Unit 1 DNA and chromosomes (from slides)
1/85
Earn XP
Description and Tags
Defintions
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
86 Terms
Identify the four types of biomolecules within a cell and explain polymer formation for three of these biomolecules
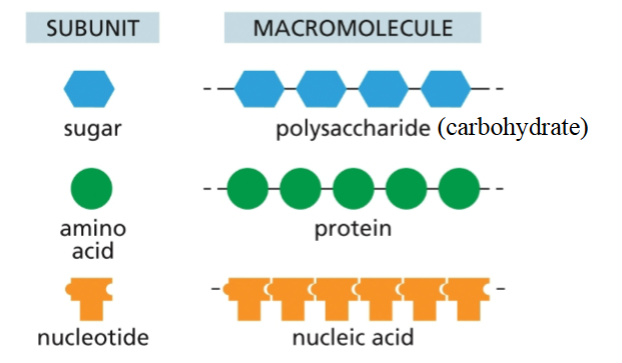
1. Carbohydrates (Polysaccharides)
Monomers: Monosaccharides (e.g., glucose)
Bond: Glycosidic linkage
Process: Dehydration synthesis – an –OH from one sugar and an –H from another are removed to form water and a covalent bond.
Result: Chains like starch, glycogen, and cellulose
2. Proteins (Polypeptides)
Monomers: Amino acids
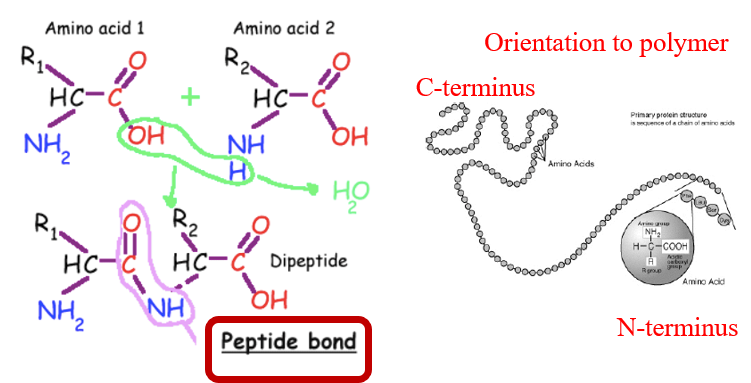
Bond: Peptide bond
Process: Dehydration synthesis – the carboxyl group (–COOH) of one amino acid bonds with the amino group (–NH₂) of another, releasing water.
Result: Linear chains that fold into functional proteins
3. Nucleic Acids (DNA and RNA)
Monomers: Nucleotides
Bond: Phosphodiester bond
Process: The 3′ hydroxyl group of one nucleotide binds to the 5′ phosphate group of the next, releasing water.
Result: A single strand of DNA or RNA with 5′ to 3′ directionality
4. Lipids (NOT true polymers)
Lipids like triglycerides are made from glycerol + 3 fatty acids, but they are not true repeating monomer chains.
Bond: Ester bond (formed via dehydration synthesis)
They’re assembled, not polymerized, and function in membranes and energy storage.
Explain the structure and function of proteins including the roles of individual amino acids in protein folding, (discussion could mention role of charge, and/or acid/base properties in levels of organization and protein-molecule interactions)
🧬 Protein Structure and Function 🔹 Basic Structure:
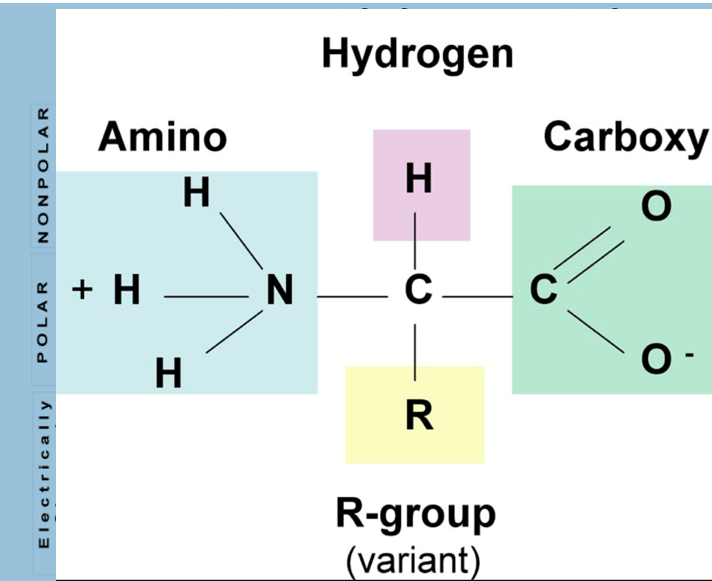
Proteins are polymers of amino acids linked by peptide bonds. Each amino acid has:
A central carbon (α-carbon)
An amino group (–NH₂)
A carboxyl group (–COOH)
A hydrogen atom
A unique side chain (R group)
🔄 Levels of Protein Structure: 1. Primary Structure
Linear sequence of amino acids
Determines all higher levels of folding
Held together by peptide bonds
2. Secondary Structure
Local folding into α-helices or β-pleated sheets
Stabilized by hydrogen bonds between backbone atoms (not R groups)
Amino acids with small, flexible side chains (like glycine) often appear in bends and turns
3. Tertiary Structure
Overall 3D shape of a single polypeptide
Stabilized by interactions among R groups, including:
Hydrogen bonds
Ionic bonds between charged side chains (acidic/basic residues)
Hydrophobic interactions (nonpolar R groups cluster inward)
Disulfide bridges (covalent S–S bonds between cysteines)
4. Quaternary Structure
Structure formed when multiple polypeptide subunits combine
Stabilized by same interactions as tertiary structure
⚙ Role of Amino Acids in Folding 🧲 Charge and Acid/Base Properties
Acidic residues (like aspartic acid, glutamic acid): Negatively charged
Basic residues (like lysine, arginine, histidine): Positively charged
These charges form ionic bonds (salt bridges), influencing folding and stability
Changes in pH can disrupt these interactions, denaturing the protein
💧 Hydrophobic vs. Hydrophilic
Nonpolar amino acids (e.g., leucine, valine) fold inward to avoid water
Polar and charged amino acids (e.g., serine, lysine) fold outward to interact with water or other molecules
🧪 Protein-Molecule Interactions (Function)
Protein function depends on shape and chemical compatibility with other molecules (ligands, substrates, etc.)
Active sites in enzymes are shaped by the precise positioning of amino acids, including:
Charged residues for electrostatic interactions
Acid/base residues to catalyze proton transfer
Hydrophobic pockets to bind nonpolar molecules
What does life do?
All living cells come from existing cells (cannot spontaneously occur)
It makes copies of itself
It creates order; not randomly occurring - has to occur at the right place at the right time in the right order
All species are related through evolution: Phylogenetic Tree of Life
Bacteria, Archaea, and Eucaryotes all come from a common ancestor cell
There are shared properties between organisms despite differences in appearance
What are the two branches of life?
Prokaryotes
not a lot of compartmentalization, has a plasma membrane separating interior of cell from exterior, bag of molecules
Eukaryotes
a lot of compartmentalization
roles for compartments
allows for specialization
has a nucleus; very dominant
also has plasma membrane made of lipids
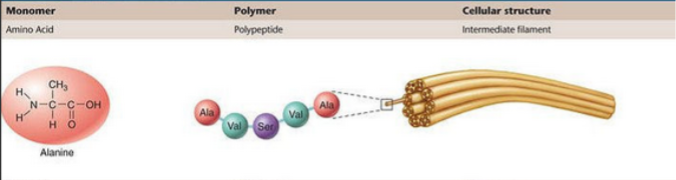
Protein (functions)
Structural and primary workhorse
Anything born from amino acids
They catalyze
Example is a polypeptide; single strand of amino acids
Bond between amino acids is peptide bond
Nucleic acids (functions)
Energy, information, and regulation
Passes down information
Regulatory; RNAs; control how we turn on gene regulation, turn off gene expression
Bond between is phosphodiester bonds
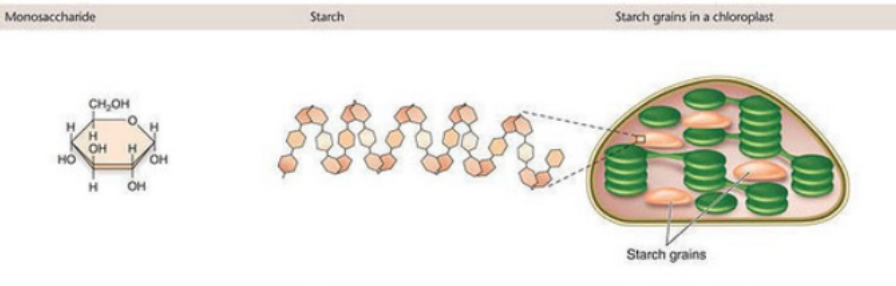
Carbohydrates (function)
Energy source/storage
Structural
Example is glucose
Sugars are stored in much larger macromolecules
Bond between is glycosidic
Lipids (function)
Barriers and long-term storage
What membranes are made of
Join to make sugar molecules; they interact but do not make polymers
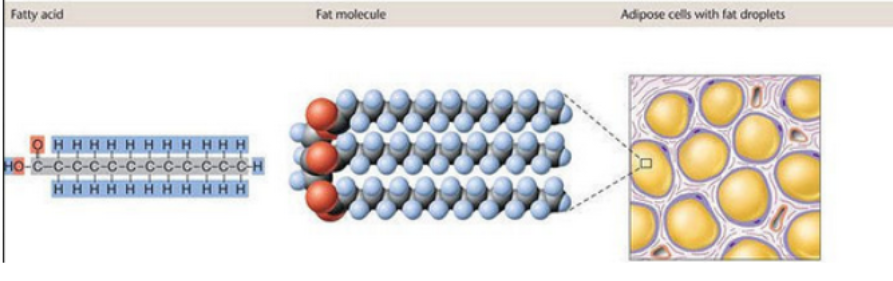
Polymers formed from monomers that are linked by Covalent bonds
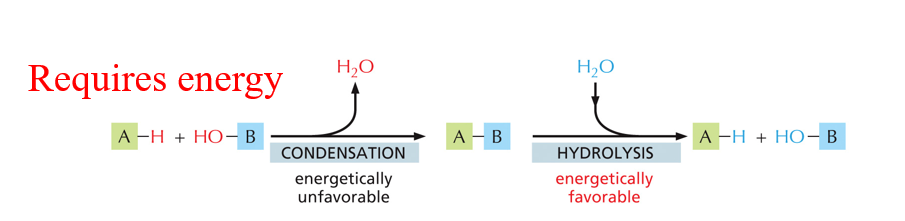
Condensation and Hydrolysis reaction
Condensation: joining monomers where the product is the release of water
Hydrolysis is energetically favorable
Polymers of 3 of the 4 families (below) of macromolecules are made (condensation) and broken down (hydrolysis) through these reactions.
