Unit 1 (STATS - 1000)
1/139
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No study sessions yet.
140 Terms
Statistics
Set of methods for obtaining, organizing, summarizing, presenting and analyzing data
Data
Comes from characteristics measured on individuals, or units
Individuals/ Units
Nearly anything: people, animals, places, things, etc
Observations
collected data values
Population
Totality of individuals about which we want information
Sample
Subset of the individuals in a population that we actually examine in order to gather information
Good sample
Representative of the populations
Identifying the population that a sample represents
replace the sample size with “all”
Variable
characteristic or property of an individual.
Examples of possible variables
Lifespan of a light bulb, The number of heads in five tosses of a quarter, Hair colour
Classifications of data
categorical and quantitative
Categorical data
values of categorical/qualitative variables.
These are variables that place individuals into one of several groups categories.
Categorical variables (examples)
Eye colour
Favourite singer
Reason for taking STAT 1000
Categorical and ordinal
meaningful, logical ordering to the values of a categorical variable.
Categorical and nominal
not a meaningful, logical ordering to the values of a categorical variable
Quantitative data
Represents quantitative variables
Quantitative variables are
Take numerical values for which arithmetic operations (such as subtracting, averaging, etc.) make sense (i.e. their results are meaningful).
Quantitative variables (examples)
Height
Volume of air in a balloon
Exam score
Time
Data distribution tells us:
What values a variable takes, and How often it takes these values
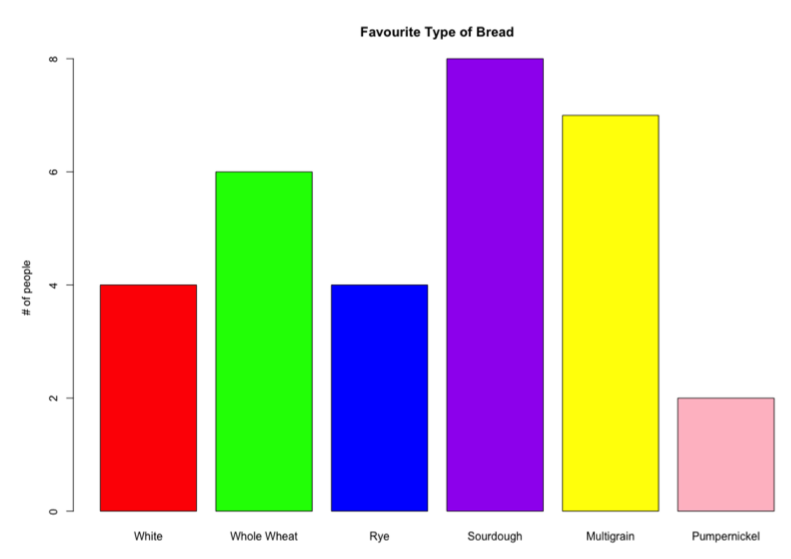
Bar Charts
Display variable values on one axis, and frequencies on the other.
