21. Du brut au traitable - Le pré-traitement des données
1/44
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
45 Terms
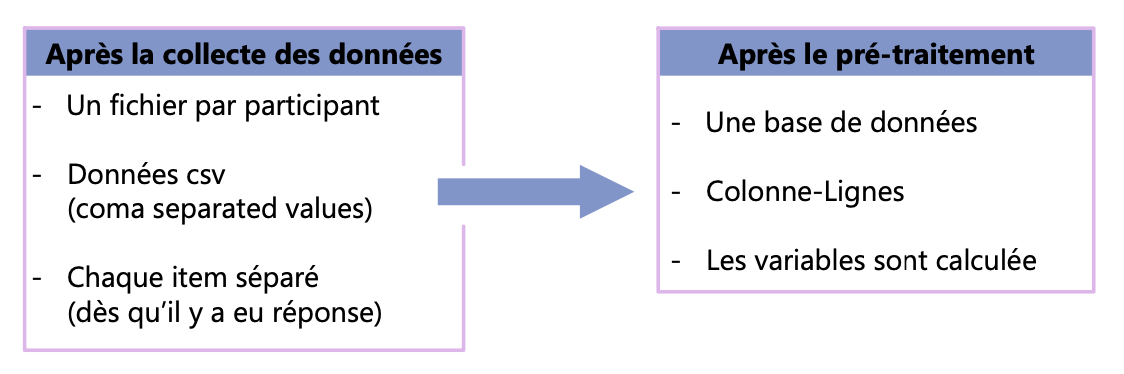
Pourquoi on pré-traite les données ?
Ce qu’on obtient des participants ≠ ce qu’on doit analyser
Le pré-traitement est une étape fondamentale
Les données brutes sont souvent bruitées, incomplètes ou mal structurées … et surtout non-analysables
Une mauvaise préparation peut entraîner des conclusions erronées et un gaspillage de ressources
Les erreurs de saisie et les valeurs aberrantes fausses les données
Pré-traitement des données
Mise en forme / nettoyage des données
Permet de passer des données brutes aux données analysables
Vise à garantir la qualité et la fiabilité des résultats en corrigeant les erreurs, en traitant les valeurs manquantes et/ou aberrantes
La mise en forme des données vise à pouvoir analyser les données à l’aide des logiciels statistiques en respectant le format nécessaire aux analyses prévues
Objectifs du pré-traitement des données
Ils visent à améliorer la qualité des données, à assurer leur cohérence, et à maximiser la précision des analyses statistiques en éliminant les erreurs et en comblant les lacunes.
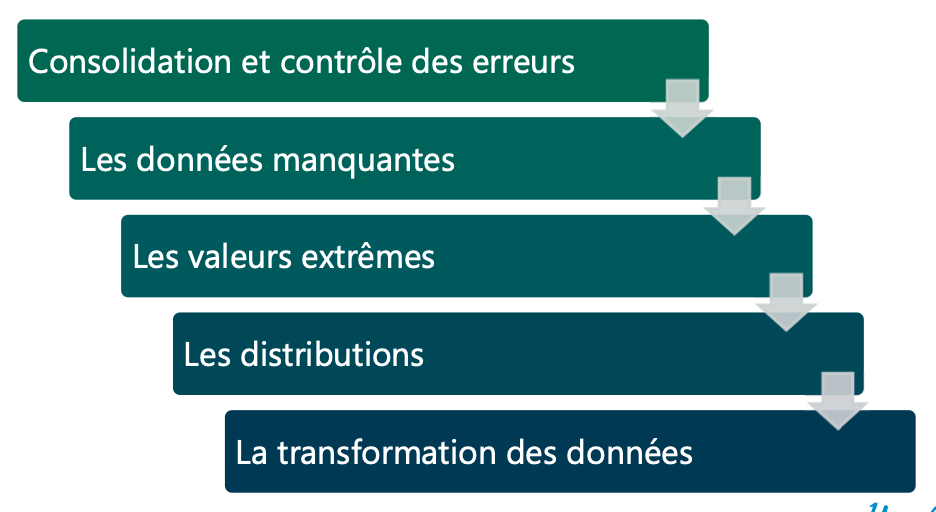
Étapes du pré-traitement
CCE : Consolidation des données
Processus de regroupement de plusieurs fichiers de données individuels en une seule base de données structurée
CCE : Fusion (merging)
Assemblage de plusieurs fichiers en fonction d'une variable commune, généralement l'identifiant du participant.
CCE : Intégration (integration)
Rassemblement de données provenant de sources différentes, comme des questionnaires, des mesures physiologiques et des performances comportementales.
Doublon
Un participant enregistré plusieurs fois dans un jeu de données.
