NLP B6-9.
1/38
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
39 Terms
Role of AI alignment
Ensuring that it operates in accordance (“is aligned”) with
▶ the intended goals and preferences of humans (users, operators etc.), and
▶ general ethical principles
Main human influences on AI systems
Choosing the:
dataset
reward function
loss or objective function
Outer misalignment
A divergence between the developer specified objective or reward of the system and the intended human goals
Inner misalignment
A divergence between the explicitly specified training objective and what the system actually pursues, its so-called emergent goals.
Instruction following assistant
An LLM-based general model which can carry out a wide, open-ended range of tasks based on their descriptions
Main expectations towards an instruction following assistant
HHH
helpful
honest
harmless
Hallucination
Plausibly sounding but non-factual, misleading statements
Main strategies for creating instruction datasets
manual creation
data integration
synthetic generation
Manual creation
Correct responses are written by human annotators, instructions are either collected from user–LLM interactions or also manually created
Data integration
Converting existing supervised NLP task datasets into natural language (instruction, response) pairs using manually created templates.
E.g. Flan
Synthetic generation
The responses are generated by LLMs (but are possibly filtered by humans), while instructions are either
▶ collected from user prompts, or
▶ also generated by LLMs based on a pool of manually created seed prompts → randomly sample the pool to prompt an LLM to generate further instructions and examples, filter these and add the best ones iteratively
E.g. Self-Instruct
Proximal Policy Optimization (PPO)
A policy gradient variant which avoids making too large policy changes by clipping the updates to a certain range
RL training objectives
maximize the expected reward for (instruction, model-response) pairs
minimize (a scaled version of) the KL divergence between the conditional distributions predicted by the policy and by the instruct language model used for its initialization
Direct Preference Optimization (DPO)
Transforms the RL optimization problem into a supervised (ML) learning task, hence eliminating the need for the costly reward model
Reparameterizes the RL optimization problem in terms of the policy instead of the reward model RM
Formulates a maximum likelihood objective for the policy πθ
Optimizes the policy via supervised learning on the original user judgements
Input of conditional text generation
A complex representation of the assistive dialog’s context, including its history (instead of a single instruction)
Complexity of retrieval with nearest-neighbor search
O(Nd)
d is the embedding size, N is the number of documents
Methods for approximating nearest neighbors
Hashing
Quantization
Tree structure
Graph-based
Main idea of using locality-sensitive hashing for nearest neighbor approximation
The probability of collision monotonically decreases with the increasing distance of two vectors (the bins will contain elements which are close to eachother)
→ we perform complete nearest neighbor search in the element’s bin only
Main idea of using KD-trees for nearest neighbor approximation
Drawing a hyper-plane at the median orthogonal to the highest-variance data dimension
Each half is split using the same principle, until each node contains a single element only → tree leaves
We create connections by merging nodes/subgroups by the inverse order of their separation
Use priority search for finding the nearest neighbors
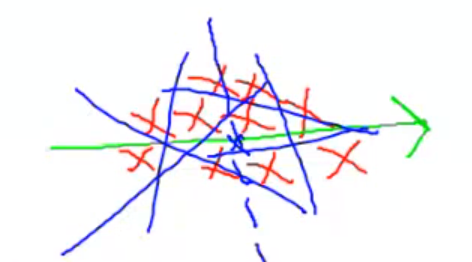
Main idea of using priority search in KD-trees for nearest neighbor approximation
We split up our data into cells, each cell containing a KD-tree leaf node
We encode the user query, and finds its cell.