Bars don’t touch (not continuous)
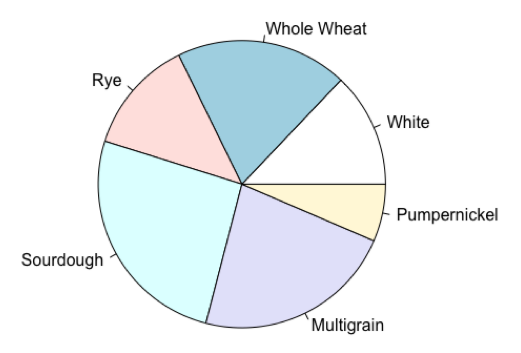
Pie charts
visual representation of the relative frequency/proportion of the observed values for a categorical variable
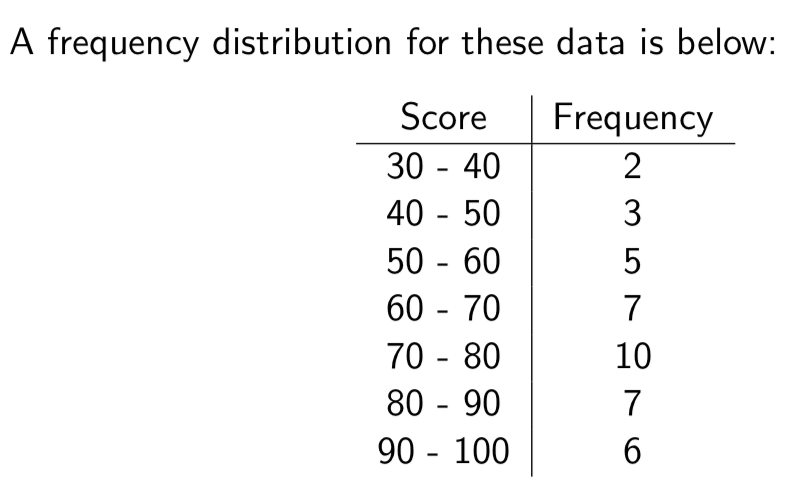
Frequency distribution
count of how many of our data values fall into various predetermined classes or intervals

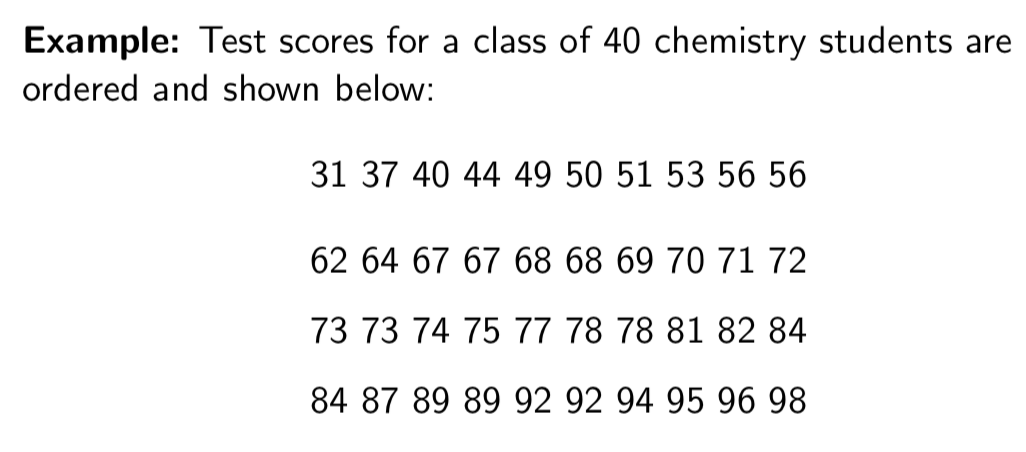
Frequency Distribution Example
Relative frequency distributions
Dividing the number of data values in each class by the total number of data values, we get the relative frequency, or proportion of individuals in each class
Proportions (relative frequency distributions)
Values between 0 and 1 that are decimal representations of fractions. You can convert proportions to percentages by multiplying by 100.
Relative frequency distribution Example

Frequency distribution (intervals)
choose them ourselves
Frequency distribution (interval rules)
Our first interval must include the lowest data value (called the minimum)
Our last interval must contain the highest data value (called the maximum)
All intervals should be of equal length
Each interval includes the left endpoint, but not the right
Choosing the intervals (frequency distribution)
“nice choices”, that summarize our data well. We’d typically use around 5 - 10 intervals total
Why cant we just use non-overlapping intervals?
because of decimals (continuous variables)
70-79 how about 79.5?
Continuous variables
These are quantitative variables that can take any value within a given range.
Continuous variables (examples)
Test scores, age, height, distance
Discrete variables
These are quantitative variables that can only take a “countable” number of values: i.e. they can only take a specific, distinct values.
discrete variables (examples)
The number of children in a family
The number of days of rain in a month
The number of books a person has read in their life
Histograms
More useful and commonly used display of continuous data
Graphical displays of the frequency (or relative frequency) of data values falling into each of several intervals.
Histograms are especially useful when we’re dealing with large data sets.