CCE : Les doublons
La présence de doublons peut fausser les analyses en attribuant un poids excessif à certains participant
Peut arriver car il a complété l’étude plusieurs fois, a recommencé l’étude, ou a été saisie deux fois
Si le code n’est pas assez spécifique (unique) : il se peut que ce soit deux participants différents
CCE : Que faire des doublons ?
Sʼassurer de lʼunicité du code (avant la récolte de données)
Voir si il est possible de savoir si cʼest le même participant ou non (Date de naissance? Autre identifiant?)
Si cʼest deux différents: les garder les deux (en trouvant un moyen de les distinguer)
Si cʼest le même: en général ne garder que la première occurrence du remplissage (peut impliquer une fusion) → évite apprentissage ou fatigue
CCE : Erreur de codage ou d'enregistrement
Incohérence ou inexactitude survenue lors de la saisie, de la transformation ou de l'enregistrement des données
Ces erreurs peuvent fausser les analyses et compromettre la validité des résultats
CCE : Que faire avec les erreurs de codage ou d’enregistrement ?
Repérage :
Contrôler les valeurs minimales et maximales de chaque cellule (pour chaque type de variable)
Identifier toutes les cellules problématiques (pas uniquement le maximum et le minimum)
Action :
Si on peut retrouver l’information exact (à 100% sûr) → insérer les valeurs correctes
Si on ne peut pas retrouver l’information → valeurs manquantes
Valeurs manquantes
Absence de certaines observations dans un jeu de données, ce qui peut affecter l'analyse statistique et biaiser les conclusions
Elles peuvent être dues à diverses raisons, comme des erreurs techniques, des choix des participants, ou des biais systématiques liés aux variables étudiées
Le choix de la méthode de coercition dépend du champ, de la question de recherche, et des types de valeurs manquantes (impact potentiel sur les analyses)
Types de données manquantes
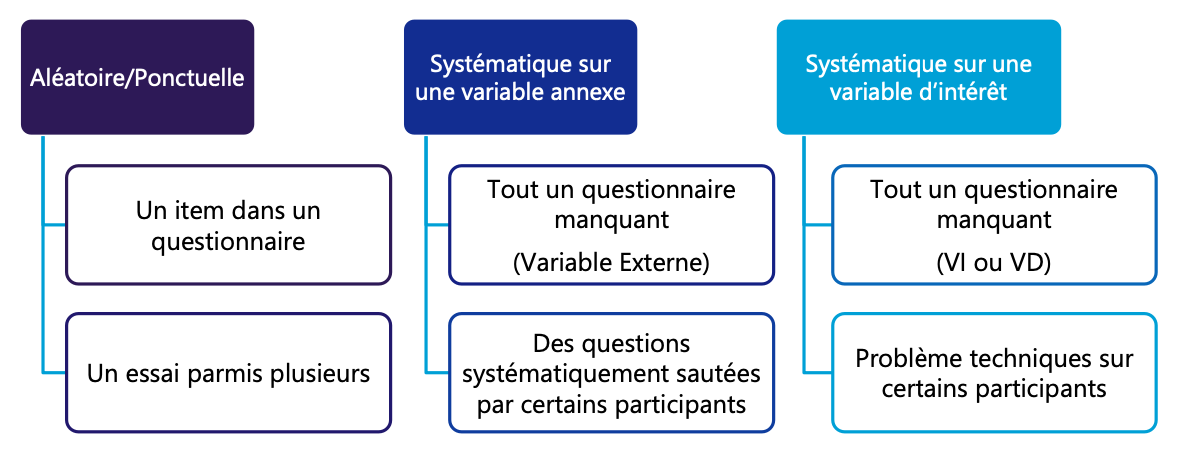
DM : Solution pour les erreurs aléatoires
Si on peut retrouver lʼinformation (par exemple pour un manquement lors du passage du questionnaire papier à la base de données) → Ajouter les données correctes
Laisser tel quel (surtout si item dʼun questionnaire) → Vérifier le bon scoring dans la sous-dimension
Imputer les données
Lʼimputation consiste à remplacer les valeurs manquantes par une estimation
Prendre la moyenne des autres items → réduit la variance
Imputer par regression (prédiction) de lʼitem manquant → suppose une relation linaire
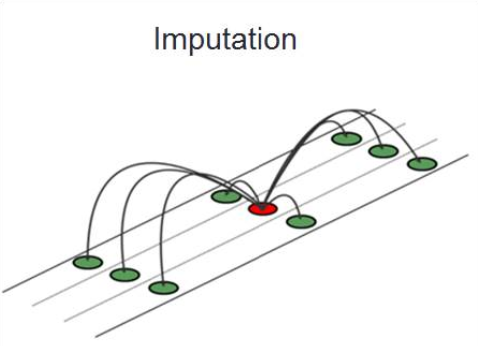
Imputer les données
Remplacer les valeurs manquantes par une estimation (moyenne des autres items, régression).
