Database Systems
1/90
Earn XP
Description and Tags
MODULE 1 - 4
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
91 Terms
Handling Big Data
Real-time Data Processing
Enhanced Scalability
Support for Unstructured Data
Importance of Advanced Database Systems
Relational Database
is a type of database that stores and organizes data in tables, where relationships between the data are defined.
It follows a structured format, using rows and columns, making it easy to retrieve, manage, and manipulate information through SQL
used because of their flexibility, accuracy, and ability to handle large amounts of interconnected data.
Tables
Relations
Structured formats where data is stored, similar to spreadsheets
Rows
known as records or tuples — each row contains data entries
Columns
Also called fields or attributes — each column represents a particular property of the entity
Primary Key
A unique identifier for each record in a table.
It ensures that each row can be distinctly identified.
Foreign Key
A field in one table that refers to the Primary Key in another table.
It establishes a link between two tables and ensures referential integrity.
One-to-One (1:1)
Each record in Table A corresponds to a single record in Table B.
One-to-Many (1:N)
A record in Table A can be associated with many records in Table B, but a record in Table B relates to only one in Table A.
Many-to-Many (M:N)
Multiple records in Table A relate to multiple records in Table B, usually requiring a junction table
functions and operators
are essential tools for manipulating and analyzing data.
They help you perform calculations, filter results, and transform data directly within SQL queries.
Functions
are pre-defined operations that take inputs (arguments), process them, and return results.
Aggregate Functions
operate on multiple rows to produce a single result.
Scalar Functions
operate on individual rows and return one result per row
COUNT()
Count the number of rows in a table
Counts rows matching a condition
SELECT COUNT(*) FROM Students;
SUM()
Adds up numeric values
SELECT SUM (Salary) FROM Employees;
AVG()
Calculates average of values
SELECT AVG (Age) From Users;
MAX()
Finds maximum value
SELECT MAX (Price) FROM Products;
MIN()
Finds minimum value
SELECT MIN(Score) FROM Products;
WHERE
SQL clause is used to filter records
Operators
are symbols used to perform operations on data.
They’re crucial for filtering data and forming conditions in queries.
AND
True if both conditions are true
OR
True if at least one condition is true
NOT
Reverses the condition’s result
BETWEEN
Checks if value is within range
IN
Checks is value matches any in list
LIKE
Searches for pattern
IS NULL
Checks for null values
EXISTS
Returns true if subquery returns rows
join
is used to combine rows from two or more tables based on a related column.
CREATE PROCEDURE
to create a stored procedure
Aggregate Function
a function that performs a calculation on a set of values
Joins and Aggregate Functions
Allows you to combine data from multiple tables and perform calculations on data sets, giving you powerful ways to analyze and extract insights from relational databases.
INNER JOIN
Returns rows that have matching values in both tables

LEFT JOIN
Returns all rows from the left table and the matched rows from the right table.
Unmatched rows from the right table will be NULL.

RIGHT JOIN
Returns all rows from the right table and matched rows from the left table

FULL JOIN
Combines all rows from both tables, returning matched rows and NULL for unmatched rows.

CROSS JOIN
Returns the Cartesian product of two tables every combination of rows from both tables

GROUP BY
clause groups rows sharing a property so you can use aggregate functions on each group

DDL (Data Definition Language)
Deals with the structure of the database
creating (CREATE TABLE)
altering (ALTER TABLE)
deleting tables (DROP TABLE)
schemas/truncate (TRUNCATE TABLE)
DML (Data Manipulation Language)
Deals with data within tables
retrieving (SELECT)
adding (INSERT INTO)
updating (UPDATE)
deleting records (DELETE FROM)
DCL (Data Control Language)
Controls access and permissions to the database.
GRANT
REVOKE
TCL (Transaction Control Language)
Manages transactions — sequences of database operations that must be executed as a single unit.
COMMIT - Saves all changes made in the transaction
ROLLBACK - Reverts changes since the last commit.
SAVEPOINT - Sets a point to roll back to within a transaction
SET TRANSACTION - Configures transaction properties like isolation level.
Triggers
are powerful tools used to automatically execute predefined actions in response to certain events on a table or view
Used for enforcing business rules, auditing, logging, and validating data.
AFTER Triggers (FOR Triggers)
Executed after the triggering event (INSERT, UPDATE, DELETE) has completed.
Cannot be used with views.

INSTEAD OF Triggers
Executed instead of the triggering event.
Can be used on tables and views.

DDL Triggers (Data Definition Language Triggers)
Fire in response to changes to database schema (CREATE, ALTER, DROP).