We measure the distance between the leaf node belonging to that cell and the encoded query
We use this distance as a search radius -> we only do NN search in cells which are touched
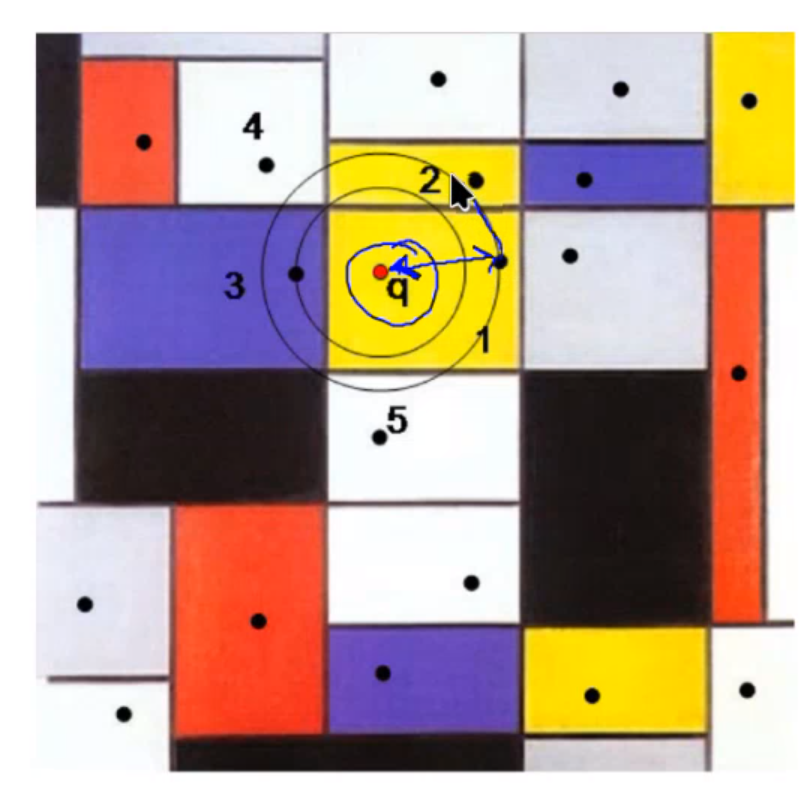
Voronoi cell
A geometric shape that represents the region closest to a specific point, forming boundaries with neighboring points.
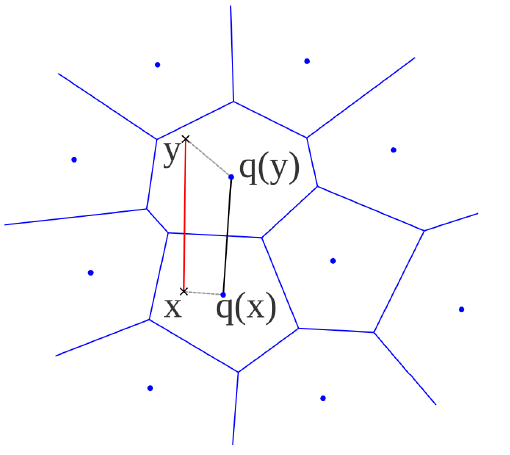
Vector Quantization
A compression technique that represents text data as a smaller set of reference vectors (centroids), approximating the original high-dimensional word vectors with the closest centoid vector.
It significantly enhances storage efficiency and processing speeds ←→ involves a trade-off with information loss due to approximation
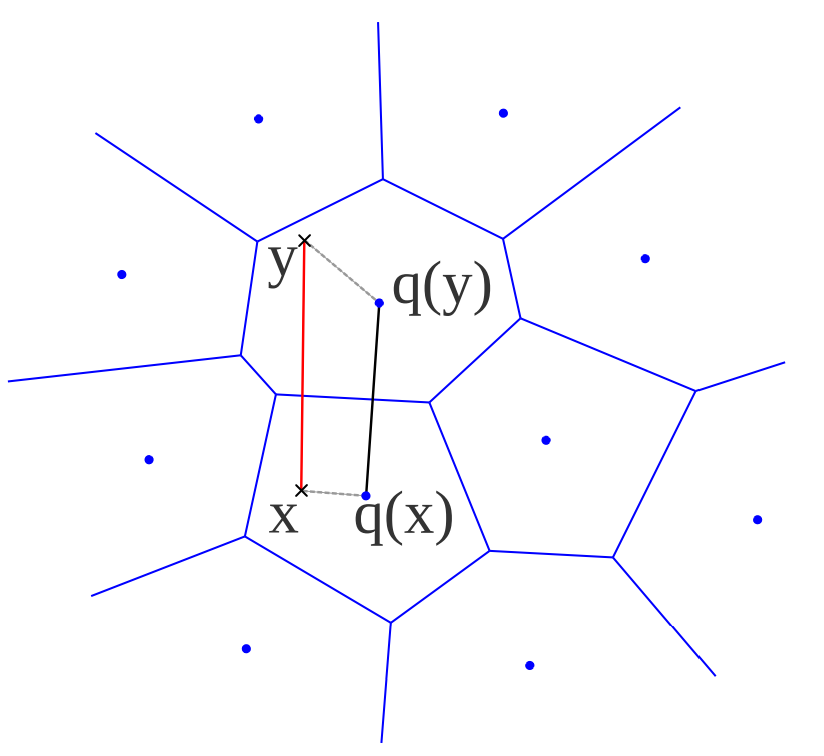
Product quantization
A high-dimensional vector is divided into smaller sub-vectors or segments. Each sub-vector is then quantized independently, using a smaller codebook of centroids that is specific to that segment. The final quantized representation of the original vector is obtained by combining the quantized codes (indices of the nearest centroids) of each segment (taking the Cartesian-product).