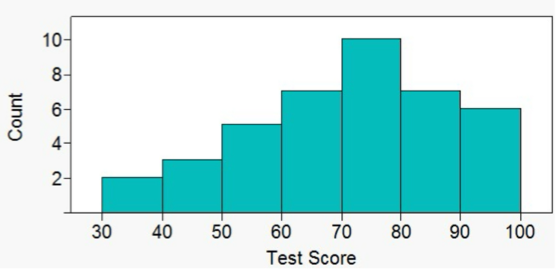
What type of data is used for a histogram
continuous, quantitative data
Why is there no spaces between the bars in a histogram
because they are continuous data
What does the base of a histogram represent
length of the interval (equal length)
What does the height of a histogram represent
the frequency of the data in each interval
Distribution shape (histogram)
A histogram can be used to characterize the shape of the data distribution
Symmetric
Skewed to the right
Skewed to the left
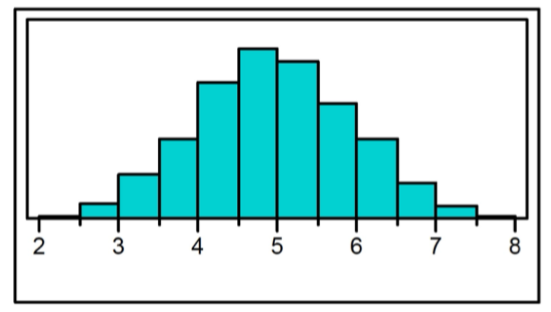
Symmetric shape (histogram)
center divides it into two approximate mirror images
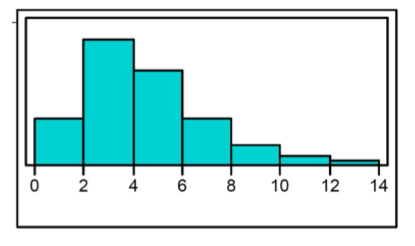
Skewed to the right (Histogram)
longer tail on the right side
most of the data values are concentrated on the left
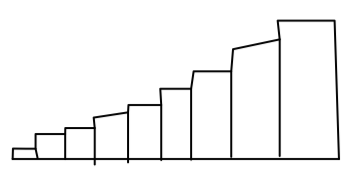
Skewed to the left (Histogram)
longer tail on the left side
most of the data values are concentrated on the right.
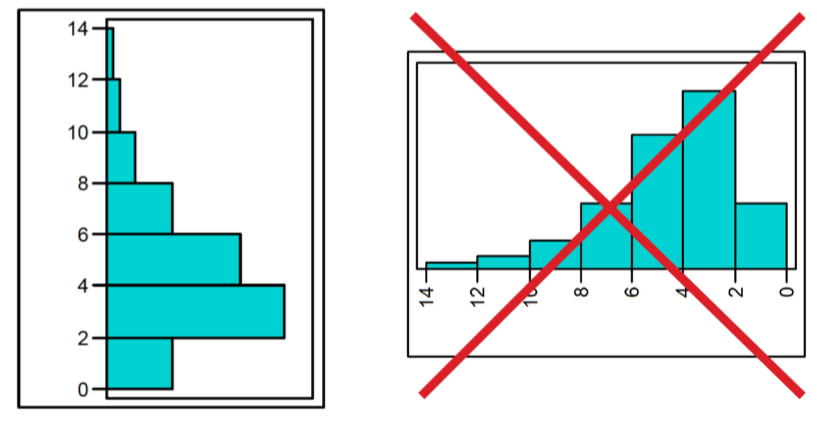
Distribution shape (!!WARNING!!)
Be careful interpreting the shape of a histogram if it’s displayed vertically!!
