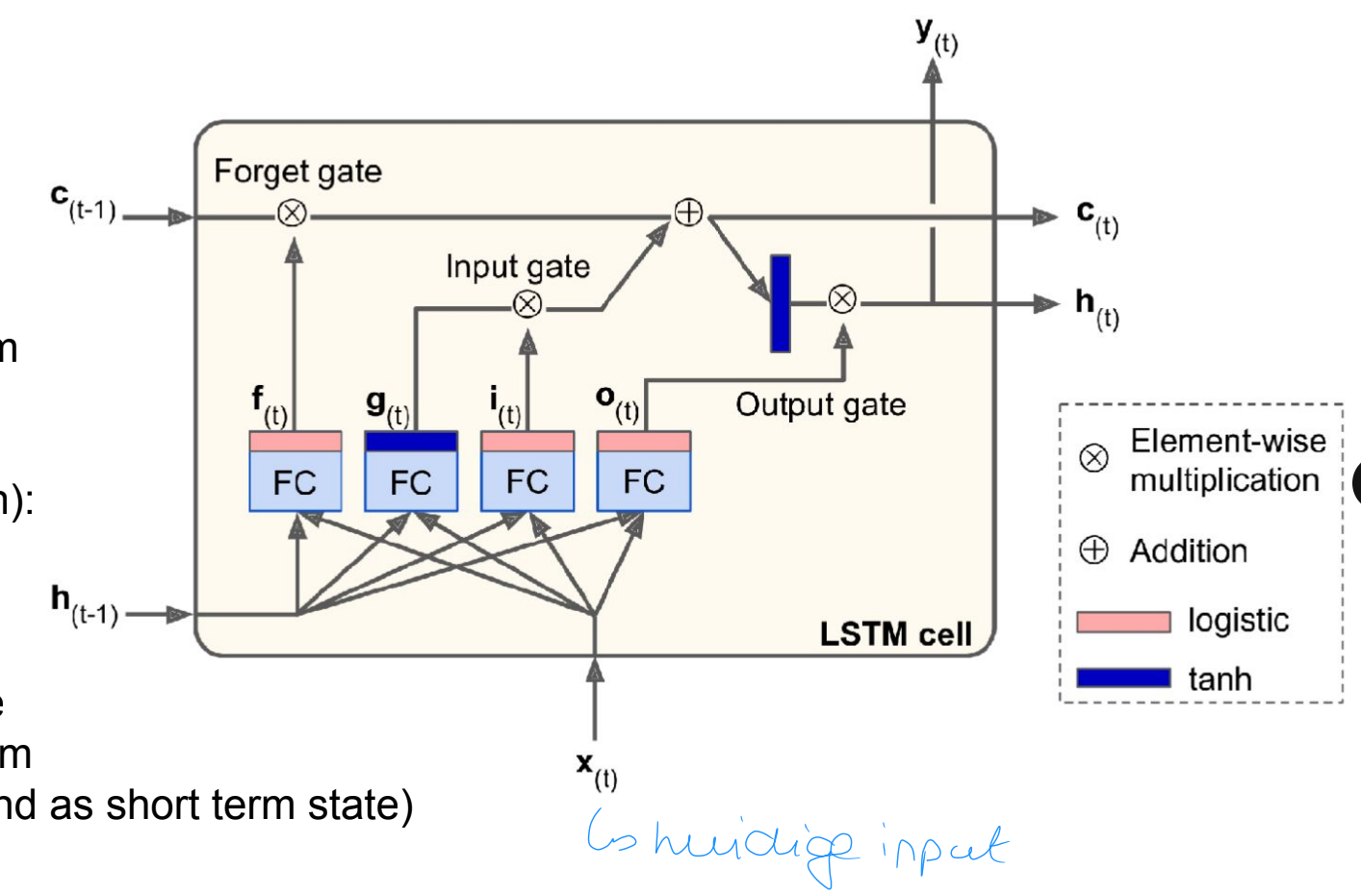
Twee staten
c(t): long term state
h(t): short term state (vorige output)
Cell gate g(t) (tanh activatie) berekent een functie van de input en huidige short term state h(t−1)
3 gate controller lagen (sigmoid activatie):
forget gate: controlleert welk deel van de long term state te wissen
