AS Level Information Technology
1/153
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
154 Terms
What is the difference between Data and Information?
Data consists of raw figures, characters, or numbers.
Data does not have any meaning or context on its own.
Information is data that has been processed or given meaning or context.
Essentially, data is the raw input, and information is the meaningful output after processing.
Example: Numbers like "25, 10, 2023" is data. When processed and given context, such as "The exam is on 25/10/2023", it becomes information.
What makes Information good quality? (Focus on Accuracy)
The quality of information is determined by a number of attributes.
Accuracy is a key attribute of good quality information.
Information must be accurate to be considered good quality.
Inaccurate data is likely to lead to poor decisions.
Information should be free from errors or mistakes.
Examples of inaccurate information:
A decimal point in the wrong place, like $90.30 instead of $9030.
Misspelling a word like 'stair' instead of 'stare'.
Misplaced characters in a sequence, like a car licence plate BW93PET instead of BW93BPET.
What makes Information good quality? (Focus on Relevance)
Relevance is another attribute of good quality information.
Information is relevant if it is useful and relates to its purpose.
Irrelevant information makes it harder to find what is actually required.
Selecting relevant information is important—like teachers focusing on content related to your exams.
Examples of irrelevant information:
Being given a bus timetable when you want to catch a train.
Being told the rental price of a car when you want to buy it.
A user guide for a mobile phone including how to assemble a plug.
What makes Information good quality? (Focus on Age)
The age of information refers to how current or up-to-date it is.
Information must be current to be useful.
It may be out of date if collected at a different time.
Always check when the information was produced.
Examples of out-of-date information:
Census data from 2011 when 500 new homes have since been built.
A rugby score not updated for 5 minutes, during which a player scored.
What is Encryption and why is it used?
Encryption is the process of scrambling or converting information so it's unreadable without a key.
It is used to protect data, especially personal data.
It ensures confidentiality.
Encrypted data cannot be unscrambled without a decryption key.
Explain Symmetric Encryption.
Symmetric encryption is the oldest encryption method.
Also called secret key encryption.
Requires both sender and recipient to have the same key.
One key is used to both encrypt and decrypt data.
The key must be shared between sender and receiver.
A main drawback is that the key can be intercepted during transmission.
Explain Asymmetric Encryption.
Also known as public-key cryptography.
Solves the problem of intercepted symmetric keys.
Uses a pair of keys:
Public key: available to anyone.
Private key: kept secret by the recipient.
Sender encrypts using the recipient’s public key.
Recipient decrypts using their private key.
Decryption requires both keys to work together.
What is Validation (in data processing) and why is it used?
Validation checks that data entered into a system is reasonable and acceptable.
It ensures data conforms to predefined rules.
It confirms the data is within set boundaries.
Validation can catch errors immediately during input.
Name and describe some types of Validation checks.
Presence check: Ensures data is entered in required fields.
Length check: Ensures data is the correct length.
Type check: Ensures data is the correct data type (e.g., number, text).
Format check: Ensures data follows a specific pattern (e.g., dd/mm/yyyy).
Lookup check: Ensures data matches values in a list or table.
Range check: Ensures data falls within an acceptable range (e.g., marks between 0–100).
What is Verification (in data processing) and why is it used?
Verification checks that data has been accurately copied from one source to another.
It ensures the entered data matches the original.
Differs from validation: validation checks if data is reasonable; verification checks if it’s correct.
Methods include:
Double-entry: Typing data twice and comparing.
Visual check: Manually comparing source and entered data.
What is Data Processing?
Data processing is the manipulation of data to produce information.
It involves converting raw data into more understandable formats like graphs and reports.
Its goal is to provide structure and context so data can be used effectively.
Data processing is what turns data into information.
Describe Batch Processing.
Data is collected over time and processed all at once as a batch.
There’s a delay between data collection and processing.
Often scheduled for off-peak times.
Requires little human interaction during processing.
Errors are found later, only when processing is complete.
Data accuracy is only guaranteed at processing time.
Examples: Payroll, utility billing, credit card transactions.
Describe Online Processing.
Data is processed almost instantly.
Immediate system response when data is input.
Errors are revealed right away.
Data stays accurate because it is constantly updated.
Systems must run continuously.
Useful where instant access to up-to-date data is needed.
Examples: EFT, stock control, online shopping.
Describe Real-time Processing.
Data is processed immediately with no noticeable delay.
Information is always current, allowing fast system responses.
Output often directly affects input, triggering immediate actions.
Commonly uses sensors to collect live data.
Examples: Automated systems like greenhouses, heating, traffic lights, security systems, car park barriers.
What is the basic difference between Hardware and Software?
Hardware refers to the physical components of a computer system.
These are the parts you can touch, like the CPU, motherboard, RAM, monitor, keyboard, mouse, printer, and memory card.
Software refers to the programs or applications that run on the hardware.
Software consists of instructions that tell the hardware what to do.
Software is typically stored as instructions in binary format (ones and zeros).
What are Mainframe Computers? Give examples of their uses.
Mainframe computers are powerful computers.
They can connect to many terminals, often thousands, within an organisation.
Terminals are typically dummy terminals that rely on the mainframe for processing.
Mainframes are used to host business databases accessed by multiple users simultaneously.
Also used for large-scale transaction processing and batch processing.
Examples: Processing payrolls, utility bills, credit card transactions, and statistical analysis (e.g. census data).
What are Supercomputers? Give examples of their uses.
Supercomputers are large computers with parallel processing capabilities.
Designed to perform highly complex tasks quickly.
Used to run a small number of programs that require maximum processing speed.
Essential for research in quantum mechanics, molecular simulations, weather forecasting, and climate studies.
Examples: Weather forecasting, climate research, and simulating scientific phenomena.
What are the advantages of using Mainframe Computers?
Designed to be reliable, available, and serviceable (RAS).
Scalable—processors and memory can be added as needed.
Built to last at least 10 years.
Can store and process extremely large amounts of data.
Support multiple operating systems, enhancing performance.
Detect hardware failures immediately for quick replacement.
Terminals require only basic I/O devices and use mainframe processing power.
What are the disadvantages of using Mainframe Computers?
High cost of mainframes and supercomputers.
Typically used only by large organisations (e.g. governments, banks).
Require specialist operating systems, which are costly.
Need significant space for installation.
Must be kept at suitable temperature conditions.
Require specialist support staff for maintenance.
Usually have a command-line interface, which can be challenging to use.
What is System Software?
System software is required to operate the computer system.
It includes programs designed to maintain or run the system.
Examples include the Operating System and Utility Software.