x-axis has to start at 0 (when flipped horizontal)
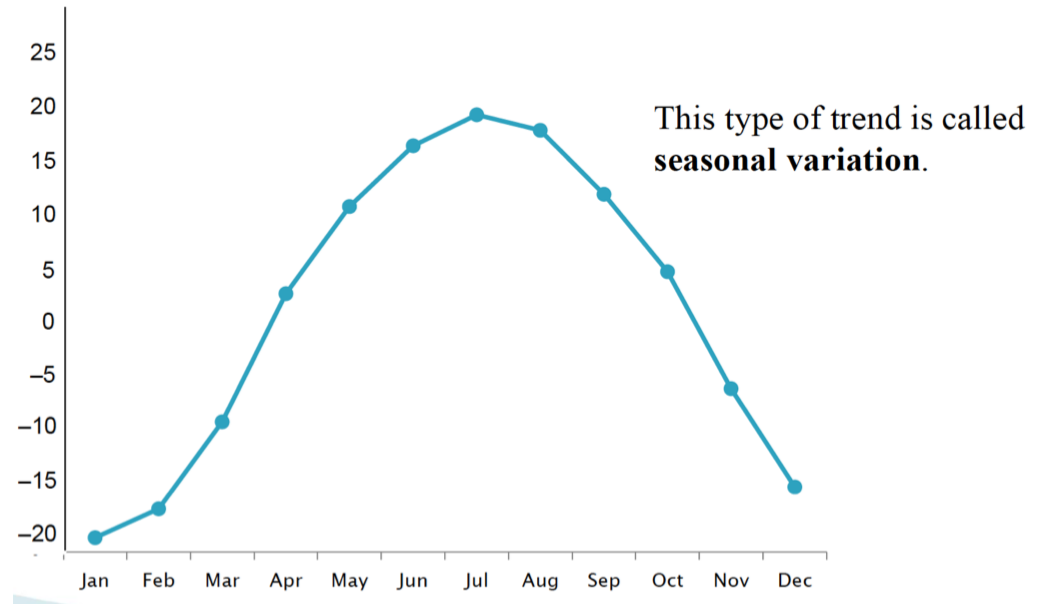
Time series data
which are values for a variable measured over time
How can you visually display time series data
time plots
What constitutes a Time Plot
Time is plotted on the x - axis, and variable values are plotted on the y - axis
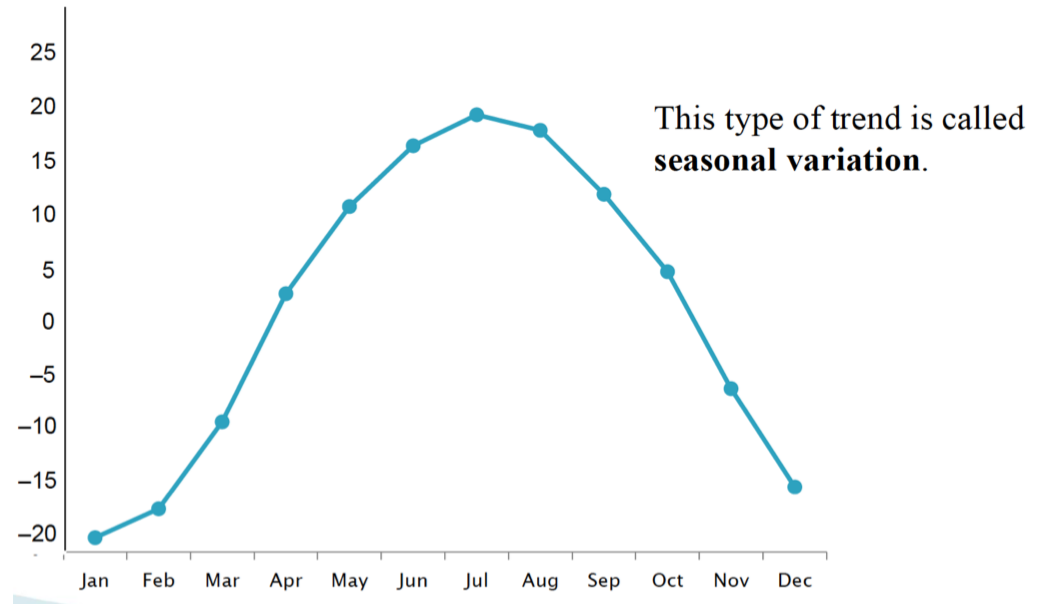
How is data represented on a Time Plot
Data values are represented by points. We connect these points to better visualize the pattern/trend.
Seasonal variation (time plot) {example}
fluctuations in data values that occur at regular intervals due to seasonal factors, showing predictable changes at specific times of the year.
Numerical Summaries of Data
Two important features of a data set that we describe using numbers are its location and variability
Measures of Location
our data is determined by where the center of our data falls.
mean
median
mode
Mode
Most frequently observed data value
Can you have more than one mode
it is possible
Median value
“middle value” in an ordered data set.