input gate: controlleert welk deel van g(t) toegevoegd moet worden aan de long-term state
output gate: welk deel van de long term state teruggegeven moet worden als output (en als short term state)
GRU
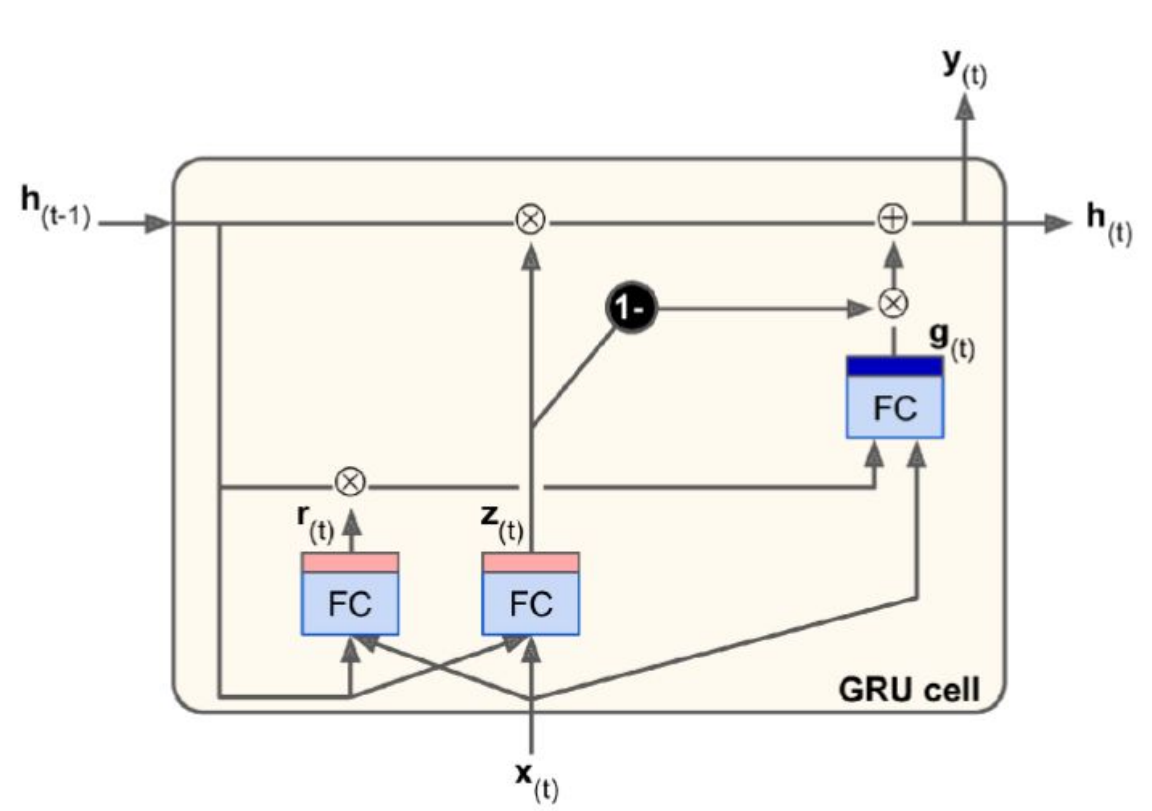
Gated recurrent units (GRU) zijn een vereenvoudigde versie van LSTMs die meestal evengoed werken
een enkele staat h(t)