This is more computationally efficient since it's much easier to manage and compute distances within these lower-dimensional subspaces.
Complexity of product quantization
O(d*m^{1/L})
L is the number of segments, d is the vector dimensionality, m is the number of the possible value combinations
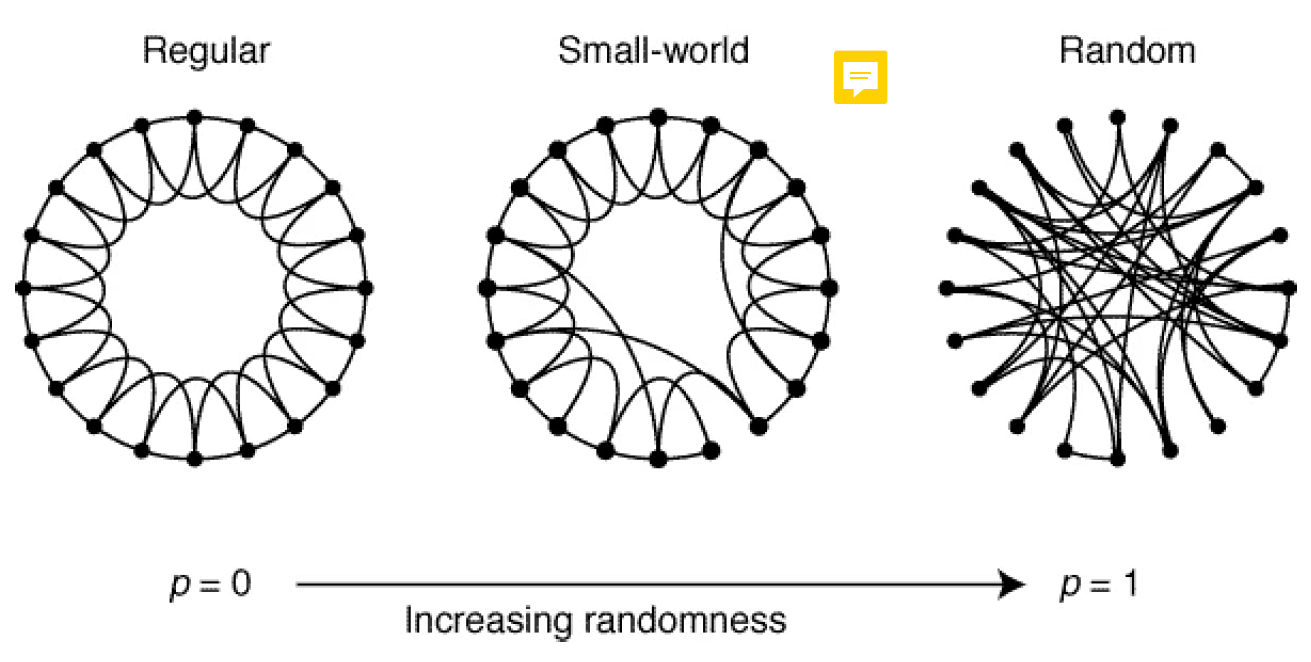
Small world property of graphs
shortest path between two vertices of the graph on average should be small (idea of "six degrees of separation" in social networks)
clustering coefficient (ratio of the fully connected
triples (triangles) and all triples in the graph), should be
large → captures the intuition that entities tend to form tightly interconnected groups
In the context of NLP, these properties of small-world networks facilitate models and systems that are both efficient (due to short path lengths) and capable of capturing nuanced relationships (due to high clustering).