1.Carbohydrates
2.Proteins
3.Nucleic acids

Each type of biomolecule is made from constituent monomeric units
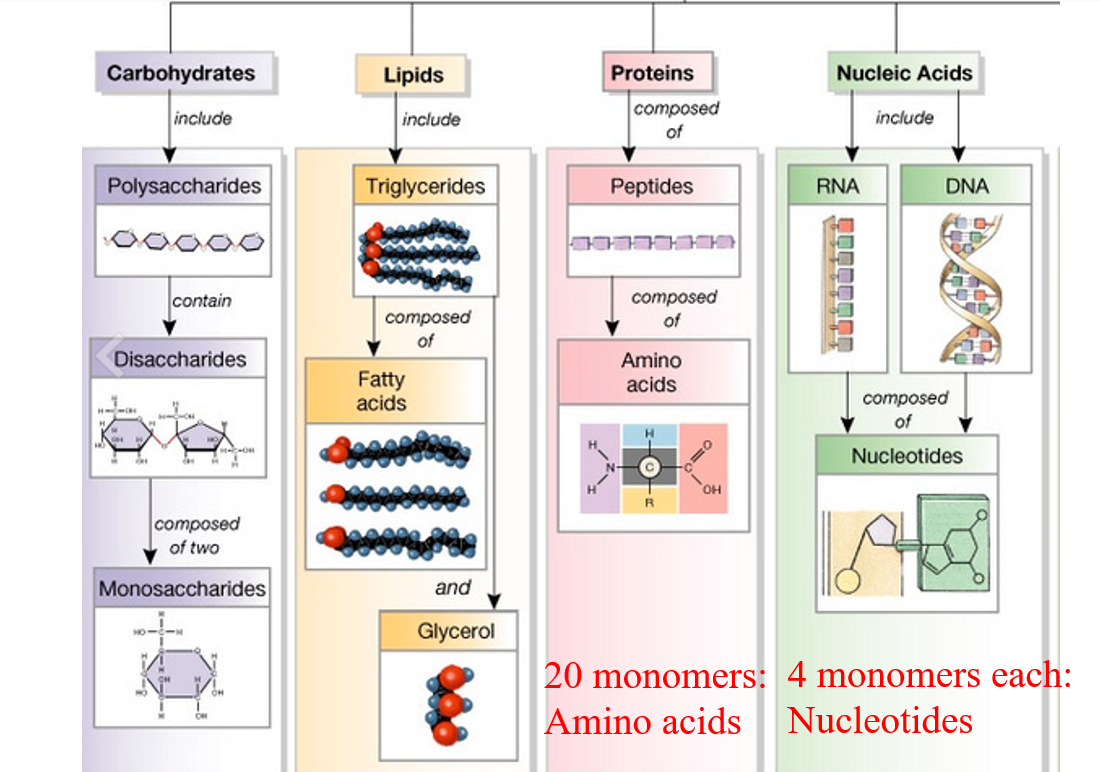
Different bonds are formed for each polymer type (macromolecules)
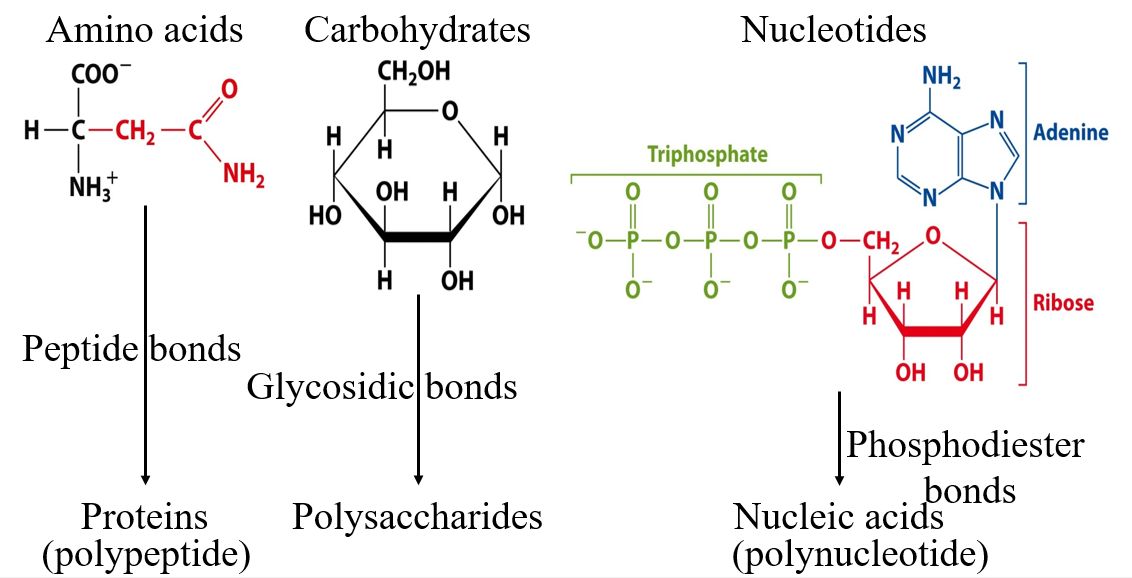
Carbohydrates are made from many different types of sugars and can form a variety of structures
Carbohydrates are banches!
Example is Glucose
Basic structure of a protein
Peptide backbones
Same for all 20 types
Has polarity
Structure of protein
R is the region that differs
Proteins are linear polymers of amino acids
N to C orientation
Amino acids have varied chemical properties
Takeaway is that the characteristics or properties associated with R groups are important for dictating how the protein/polymer folds together and how it interacts with other biomolecules
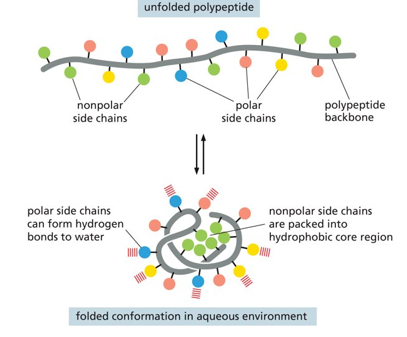
Folded versus unfolded peptide
In an unfolded peptide there are both polar and nonpolar side chains
In a folded confirmation (in aq environment) the polar side chains can form hydrogen bonds to water and the nonpolar side chains are packed into hydrophobic core region (resistant to aq)
Disease state
Supposed to make hexagon but made ball
Mutations can lead to disease state
Proteins fold into 3D shapes
occurs within peptide backbone
3D orientation + amino acid sequence = diverse chemical properties
primary structure; amino acid sequence
secondary structure; regular sub-structure
tertiary structure; three dimensional
quaternary structure; complex of protein molecules
the final shape is determined by the R group
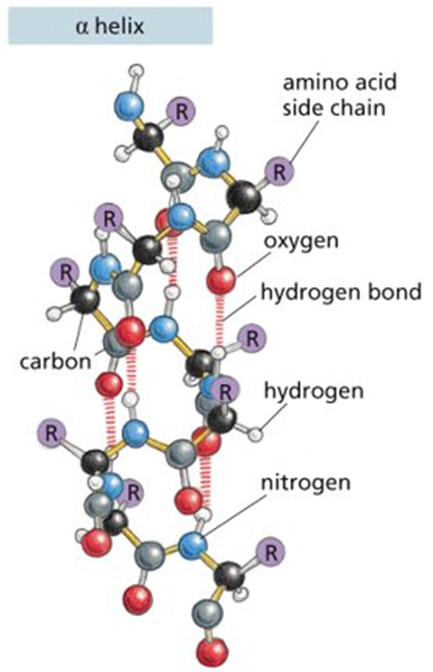
Example of secondary structure: noncovalent bonds form between atoms of peptide backbone only

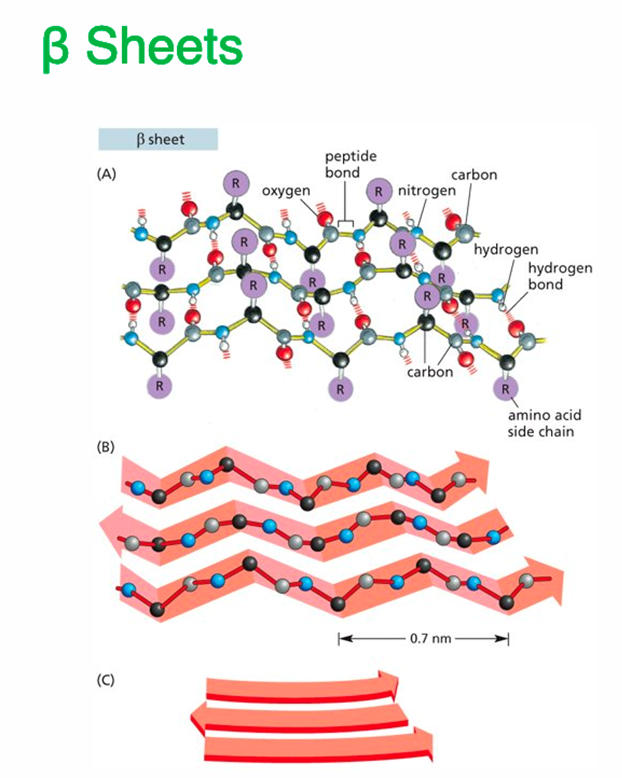

Example of secondary structure: noncovalent bonds form between atoms of peptide backbone only

Tertiary structure
folding results in the specific 3D shape
determined largely by interactions between R-groups
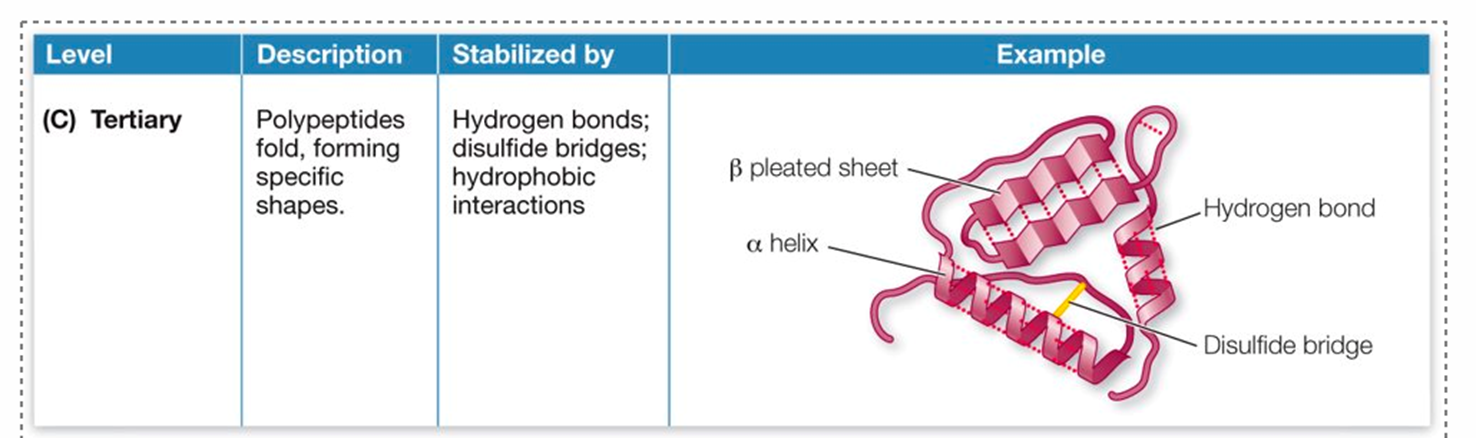
Quartenary structure
🧬 Quaternary Structure of Proteins – Summary
Definition:
The quaternary structure is the highest level of protein organization, formed when two or more polypeptide chains (subunits) assemble into a functional protein complex.