een enkele gate controller laag z(t) controlleert zowel de forget gate als de input gate
geen output gate
nieuwe gate controller r(t) die determineert welk deel van de staat in deze stap zal gebruikt worden
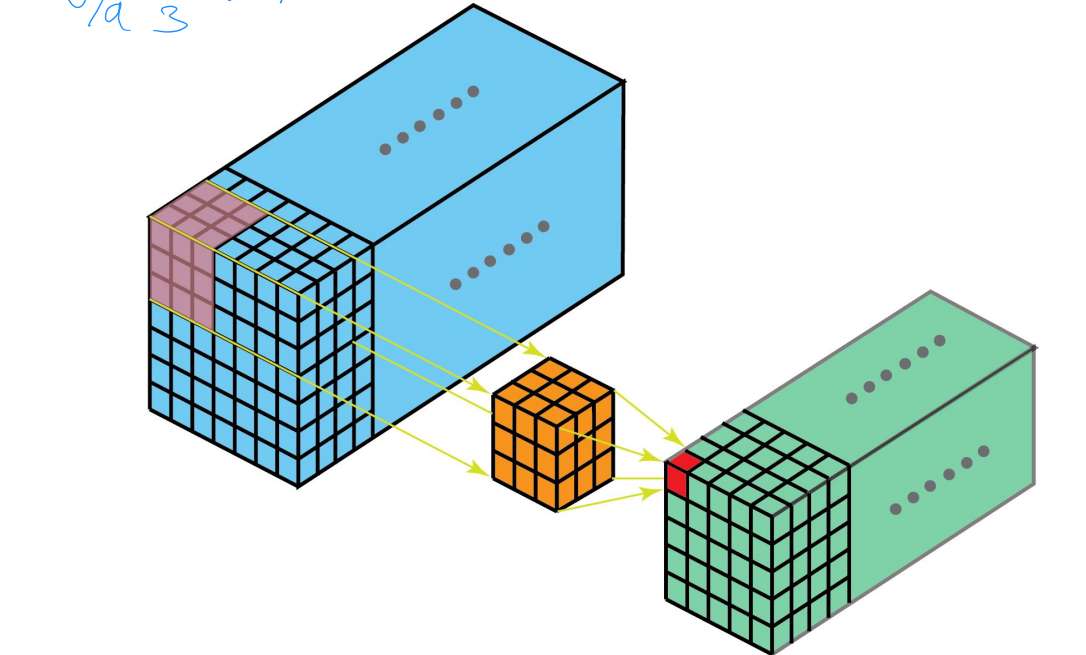
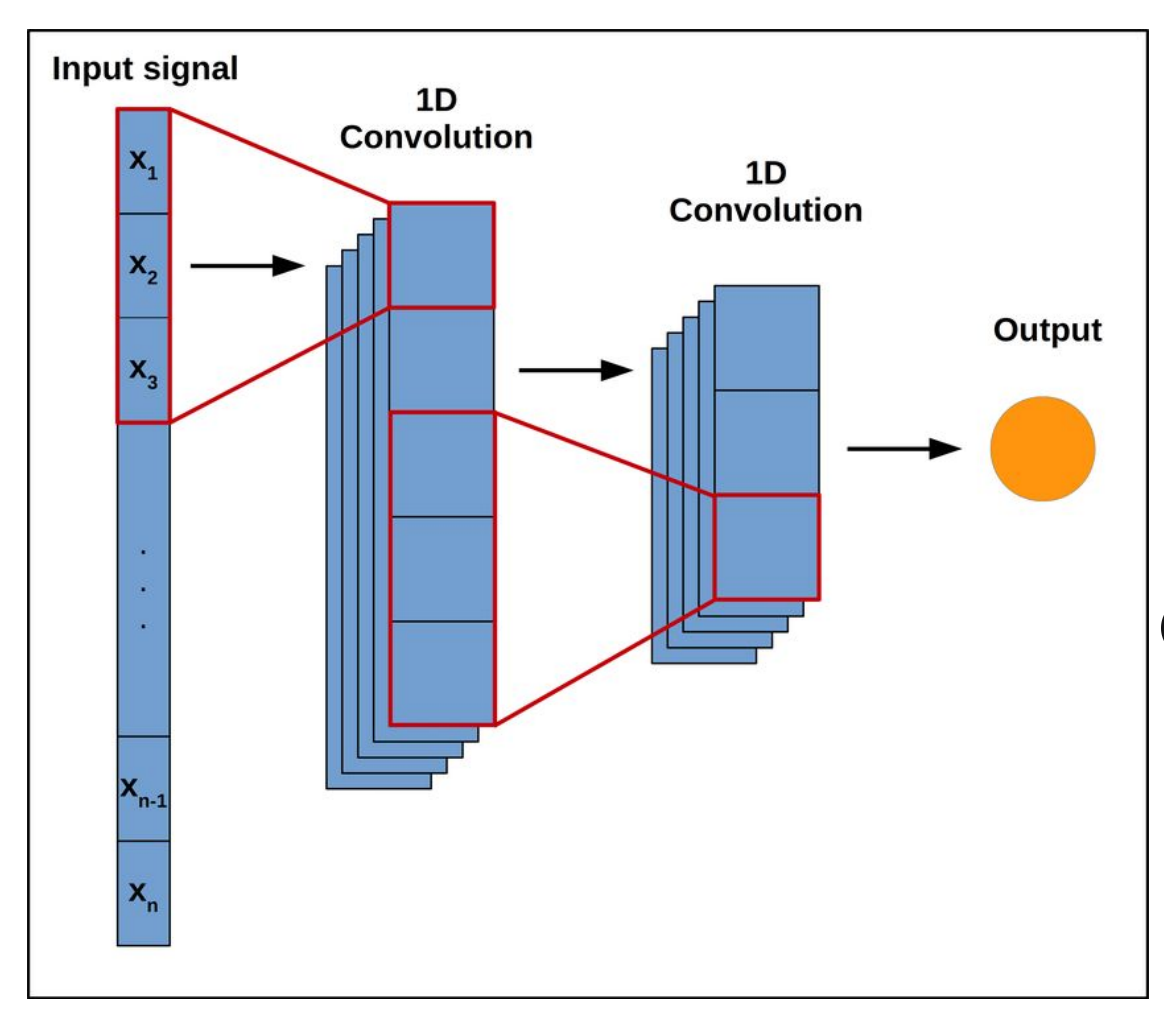
1D conv lagen
In een 2D convolutionele laag, glijdt een 2D filter over een 2D input, wat een activatie genereert op elke positie