Navigable small worlds (NSW) algorithm
Vertices are iteratively inserted into the network. By default we connect the vertex with its closest neighbors, except with a certain p probability, when we connect it randomly
→ we build up the network in a node-by-node manner
Hierarchical navigable small worlds (HNSW)
HNSW constructs a multi-layered graph where each layer is a smaller-world network that contains a subset of the nodes in the layer below. (The top has the fewest, while the bottom layer contains all the nodes)
It is based on the principle of proximity, each node connects to its nearest neighbors at its own layer and possibly to nodes at other layers.
To find the nearest neighbors of a query point, HNSW starts the search from the top layer using a greedy algorithm. At each step, it moves to the node closest to the query until no closer node can be found, then proceeds to search the next layer down. This process repeats until the bottom layer is reached.
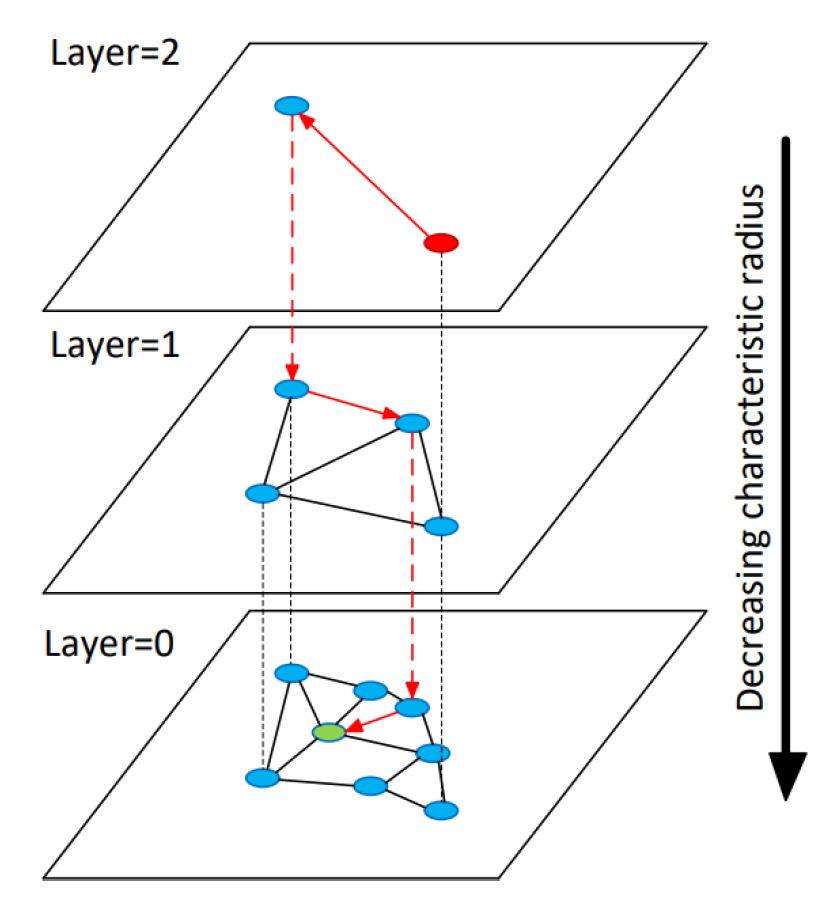
Average complexity of HNSW inference
O(log(N))
N is the number of documents
Sentence-level supervised dataset examples
sentence similarity datasets
sentiment analysis datasets
natural language inference datasets (premise and either an entailment, a contradiction, or a neutral pair)
Instruction embedding
The model dynamically determines which task to perform based on the content of the embedded instruction
→ provides versatility and adaptability to multiple tasks and domains
Retrieval Augmented Generation (RAG) steps
Question-forming
Retrieval
Document aggregation
Asnwer-forming
Hypothetical document embedding
The model generates fake answers to the query and then retrieves the actual answers based on the similarity between the fake answers and the real documents themselves.