📦 Key Features:
Involves multiple polypeptides, each with its own tertiary structure
Subunits can be identical (homomers) or different (heteromers)
Held together by:
Hydrogen bonds
Ionic bonds
Hydrophobic interactions
Van der Waals forces
Sometimes disulfide bonds
⚙ Function:
Enables cooperative behavior (e.g., oxygen binding in hemoglobin)
Allows structural complexity and regulation
Some proteins are only functional in their quaternary form
a lot are noncovalent interactions are not very strong (rely on larger # of interactions to occur)
amino acid sequence is important here as well
protein-protein interactions are lock in key
shapes and charges determine the fit
enzymes catalyze particular chemical reactions
type of protein that can perform catalytic activities
bad ones won’t stay associated
Protein interactions
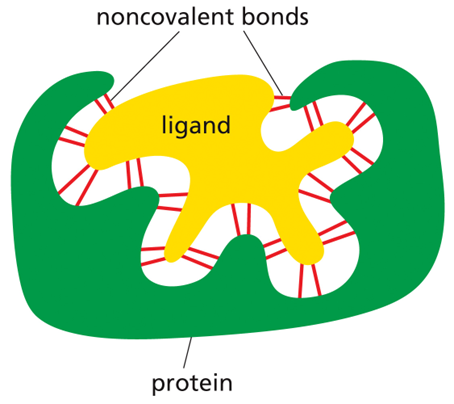
the activity of the protein depends on its ability to bind specifically to other molecules (R group specificity)
the number of molecules required to carry out an activity varies from one to a few to dozens
each noncovalent interaction is weak, ligand must fit/align very closely with the protein so many weak interactions can occur simultaneously
few interactions: molecules dissociate quickly
some interactions: productive interaction but will not persist
many interactions: molecules will remain associated for a long time
ligand
the molecule that a protein can bind to (can be an ion, small molecule, or macromolecule)
binding site
the part of a protein that interacts with the ligand (consists of a cavity formed by a specific arrangement of amino acids)
high chemical complexity allows proteins to perform complex functions
interactions with other proteins, nucleotides, carbohydrates, and lipids
some proteins bind specifically to other proteins
some proteins bind DNA
most cellular functions are performed by proteins
motors move along scaffolds to transport materials within the cell
receptors allow communication between outside and inside of cell
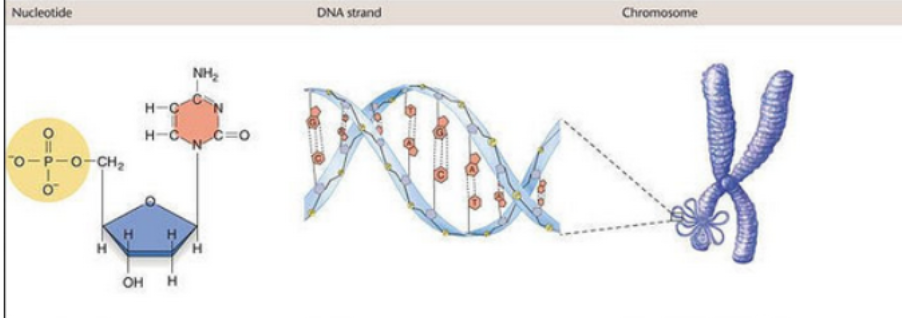
identify the parts that make up a nucleotide
Phosphate Group (PO₄³⁻)
Usually attached to the 5′ carbon of the sugar
Provides negatively charged backbone
Links to the 3′ carbon of the next nucleotide via a phosphodiester bond
Five-Carbon Sugar (Pentose)
Two types:
Ribose (in RNA) – has an –OH on the 2′ carbon
Deoxyribose (in DNA) – has an –H on the 2′ carbon
Serves as the scaffold that connects the base and phosphate
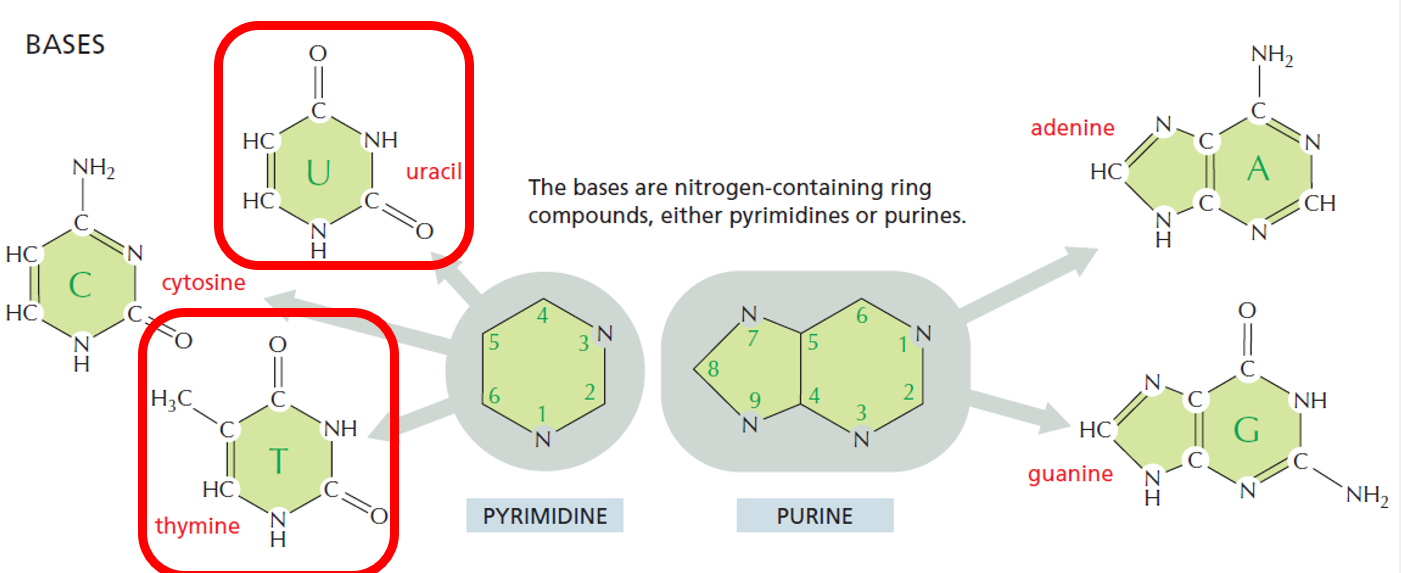
Nitrogenous Base
Attached to the 1′ carbon of the sugar
Can be a:
Purine: Adenine (A), Guanine (G) – double-ring structure
Pyrimidine: Cytosine (C), Thymine (T, in DNA), or Uracil (U, in RNA) – single-ring structure
Determines base pairing and genetic code
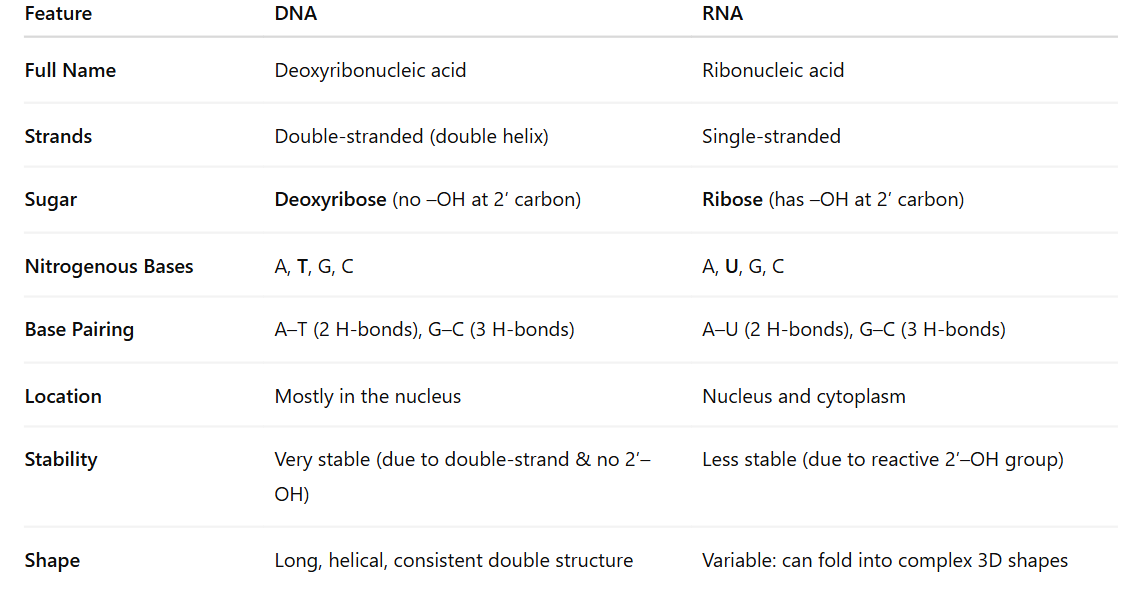
Compare and contrast the structures of RNA and DNA and explain how their organizational structure contributes to their roles
DNA – Long-term Information Storage
Double helix: Protects genetic code from damage
Complementary base pairing: Enables accurate replication
Deoxyribose: Lacks 2′ OH, making it chemically stable, ideal for long-term storage
Strandedness: The two strands act as templates for replication and error correction
RNA – Short-term Information Transfer & Functional Roles
Single-stranded: Allows folding into complex 3D shapes for catalysis (e.g., ribozymes), binding, and regulation
Ribose sugar with 2′ OH: Increases reactivity—suited for temporary tasks
Uracil instead of thymine: Slightly cheaper for the cell to produce and sufficient for RNA’s temporary role
Different forms of RNA:
mRNA: Carries genetic info to ribosome
tRNA: Brings amino acids during translation
rRNA: Catalyzes protein synthesis in ribosomes
Other small RNAs: Regulate gene expression
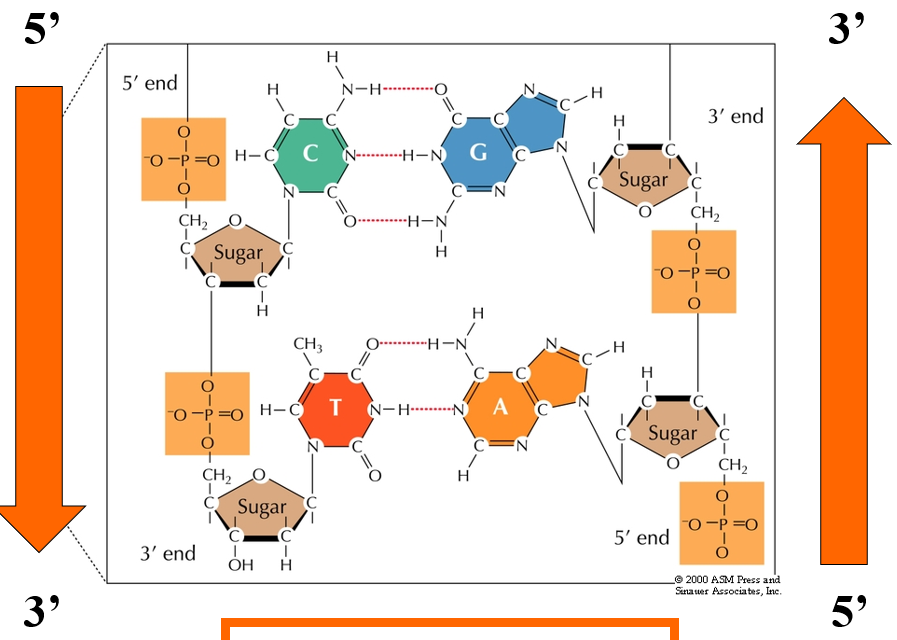
Identify the different ends of a DNA/RNA molecule
A DNA or RNA strand has two distinct ends due to the orientation of its sugar-phosphate backbone. This is called structural polarity or directionality:
🧬 In Double-Stranded DNA:
The two strands run antiparallel:
One strand runs 5′ → 3′
The complementary strand runs 3′ → 5′
⚙ Why These Ends Matter:
DNA/RNA synthesis always proceeds in the 5′ to 3′ direction (new nucleotides are added to the 3′ end).
