7. Differentially-Private Stochastic Gradient Descent
1/15
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
16 Terms
How are ML models trained (formula)?
Minimize loss function.
Values of the parameters Θ determine the loss → should be minimized.

How does Stochastic Gradient Descent work?
Stochastic → Sampling training data instead of computing loss / gradient over entire dataset.

What is the purpose of using Minibatches in Stochastic Gradient Descent?
Using only single examples from the training data results in noise in the loss computation, were we want to estimate the loss of the entire dataset → Batching will reduce noise.

What is the best angle to privatize Stochastic Gradient Descent?
Add noise to the gradient
→ See gradient as a query to the data.
→ If gradient is DP, the rest of the model is also DP.
What are problems in privatizing Gradients?
Unbounded Sensitivity of Gradient:
To privatize we need to compute the sensitivity.
Gradients can be anything from 0 to ∞ → would mean we need to add (almost) infinite noise!
SGD is multi-step / mechanism
By the rules of basic composition → need to add up privacy budget to (kε, kδ)-DP for k steps.
Leads to excessively high overall privacy budget (ε).
How can we solve the problem of unbounded sensitivity of gradients? (Private SGD)
Clip the gradients using a hyperparameter C.
Per-example L2 norm.
=> Gradient will still point in correct direction = slower.
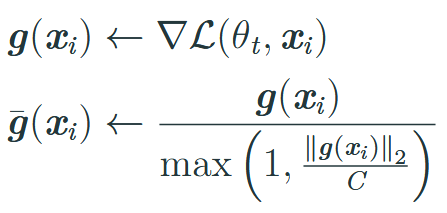
How is the problem of SGD being multi-step/mechanism solved? (Private SGD)
Instead of rules for basic composition (k*ε), we use rules of advanced composition (≈ √k · ε).
Advanced composition is closer to the actual worst-case.
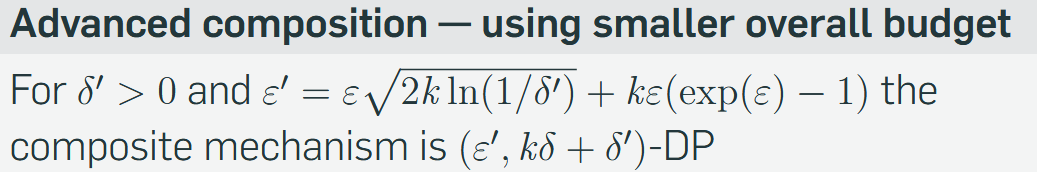
What is Poisson Sampling?
Each entry in a database is subject to an independent Bernoulli trial. 1 = keep for sample, 0 = drop.
What is the goal of sub-sampling for Private SGD?
Instead of drawing minibatches from our data, do poisson sampling with a parameter β.
ε2 = ln (1 + β [exp(ε1) − 1])
δ2 = βδ1
=> Required privacy budget decreases in respect to β.
![<ul><li><p>Instead of drawing minibatches from our data, do <strong>poisson sampling</strong> with a parameter β.</p></li><li><p>ε<sub>2</sub> = ln (1 + β [exp(ε<sub>1</sub>) − 1])</p></li><li><p>δ<sub>2</sub> = βδ<sub>1</sub></p></li></ul><p>=> Required privacy budget decreases in respect to β.</p>](https://knowt-user-attachments.s3.amazonaws.com/57ecaf82-1995-4772-a073-5a5d78dd7bcf.png)
What characterstics does the DP-SGD algorithm have?
Poisson Sub-Sampling for sampling lot.
Clip gradient.
Add (multivariate gaussian) noise to clipped gradient.

What are disatvantages of DP-SGD?
Bad scalability because of slow per-example gradient norm + gradient clipping.
What is the general relationship between Privacy Budget and performance in NLP tasks?
General trade-off between performance and privacy.
Higher privacy budget (less privacy) —> better performance.
What is the idea behind a “Privacy Accountant” in DP-SGD?
Compte privacy loss at each access to training data → accumulate throughout training.
Tightest privacy by numerical integration to get bounds on moment generating function of the privacy loss random variable.
What are User-adjacent datasets?
Two datasets that differ in all of the examples associated with a single user.
What are differences between Batching and Poisson Subsampling?
Size of batch/sample: Batch will always be same size, poisson sample size can differ.
For DP → Poisson has formal privacy gurantee, while batchin breaks privacy empirically.
=> Poisson sampling = slower training since sample size changes.
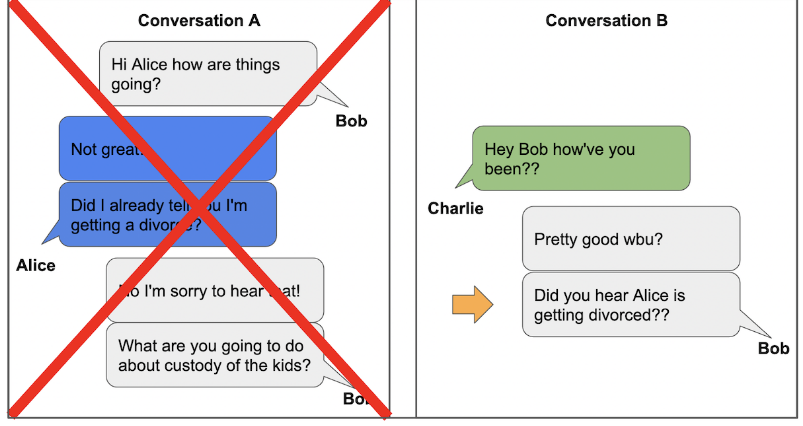
What is tricky about protecting private information in text (f.e. chats)?
Private information about one person can be present in text from another.
Even in chats not including the privacy holder, private information might be revealed.