Half of the data values are less than or equal to the median, and the other
half of the data values are greater than or equal to the median.
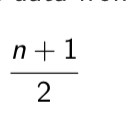
What is the first step to make sure the median is accurate
Ensure the data set is ordered.
What must you do if the n is odd (median)
You locate the middle value directly.
What must you do if the n is even (median)
take the average of the two middle values.
Mean
The average of a data set, calculated by adding all values together and dividing by the number of values.
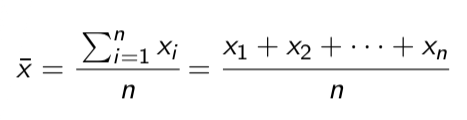
What is a extreme value (or outlier)
An extreme value, or outlier, is a data point that significantly differs from other observations in a data set, potentially skewing the results.
Which is resistant to outliers
The median
Which is not resistant to outliers
The mean
Is resistance to outliers a good thing?
Yes
a more accurate representation of the central tendency of the data, making analyses less sensitive to extreme values.
what is the advantage of the mean
It takes all data points into account, providing a measure of central tendency that reflects the overall dataset.
Median as a Measure of Center
It is simple to visualize how the median measures the center of the data: it divides the data set in half
Mean as a Measure of Center
center of mass” or “balance point” of the data.
How do the mean and the median for a given data set compare?
symmetric distribution
In a skewed distribution
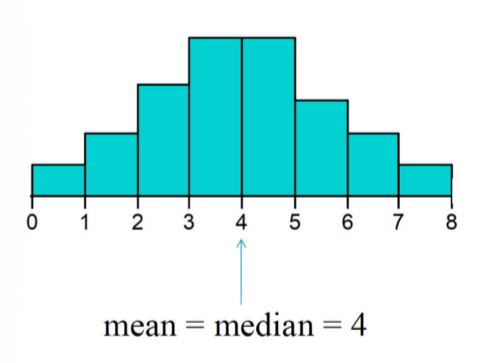
Symmetric distribution (given data set)
the mean and median are equal
Skewed distribution (given data set)
The mean follows the tail
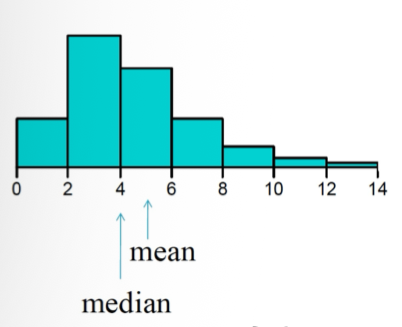
right-skewed
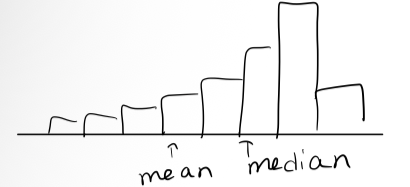
Left skewed
Right skewed (skewed distribution)
The mean is greater than the median
Left skewed (skewed distribution)
The mean is less than the median
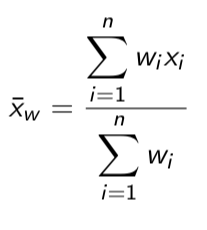
Weighted mean
Sometimes when we’re calculating the mean, some data values are given more weight than others
Some values are observed more frequently, or because some values are more “important” than others
Variability
How going to discuss how to numerically describe the variability of quantitative data
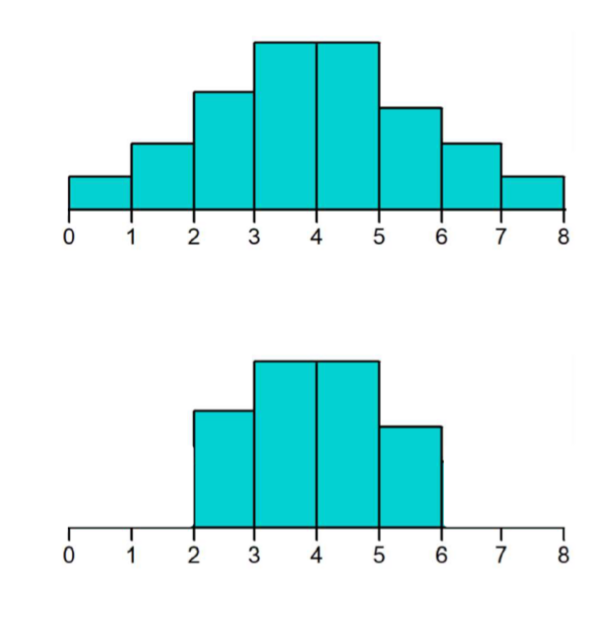
Difference
Both are approximately symmetric
The center of the distributions are approximately equal
The variability/spread is different:
The distribution on top has higher variability than the distribution on the bottom (the data is more “spread out”)
Measures of variability
Range
Interquartile Range
Range
This is the difference between the greatest observation and the least observation
Range formula
R = maximum - minimum
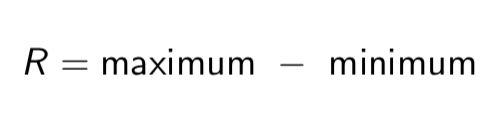
is range affected by extreme values?