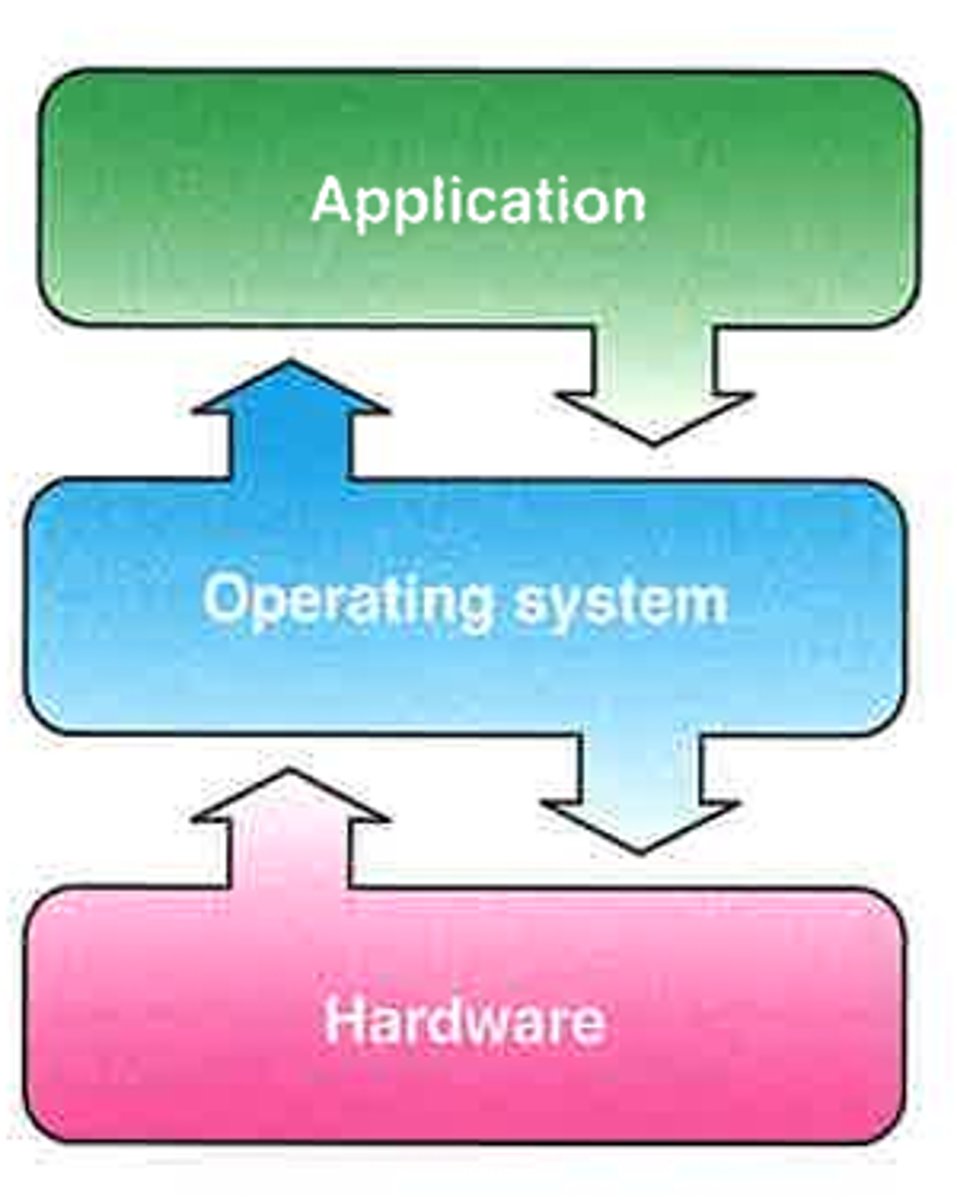
Explain the role of an Operating System (OS).
An Operating System (OS) is software that controls computer hardware.
It manages the system as soon as the computer is turned on.
Loads immediately after the BIOS.
Acts as a bridge between hardware and application software.
Tasks of the OS include:
Allocating memory to software
Sending data to output devices
Responding to input devices (e.g., keyboard)
Managing files on storage devices
Distributing processor time fairly
Handling errors and status messages
Managing user logins and security
What is a Device Driver?
A device driver is a software program that comes with an external hardware component.
It provides the OS with custom instructions to communicate properly with that hardware.
Each hardware model (e.g. different printers) may require a unique driver.
What are Translators in software development? Name the types.
Translators convert high-level code into machine code that computers can understand.
High-level code is human-readable, while machine code is binary (0s and 1s).
The three types of translators are:
Compilers
Interpreters
Linkers
Explain the difference between a Compiler and an Interpreter.
Compiler:
Translates the entire program at once into machine code.
Produces an independent executable file.
Compilation occurs before execution.
Program runs faster after compilation.
Errors are shown after full compilation.
Interpreter:
Translates and runs code line by line.
Does not produce an executable file.
Needs the interpreter every time the program runs.
Runs slower than compiled code.
Errors appear immediately when encountered.
What is Utility Software? Give examples of its purpose.
Utility software performs maintenance tasks on the system.
Does not include the operating system itself.
Often comes pre-installed with the OS.
Helps manage, maintain, and control resources.
Examples: Anti-virus software, Backup utilities, File management tools.
Describe the purpose of Anti-virus software and Backup software.
Anti-virus software:
Protects against viruses and other threats (malware, spyware).
Monitors the system continuously.
Detects, quarantines, or deletes threats.
Prevents execution of harmful programs.
Backup software:
Creates a duplicate copy of data.
Used to restore files if the original is lost or damaged.
Can be scheduled to run automatically.
Users can select specific files or folders to back up.
What is the difference between Custom-written software and Off-the-shelf software?
Custom-written software:
Made for a specific client.
Not available to the public.
Expensive, as client bears full cost.
Takes a long time to develop.
Matches exact needs, no extras.
May have initial bugs.
Comes with developer support.
Off-the-shelf software:
Already developed and sold to the public.
Designed for general use.
Cheap, as costs are shared among users.
Ready to use instantly.
May include unnecessary features.
Bugs are usually already fixed.
Supported via forums, help lines, etc.
What is a User Interface (UI)? What makes a UI 'user-friendly'?
A User Interface (UI) is how the user interacts with the computer system.
Acts as the boundary between the user and the system.
Allows interaction through input devices and software.
A user-friendly UI is easy to use, intuitive, and predictable.
An intuitive UI enables users to know what to expect (e.g., clickable buttons resemble real ones).
Name and briefly describe four major types of User Interfaces.
Command Line Interface (CLI):
User types text commands; output is shown in text.
Example: typing cd logs in a terminal.
Graphical User Interface (GUI):
Uses windows, icons, menus, and pointers (WIMP).
Users click rather than type commands.
Dialogue Interface:
Interface where user interacts via text or speech. (Not deeply covered in source)
Gesture-based Interface:
Involves physical gestures (like swiping or tapping). (Not deeply covered in source)
List and describe some common Form Controls used in User Interfaces.
Elements used in GUIs for input or displaying data.
Labels: Text prompts that cannot be edited.
Text boxes: Allow users to type in data (e.g., name).
Tick boxes (Checkboxes): Multiple selections from a set.
Option buttons (Radio buttons): Only one selection per group.
Drop-down boxes: Single selection from a long list.
Buttons: Used to confirm actions, navigate, clear data, or request help.

What is disk defragmentation?
Disk defragmentation is a utility software process that reorganises the files on a hard disk.
It moves file fragments closer together so that each file occupies contiguous sectors.
This reduces the time the read/write head spends moving around the disk, making file access faster.
It is especially useful for hard disk drives (HDDs), but not needed for solid-state drives (SSDs).
Why do files become fragmented on a hard disk?
When files are saved, deleted, or edited, they can be stored in non-contiguous blocks.
As a result, a single file may be scattered in pieces across the disk.
Over time, this fragmentation increases, causing slower file access and reduced performance.
What are the benefits of disk defragmentation?
Speeds up file access times by storing files in one place.
Improves the overall performance of the hard disk.
Frees up more contiguous free space, which helps avoid further fragmentation.
Helps extend the lifespan of the hard disk by reducing mechanical movement.
Why is defragmentation not necessary for SSDs?
SSDs have no moving parts, so file location does not affect access speed.
Defragmenting an SSD provides no speed benefit.
It may actually reduce the lifespan of the SSD due to unnecessary write cycles.
When should disk defragmentation be performed?
When your computer starts to slow down during file access.
After installing or uninstalling many programs.
When the disk is heavily used and becomes fragmented.
Many systems can be set to automatically defragment on a schedule.
What is a monitoring system?
A monitoring system is an IT system that observes and often records the activities in a process.
Purpose: To keep track of what is happening within a system or environment.
Example: A weather station is a monitoring system. It uses sensors to collect data like temperature, pressure, humidity, and light. This data is observed and recorded to help predict the weather. Another example is a system in a textile factory monitoring chemical levels in a nearby river to check for pollution.
What is a control system?
A control system is an IT system designed to manage or regulate a process by physically changing aspects of the system based on the collected data.