Enzymes like DNA polymerase and RNA polymerase recognize and act based on this directionality.
During transcription and translation, the correct orientation ensures accurate copying and expression of genetic information.

Predict the complimentary DNA strand of a given RNA sequence
If the RNA sequence is:5' - A U G C C U A G A - 3'
The complementary DNA strand will be:3' - T A C G G A T C T - 5'
Or written 5' to 3' (reverse the strand):
5' - T C T A G G C A T - 3'

Deoxyribonucleic acid (DNA)
is the cellular library and contains the information for coding for the correct amino acid sequence in proteins as well as many types of RNA.
Ribonucleic acids (RNA)
are used as the messengers (intermediary between DNA and amino acid sequence), may have regulatory roles or structural roles
Nucleic acid structure
Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) are composed of biomolecule monomers called nucleotides
Nucleotides have a nucleoside + a phosphate group
A nucleoside is a five-carbon sugar ring (pentose) + an organic base
Difference in RNA and DNA pentose rings
Ribose has hydroxyl at C2 position, but there is just H in DNA
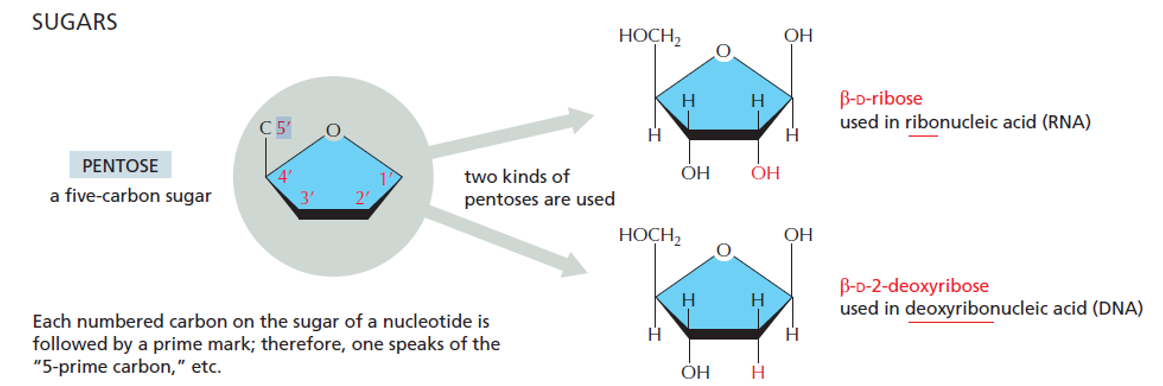
Nucleoside
base covalently attached to C1 of sugar backbone
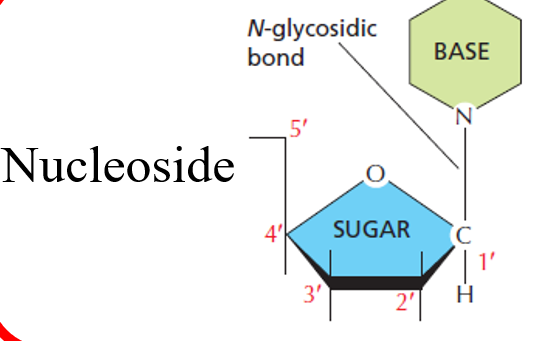
Nucleotides
consists of a nitrogen-containing base, a five-carbon sugar, and one or more phosphate groups (a nucleoside with one or more phosphates attached)
Organic bases
nitrogen-containing ring compounds, either pyrimidines or purines
4 different bases used by nucleic acids;
DNA uses ACGT
RNA uses ACGU
Pyrimidines are TCU
Purines are GA
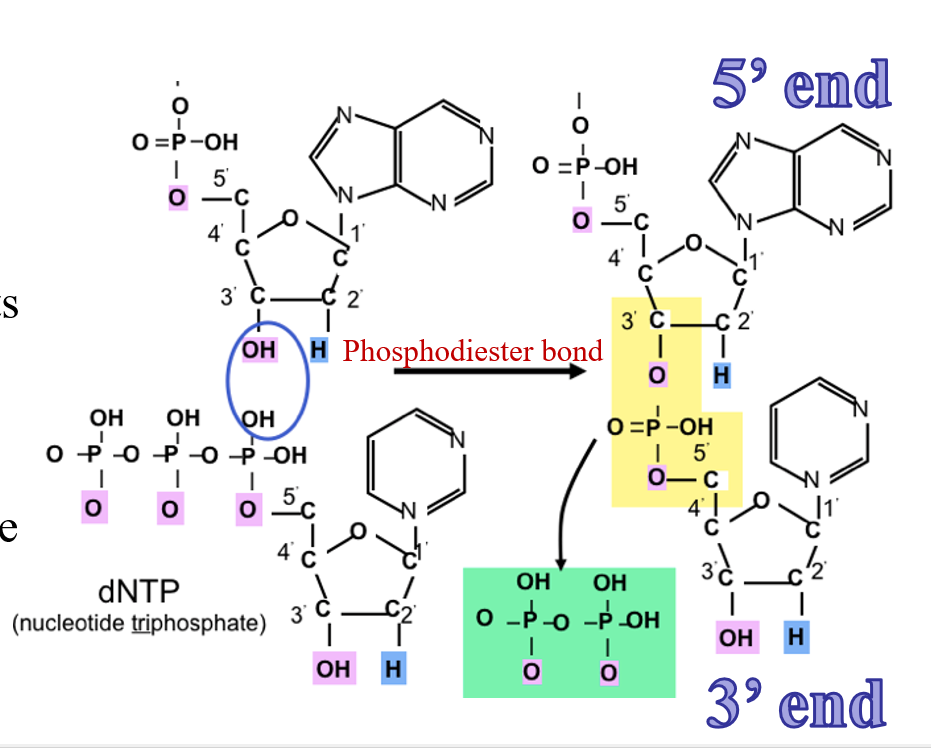
Polymer formation
phosphate on the 5’ carbon of the new nucleotide reacts with the hydroxyl on the 3’ carbon of the previous nucleotide
we talk about orientation of polymer based on what end is free
5’ is free phosphate
3’ is free hydroxyl
on C3 position on sugar within nucleotide we have a hydroxyl group
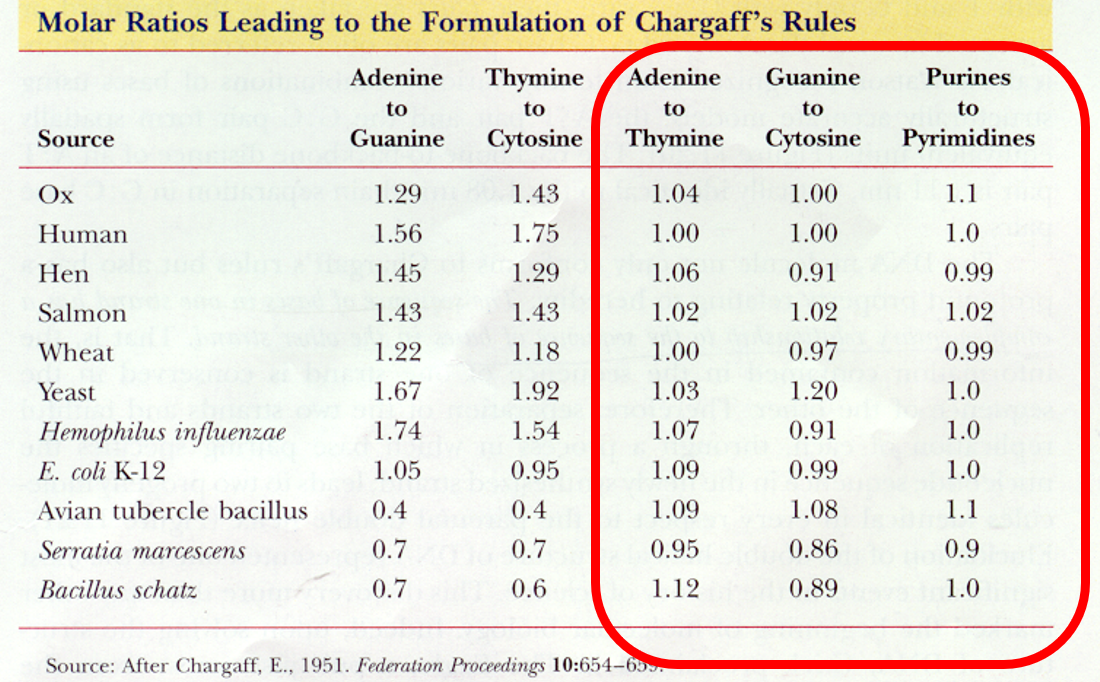
Molar ratios leading to formation of Chargraff’s Rule
A to T G to C and Purine to Pyrimidine are 1:1
Revealing image (Xray)
Franklin’s photograph 51 of B form of DNA told Watson that the molecule was a double helix through use of X-ray crystallography (fiber diffraction)
Discovery of DNA structure
Chargraff had pairing data but didn’t understand implicatios
1950’s by Watson and Crick
Rosalind Franklin and Maurice Walkins X-ray diffraction
Francis Crick knew it was a helix
James Watson discovered two strands held together by H-bonds and that between bases DNA was not a single strand but was double helixed
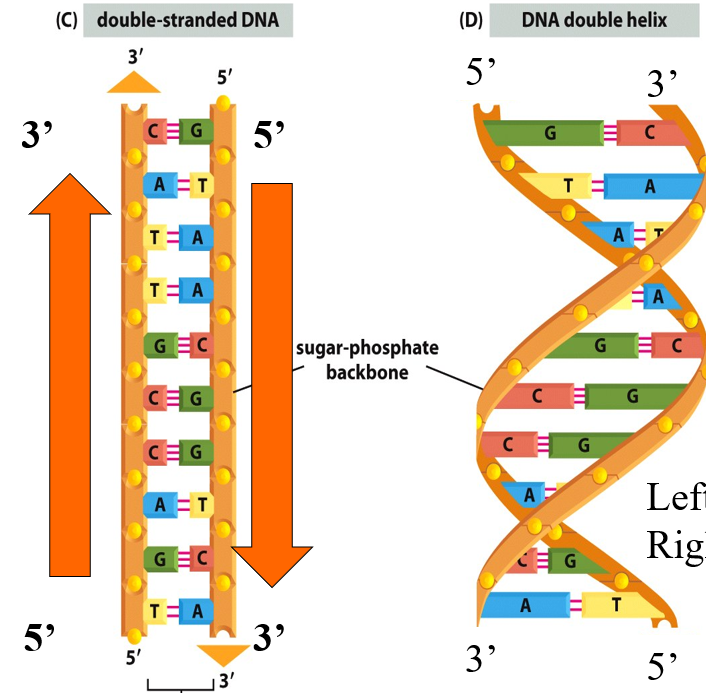
Explain DNA strands
2 strands of DNA are wound in a helix with bases on the inside and sugar-phosphate backbone on the outside
the strands are antiparallel (running in opposite directions)
this structure keeps the sugar phosphate backbone equidistant and straight
Roughly 2nm in width
Base pairs are hydrogen bonded
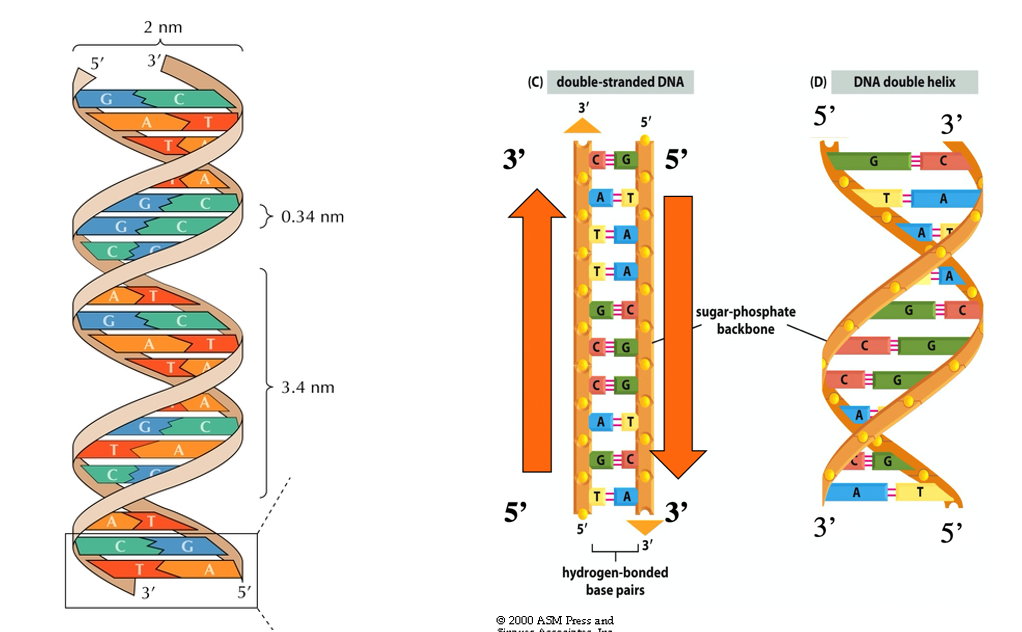
Complementary base pairings
bases are held together by non-covalent hydrogen bonds
