ECS 154B Assesment 4
1/44
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
45 Terms
Write down the average memory access time equation.
T(hit) + miss ratio * miss penality
Circle the type of cache miss that cannot be changed by altering the size of the cache.
Conflict Capacity Compulsory
Compulsory
Circle the type of cache miss that can be reduced by using longer lines.
Conflict Capacity Compulsory
Compulsory
Writing to a cache is inherently slower than reading from a cache. Why?
in a read, you can access in parallel the tag array and the data array. you cannot do that in parallel with a write because it changes the state of the machine so you cannot do the write until you have checked the tag
What does TLB stand for? What does it do?
Translation lookaside buffer, It caches recent virtual to physical translations
Compilers have trouble scheduling code that involves reads and writes to memory. Why?
Hazards through the memory system, when an offset + register is unknowingly the same in two SW/LW, since the compiler does not know what is in the register
Why is there a desire to create larger basic blocks? Give one example of a way to create a bigger basic block.
a larger basic block allows for more code to be scheduled, which can increase performance. loop unrolling
What does ROB stand for, and why is it used in modern advanced pipelines? (What necessary function does it help support?)
Reorder Buffer. It allows for out of order completion/issue in stack. Allows for precise interrupts and prediction which is necessary for Virtual Memory
Speculation is a very useful technique for improving performance. However, it is not being used as extensively as was 20 years ago - why not?
With so much constraint on power, speculation often guesses wrong which means lost of wasted energy
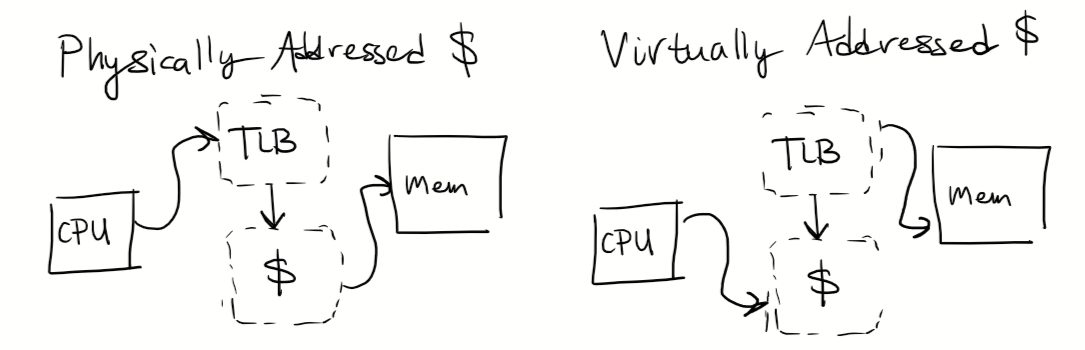
The designer has the choice of using a physically addressed cache or a virtually addressed cache.
Explain the difference (drawing a picture is fine!), and give 1 advantage for each
Advantage for Physically Addressed: There are no aliasing issues
Advantage for Virtually Addressed: faster
What is the primary difference between superscalar and VLIW processors? Give one advantage and one disadvantage to using each approach. (These have to be different - in other words, if the advantage of super-scalar is X, then you can’t say a disadvantage of VLIW is that it can’t do X.)
In superscalar, it does dynamic scheduling, while VLIW does compiler scheduling.
Superscalar advantage: better at adapting to dynamic code and changed at runtime.
Superscalar disadvantage: hardware challenge, only scheduling size of N², consumes a lot of power
VLIW advantage: simpler hardware, can see the entire program
VLIW disadvantage: compiler doesnt know runtime information, limited in speculative execution
Understanding the hardware and what is and is not good at can influence how you write high-level programs. You have been writing high level language programs for a high performance, non-pipelined
machine. You have recently received a promotion, and now your job is to write high level language programs for a heavily pipelined, high performance processor with an advanced tournament-style branch predictor and a 2 billion entry RAS. Your programs must execute as fast as possible (the emphasis is on response time), and your code will be compiled using a highly optimizing compiler at the maximum setting that still guarantees correctness (-03).
a) Give an example of how you will change the way you write your high level language program. Explain in detail why you decided to make the change (what is the problem you are overcoming?)
b) Give another example of how you will change the way you write your high level language program. Explain in detail why you decided to make the change (what is the problem you are overcoming?) Your answer must address a different problem than your answer for part a) above.
c) Which of your two changes is likely to make the biggest difference in performance, and why?