Purpose: To automatically adjust or take action within a system based on input data.
Key Components: Typically uses sensors to collect data, a microprocessor (computer) to process the data and make decisions, and actuators to carry out physical actions.
Example: A central heating system is a control system. A temperature sensor collects the room temperature. The microprocessor compares it to a pre-set value and may activate an actuator, like turning on the furnace, to change the temperature.
What is the role of sensors in monitoring and control systems?
Sensors function as input devices in these systems.
They collect data about the physical environment automatically.
They remove the need for manual human data collection.
The collected data is then input into the system for processing or control action.
List different types of sensors.
Common types of sensors include:
Light/UV sensors
Infrared sensors
Temperature sensors
Pressure sensors
Humidity sensors
Sound sensors
Touch sensors
Electromagnetic field sensors
Proximity sensors
What are the advantages of using sensors?
Advantages of using sensors to collect data include:
Data can be collected 24 hours a day, reducing the need for constant human presence.
Data can be collected in dangerous or harmful environments without risking human safety.
Sensors can provide more consistent and accurate readings compared to mechanical devices (although they can still fail or become faulty).
What is calibration and why is it important for sensors?
Calibration is the process of testing and modifying a device (such as a sensor) to ensure it is taking correct readings.
Importance: Inaccurate data can be useless or dangerous, especially in a control system. Calibration ensures sensor data is accurate, allowing the system to function properly.
How can sensors be calibrated? Describe one method.
Calibration involves comparing a sensor’s reading to a known reference. One method is to test the sensor against a calibrated sensor.
Types of Calibration: One-point, two-point, and multipoint calibration.
One-Point Calibration: Used to correct an offset error — when the sensor is always too high or too low by a fixed amount. You find the offset by comparing the reading to the reference, then adjust all future readings accordingly.
Example: If a thermometer reads 22°C when the actual value is 20.5°C, the offset is +1.5°C. Subtract 1.5°C from future readings.
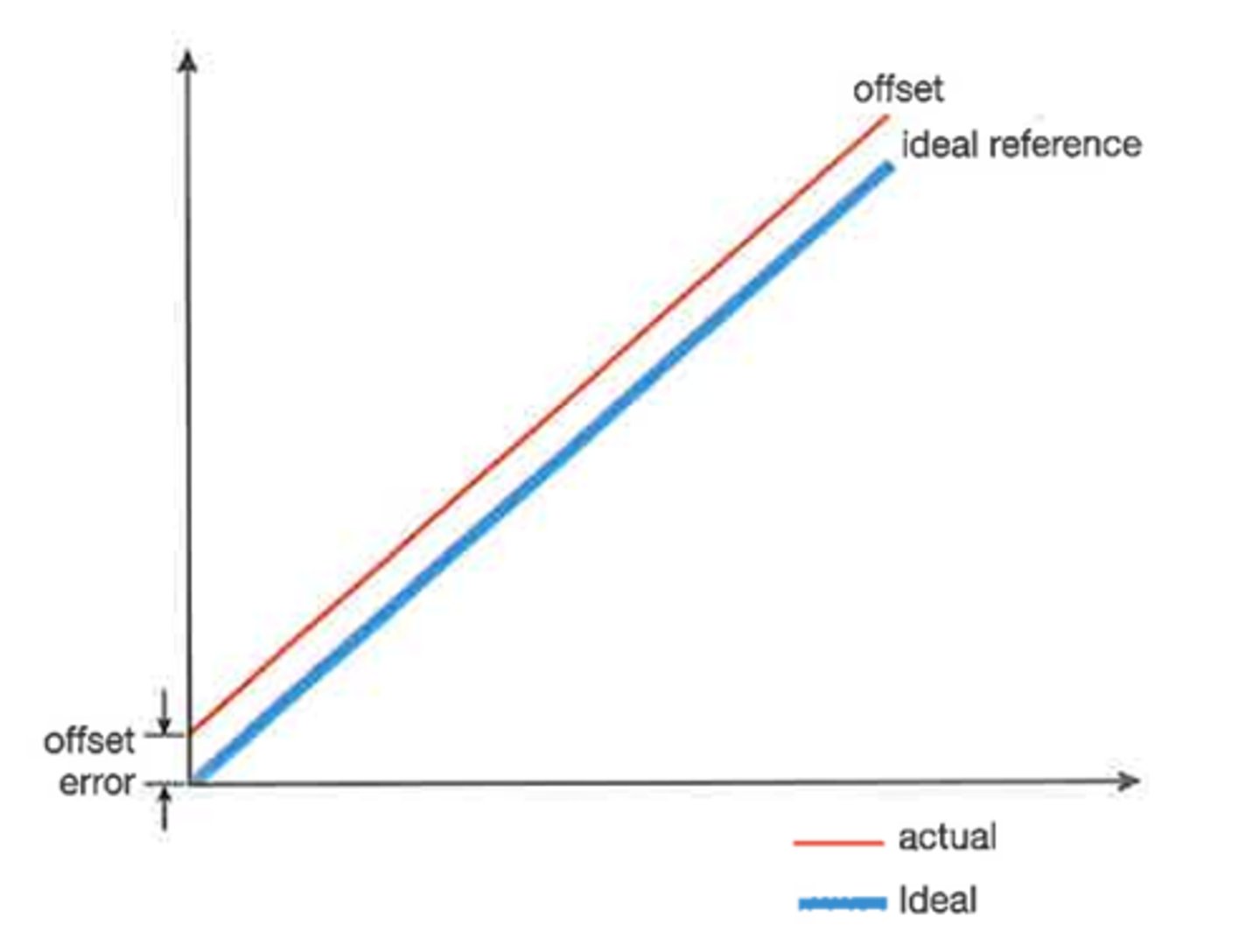
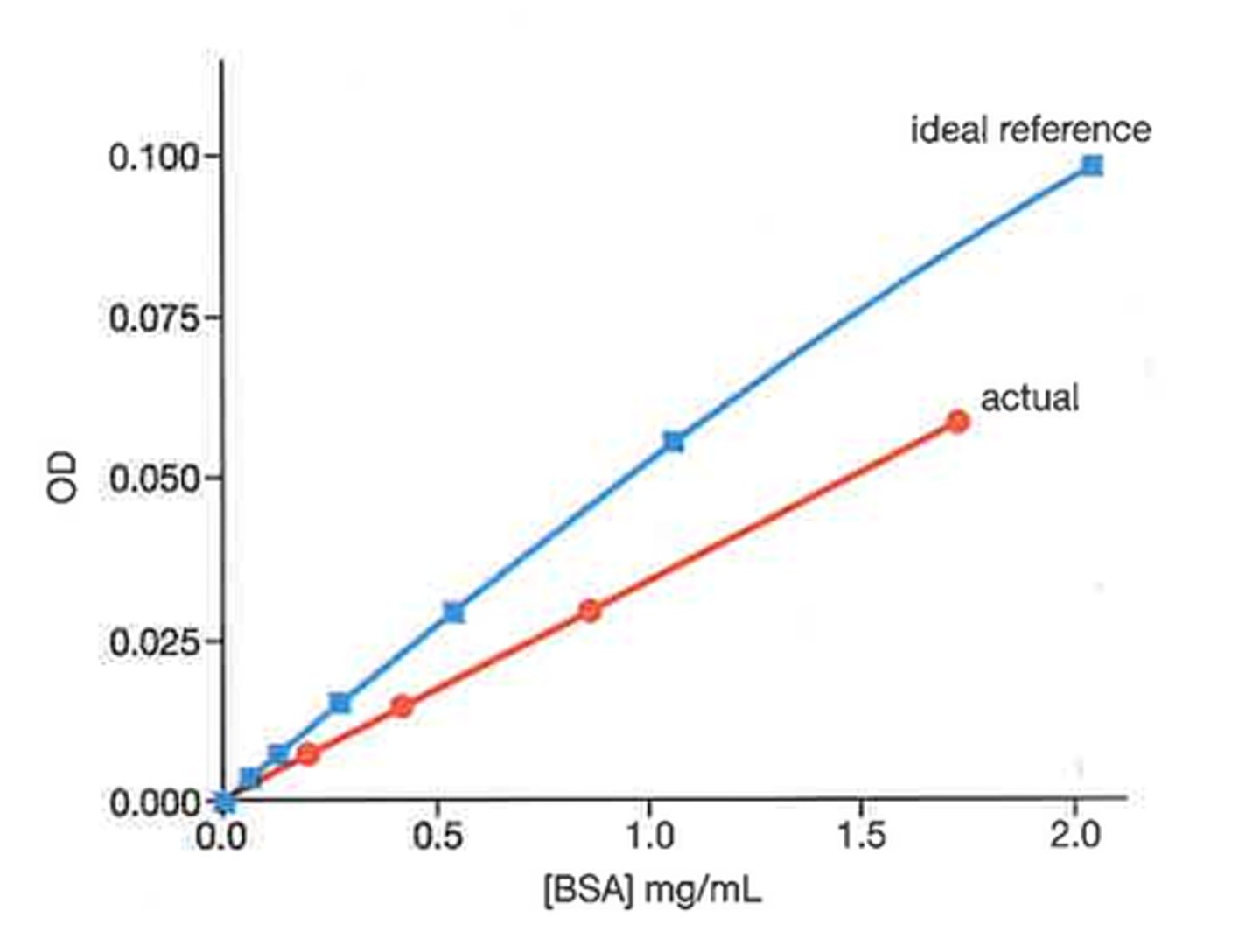
Explain the key concepts related to sensor calibration curves: Offset, Sensitivity, and Linearity.