Purine (AG) always paired with Pyrimidine (C, T/U)
Chargraff pairs A with T and G with C
GC has 3 hydrogen bonds
AT has 2 hydrogen bonds
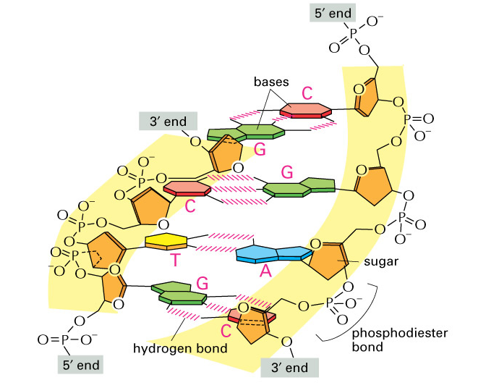
Phosphodiester bond
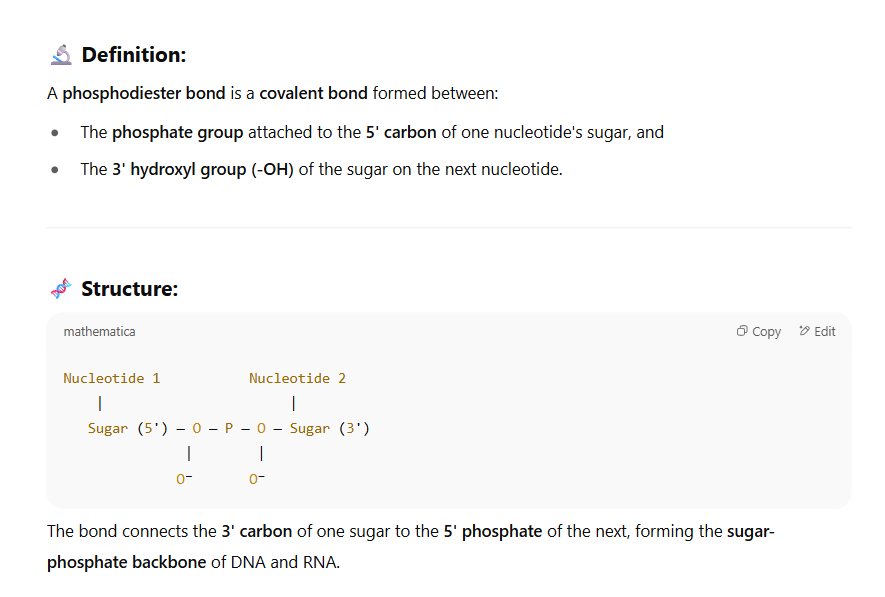
Base-pair complementarity is a consequence of what?
Size, shape, and chemical composition of the bases
Energetically favorable and does not disturb backbone spacing because always have a Purine (AG) with a Pyrimidine (TC)
Rules for reading DNA sequence
DNA always reads 5’ to 3’
Right strand is 5’ AG 3’
Left strand is 5’ CT 3’
Example of reading DNA strand
Left strand: 5’TGACCGTTAC3’
Right Strand: 5’GTAACGGTCA3’
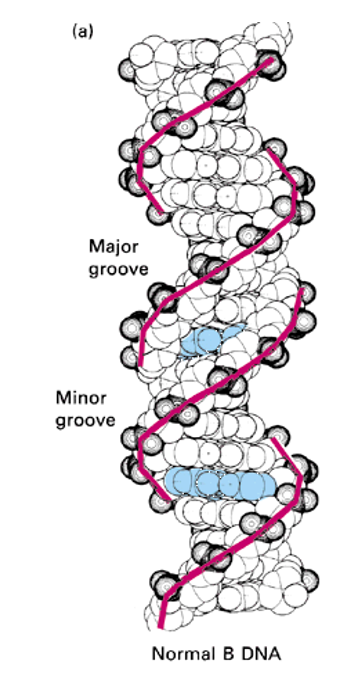
Major and Minor grooves
the helix makes a complete turn every 3, 4 nm - 10 pairs per turn
the spaces between the strands form two helical grooves of different widths
each base is accessible to molecules from the outside
Major grove; wider space between the backbones of the DNA helix, where the edges of the base pairs are more exposed and accessible to proteins.
Because the glycosidic bonds (where the bases attach to the sugar) are not directly opposite each other, the grooves formed are asymmetrical:
Minor groove; narrower of the two grooves that wind around the DNA double helix, opposite the major groove. These grooves are a direct result of the DNA's asymmetrical helix geometry.
What does life do?
creates order through the use of subunits (AGCT), polymer (specific sequences encode genes), DNA double helix, and chromosome
Gene (geneticist vs biologist)
Geneticists’ Definition: The functional unit of heredity. A trait that comprises a distinct phenotype and can be passed from parents to offspring.
Molecular Biologist’s Definition: A region of DNA containing all the elements necessary to encode an RNA transcript
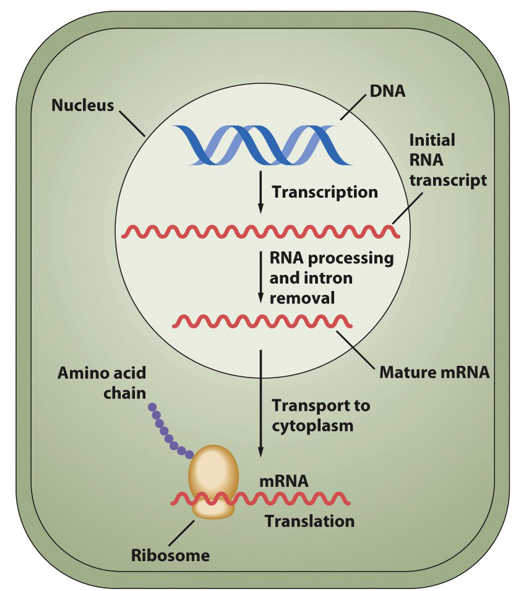
Central Dogma
DNA —> RNA —> Protein
Genes encoded in DNA are transcribed into messenger (mRNA) and then translated into proteins which perform the majority of the cell functions
What is a gene?
A unit of hereditary information
DNA segment with information to make a specific RNA molecule
Doesn’t have to be translated to be a gene; RNA molecules from genes may be final product if RNA used in structural, catalytic, or regulatory roles
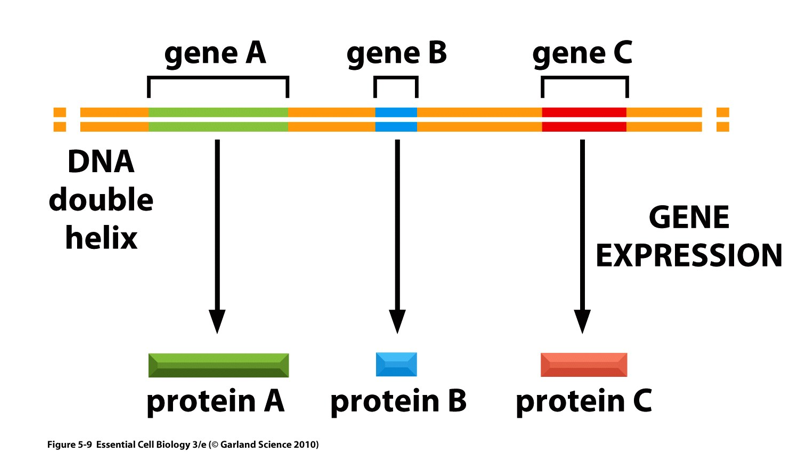
Gene definition (synthesis)
the entire nucleic acid sequence that is necessary for the synthesis of a functional protein (polypeptide) or RNA molecule
Coding regions as well as controlling regions (and in eukaryotes introns)
Only one strand will code for gene but genes can be located on either strand
Eukaryotic Genome Organization
Genome is the total genetic information of an organism (contains genes and non-coding DNA)
Long double-stranded DNA molecules are packaged into a number of chromosomes in eukaryotes
DNA plus protein complexes are called chromatin
Human genome
3.2 billion nucleotide pairs
22 chromosome pairs and sex pairs (22 from each parent + 2 = 46 total)
most of the genome is noncoding and repetitive sequence
How much of the human genome is transcribed and how much codes for proteins?