DM : Solution pour les erreurs systématiques
Variables annexes
→ Pair-wise deletion (suppression par paire de données disponibles)
Variables indépendantes ou dépendantes
→ List-wise deletion (suppression d’observation)
Pair-wise deletion (suppression par paire de données disponibles)
Utilisation de toutes les données disponibles pour chaque analyse, sans exclure complètement les participants avec des valeurs manquantes.
Chaque statistique (corrélation, régression,…) est calculé avec les valeurs présentes, sans exclure complètement les participants avec des valeurs manquantes
Permet d’exploiter le plus de données possibles sans réduire l’échantillon
Les différentes analyses seront basées sur des échantillons légèrement différents
List-wise deletion (suppression d'observation)
Suppression des lignes (observation) contenant au moins une valeur manquante
Pas d’estimation et toutes les analyses seront faites sur le même échantillon
Peux réduire drastiquement la taille de l’échantillon
Valeur extrême / aberrante – outlier
Observation qui s'écarte fortement des autres valeurs d'un jeu de données
Peut-être du à :
Des participants avec des valeurs très éloignées de celles de leur groupe (mais légitime et possible)
Une erreur de mesure
VE : Impact et seuils
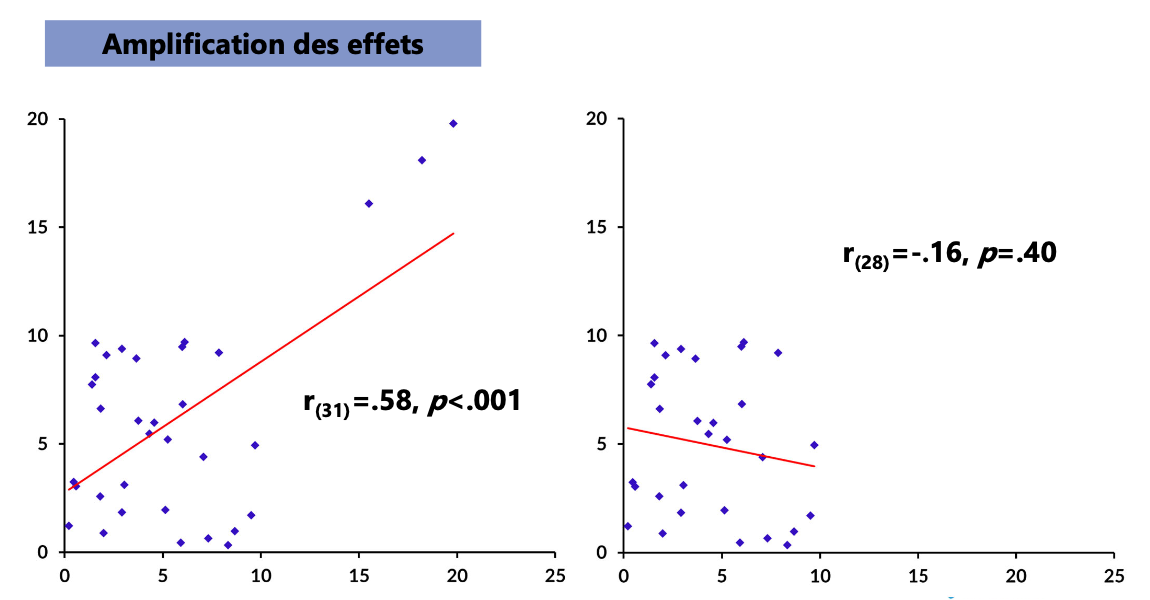
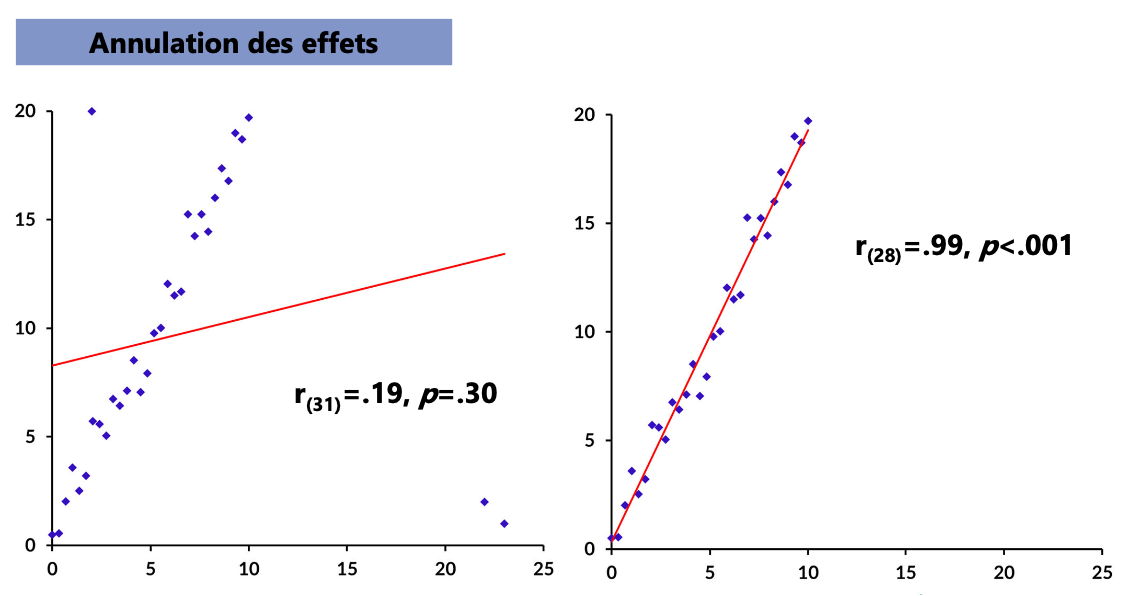
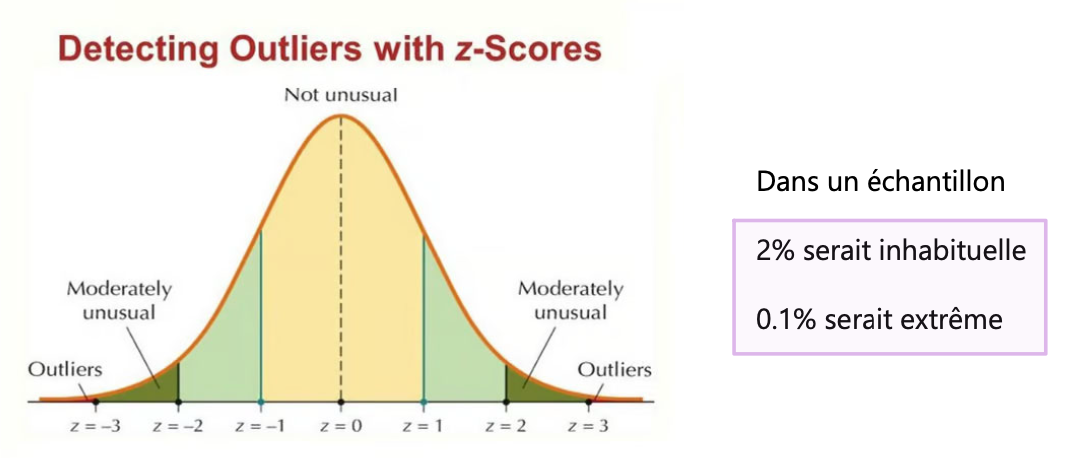
VE : Standardisation des données
Processus consistant à transformer les données afin qu'elles aient une échelle commune, ce qui permet de les comparer plus facilement
Méthode la plus connue : le Z-score
moyenne = 0
écart-type = 1
unité : “écart-type de l’échantillon”
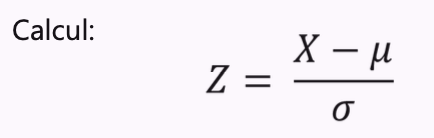
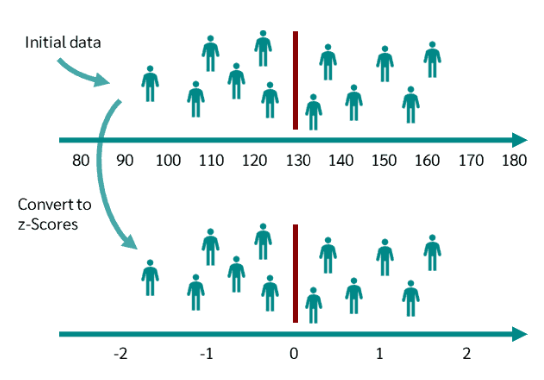
Standardisation test ≠ standardisation des données
TEST