These describe how a sensor's readings compare to ideal values:
Offset: Sensor readings are consistently above or below the correct value by a fixed amount.
Sensitivity: Sensor readings change at a different rate compared to the ideal — not as fast or too fast.
Linearity: How close the sensor’s readings follow a straight-line relationship with the ideal. The ideal sensor shows a perfect straight line.
What is the role of a microprocessor (computer) in monitoring and control systems?
The microprocessor is the brain of the system.
It receives input data from sensors.
It analyzes and processes the data.
In control systems, it follows algorithms to make decisions and sends signals to actuators to trigger actions.
What is the role of actuators in control systems?
An actuator is a device that receives an electronic signal and creates physical movement or change.
It carries out actions as instructed by the microprocessor.
Examples: Motors, pumps, valves, alarms, locks, and lights.
In a heating system, the actuator may turn the furnace on or off based on temperature data.
How are algorithms and flowcharts related to control systems?
Algorithms and flowcharts provide structured instructions for control systems.
An algorithm is a set of rules or steps that the system follows.
A flowchart visually represents an algorithm using symbols.
They are used to describe how the microprocessor should analyze input data and decide what action to take through actuators.
Are there any disadvantages to using sensors?
Yes, sensors can also have drawbacks.
They may suffer from wear and tear over time.
Faulty sensors can give incorrect data.
This may lead to wrong decisions by the system and potentially dangerous outcomes if the control system acts on incorrect input.
What is an Algorithm?
An algorithm is a series of steps followed to solve a problem or complete a task. Like a recipe, it's a clear, ordered list of instructions.
Algorithms must be followed step-by-step.
They need to be precise so there's no confusion about what to do at each step.
How are Algorithms Represented?
Algorithms can be represented in different ways to make them easier to understand and follow. Two common methods are:
Flowcharts: Use symbols connected by lines to show the steps and flow of logic in the algorithm.
Pseudocode: A way of writing the steps using structured English. It resembles programming code but uses plain language and keywords (e.g. INPUT, OUTPUT, WHILE, IF) without strict syntax rules.
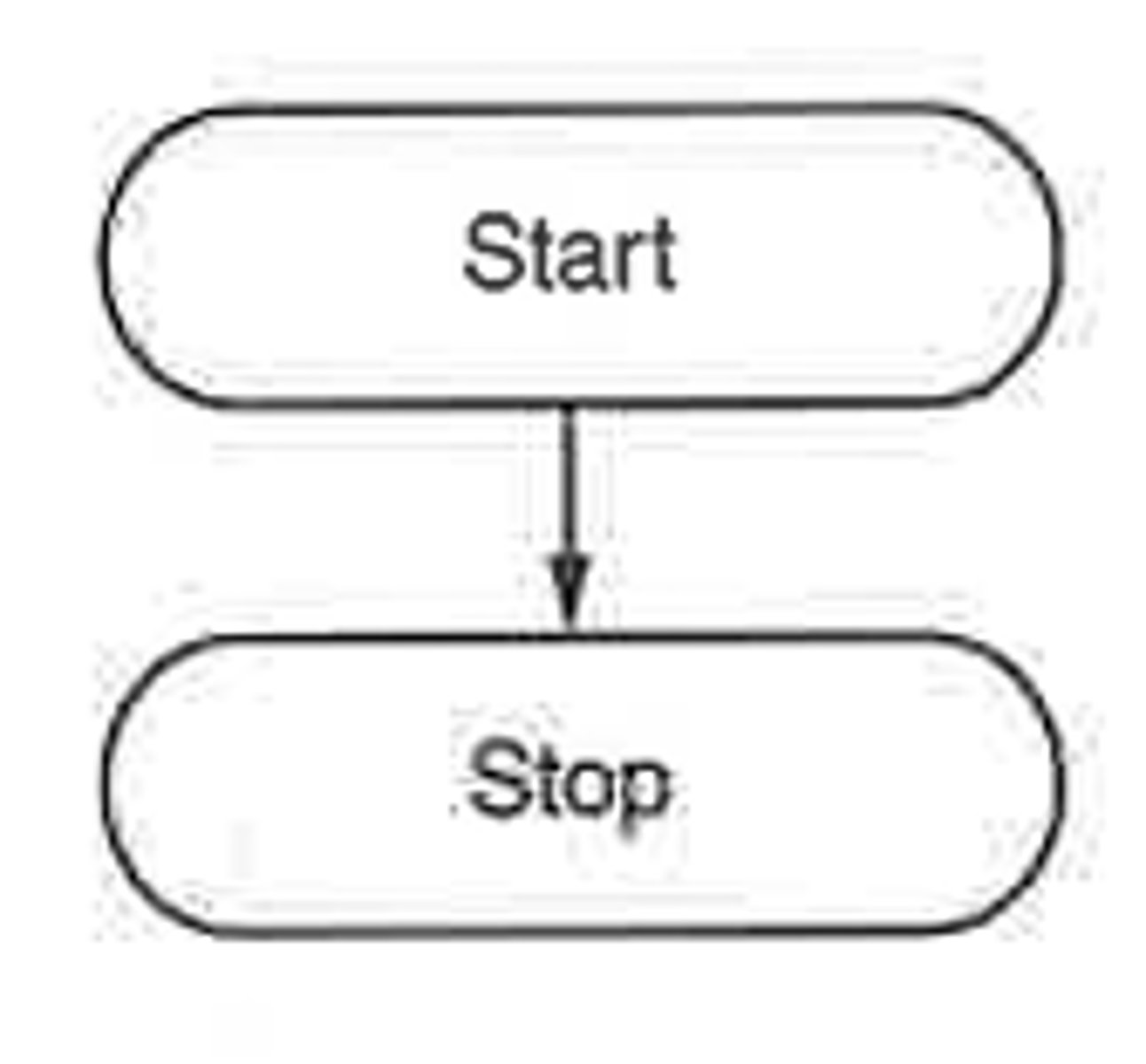
What are the basic Flowchart Symbols?
Flowcharts use specific shapes to represent different types of steps:
Terminator (Start/Stop): Oval shape used at the beginning and end of a flowchart.