Yes, range is sensitive to extreme values.
outliers how can they occur
in measurement
legitimate observations, BUT we might not be interested in including these extreme values in our numerical summary of the data
Interquartile range
measures the length of the interval that covers the middle 50% of the ordered observations.
Does the interquartile range exclude outliers?
Yes, it excludes outliers because it focuses only on the central 50% of data.
What is the first and third quartile
The endpoints of this interval
first quartile
Value where at least 25% of our observations are less than or equal to Q1
75% of our observations are greater than or equal to Q1
Third quartile
Value where at least 75% of our observations are less than or equal to Q3
25% of our observations are greater than or equal to Q3
How to find Q1 (first quartile)
Take the median of all the data values lower than the (data’s) median
don’t include counting the median
How to find Q3 (third quartile)
Take the median of all the data values higher than the (data’s) median
count from the maximum of the data set
how to solve for the interquartile range
Subtract Q1 from Q3 to find the IQR
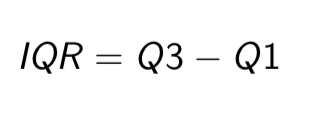
Percentiles
Percentiles are values that divide a dataset into 100 equal parts, indicating the percentage of scores that fall below a particular data point.
Percentile (class)
P-th percentile of a data set is a value such that p% of observations are less than or equal to the p-th percentile, and at least (100-p)% of observations are greater than or equal to the p-th percentile
What is the five-number summary
The five-number summary consists of five descriptive statistics that provide a quick overview of a dataset:
The minimum
first quartile (Q1)
median
third quartile (Q3)
maximum
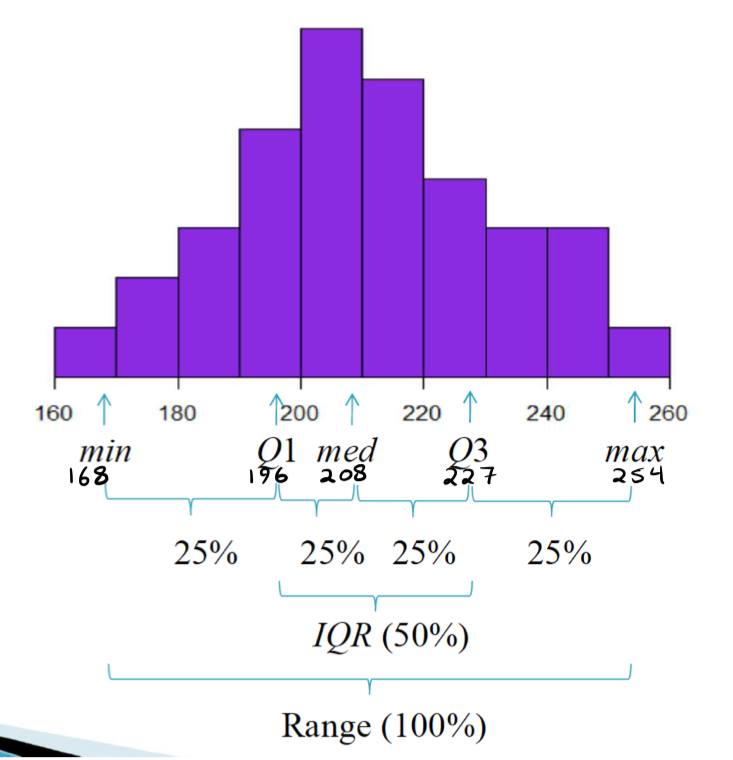
What does the five number summary divide the data into
The five-number summary divides the data into four intervals,
25% each
What does the Five number summary describe?
