DM Exam 1
1/25
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
26 Terms
Error(E)=
y_i-(mx_i+b)
Standard Error(SE)=
(\frac{var(E)}{var(x)})^{\frac{1}{2}}
95\% Confidence Interval=
m \pm t(1-\frac{\alpha}{2},n-2)\cdot SE
We reject the null hypothesis when…
…the p-value is less than or equal to 0.05 or the confidence interval doesn’t include 0.
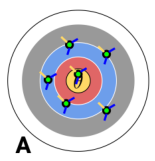
This target has a…
…low bias, high variance.
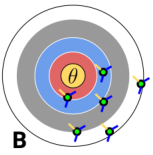
This target has a…
…high bias, high variance.
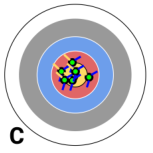
This target has a…
…low bias, low variance.
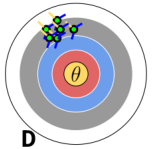
This target has a…
…high bias, low variance.
Empirical Distribution Steps:
Take a random sample of length l with replacement.
Perform function.
Append to sample list.
Repeat n times.
Exploratory Data Analysis Steps:
Question
Investigate
Interpret
Ask more questions
Average Error=
\frac{1}{n}\sum E
Variance=
\frac{1}{n}\sum (x_i - avg(x))²
Mean Absolute Error (MAE)=
\frac{1}{n}\sum |E|
\frac{d}{dx}|x|=
\frac{x}{|x|}
Gradient Descent=
\theta_{t+1}=\theta_t - \alpha \cdot \frac{d}{d\theta} L(y,\hat{y})
The difference between Gradient Descent and OLS is…
…Gradient Descent sets m and b multiple times and uses the derivative of the gradient, while OLS relies heavily on matrix operations and sets m and b once.
MAE introduces bias by…
…treating all errors as positive, meaning the total error only gets added to, not subtracted from.
Stochastic Gradient Descent differs from Gradient Descent by…
…only using a small, random subset of the population each iteration.
Correlation
The measure of how much a variable will change given the change of another variable.
Error
The difference between the real value and the predicted value.
A model with high correlation and a high error…
…has variables that are very related to each other, but the model itself is an inaccurate predictor.
A model with a low correlation and a low error…
…is an accurate predictor, but uses variables that are unrelated to each other.
P(x|y)=
\frac{P(y|x)P(x)}{P(y)}
Given P(x|y) and P(y), P(x)=
P(x|y)P(y)
When given a large dataset, Gradient Descent can be faster than OLS because…
…OLS relies heavily on expensive matrix operations, while Gradient Descent relies on looping and the derivative of the loss function.
OLS achieves the line of best fit by…
…taking the derivative of the loss function with respect to each parameter, setting it to 0, and solving for the parameter.