Process Box: Rectangle shape for any action or calculation.
Input/Output Box: Parallelogram shape for data input or output.
Flow Lines: Arrows connecting symbols to show direction.
Decision Box: Diamond shape for a choice based on a condition (e.g., Is X > 10?).
Connector: Small circle to connect parts of a flowchart, especially on multiple pages.
What are Variables and Assignment in Algorithms?
Variables store temporary data in memory during the execution of an algorithm.
A variable is a named storage space in memory.
Examples: myNumber, totalScore, userNameAssignment is putting a value into a variable.
In pseudocode, this can be shown with <- or =.
Examples: counter <- 0 or total = num1 + num2
Process boxes in flowcharts often represent assignment or calculations.
How is Selection (Making Choices) shown in Flowcharts and Pseudocode?
Selection allows an algorithm to take different paths based on whether a condition is True or False.
Flowcharts: Use a diamond (Decision) symbol.
One input flow line and two output lines labelled ‘Yes’ and ‘No’.
Pseudocode: Uses IF, THEN, ELSE, and ENDIF.
IF condition THEN
[code if TRUE]
ELSE
[code if FALSE]
ENDIF
Example:
IF temperature > pre-set THEN
OUTPUT "Too hot"
ELSE
OUTPUT "Temperature okay"
ENDIF
For multiple choices, use ELSIF.
Use CASE...OF...ENDCASE when checking the value of one variable.
What is Iteration (Looping)?
Iteration allows an algorithm to repeat a block of instructions multiple times.
Two main types of loops:
Count-controlled loops – repeat a fixed number of times.
Condition-controlled loops – repeat while or until a condition is met.
How are Count-Controlled Loops shown?
Count-controlled loops repeat for a specific number of times.
Flowcharts: Combine a process box to initialize a counter, a decision box to check the limit, and a process box to update the counter.
Pseudocode: Use FOR and NEXT.
FOR counter = start TO end
[code]
NEXT counter
Example:
FOR count = 1 TO 10
OUTPUT count
NEXT count
![<p>Count-controlled loops repeat for a specific number of times.</p><p>Flowcharts: Combine a process box to initialize a counter, a decision box to check the limit, and a process box to update the counter.</p><p>Pseudocode: Use FOR and NEXT.</p><p>FOR counter = start TO end</p><p>[code]</p><p>NEXT counter</p><p>Example:</p><p>FOR count = 1 TO 10</p><p>OUTPUT count</p><p>NEXT count</p>](https://knowt-user-attachments.s3.amazonaws.com/ef5575ce-24e9-486e-a22d-44790f09299b.png)
How are Condition-Controlled Loops shown?
These loops continue while or until a condition is met.
Flowcharts: Use a diamond (Decision) symbol to check the condition.
Pseudocode:
WHILE loop: Checks the condition before the loop starts.
WHILE condition
[code]
ENDWHILE
Example:
total <- 0
WHILE total < 100
INPUT number
total <- total + number
ENDWHILE
REPEAT loop: Runs the code at least once, then checks the condition.
REPEAT
[code]
UNTIL condition
Example:
REPEAT
INPUT password
UNTIL password = "correct"
![<p>These loops continue while or until a condition is met.</p><p>Flowcharts: Use a diamond (Decision) symbol to check the condition.</p><p>Pseudocode:</p><p>WHILE loop: Checks the condition before the loop starts.</p><p>WHILE condition</p><p>[code]</p><p>ENDWHILE</p><p>Example:</p><p>total <- 0</p><p>WHILE total < 100</p><p>INPUT number</p><p>total <- total + number</p><p>ENDWHILE</p><p>REPEAT loop: Runs the code at least once, then checks the condition.</p><p>REPEAT</p><p>[code]</p><p>UNTIL condition</p><p>Example:</p><p>REPEAT</p><p>INPUT password</p><p>UNTIL password = "correct"</p>](https://knowt-user-attachments.s3.amazonaws.com/a4359396-8a0c-4ded-97b4-d0af692be346.jpg)
What are Subroutines (Procedures and Functions)?
Subroutines are named blocks of code for specific tasks. They make algorithms easier to manage.
Procedure: Performs a task but doesn’t return a value.
Starts with PROCEDURE and ends with ENDPROCEDURE.
Function: Performs a task and returns a value to the main algorithm.
Example: A function that calculates a square root.
Flowcharts: Use a special symbol (process box with double lines) to show subroutines.
Parameters: Data passed to a subroutine for it to use.
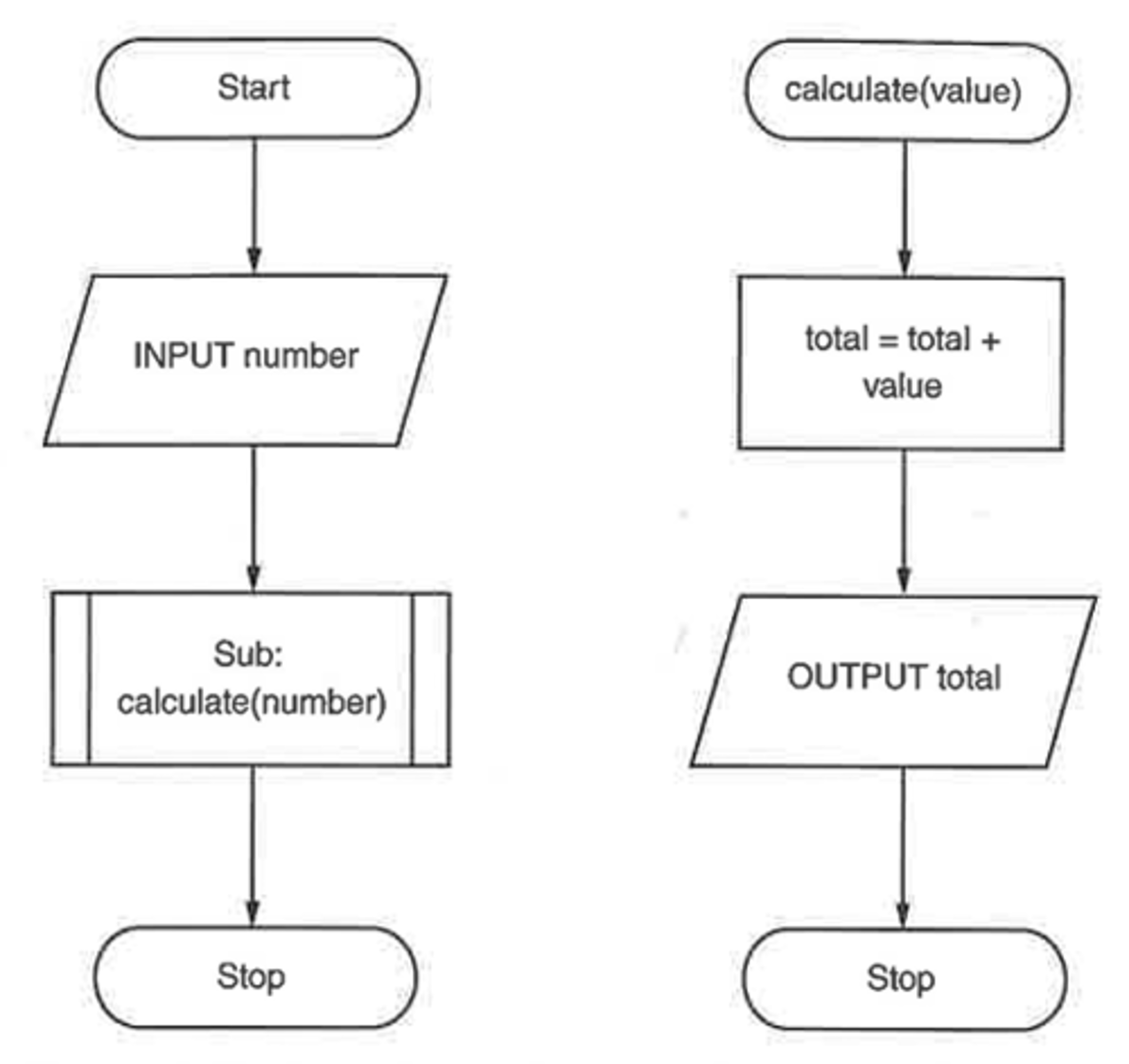
What are Nested Constructs?