→ processus visant à uniformiser des procédures, des mesures ou des outils pour assurer leur cohérence et comparabilité
DONNÉES
→ Processus consistant à transformer les données afin qu’elles aient une échelle commune, ce qui permet de les comparer plus facilement
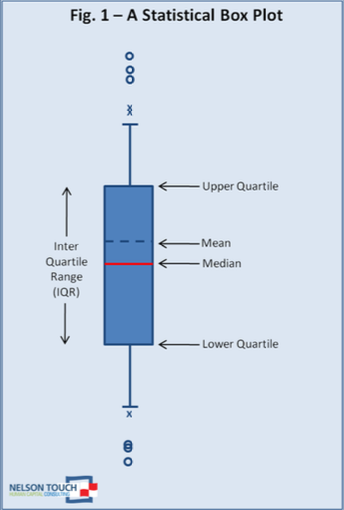
VE : représentation impact et seuils
Boîte
→ représente l’intervalle interquartile
→ contient la moitié centrale des données (50%)
Ligne médiane
→ une ligne à l’intérieur de la
Moustaches
→
Valeurs extrêmes
→
Les extrêmes bi-variés
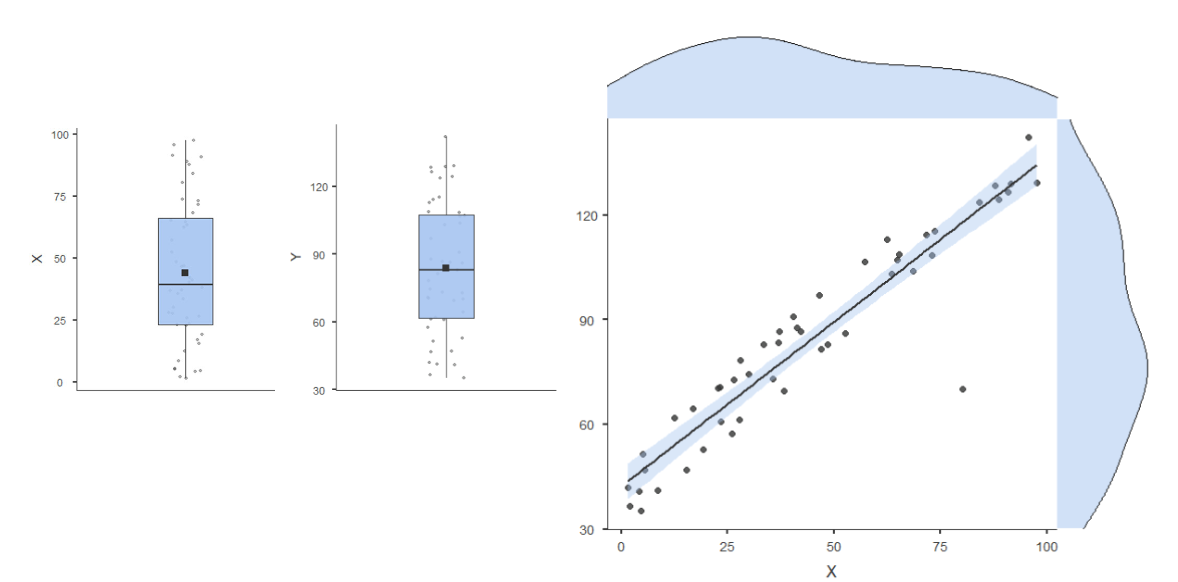
Distance de Mahalanobis
→ Mesure de la distance d'un point à partir du centroïde d'une distribution multivariée
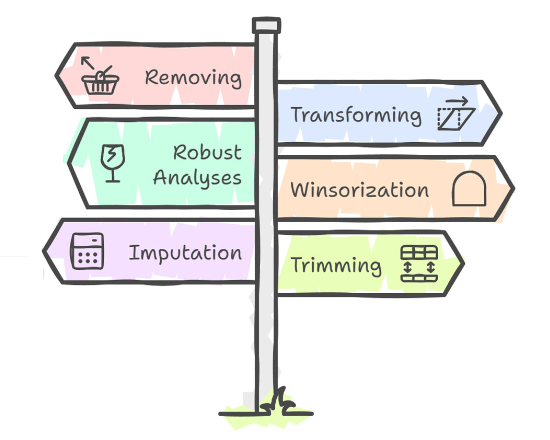
Que faire avec les valeurs extrêmes ?
Enlever ces participants
Transformer les données
Utiliser des analyses non-paramétriques
Winsorisation
Imputation
Elagage (trimming)
VE : Enlever ces participants
→ Est-ce légitime ?
