Ch8: Instance-based Learning
1/16
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
17 Terms
What is instance-based learning?
A learning method where the model stores the training instances & delays generalization until a new query is received.
It classifies new instances based on their similarity to stored data.
How does instance-based learning differ from previous models like decision trees or neural nets?
A: Previous models are eager learners that generalize during training; instance-based learning is a lazy learner that postpones generalization until prediction time.
What are some practical challenges with lazy learning?
A:
High storage requirements
Slow prediction time
Difficulty handling noise
Need to classify new data without an exact match
What is the Nearest Neighbour (NN) learning method?
The most basic instance-based method, it assigns to a new instance the target value of the closest training instance.
How is similarity typically measured in NN learning?
Using Euclidean distance between feature vectors:
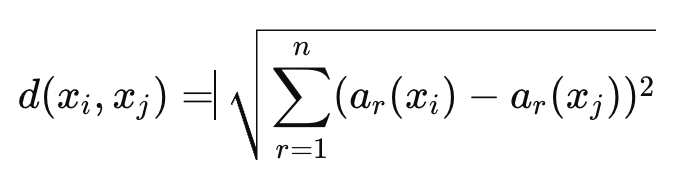
What is a key drawback of 1-Nearest Neighbour?
A: It is highly sensitive to local structure and noise, which can lead to overfitting.
What is K-Nearest Neighbour (K-NN)?
A: An extension of NN that assigns to a new instance the most common target value among the k nearest instances. For regression, it takes the mean of their target values.
What is the benefit of using k > 1 in k-NN?
A: Reduces sensitivity to noise & overfitting by smoothing the prediction across multiple nearby instances.
What is the trade-off when choosing the value of k in k-NN?
A: Small k (k neighbors=1) values may overfit (sensitive to noise), while large k (k=20) values may oversmooth (high bias).
What is the decision boundary in k-NN learning?
A: The implicit border between regions where a new point would be classified differently, determined by proximity to training examples.
What is a Voronoi diagram in the context of NN?
A geometric representation where each training point "owns" a region of the feature space based on proximity; new points are classified by the region they fall in.
What is Distance-Weighted K-NN?
A: A variant of k-NN where closer neighbors are given more influence in prediction than farther ones, based on distance.
What are the advantages of instance-based learning?
Simple to implement
No training time
Handles both discrete and continuous outputs
Can model complex target functions
Robust to noise (especially with distance weighting)
What are the disadvantages of instance-based learning?
A:
Expensive to predict (slow at classification time)
High memory usage
Sensitive to irrelevant features
Poor performance in high-dimensional spaces
Why does high dimensionality hurt k-NN?
As the number of features increases, the data needed to generalize well grows exponentially, making models like k-NN less effective due to sparse coverage and misleading distances.
What are possible solutions to the curse of dimensionality in k-NN?
A:
Feature selection to remove irrelevant features
Feature weighting
How does decision trees differ from k-NN in dealing with features?
Decision trees naturally focus on the most relevant features, while k-NN considers all features equally in distance calculations unless adjusted.