Nested constructs occur when one control structure is placed inside another.
Examples:
A loop inside another loop (nested loops)
Example: Looping through rows, then columns
An IF inside another IF (nested IFs)
A loop inside an IF
An IF inside a loop
Nested structures help solve more complex problems.
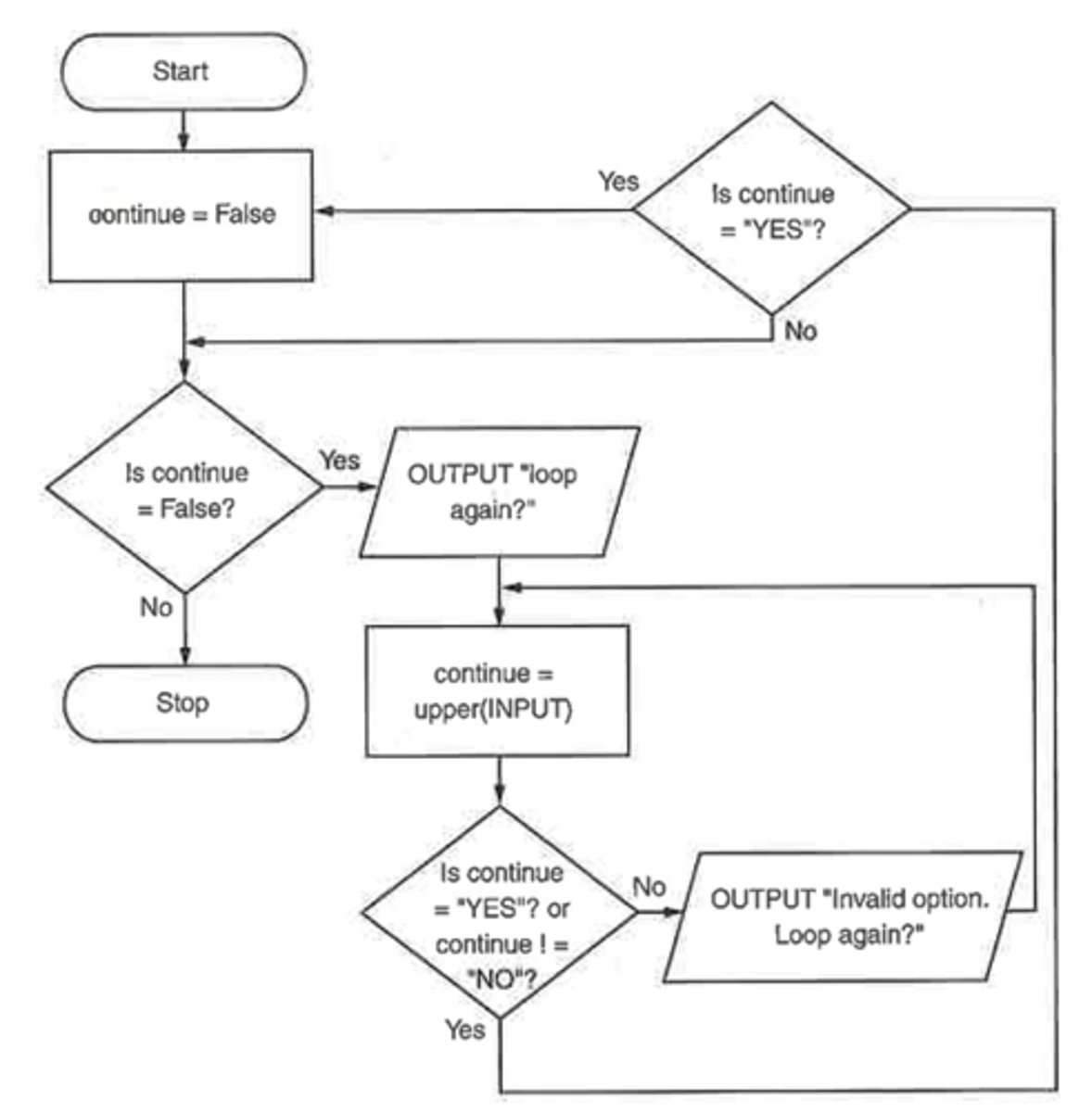
How do you Correct or Edit an Algorithm/Flowchart?
To correct or edit an algorithm or flowchart:
Debugging:
- Go through the algorithm step-by-step with test data.
- Compare what happens with what’s expected.
- This helps locate logic errors.
Editing:
- Identify which steps, symbols, or conditions need changing.
- Modify them to fix or improve the algorithm.
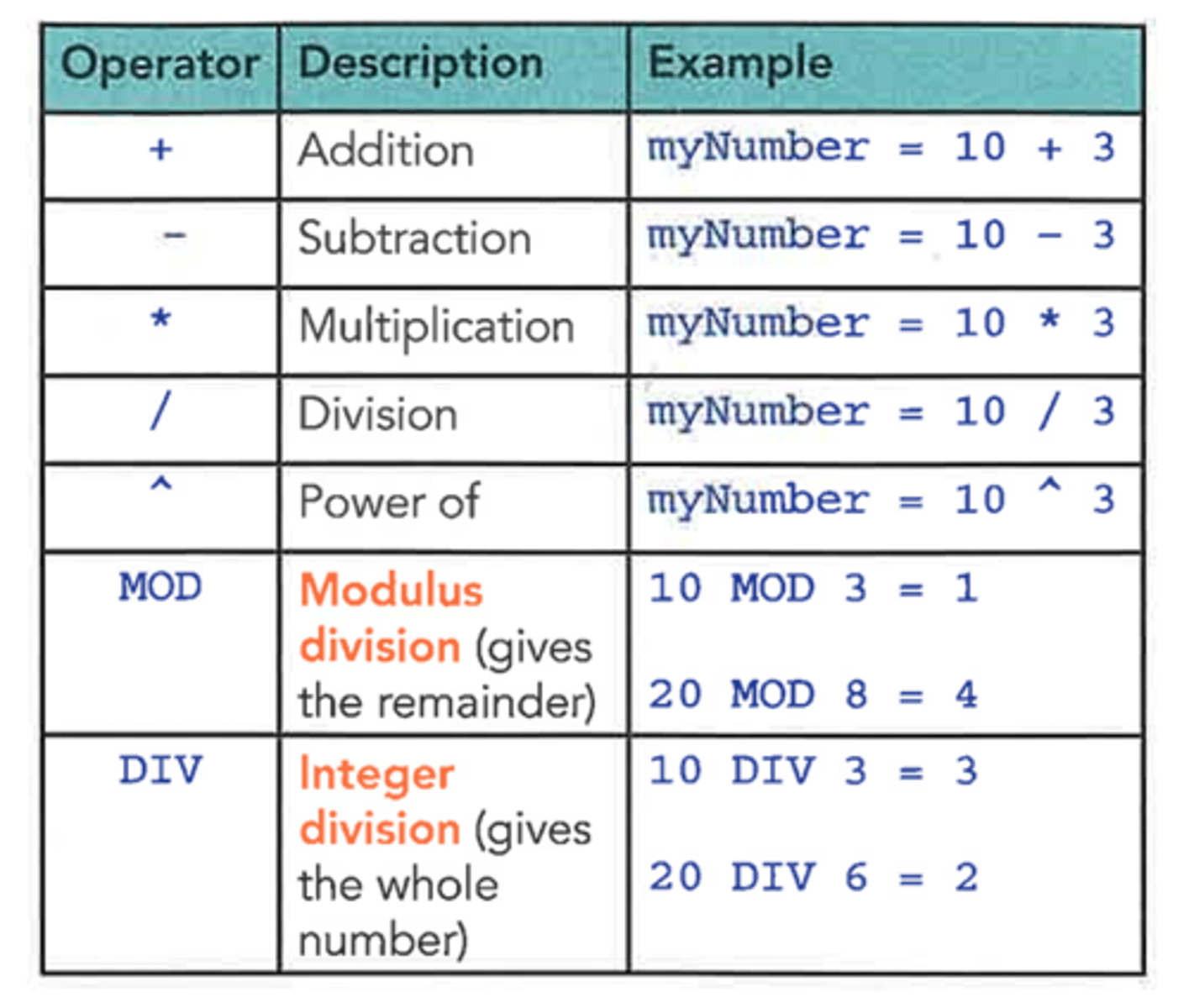
Mathematical (arithmetic) operators.