The center/location of our data
The spread/variability of our data
The shape of our data
Quantile boxplot
five - number summary to get a “picture” of our data,
What does a quantile boxplot consist of
A number line at the bottom, drawn horizontally
A vertical line at the median
A box around the median that covers the IQR
Lines (called “whiskers”) that extend from the box out to the minimum and maximum
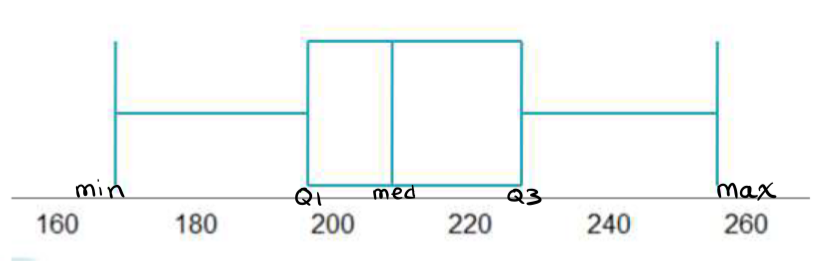
How do you know if the boxplot is skewed to the left
left is longer than on the right, it indicates left skew.
How do you know if the boxplot is skewed to the right
If the right whisker is longer than the left, it indicates right skew.
Vertical boxplot
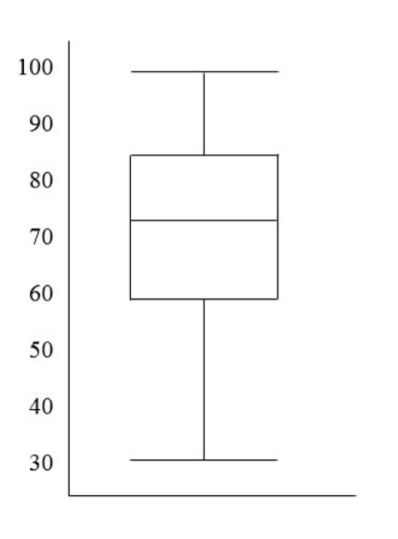
How do you know if the boxplot is skewed to the left (vertical)
The lower line is longer
How do you know if the boxplot is skewed to the right (vertical)
The upper line is longer.
side-by-side boxplots
Comparative visual display of two or more boxplots to analyze differences in distributions.
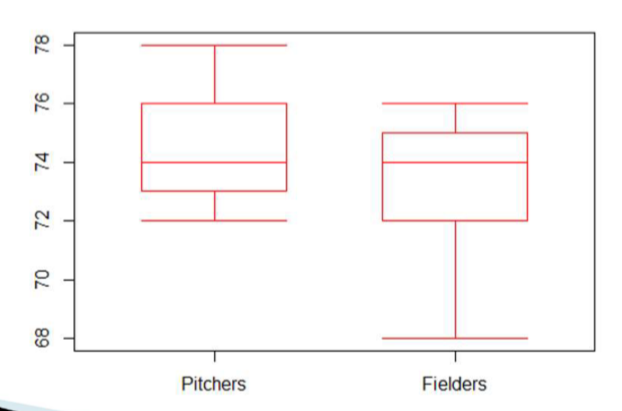
The side-by-side boxplots below compare the height distributions for Toronto Blue Jays pitchers and players in other fielding positions: (example)
The median heights for pitchers and fielders are equal
The distribution for pitchers is skewed to the right and the distribution for fielders is skewed to the left
The IQR for pitchers and fielders are equal, but the range for fielders is greater