→ Favoriser les analyses avec et sans
VE : Transformer les données
→ Quand les distributions ne sont pas normales
VE : Utiliser des analyses non-paramétriques
→ La majorité utilise les RANGs
→ La valeur extrême est juste “le rang suivant”
VE : Les rangs
→ Correspond à la position d’une valeur dans un ensemble de données triées (par ordre croissant ou décroissant)
→ Utilisés pour traiter des données non normales, permettant des comparaisons entre groupes. Les rangs sont attribués aux valeurs afin d'effectuer des analyses plus robustes
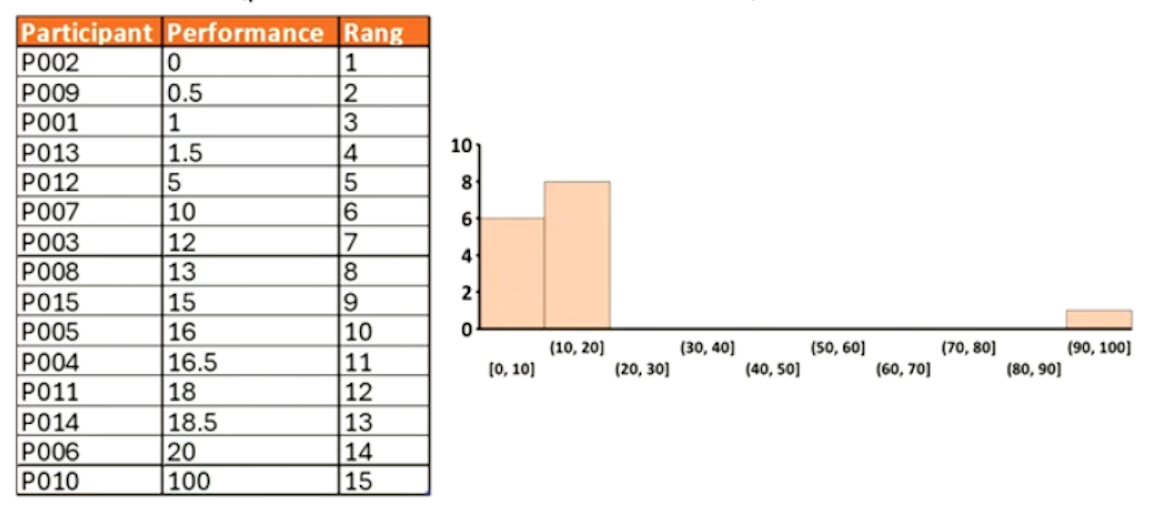
VE : Winsorisation
→ Remplacer une valeur extrême avec la dernière valeur « acceptable » (par exemple, le 5e ou le 95e percentile)
VE : Imputationn
→ Remplacer la valeur avec la valeur médiane ou une valeur estimée (par régression par exemple)
VE : Élagage (Trimming)
→ Enlever un certain pourcentage de participants aux extrêmes de la distribution
Les distributions
Résumé de toutes les valeurs ou plages de valeurs possibles dans un ensemble de données et de leur fréquence d'apparition
Moyen d’organiser et de comprendre les mesures et les données
Permet de repérer les problèmes (valeurs extrêmes ou asymétrie)