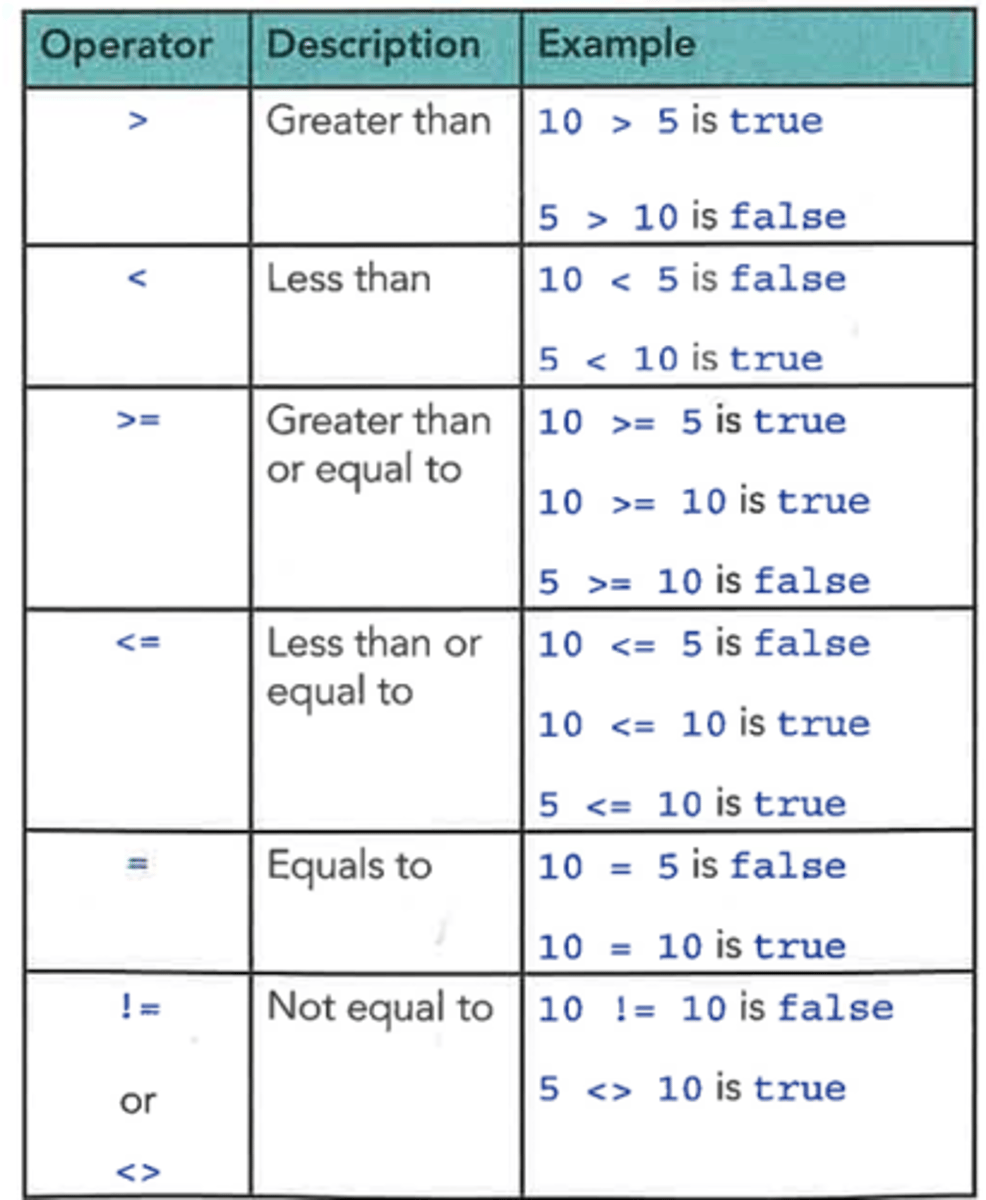
Comparison operators
String manipulators
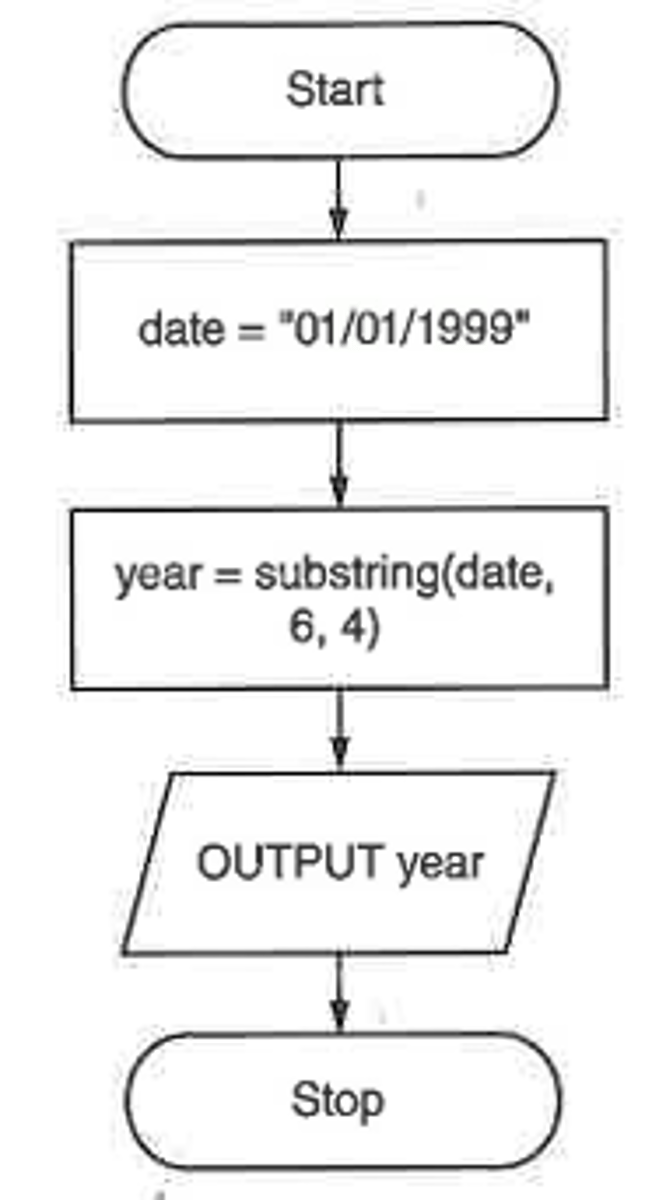
Flowchart to extract year from a date pseudocode.
What is Personal Data?
Personal data is any information that relates to a living individual who can be identified.
Even different pieces of information that, when collected together, allow a person to be identified, count as personal data.
Think of it as information that points directly to you.
Examples include:
Name
Address
Telephone number
Email address
Bank details
Medical records
Salary
Political opinions
Why is it important to keep your Personal Data secure?
