4.0. experimental method
1/75
Earn XP
Description and Tags
4.0. experimental method
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
76 Terms
demonstrating cause & effect
experiment
experimental method
demonstrates a relatively unambiguous connection between cause & effect (aim)
these connections are what science tries to establish.
a type of research in which the researcher carefully manipulates a limited number of factors (IVs) and measures the impact on other factors (DVs).
alternative interpretations of findings
possible to data that supports a hypothesis → often, we cannot rule out competing explanations; that is we cannot confidently point to a clear cause & effect relationship between events & human behaviour
independent variable (IV).
manipulate independently of what the other variables are doing
dependent variable (DV).
we expect to experience a change which depends on the manipulation we’re doing
confounding variables
other variables that might have an effect on the dependent variable
experiments in psychology looks at
the effect of the experimental change (IV) on a behavior (DV).
Experiments can meet the three causal rules
covariance
temporal precedence
internal validity
Covariance
signifies the direction of the linear relationship between the two variables (directly proportional or inversely proportional)
increased values may have positive or negative impact on the other value
Temporal precedence
IV comes before DV
internal validity (very important)
the extent to which a study establishes a trustworthy cause-and-effect relationship between a treatment & an outcome
variation among scores recorded in an experiment can be divided into three sources
variance from the treatment (the effect under investigation)
systematic variance caused by confounding
unsystematic variance coming from random errors.
error variance emerges when
behavior of participants is influenced by variables that the researcher does not examine (did not include in his or her study)
by means of measurement error (errors made during the measurement).
systematic variance
refers to that part of the total variance that can predictably be related to the variables that the researcher examines.
Three types of Groups in an experiment
experimental group
control group
placebo group
experimental group
The one that is being manipulated
control group
Act as a BASELINE MEASURE of behaviour without treatment
A control group is not always necessary
placebo group
One group of patients is often given an inert substance (a ‘placebo’) → patients think they have had the treatment.
They are similar to a control group because they experience all the same conditions as the experimental group, except they do not receive the change in the independent variable that is expected to influence the dependent variable