Permet de décider de la prochaine étape du traitement des données (transformation ou choix d’analyses)
Les distributions normales et ses indicateurs
→ Un type de distribution de probabilité caractérisée par sa forme en cloche, où la majorité des valeurs se concentrent autour de la moyenne.
→ Ses indicateurs incluent la moyenne, l'écart-type et la variance, qui déterminent la position et la dispersion des données.
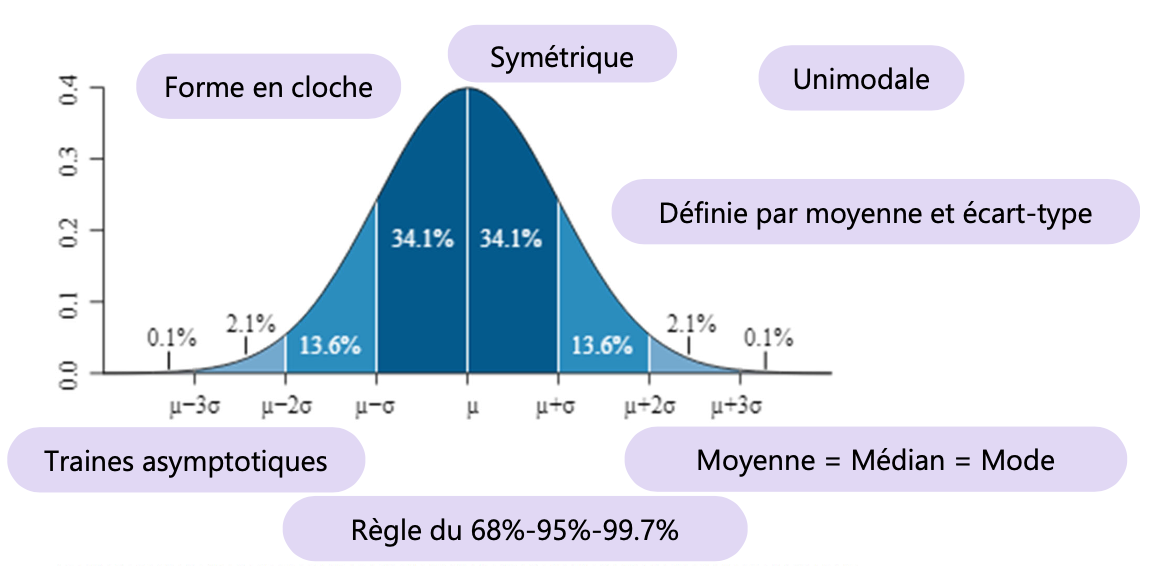
Tester la normalité
Test de Shapiro-Wilk
Utilisé pour les petits échantillons
Très sensible aux valeurs extrêmes
Test de Kolmogorov-Smirnov (K-S)
Peut être utilisé pour des échantillons plus grands
Très sensible à la déviation de la normalité
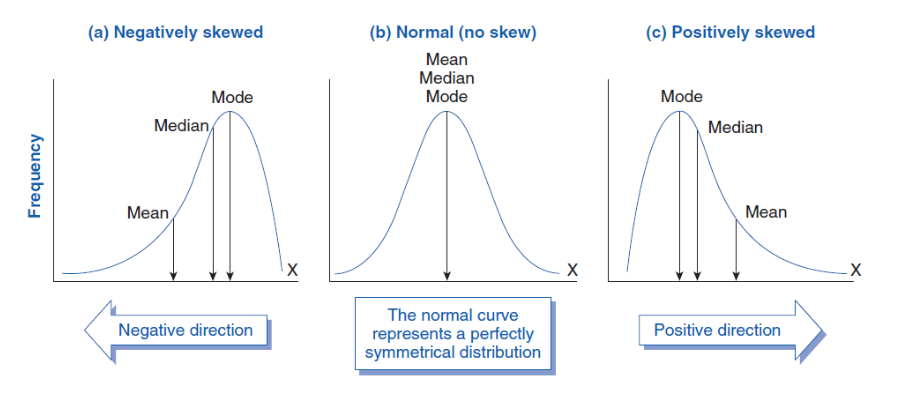
Assymétrie (Skewness)
Mesure le degré de dissymétrie d'une distribution par rapport à une distribution normale
→ regarder le coefficient d’assymétrie : signe et valeur
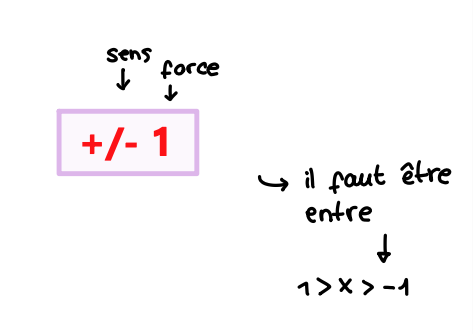
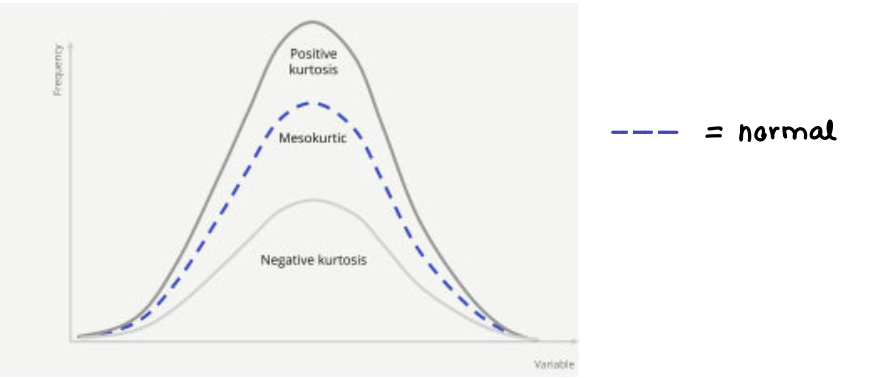
Applatissement (Kurtosis)
Mesure la propension de la distribution à produire des valeurs extrêmes
+ / - 3
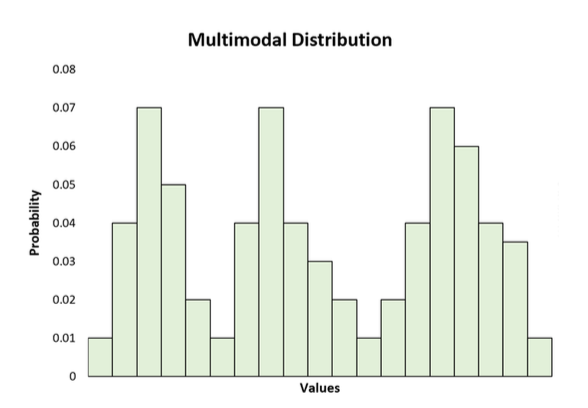
Multimodalité
Caractéristique d'une distribution qui présente plusieurs modes ou pics, indiquant la présence de plusieurs groupes ou tendances distincts dans les données