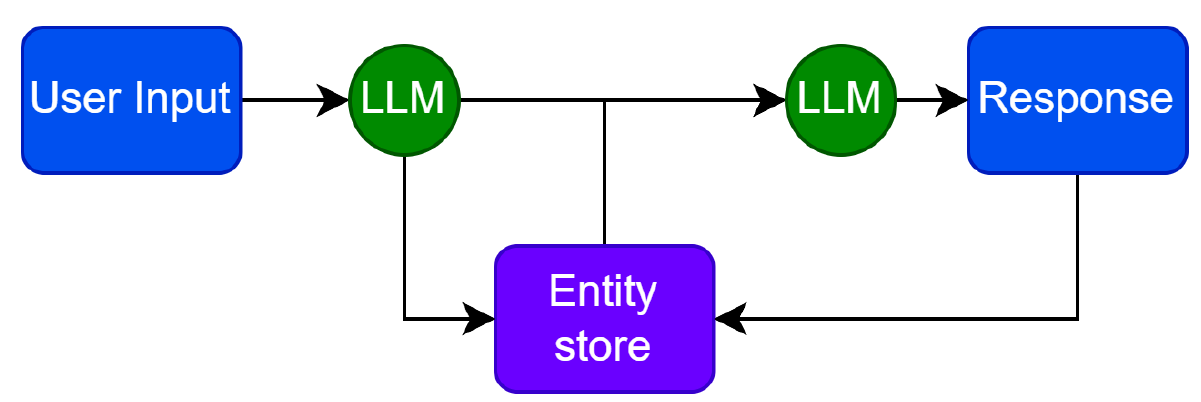
Entity memory
A list of entities and related knowledge which gets stored in a database that the LLM can update as well as retrieve information from.
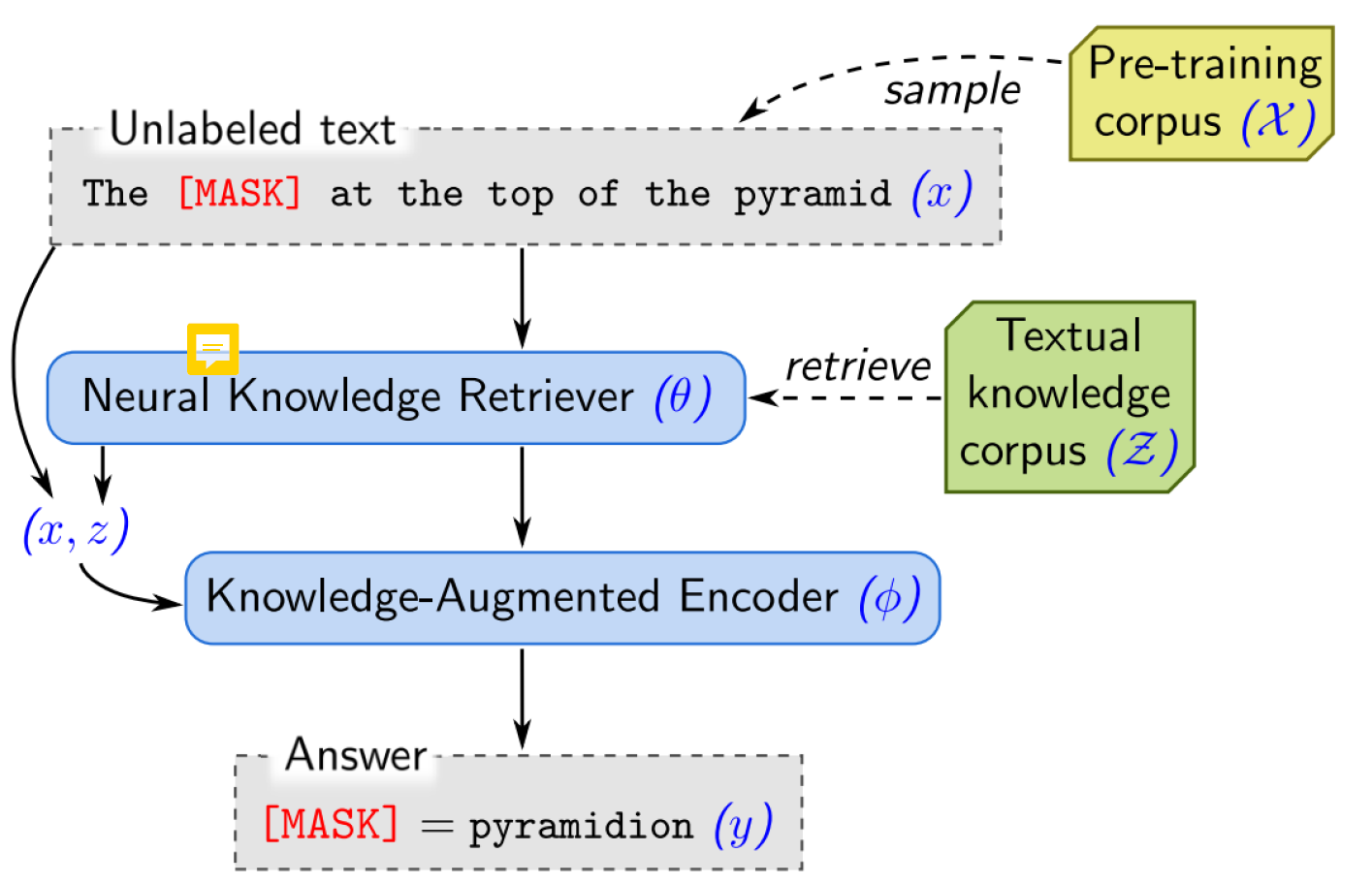
Retrieval Augmented Language Model Pretraining (REALM)
It uses neural knowledge retriever (BERT-like) embedding models to retrieve knowledge from the textual knowledge corpus, which gets fed to a knowledge-augmented encoder alongside the actual input
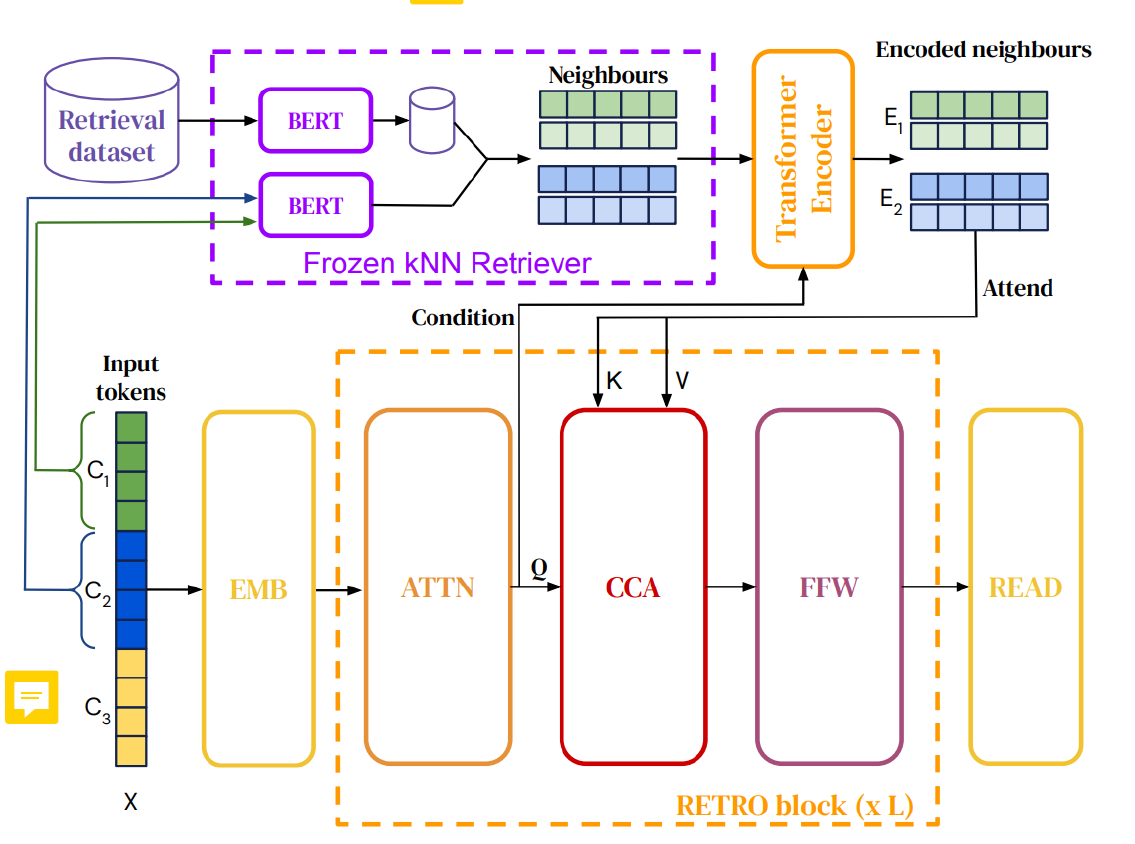
Retrieval-Enhanced Transformer (RETRO)
The main idea is that relevant context information is encoded using cross-attention based on the input information.