limitation in experimental method → can sometimes be
inappropriate
unethical
artificial → limit the range of sensibly studies
non-experimental methods suited for
naturally occurring phenomena:
reactions to parental discipline
gender-specific behaviour
everyday health behaviour
Experimental design between group design
single case experimental design
between group design
single case experimental design
Withdrawal or reversal designs (ABAB)
Multi-treatment design (ABCBC)
Multiple baseline design
Alternating design
Variable criteria design
Between group designs
Parallel-group designs
Crossover or within groups design
Cluster design
Factorial design
Dismantling design
general dimensions of group design
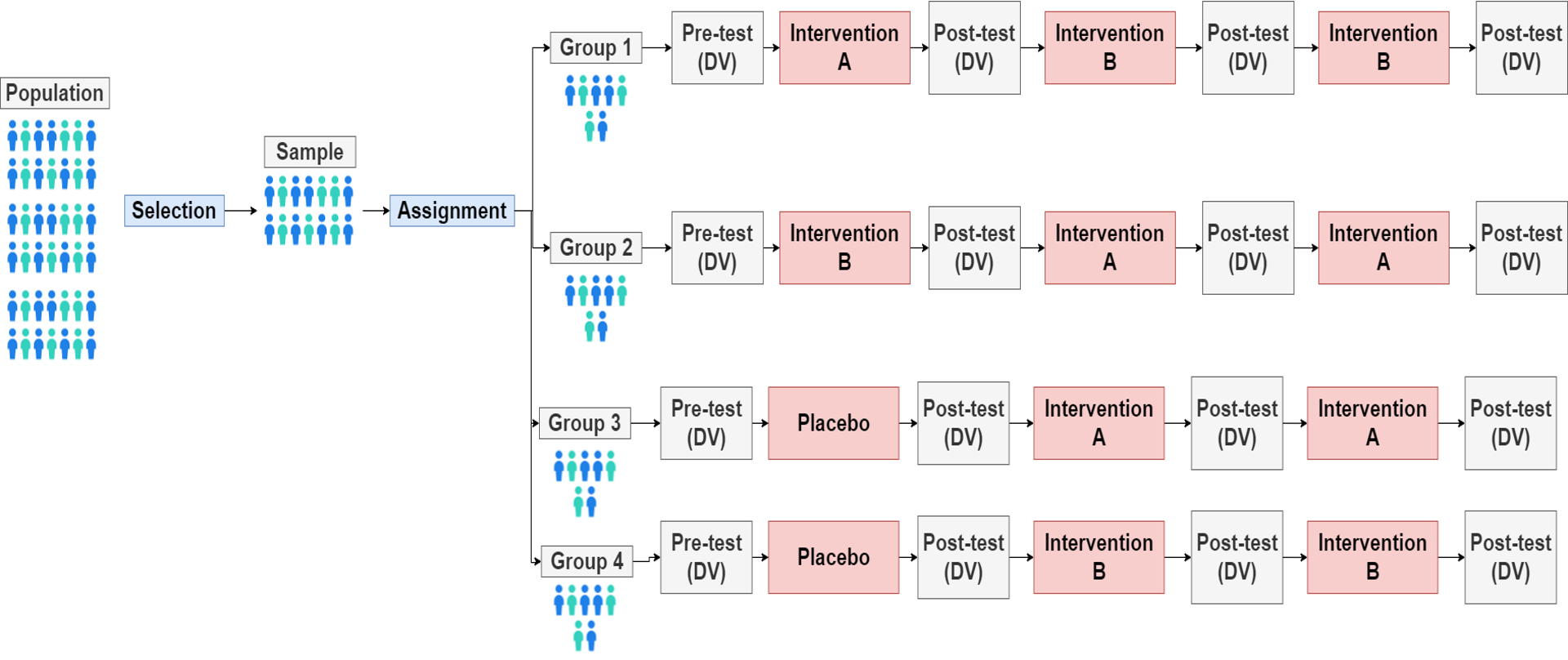
Selection of the Sample: Random/non-random
Assignment to the groups: Random/non-random
Treatment Information: Blinded/open
Random sampling
pool of research participants that represents the population you’re trying to learn about
Random assignment
participants to control or experimental groups
control all variables except the one you’re manipulating.
random sampling vs random assignment
first → random sampling
next → random assignment
single-blind study
participants are blinded.
double-blind study
both participants and experimenters are blinded.
triple-blind study,
assignment is hidden from participants, experimenters, & the researchers analyzing the data.
illustration of parallel-group
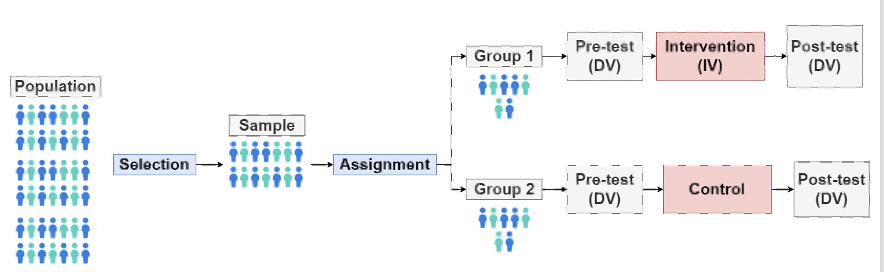
No-Treatment Control
What it is: Participants get no treatment at all.
What happens: They are only assessed before and after the study.
Purpose: Shows how much change happens naturally, without any intervention.
Waitlist Control
What it is: Participants do not get treatment now, but will receive it later.
What happens: They are assessed while waiting, then treated after the experiment.
Purpose: Helps control for expectation effects (people may expect to improve just by knowing treatment is coming).
Attention-Placebo / Nonspecific Control
What it is: Participants get some kind of interaction (e.g., therapist attention) but not the real treatment.
What happens: They receive support/attention, but not the active therapeutic techniques.
Purpose: Controls for the fact that attention alone can improve symptoms.
Standard Treatment / Routine Care Control
What it is: Participants get the usual or current standard treatment, not the new experimental one.
What happens: They receive normal care, not the experimental intervention.
Purpose: Tests whether the new treatment is better than what is already commonly used.