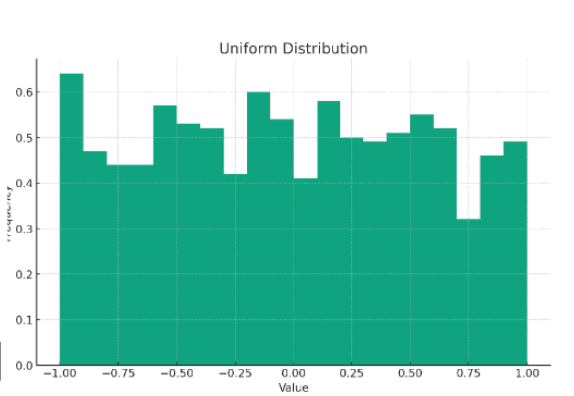
Uniformité
Mesure de la distribution des données où chaque valeur a la même fréquence, entraînant une répartition uniforme
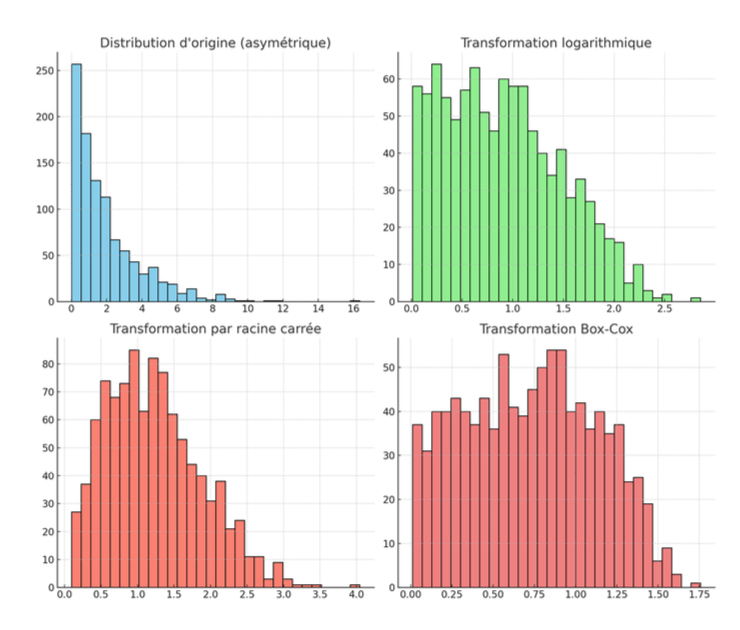
Transformation des données
→ Appliquer une fonction mathématique aux données brutes pour rendre leur distribution plus normale
Avantages :
Facilite l’utilisation de tests paramétriques en respectant l’hypothèse de normalité
Rend la distribution plus symétrique
Rend la distribution moins plates ou pointues
Atténue l’impact des valeurs extrêmes
Inconvénients :
Les données transformées peuvent devenir plus difficiles à interpréter
Certaines transformations modifient la relation avec les autres variables
Scoring des échelles
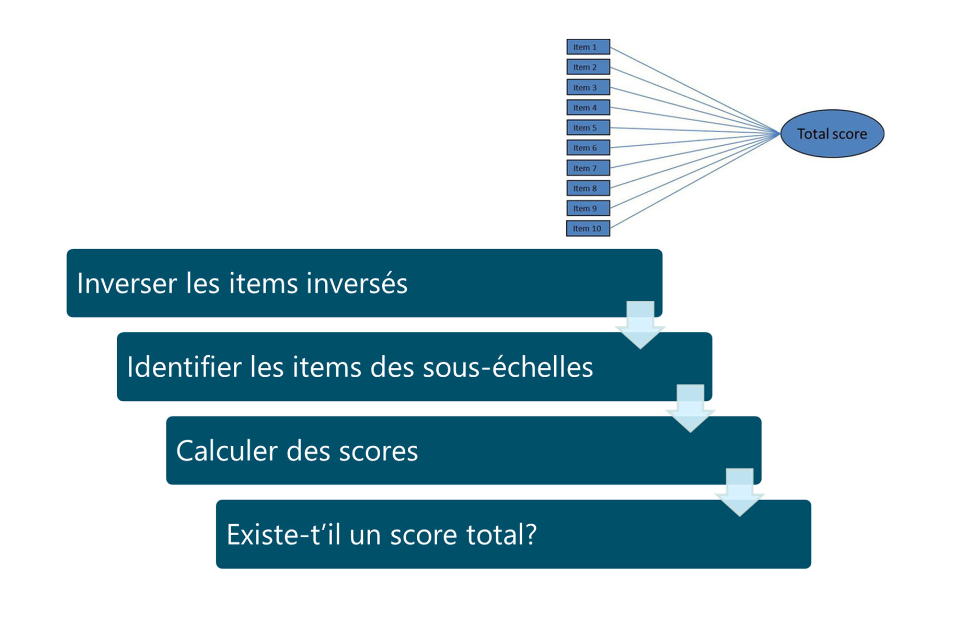
Processus d'évaluation des réponses sur une échelle prédéterminée, permettant d'attribuer des scores en fonction des performances ou des opinions des répondants.
Traçabilité
Capacité à suivre et de vérifier toutes les étapes d’un processus de recherche, depuis la collecte des données jusqu’à l’analyse et la publication
Versionnage
Garder une trace de toutes les modifications apportées à un fichier ou à un ensemble de fichiers au fil du temps