1D convolutionele lagen zijn gelijkaardig maar nu zijn de input en output 1D
We kunnen strided convoluties en pooling gebruiken
kan beter omgaan met langere sequenties
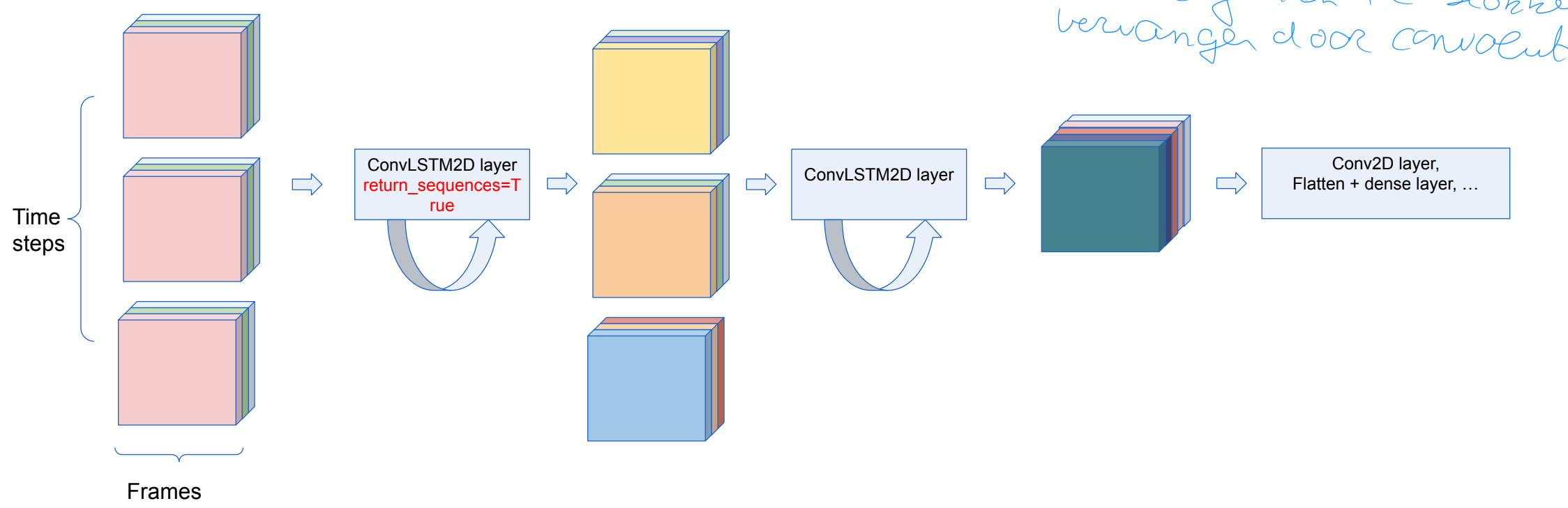
Video data: 3 opties
Optie 1: Convolutionele LSTM
De input transformaties en recurrente transformaties zijn beide convolutioneel.