a) reduce number of indirect branches by avoiding switch statements, since it is difficult to get the BTA
b) create bigger basic blocks to give the scheduler more to work with. I could support loop unrolling by making sure that the loops have a number that a compiler knows about in the beggining
c) likely creating bigger basic blocks, since loops are really common and code scheduling allows for a large magnitude of improvement
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Decreasing cache size HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
HT: ↓ MR: ↑ MP: unchanged
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Increasing Associativity HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
HT: ↑ MR: ↓ MP: unchanged
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Decreasing Line/Block size HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
HT: unchanged MR: ↑ MP: ↓
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Nonblocking cache HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
(Assume an OOO machine)
HT: unchanged MR: unchanged MP: ↓
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Hardware Prefetching HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
(Assume prefetched data does not arrive before needed)
HT: unchanged MR: unchanged MP: ↓
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Hardware Prefetching HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
(Assume prefetched data arrives before needed)
HT: unchanged MR: ↓ MP: unchanged
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Compiler optimizations HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
(Excluding prefetching)
HT: unchanged MR: ↓ MP: unchanged
blocking, row vs column access
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Adding an L2 cache HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
(Affect on L1 parameters)
HT: unchanged MR: unchanged MP: ↓
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Physically Addressed: HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
HT: ↑ MR: unchanged MP: unchanged
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Virtually Addressed: HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
HT: unchanged MR: ↓ MP: unchanged
Find the Average Memory Access Time (AMAT) for a processor with a 2 ns clock cycle time, a miss penalty of 15 clock cycles, a miss rate of 0.20 misses per instruction, and a cache access time (including hit detection) of 1 clock cycle. Assume that the read and write miss penalties are the same and ignore other write stalls
AMAT = T(hit) + miss rate * miss penalty
1 clock cycle x 2nc clock cycle time + 2ns x 0.20 misses per inst x 15ns miss penalty
8ns
Given the following 21-bit address and a 2Kbyte Direct Mapped cache with a linesize=4, show how an
address is partitioned/interpreted by the cache.
1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 0
offset: log2(LS) = log2(4) = 2
entry: 2Kbyte = 2^11, LS = 2² => 2^11/2² => 2^9, take log of 2^9 and entry is 9 bits long
tag entry offset
1 0 1 1 0 1 1 1 || 0 0 0 1 0 1 0 0 1 || 1 0
Assuming a 21-bit address and a 96-byte 3-way Set Associative cache with a linesize=8, show how an
address is partitioned/interpreted by the cache.
1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 0
offset: log2(LS) = log2(8) = 3
set #: 96/3 = 32 => 32/8 = 2² => 2 bits
tag set # offset
1 0 1 1 0 1 1 1 0 0 0 1 01 || 0 0 || 1 1 0
Assuming a 21-bit address and a 200-byte Fully Associative cache with a linesize=2, show how an address is partitioned/interpreted by the cache.
1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 0
offset: log2(LS) = log2(2) = 1
1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 || 0
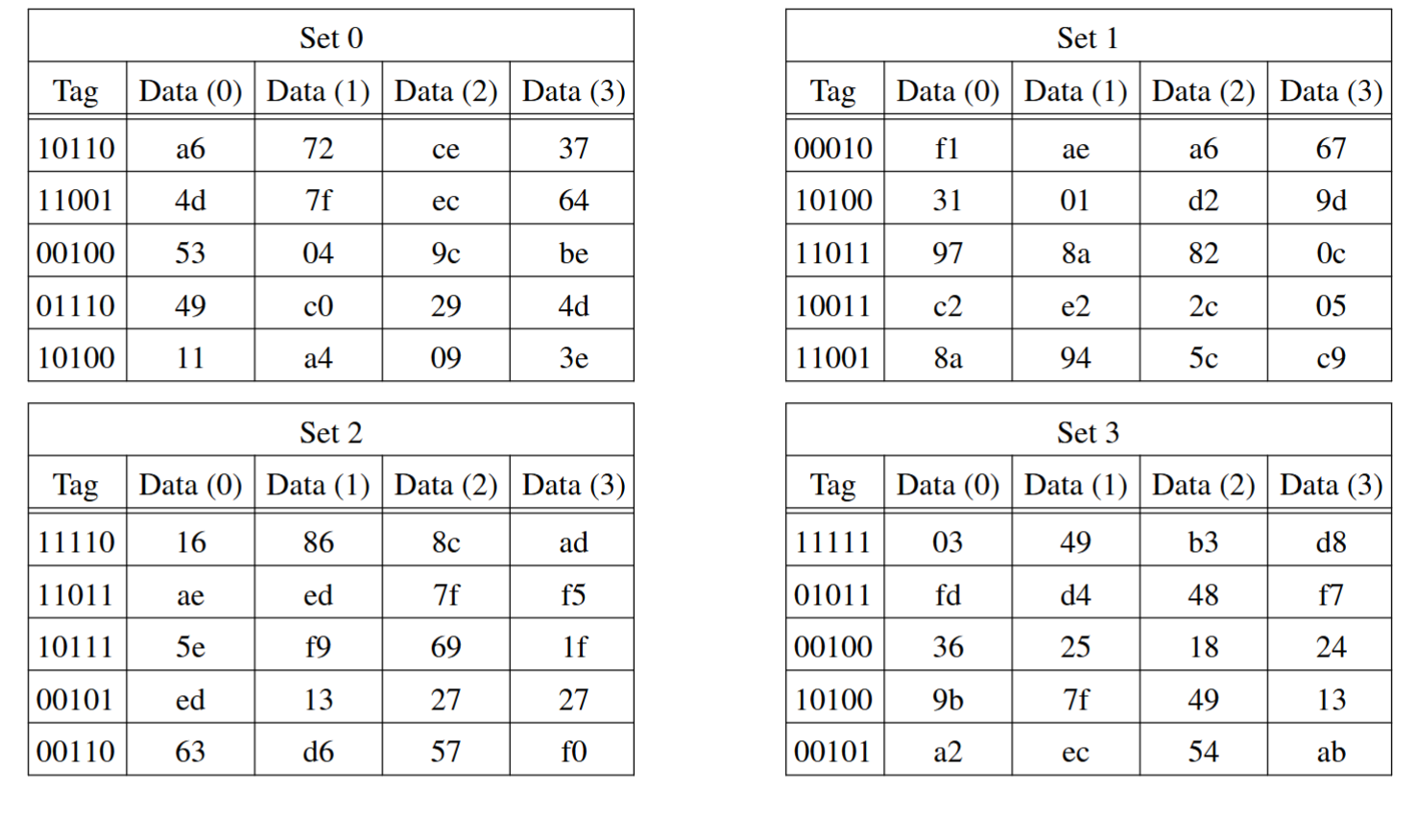