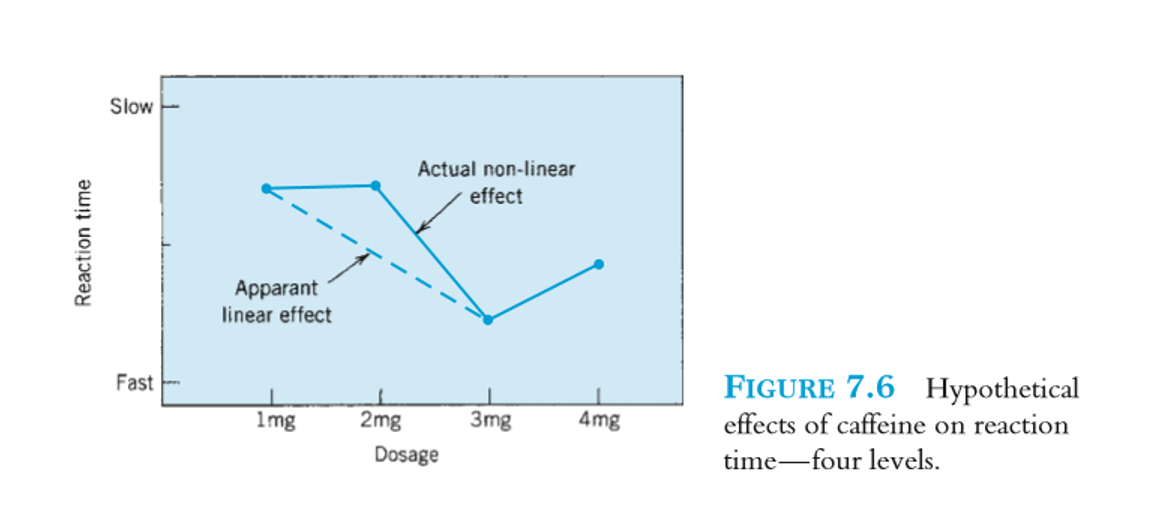
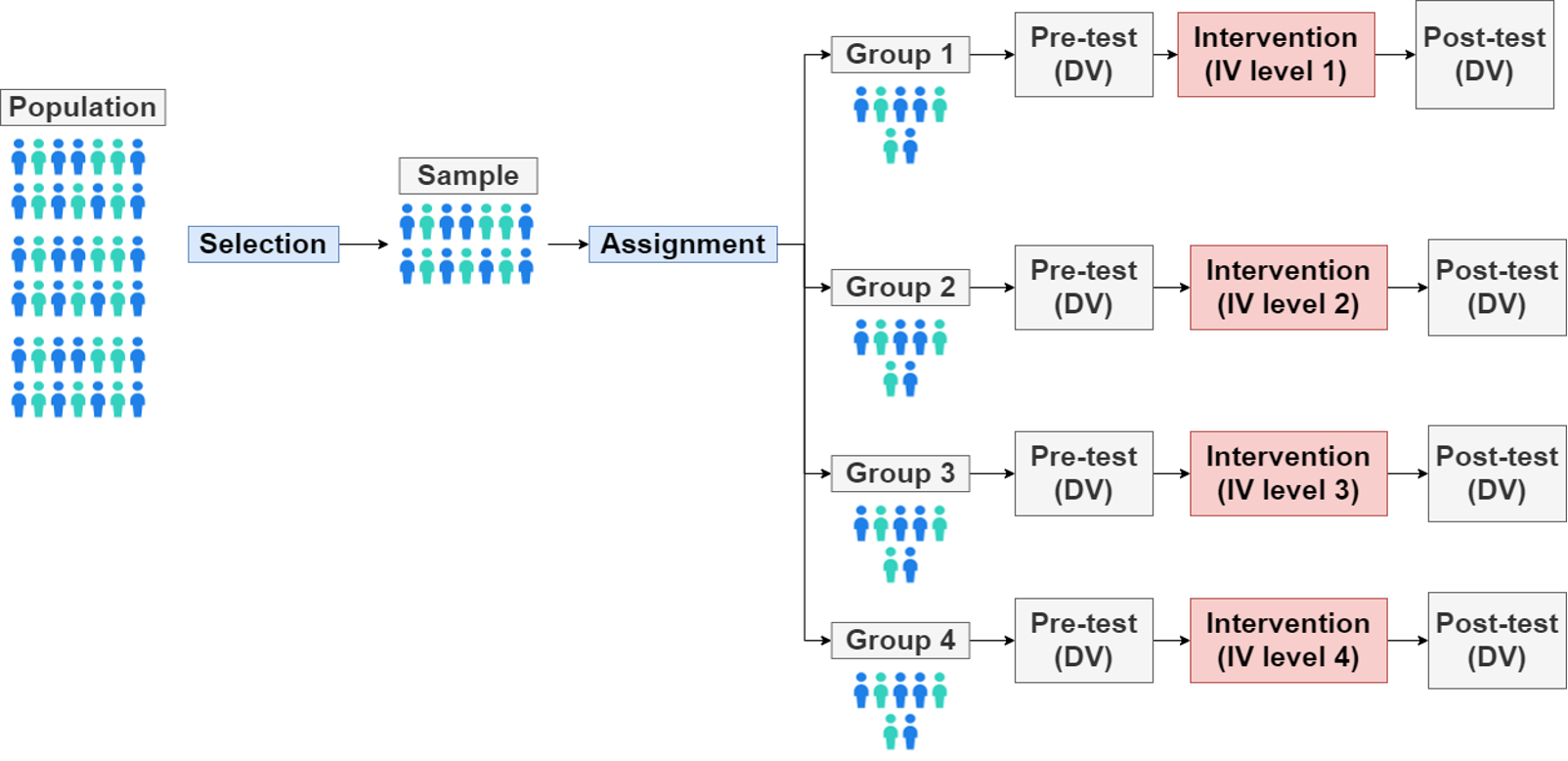
Parallel-group or INDEPENDENT GROUPS DESIGNS → mulitlevel design
greater than two levels of IV
more realistic
non-linear effect can be discovered
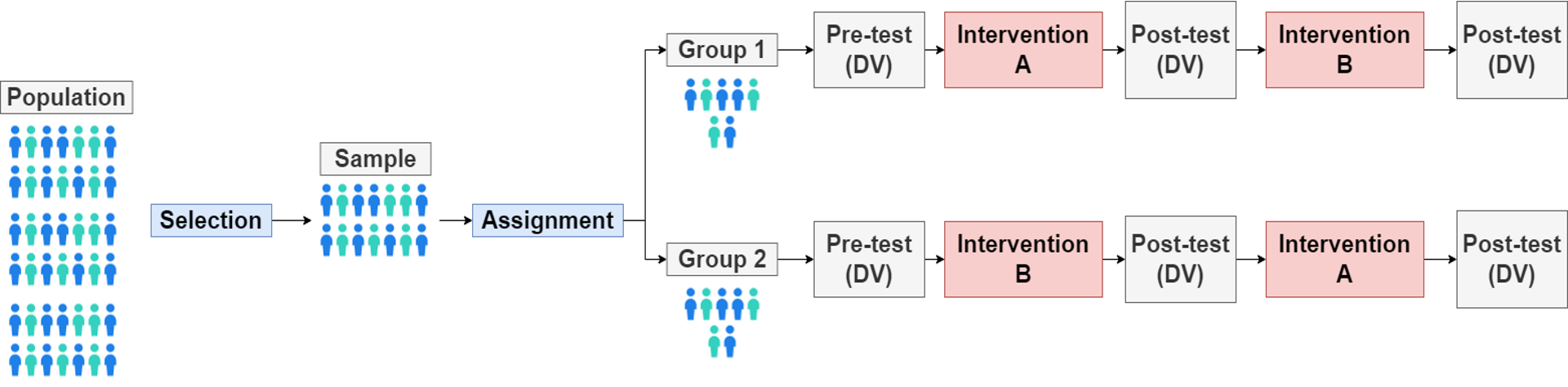
crossover or within groups design
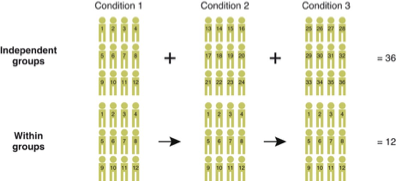
Independent sample designs
within-subject design (crossover or within groups design)
same measure is repeated on each participant
under the various conditions of the IV
participants are the same for both conditions
all other variables are controlled
differences within participants → effect of the manipulated IV
individuals → serve own control
multiple testing
is not repeated measures.
illustrations of crossover designs / repeated design
ORDER EFFECTS
Effects from the order in which people participate in conditions
how to deal with order effect?