80% of the human genome is transcribed and 1% codes for proteins
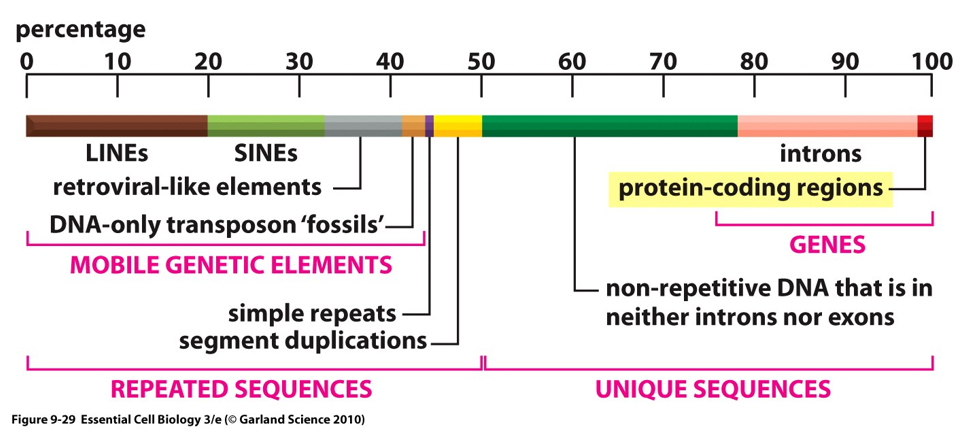
Coding versus noncoding regions of the genome
Coding region is exon
Noncoding (between or within genes) is introns
can function as regulatory sequences (not junk DNA)
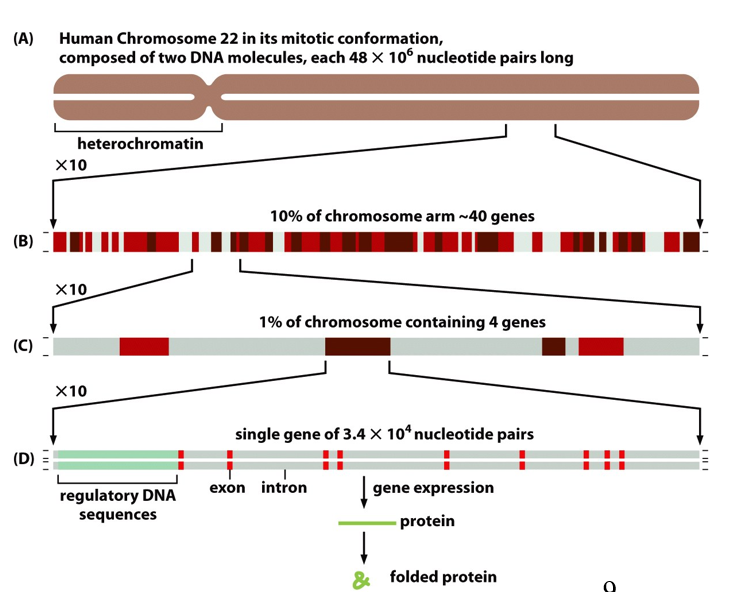
Does genome size matter?
There is a loose correlation between the genome size of an organism and genetic complexity
Not always true
In general, more complex = larger genomes
There is no simple relationship between gene number, chromosome number, and total genome size
Homology with other organisms; what makes humans different from chimps?
Noncoding DNA contains some information that is being selected for
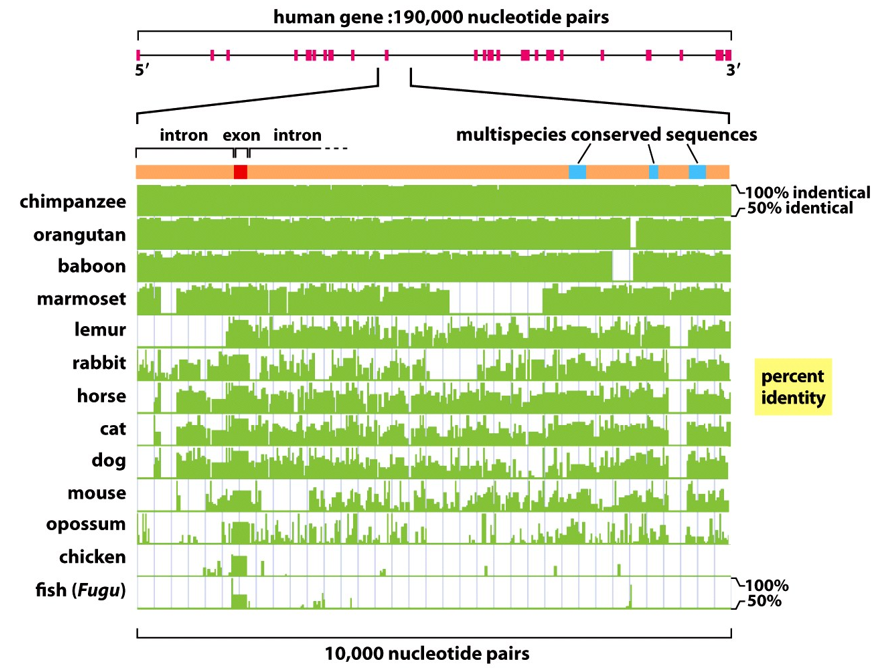
How are humans different from each other?
Human nucleotide sequences differ by about 0.1% - 2.5 million differences
Single nucleotide polymorphisms (SNPs)
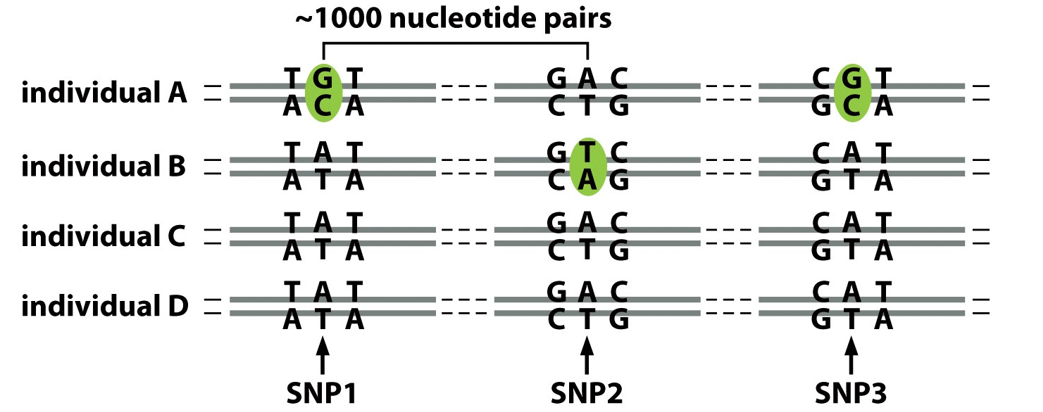
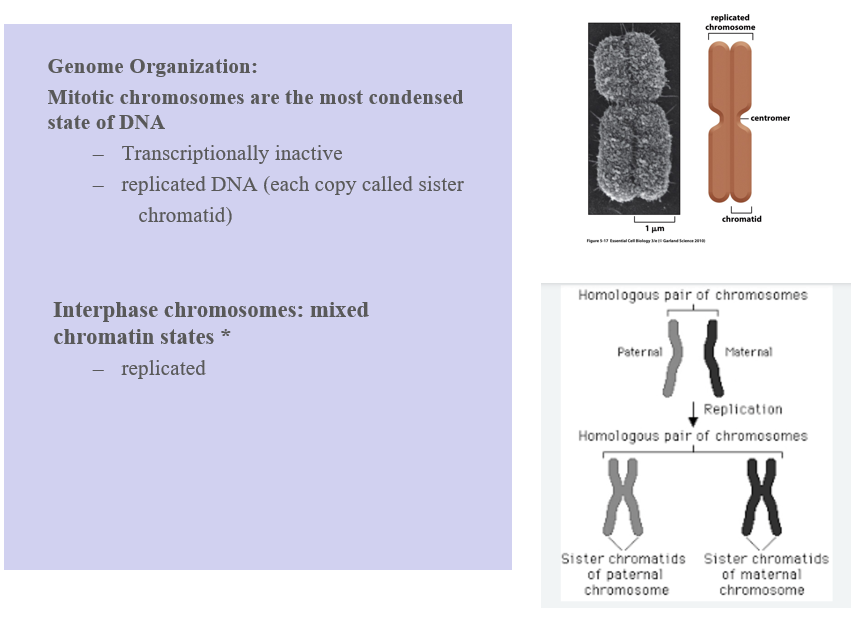
Genome organization, which chromosomes are the most condensed state of DNA?