Eerder geziene FC blokken vervangen door convolutionele blokken
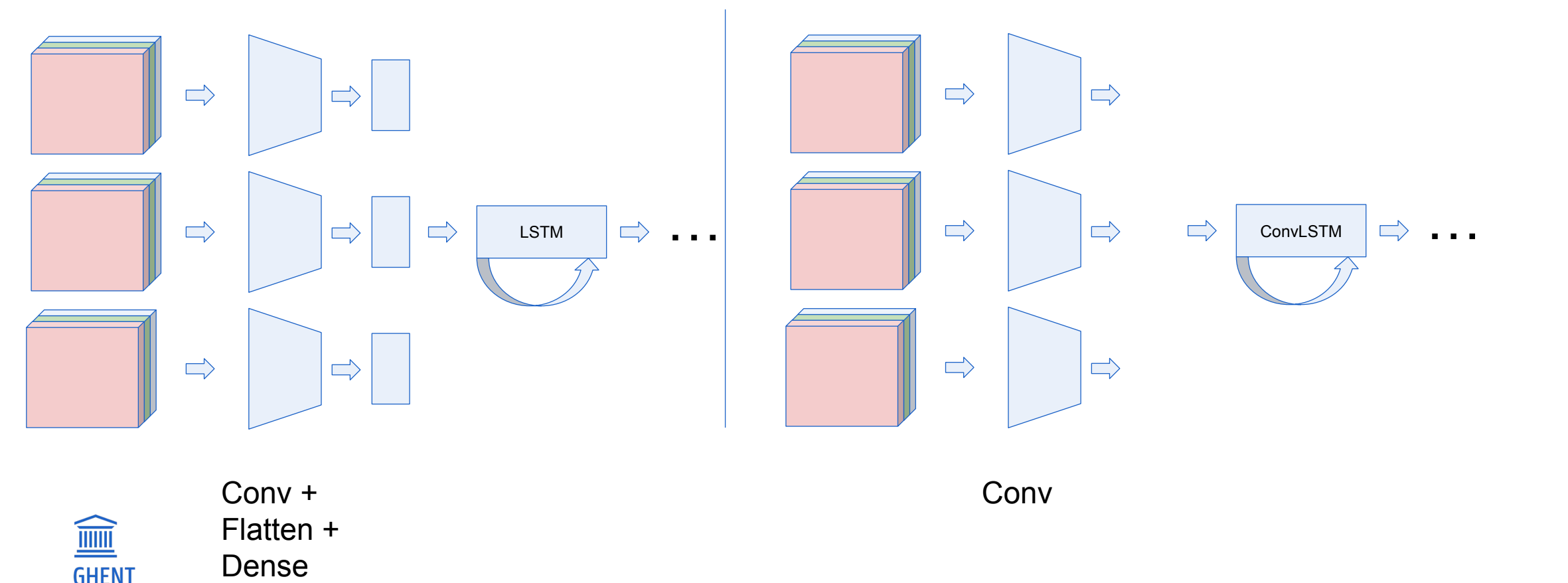
Optie 2: 2D CNN + LSTM
Extract features van individuele frames en combineer deze met recurrent model
Optie 3: 3D Convolutionele lagen
Belangrijkste van de 3
We kunnen een video zien als een stack van frames doorheen de tijd
2D convnets laten ons toe om 2D spatiale informatie te extracten uit een afbeeldingen
we kunnen dit uitbreiden naar een video waar de kernel ook scant doorheen de tijdsdimensie