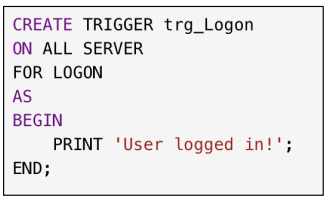
Logon Triggers
Execute in response to a LOGON event.
query optimization
is the process of enhancing the efficiency of a query to ensure it runs as quickly and efficiently as possible.
index
is a data structure that improves the speed of data retrieval.
Clustered Index
Sorts and stores rows in the table based on the indexed column.
There can be only one clustered index per table.
Non-Clustered Index
Contains pointers to rows in the data pages.
A table can have multiple non-clustered indexes
Unique Index
Ensures that all values in the indexed column(s) are unique.
view
is a virtual table based on a SQL query
It does not store data itself but shows data from one or more tables.
simplify complex queries by presenting results as if they were from a table
Transaction
is a sequence of operations performed as a single logical unit of work
must be rolled back, ensuring the database remains in a consistent state
sequence of one or more operations
executed as a single unit
Read(X)
is used to read the value of a particular database element X and stores it in a temporary buffer in the main memory for further actions such as displaying that value
Write(X)
is used to write value to the database from the buffer in the main memoryC
Commit
This operation in transactions is used to maintain integrity in the database
Rollback
undoes all the changes made by the transaction, reverting the database to its last consistent state
Serial Schedule
when multiple transactions are to be executed, they are executed serially
Non-Serial Schedule
To reduce the waiting time of transactions in the waiting queue and improve the system efficiency
Atomicity
Consistency
Isolation
Durability
ACID
Atomicity
This property ensures that either all operations of a transaction are executed or it is aborted
achieved through commit and rollback operations
Consistency
This property of a transaction keeps the database consistent before and after a transaction is completed
the changes made in the database are result of logical operations only which the user desired to perform and there is not any ambiguity
Isolation
This property states that two transactions must not interfere with each other
It ensures that the integrity of the database is maintained
Concurrency Control
is a critical mechanism in DBMS that ensures the consistency and integrity of data when multiple operations are performed at the same time
ensures multiple transactions can simultaneously access or modify data without causing errors or inconsistencies
Dirty Reads
Lost Updates
Inconsistent Reads
Concurrent Execution can lead to various challenges
Temporary Update Problem (Dirty Read)
Occurs when a transaction reads data that has been updated by another transaction but has not yet committed.
Incorrect Summary Problem
Happens when aggregate function produces incorrect results because concurrent transactions update some records while the calculation is in progress
Lost Update Problem
Occurs when two transactions update the same data simultaneously, and one update is overwritten by the other without considering the changes
Unrepeatable Read Problem
Occurs when a transaction reads the same data multiple times, but another transaction modifies the data in between ready leading to inconsistent results
Phantom Ready Problem
Happens when a transaction retrieves a set of records based on condition, but another transaction inserts or deletes records that match the condition before the first transaction completes
Without Concurrency Control
Transactions interfere with each other, causing issues
With Concurrency Control
Transactions are properly managed
Read Uncommitted
Allows dirty reads
When performance is the priority & data accuracy is less critical
Read Committed
Prevents dirty reads by ensuring transaction only read committed data
Default, suitable for most cases to avoid dirty reads
Repeatable Read
Prevents dirty reads and non-repeatable reads by locking reads rows until the transaction ends
When consistency is needed but phantom reads are acceptable
Serializable
Prevents dirty reads, non-repeatable reads, and phantom reads by applying reads rows
When strict data consistency is required
Snapshot
Provides a versioned copy of data to each transaction
When high concurrency is needed without blocking
Deadlock
occurs when two or more transactions are blocked indefinitely, each waiting for the other to release a resource that it needs to complete its operation, creating a circular dependency
is a concurrency control problem where two or more transactions are stuck in a waiting state, unable to proceed because each is holding a resource that the other needs
Lock Ordering
Enforce a consistency
Lock Escalation
Use a strategy when locks are escalated to a higher level to reduce contention
Short Transactions
Keep transactions as short as possible to reduce the time resources are held
Deadlock Prevention
Implement strategies to avoid the conditions that lead to deadlocks
Deadlock Detection
Implement mechanisms to detect deadlocks and take corrective actions
Wait-for-Graph
Use a graph to represent the wait relationships between transaction and resources
Timeout
Set a timeout for transactions to prevent them from waiting indefinitely
Rollback (Deadlock)
Roll back one or more of the deadlocked transactions to break the cycle
Deadlock Avoidance
is suitable for smaller databases
Wait-Die Scheme
If a transaction requests a resource that is locked by another transaction, then the DBMS simple checks the timestamp of both transactions and allows the older transaction to wait until the resource is available for execution
Wound Wait Scheme
If an older transaction requests for a resouce held by a younger transaction, then an older transaction forces a younger transaction to kill the transaction and release the resource.