Mitotic chromosomes
Transcriptionally inactive
Stained mitotic chromosomes have a reproducible banding pattern
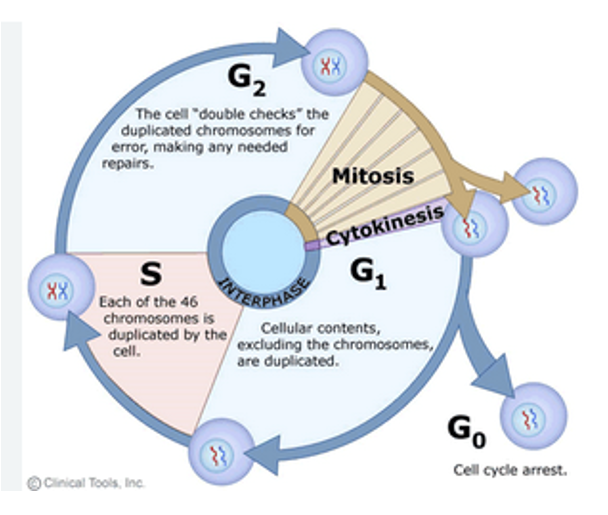
Diagram of a chromatid
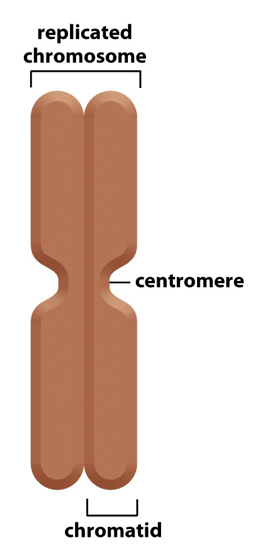
What are the three DNA sequences required for eukaryotic chromosome stability?
telomere, replication origin, and centromere
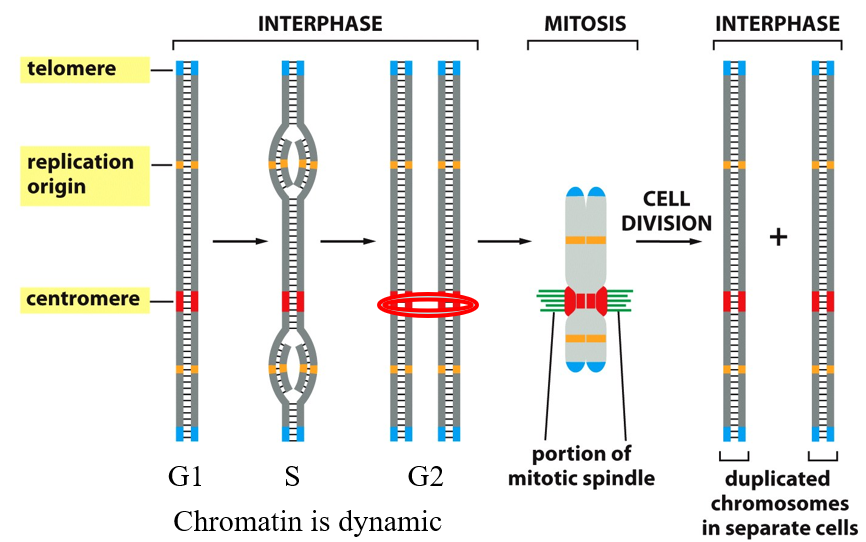
Cell Cycle Progression
Left to Right (Cell Cycle Progression) 1. Interphase (G1, S, G2) ▶ G1 Phase (Growth Phase 1)
Chromatin is loose and dynamic.
The chromosome is not yet duplicated.
Here there is organization within nuclei
You can see:
Telomeres at the ends (blue)
Replication origins (orange)
Centromere (red)
▶ S Phase (Synthesis)
DNA replication occurs.
The chromosome is being duplicated.
Replication starts at replication origins (orange), forming the “bubble” shapes in the DNA.
By the end of S phase, you have two identical sister chromatids joined at the centromere.
▶ G2 Phase (Growth Phase 2)
DNA is fully replicated.
Sister chromatids are held together at the centromere (highlighted with a red oval).
The chromosome is ready for mitosis.
2. Mitosis
The mitotic spindle (green fibers) attaches to the centromere via the kinetochore.
The chromosome is pulled apart during mitosis so that each daughter cell gets one copy of each chromosome
Physically preparing to divide DNA
3. After Cell Division (Interphase Begins Again)
Two identical daughter cells each have:
A full set of chromosomes
The same DNA sequences: telomeres, replication origins, centromeres
Chromosomes return to an uncondensed chromatin state.
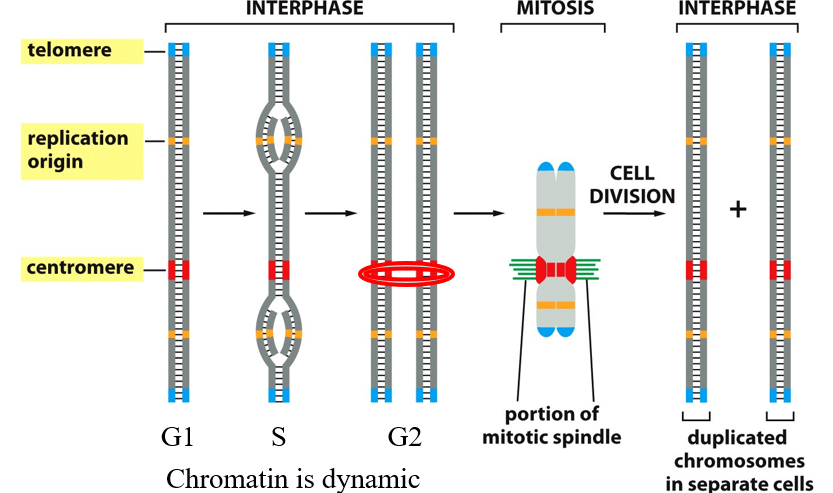
Where do DNA double helix occur specifically?
In eukaryotic cells as chromosomal structures - each double stranded helix is an individual chromosome
For eukaryotic chromosome to be stable we need these three types of DNA elements
DNA replication origin
sites where DNA replication will begin, there are many on each chromosome
Centromere
region of chromosome where the two copies of the duplicated chromosome are held together starting in S-phase and where the mitotic spindle will bind to proteins to separate DNA. One per centromeric repeat per chromosome
Telomere
DNA repeats at both ends of each chromosome to prevent DNA from becoming shorter with each replication
Explain how Chromosome localization is not random (organization)
interphase chromosomes are not randomly distributed within interphase nucleus
"Nuclear envelope attachment via membrane proteins"
→ Certain chromatin regions (especially heterochromatin) are anchored to the nuclear envelope by membrane proteins, helping to organize chromosomes in specific territories."Nucleolus – site of ribosomal RNA genes"
→ The nucleolus contains DNA sequences that encode rRNA. It’s where ribosomal subunits are assembled, which will later function in protein synthesis in the cytoplasm.
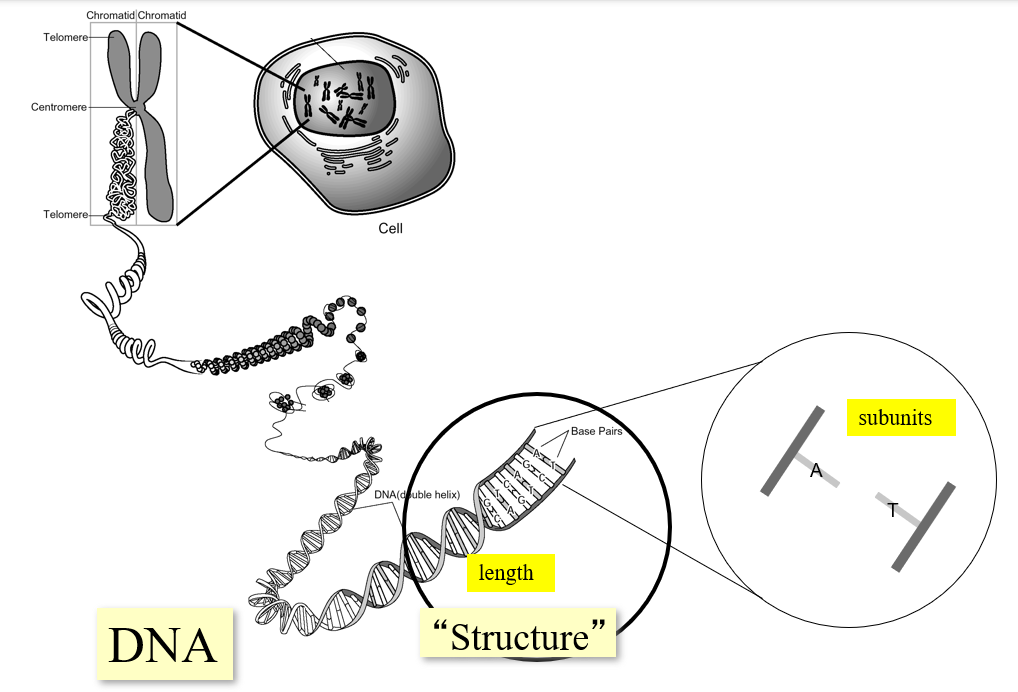
What are the levels of organization in biology
Organism (Human)
The human body is made up of trillions of cells.
Each of these cells (except red blood cells and gametes) contains a full set of genetic instructions.
Cells
Each cell has a nucleus (except mature red blood cells).
The nucleus houses the genetic material.
Nucleus → Genome
Inside the nucleus are chromosomes—structures made of DNA and proteins.
Every diploid human cell contains two copies of each chromosome (one from each parent), making up the genome.
Chromosome Pair
Humans have 23 pairs of chromosomes (46 total).
This image zooms in on one specific chromosome pair for illustration.
Chromosome Structure
A chromosome is essentially one long DNA molecule coiled and packaged with proteins.
Genes are specific functional segments of this DNA—each gene codes for a protein or functional RNA.
DNA
At the molecular level, DNA is a double helix composed of nucleotides (A, T, G, C).
This double helix structure enables DNA to store information and replicate accurately.
🧠 Big Picture Summary
This visual walks you from a whole human body ➝ to cells ➝ to chromosomes ➝ to genes ➝ to DNA, showing how all your genetic information is compacted and organized inside each cell’s nucleus.
It emphasizes that:
All cells (except gametes) carry the same DNA.
Genes are the working parts of DNA.
DNA’s structure supports heredity and function.
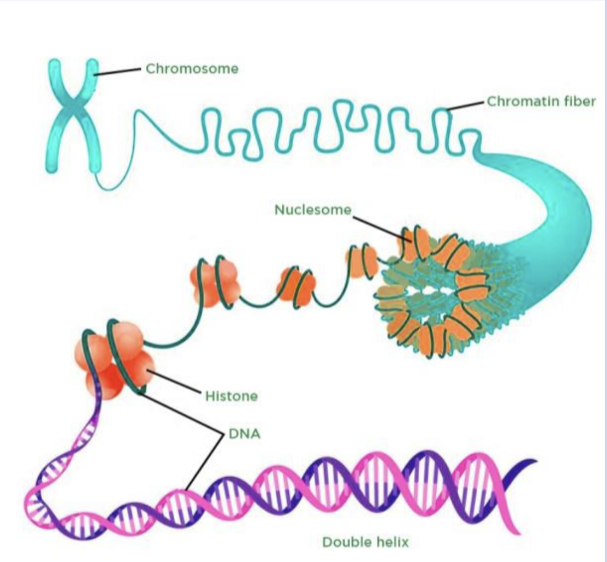
What is going on in this diagram?
Genome organization; DNA compaction state changes during the cell cycle and to control gene expression
organizing chromosomes in terms of DNA into complexes that we call chromatin
Mitosis
condensing DNA down so that we can physically separate copied chromosomes, so daughter cell will get a copy of chromosomes
Mitotic chromosomes are the most condensed state of DNA
transcriptionally inactive - no gene expression occurring
G1 and G2 phases
G1; cellular contents, excluding the chromosomes are duplicated - we aren’t replicated yet, each chromosome has maternal and paternal copy
G2; the cell “double checks” the duplicated chromosomes for error, making any needed repairs
G1 and G2 are gap phases; DNA will be selectively accessible so we’re going to be able to express different proteins by making the messenger RNA associated with it; transcription
S phase
each of the 46 chromosomes is duplicated by the cell
we’re only allowing our replication machinery access (DNA replicated)
use proteins to tether copies together
Mitotic vs interphase chromasomes
Mitotic; transcriptionally inactive (no gene expression)
replicated DNA (each copy called sister chromatid)
Interphase; mixed chromatin states, replicated
Mitotic chromosomes:
This is the most condensed form of DNA—what you see under a microscope during mitosis.