Counterbalancing
Complex counterbalancing
Randomisation of condition order
Randomisation of stimulus items
Elapsed time
Using another design
Counterbalancing
Having two conditions (A & B), one group does the AB order while the other group does the BA order.
Complex counterbalancing
To balance asymmetrical order effects all participants take conditions in the order ABBA
When there are more than 2 conditions, you divide the participants that many groups as possible orders
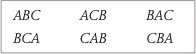
Randomisation of condition order
Present the conditions to each participant in a different randomly arranged order.
Randomisation of stimulus items
Present items from different conditions
Elapsed time
Leave enough time between conditions for any learning or fatigue effects to dissipate
Using another design
Move to an independent samples design
INDEPENDENT SAMPLES DESIGNS
More sample needed
Too much variance make the analysis harder
No contamination across independent variable levels
REPEATED MEASURES
Order effects
Effect of attrition
Taking both conditions create demand characteristics bias
Practice effect
Need of equivalent stimuli
comparison between independent sample design, & repeated mesures
PARTICIPANT VARIABLES
Participant variables = individual differences
can cause threat to internal validity
Independent groups designs
these differences can accidentally cause differences in the results.
This is a threat to internal validity
Ways to Control Participant Differences
Random Assignment
Matching
Pretest
Random assignment
Assign participants to groups by chance.
Makes groups equal on average → reduces bias
Matching
Pair participants based on a variable (e.g., IQ), then split pairs into groups
Ensures groups are equal on key characteristics
Pretest
Measure DV before & after treatment
Helps detect initial group differences
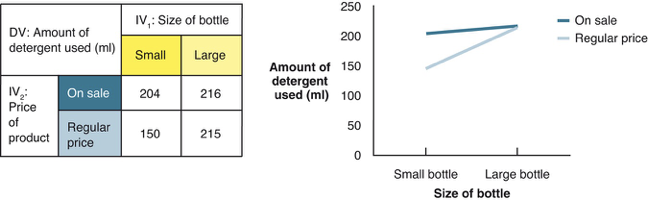
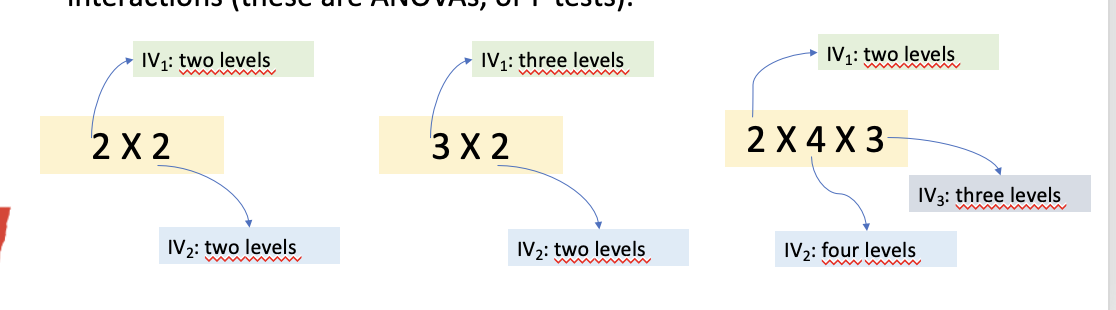
Factorial design
A study with two IV.
Each IV has at least two levels.
IVs are crossed with each other, creating all possible combinations of the levels.
IVs can be participant variables or manipulated variables.
IVs can be within-groups variables or independent-groups variables
illustration of factorial design

Factorial design aims at
test theories
test limits
show interactions
main effect of factorial design in experiment & analysis
effect of an IV on a DV averaged across the levels of any other IV
used to distinguish main effects from interaction effects.
when there is an interaction in the data
usually more important than any main effects you may find.