Initially the input gets chunked, and each chunk is processed separately → a frozen BERT model retrieves their corresponding context vectors (neighbors) → these are encoded using cross-attention → In the decoder cross-attention incorporates the modified context information into the input as the key and value
Self-monologue model
A model that operates in a semi-autonomous loop-like manner by generating its objectives, executing tasks based on those objectives, and then learning from the outcomes of its actions
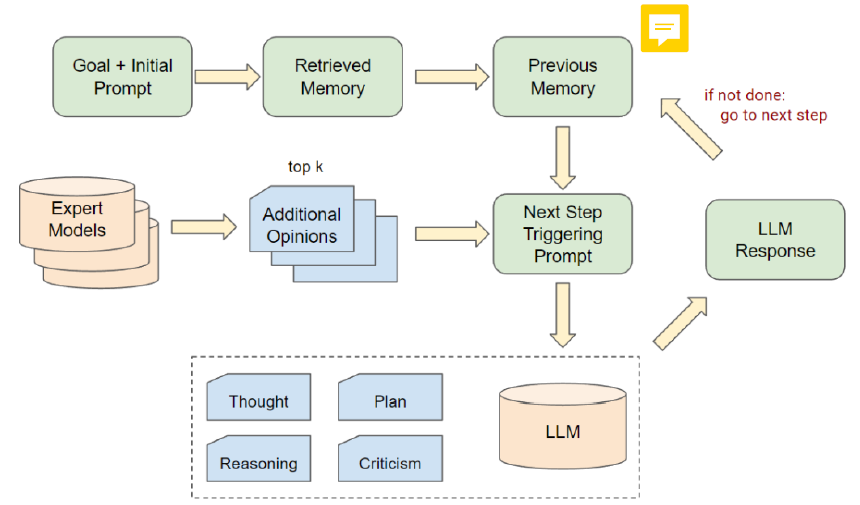
AutoGPT steps
▶ Thoughts: Interpretation of the user input/observations with respect to the goals.
▶ Reasoning: Chain of thought about what to do for this input.
▶ Plan: Planned actions to execute (additional external tools/expert LLMs can be called)
▶ Criticism: Reflexion on action before execution, aim for improvement
▶ Action: Action execution with inputs generated by AutoGPT.
Conversational agent collaboration
Agents collaborate in a conversational manner. Each agent is specialized to use a given tool, while the controller schedules and routes the conversation between them iteratively.
Tool fine-tuning
A graph of API calls is constructed using a multitude of LLM calls. These successive calls are then ranked by success rate, and the best few passing solutions are selected to be included in the dataset