Key features:
Transcriptionally inactive → Genes are not being expressed (DNA is too tightly packed).
DNA has been replicated and each chromosome consists of two identical sister chromatids joined at a centromere
Interphase chromosomes:
Interphase is the phase when cells are not dividing.
DNA is replicated, but not as tightly condensed as in mitosis.
The chromatin has mixed states:
Some regions are euchromatin (loose, active)
Some regions are heterochromatin (dense, inactive)
🖼 Right Panel: Image Summary 🔝 Top Image:
Shows a highly condensed mitotic chromosome.
Includes:
Sister chromatids (replicated copies of one chromosome)
Centromere (region that holds sister chromatids together)
🔽 Bottom Image:
Shows a homologous chromosome pair:
One from the mother, one from the father.
After DNA replication, each homologous chromosome forms two sister chromatids.
So after replication, you have 4 chromatids total (2 per homolog).
Two types of chromatin in interphase cells
Heterochromatin - lightly condensed
constitutive heterochromatin (means always in the same state)
centromere and telomere (repetitive DNA)
Gene poor regions
facultative heterochromatin
dynamic and regulated by developmental cues or cellular signals - this happens because it can be hetero in some conditions, and then in response to something, we take it out of heterchromatin and make it less condensed
Euchromatin - less condensed
active euchromatin - least condensed
quiescent (inactive) euchromatin in between (for now its inactive, not binding, not transcripting, and more accessible)
During the different phases of the cell cycle, DNA is found in different forms. Name them
Three DNA sequence elements are needed to produce a eukaryotic chromosome that can be duplicated and then segregated at mitosis
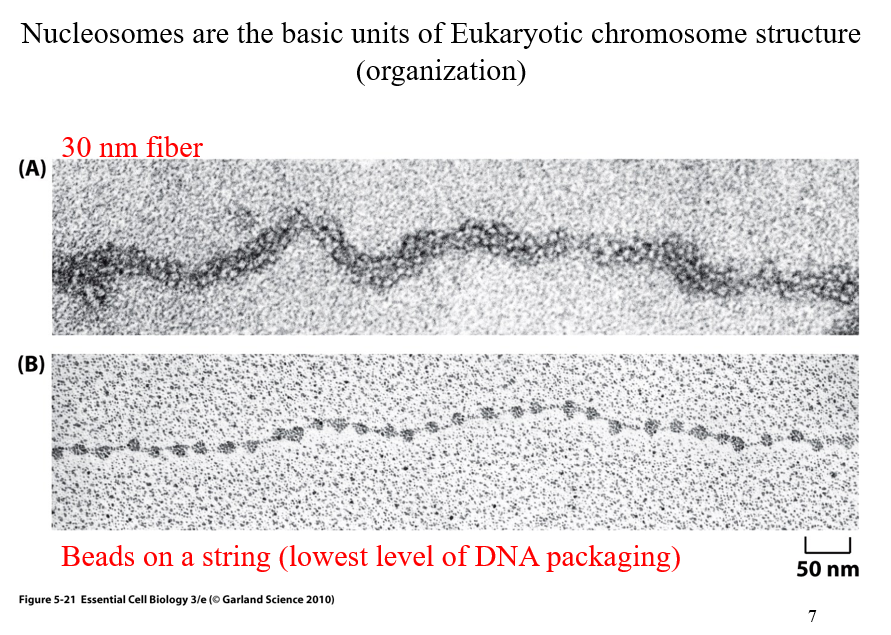
Nucleosomes
the basic units of Eukaryotic chromosome structure (organization)
two kinds; 30 nm fiber and beads on a string
30 nm fiber versus beads on a string
30nm fiber appears thicker, it ends up beading to additional proteins (another level of organization)
Beads on a string is the lowest level of DNA packaging
above DNA double helix where DNA wrapped around nucleosomes
🔍 What’s Shown in the Images:(B) Bottom Image – "Beads on a string"
This is the least compacted form of chromatin.
Each "bead" = nucleosome, which consists of:
DNA wrapped around a histone protein core
~147 base pairs of DNA wrap around each histone
The "string" = linker DNA between nucleosomes.
This structure is visible under an electron microscope when chromatin is gently unfolded.
Functional state: Often associated with active genes (euchromatin).
(A) Top Image – "30 nm fiber"
This is a more compact and organized form of chromatin.
The "beads on a string" structure coils into a thicker 30-nanometer fiber.
Involves interactions between nucleosomes and additional histone proteins (e.g. H1).
Functional state: More compact = less transcriptionally active.
🧠 Big Picture: Why This Matters
Eukaryotic DNA is extremely long and must be tightly packed to fit into the nucleus—but also organized so that genes can be accessed when needed. The packaging levels help regulate this:
Structure | Appearance | Functionality |
|---|---|---|
Beads-on-a-string | Loosely packed | Easier for gene access |
30 nm fiber | Condensed coil | More storage-efficient, less active |
📌 Key Takeaways:
The nucleosome is the first level of DNA compaction.
Chromatin exists in different packaging states, which affect gene expression.
DNA wraps around histones to form the "beads on a string" (euchromatin).
These beads coil into thicker fibers (heterochromatin-like 30 nm fiber) for further compaction.
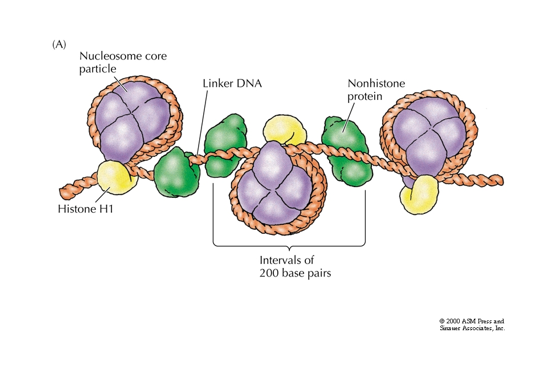
proteins that helps organize the DNA
Chromatin; histone proteins plus non-histone proteins plus DNA
Nucleosome; DNA wrapped around histone complexes 2x
🟪 Chromatin
Definition: A complex of DNA + histone proteins + non-histone proteins.
This is the general structure of DNA in the nucleus when it's not condensed into chromosomes.
Chromatin exists in either:
Euchromatin (loosely packed, active)
Heterochromatin (tightly packed, inactive)
🟣 Nucleosome
The basic unit of chromatin.
It consists of:
~147 base pairs of DNA
Wrapped around a histone core (purple spheres)
Each core is made of 8 histone proteins (2 each of H2A, H2B, H3, and H4)
Histone H1 (yellow) helps compact and stabilize the DNA between nucleosomes.
🔍 Diagram Explanation (Right Side):
This shows the "beads-on-a-string" structure of chromatin:
Nucleosome Core Particles:
The "beads" in this model.
DNA wraps around histone cores.
Linker DNA:
The "string" between nucleosomes.
These regions are not wrapped around histones.
Histone H1:
Binds to the linker DNA.
Helps pull nucleosomes together into a more compact structure (like the 30 nm fiber).
Non-histone proteins (green):
Other proteins (like transcription factors, scaffold proteins) that help organize, stabilize, and regulate the chromatin.
Intervals of ~200 base pairs:
Each nucleosome + its linker DNA repeats roughly every 200 base pairs.
📌 Why This Matters:
DNA is very long, but it needs to fit inside the tiny nucleus and still be accessible for replication and transcription.
Nucleosomes and chromatin structure make this possible through hierarchical levels of folding.
The combination of histone and non-histone proteins allows dynamic regulation of gene activity.
Nucleosome and octonomer meaning
octonomer of four types of histones; H2A, H2B, H3, H4
8 proteins in complex total; 2 of each H types
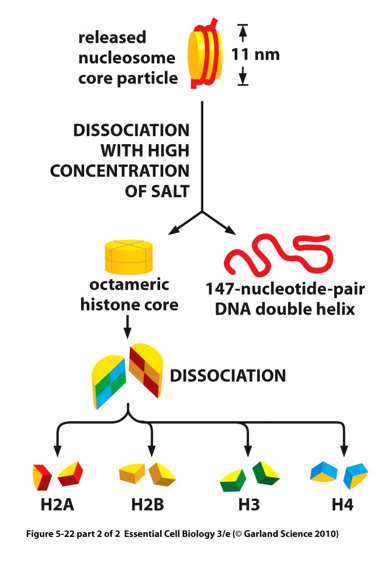
Histone binding
binding to DNA is not sequence specific
positively charged amino acids within histones form electrostatic interactions with DNA’s negatively charged sugar-phosphate backbone
electrostatic interactions allow us to associate DNA with nucleosomes but not in sequence specific manner
histones are a quartenary protein
DNA is ultimately more condensed than beads on a string
further ordered to create a 30-nm diameter fiber
Histone H1 pulls the nucleosomes together into a regular repeating array
restricts movement of tail
not nucleosome core
head to go from beads on a string to chromatin fiber. Binds with DNA helix as it comes off of wrapping around nucleosome
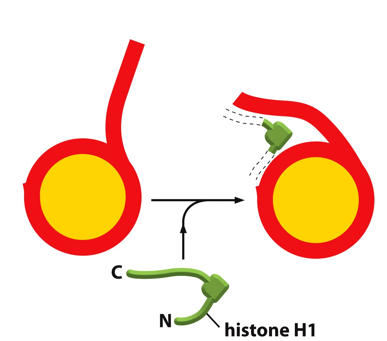
🧬 What You’re Looking At: 🔴 Red line:
Represents DNA.
🟡 Yellow circle:
Represents the histone core particle (the nucleosome made of histone proteins H2A, H2B, H3, and H4).
🟢 Green protein labeled "histone H1":
This is the linker histone H1, which plays a supportive and organizational role.
🔍 What’s Happening in the Diagram:
Left side:
DNA wraps around the histone core, forming a nucleosome.
The DNA entering and exiting the nucleosome is loose and flexible.
Middle:
Histone H1 (green) binds at the entry and exit point of the DNA on the nucleosome.
Right side:
After H1 binds, the DNA becomes more constrained and organized.
This interaction helps "lock" the DNA in place on the nucleosome.
🧠 Why Histone H1 Matters:
H1 is not part of the nucleosome core, but it binds to the linker DNA between nucleosomes and helps:
Stabilize the nucleosome structure.
Pull nucleosomes closer together.
Promote formation of the 30 nm fiber, a more compact chromatin structure.
Without H1, chromatin remains in a "beads-on-a-string" configuration.
With H1, chromatin becomes tightly packed, reducing accessibility to transcription machinery (gene silencing potential).
📌 Summary:
Feature | Role of Histone H1 |
|---|---|
Binding site | Where DNA enters/exits nucleosome |
Function | Stabilizes DNA wrap and linker region |
Effect on chromatin | Promotes compaction (30 nm fiber) |