essential tables to study
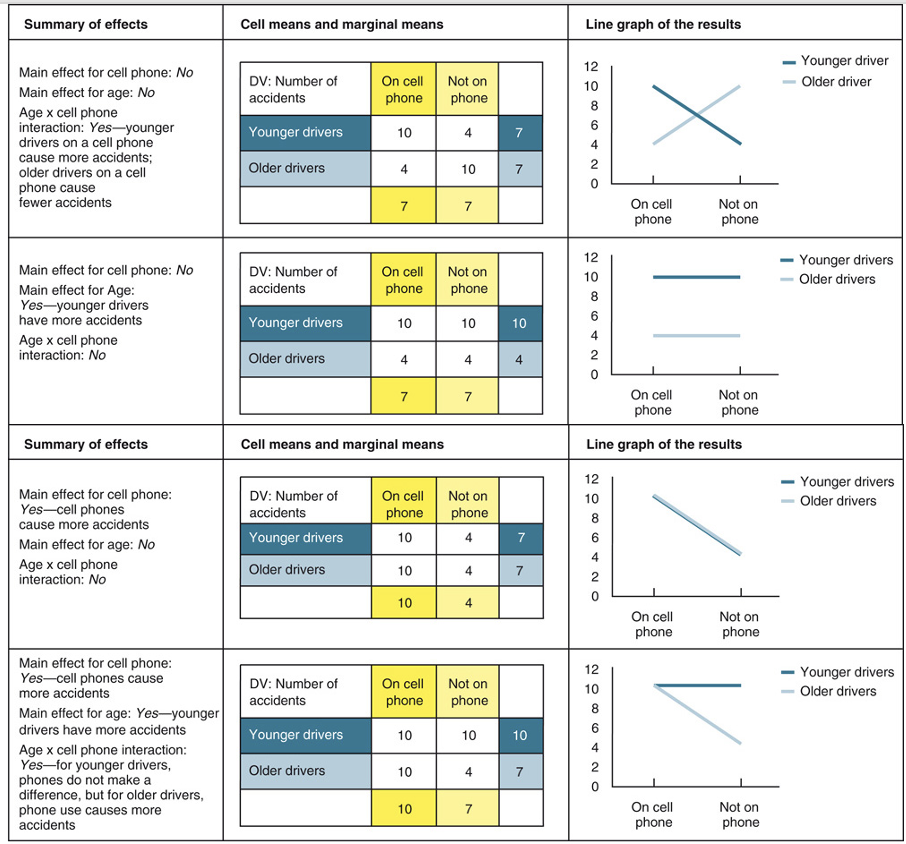
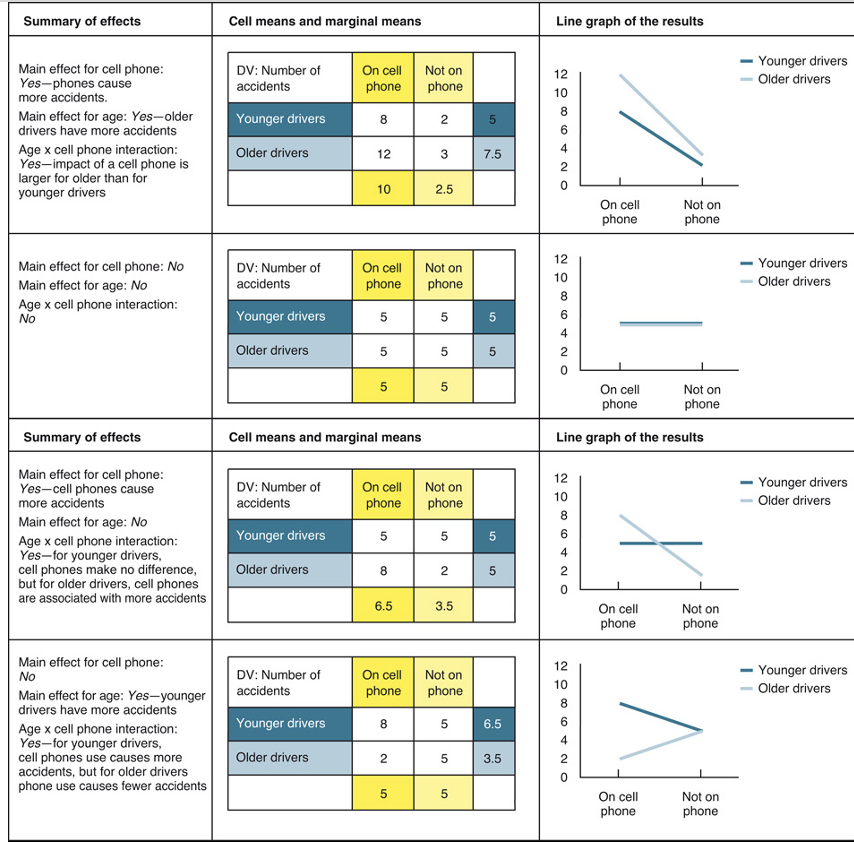
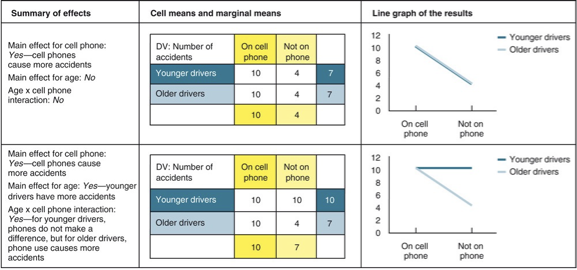
identifying factorial design
empirical journal articles:
→ method section “this was a factorial design”
→ results section “describe the statistical tests for main effects and interactions”
IVs can in factorial design be manipulated as
three-way-interaction between → within-groups or between- groups + mixed design
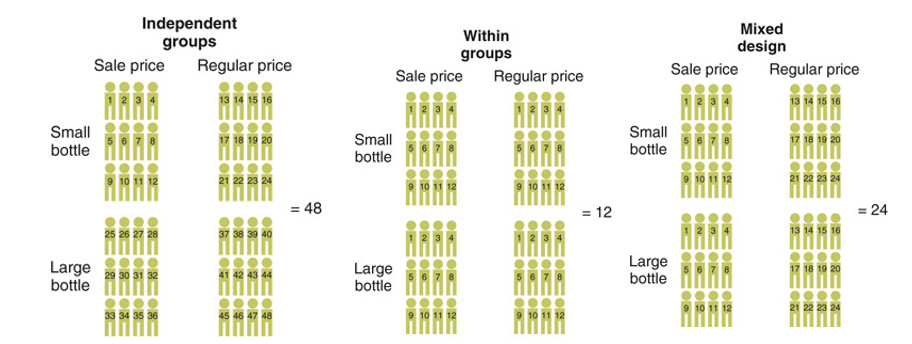
implications related to how IVs can be manipulated in factorial design
Implications for numbers of participants
Implications for statistical testing
Randomized controlled trials in clinical research
compares a proposed new treatment against an existing standard of care
→ these are then termed the 'experimental' and 'control' treatments, respectively.
What are the four main types of RCT study designs?
Parallel-group: Different groups receive different conditions (most common).
Crossover: Each participant receives multiple conditions in sequence.
Cluster: Pre-existing groups (e.g., classrooms, clinics) are randomly assigned to conditions.
Factorial: Participants receive combinations of interventions (tests multiple variables at once).
What is the purpose of randomization and blinding in RCTs?
Randomization: Makes groups comparable by balancing participant differences → reduces selection & allocation bias → improves internal validity.
Blinding: Prevents participants and/or researchers from knowing group assignments → reduces placebo effects, demand characteristics, and experimenter bias.
What is an RCT and why is it the gold standard?
RCT (Randomized Controlled Trial) compares a new treatment to a control/standard treatment.
Participants are randomly assigned to groups → this reduces selection bias & balances known & unknown participant differences.
Blinding (participants/researchers) reduces expectancy and experimenter bias.
→ Therefore, RCTs provide strong evidence for causality.
Single-subject experiments
control has to be on a individual level
A B A B design
more subjects can be added/not only one single
A way to see the effect in a single-subject experiments
extending the time of the baseline without adding more variables.
Validity in experiments (causal claim)
Construct validity→ ? how well are variables measured & manipulated?
External validity → to whom/what can the causal claim be generalized?
Statistical validity → ? how well does data support causal conclusion?
Internal validity → ? alternative explanation to the outcome?
Strengths of Validity in experiments
Can establish cause & effect because the IV & extraneous variables are controlled.
High internal validity: alternative explanations can be ruled out.
Replicable → results can be repeated to check reliability.
Weaknesses of Validity in experiments
Artificial setting → results may lack ecological validity.
Reactivity: participants may behave differently because they know they are being studied.
Limited in the range of real-world behaviors that can be studied, because variables must be tightly controlled.
Participants have little personal input, & this may raise ethical issues.