Assume an 8-bit processor, with a 40-byte 5-way set associative cache and a linesize of 4. This is the contents of the cache (all data entries are in hex; there may be more information here than you
need):
a) If the processor issues the address
1 0 1 0 0 1 1 0
Is this a hit in the cache? (YES NO) If YES, circle the entry and the data value that is returned.
b) If the processor issues the address
0 1 0 1 1 0 0 1
Is this a hit in the cache? (YES NO) If YES, circle the entry and the data value that is returned.
First, lets partition the address.
offset: log2(4) = 2
set #: 40/5 => 8/4 => 2^1 : 1 bits
a) 1 0 1 0 0 || 1 || 1 0
Yes, it is a hit in the Cache in Set1. Data being returned: d2
b) 0 1 0 1 1 || 0 || 0 1
No, not a tag in Set0
Are first level caches more concerned about minimizing hit time or miss rate?
hit time
Are second level caches more concerned about minimizing hit time or miss rate?
miss rate
Does the Virtual memory system use write-through or write-back? Why?
Write back, since write back avoids frequent writes to disk by delaying
There are some hardware structures which are fully associative and use true LRU, even over a large number of addresses - what is an example, and why would designers do that?
Fully associative caches has the lowest miss rate with the tradeoff of being slower, and since the miss penalty for the TLB is really large, we would use fully associative cache when we are using a TLB since we want to avoid misses as much as possible.
What are the three types of misses?
conflict, capacity, compulsory
What is a conflict miss?
When you have a mapping scheme and two addresses go to the same spot, even though there are empty holes in the cache
What is a capacity miss?
When a cache cannot contain all the blocks needed to satisfy the request
What is a compulsory miss?
When you have never been to the address before, so there is no way it is in the cache.
What is the difference between a write back cache and a write through cache
a write through cache halts operation until the memory is updated, a write back cache simply updates the cache, and marks the location as recently changed (dirty bits) and updates the memory later
When a write misses a cache, what are two possible approaches
write allocate, no write allocate
Page tables can be extremely large. Describe one technique we discussed in class that allows only a subset of the page table to be permanently resident in memory. (Using pictures here is a good idea.)
We can have a base page table in memory, which contains pointers to a secondary page table, which is in virtual
What principle makes Virtual Memory possible?
locality
Does an average program’s locality behavior remain the same during the entire run of the program?
no
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Adding a Victim Cache HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
(Assume it is accessed in parallel)
HT: unchanged MR: ↓ MP: unchanged
For each of the following techniques, circle the arrow(s) associated with each of the terms in the Average Memory Access Time which indicates how (on average) that term is affected. If there is more than one answer, then circle more than one term. For example, if the HT goes up, you would circle the up arrow - if the HT goes down, circle the down arrow. If the HT is unaffected, do not circle anything. Assume there is a single L1 cache.
Adding a Victim Cache HT: ↑ ↓ MR: ↑ ↓ MP: ↑ ↓
(Assume it is accessed in serial, not in parallel)
HT: unchanged MR: unchanged MP: ↓
Circle the type of cache miss that can be changed by altering the mapping scheme.
Compulsory Conflict Capacity Coherence
conflict
Circle the type of cache miss that can be reduced by using longer lines.
Compulsory Conflict Capacity Coherence
compulsory
Advances in technology allow us to make both transistors and wires smaller and smaller. If everything else is held constant, what happens to the power density as things shrink?
power density rises