When personal information (e.g., credit card details) is sent online, there's a risk it can be intercepted.
If intercepted, it can be changed or used for harmful purposes.
Consequences of misuse include:
- Identity theft
- Identity fraud
- Cyber-fraud
- Ransomware attacks (data held for money)
- Corporate espionage (secrets sold to rivals)
- Spying by rival nations
- Blackmail using private details
- Security bypass (using stolen details to pass bank security)
Using encryption makes intercepted data unreadable and useless to hackers.
How do unauthorised people get your Personal Data?
Often by tricking you into revealing it.
Common methods:
- Phishing: Fake emails that look official, urging you to click links or enter details.
- Smishing: Phishing via SMS.
- Vishing: Phishing via voice calls.
- Pharming: Redirects you to a fake website even if you type the correct address.
How can you help keep your Personal Data safe?
- Use strong, unique passwords.
- Ensure data is encrypted during transmission.
- Install a firewall to monitor and block harmful traffic.
- Use anti-virus software and keep it updated.
- Consider biometric security (e.g., fingerprint login).
- Share personal data only on trusted websites.
- Don’t open email attachments from unknown senders.
- Check links carefully before clicking them.
- Be mindful of what you post online (pictures, opinions).
- Remove geotags from shared photos.
- Avoid accepting friend requests from strangers.
- Use social media privacy controls.
- Report suspicious activity.
- Consider a nickname/pseudonym online.
- Use a VPN when using public Wi-Fi.
What is Malware?
Short for malicious software.
Software designed to damage, disrupt, or gain unauthorised access to computer systems.
What are some different types of Malware?
Virus
Trojan
Worm
Spyware
Adware
Rootkit
Malicious bots
Ransomware
Explain what a Virus is.
A type of malware that attaches to a program or file.
Replicates itself when activated.
Needs user action (e.g., opening a file) to spread.
Can damage files or programs.
Detected/removed using anti-virus software.
Explain what a Trojan is.
Malware disguised as legitimate or harmless software.
Does not replicate automatically.
Needs user to run the infected file/program.
Once active, it can release more malware.
Avoid risk by installing software from trusted sources.
Explain what a Worm is.
Malware that replicates itself without needing to attach to a program.
Spreads by exploiting security vulnerabilities.
Like viruses, worms can damage files or systems.
Explain what Spyware is.
Malware designed to gather user info or monitor activity.
Operates without user knowledge or consent.
Explain what Adware is.
Software that displays unwanted advertisements on your device.
Explain what a Rootkit is.
Malware that allows an unauthorised person to hide files or processes.
Makes detection by security software difficult.
Often used to hide other malware.
Explain what Ransomware is.
Malware that restricts access to your system/files.
Usually encrypts files, making them unreadable.
Ransom demand follows, asking for payment to unlock files.
Best defense: restore data from backup.
What are the potential consequences of a Malware infection?
Damage to the computer system.
Programs/files deleted or corrupted.
Unauthorised access (e.g., Rootkits, Trojans).
Theft of personal data (e.g., passwords, financial info).
Files rendered unusable (e.g., via encryption).
Annoying ads (Adware).
Surveillance without consent (Spyware).
Device turned into part of a botnet.
How can you protect your computer from Malware?
Install and regularly update anti-virus software.
Run scheduled scans (daily/weekly).
Use a firewall to block suspicious traffic.
Be cautious on public Wi-Fi; use a VPN.
Download software only from trusted sources.
Don’t open unknown attachments or click sketchy links.
Keep frequent backups of important data — critical against ransomware.
What is the digital divide?
The digital divide is the gap between different groups of people regarding their access to and ability to use Information Technology.
It refers to the difference in the availability and use of technology like smartphones, mobile phones, personal computers, and the internet.
Groups can be separated by factors such as location, age, socio-economic status, and level of education/skill.
Being on the disadvantaged side of the digital divide means missing out on the many benefits that technology can offer.
What causes the digital divide?
The digital divide is caused by several factors, often related to demographics and the economy:
Geographical Location:
Access to technology services is heavily influenced by where a person lives.
City vs Rural: People in rural areas often have less access to high-speed internet (broadband) compared to city dwellers.
This is because the infrastructure needed for broadband is more developed in urban areas.
Age:
Younger people may feel more confident with technology for communication, entertainment, and research.
Older people may feel less confident, especially if used to older methods like landlines or letters.
They might find new technology difficult or intimidating.
Socio-economic Status:
This relates to a country or region's level of industrial development and the economic situation of individuals.
Less Developed Areas: Tend to have a greater digital divide.
Lower Socio-economic Groups: May struggle to afford computers, smartphones, software, or internet access.
Education and Skills:
There is a divide between people who are educated in using technology and those who are not.
This refers to having the necessary skills to make good use of the technology available.
What are the effects of the digital divide?
The digital divide has several negative effects for individuals and groups with limited access or skills:
Limited Access to Information and Services:
Difficulty accessing online educational resources, government services, banking, and healthcare information.
Reduced Communication:
Hinders use of modern methods like email, video conferencing, or social media.
May lead to social isolation.
Older individuals may struggle to communicate with digitally connected younger relatives.
Economic Disadvantages:
Limits opportunities for online work, accessing customers through the internet, or using digital business tools.
People in less developed areas may miss out on economic growth driven by IT.
Disadvantage in Education and Employment:
Lack of access to online learning platforms or digital skills can hinder academic and job success.
Missed Entertainment and Leisure:
Difficulty accessing streaming services, music, games, and other digital entertainment.
Feeling Excluded or Left Behind:
Individuals, particularly older adults, may feel left out of a digitally connected society.
How can the digital divide be reduced?
Reducing the digital divide involves addressing the factors that cause it:
Improving Infrastructure:
Expand access to high-speed internet (broadband) in rural and less economically developed areas.
Increasing Affordability:
Implement programs to make devices and internet service more affordable for low-income communities.
Providing Education and Training:
Offer digital literacy courses and training tailored to older adults or those with limited IT experience.
Developing User-Friendly Technology:
Design software and hardware with simpler interfaces for beginners or less experienced users.
Government and Community Initiatives:
Launch projects to provide public internet access points, distribute donated computers, and fund digital inclusion programs.
What is an Expert System?
An expert system is a computer system designed to mimic the decision-making ability of a human expert.
It is used to produce possible solutions for different scenarios.
Expert systems can provide an explanation of how an outcome was achieved.
They are used in a variety of different scenarios.
What are the main components of an Expert System?
An expert system is typically made up of several key components:
Knowledge Base: The core of the system. It contains:
Database of Facts: Information relevant to the expert's field.
Rules Base: A set of "IF-THEN" rules the expert uses to make decisions or draw conclusions.
Inference Engine: The "brain" of the system. It processes the facts and rules in the knowledge base to arrive at a conclusion or suggestion.
User Interface: Allows the user (e.g., doctor or customer) to interact with the system, input information (facts), and receive conclusions/explanations.
Explanation System: Explains how the expert system reached a particular conclusion to help users understand the reasoning.
Knowledge Base Editor: A tool used by human experts (or knowledge engineers) to add, update, or modify facts and rules in the knowledge base.
How are Expert Systems used, and what are their advantages and disadvantages?
Applications:
Medical diagnosis: Helping doctors diagnose illnesses.
Car engine fault diagnosis: Identifying problems in vehicles.
Financial planning: Managing finances, planning for retirement, or assessing financial actions.
Chess playing: Systems like Deep Blue designed to play chess.
Other uses: Medical symptom checkers, aiding professionals, answering questions outside normal knowledge, quicker than humans.
Advantages:
Can answer questions outside the user's knowledge.
Can aid professionals by prompting and guiding them to relevant areas.
Available any time, regardless of time or day.
Can quickly arrive at a solution, often faster than a human.
Responses are logical, based on provided data and rules.
Disadvantages:
Do not have human intuition.
Only logical; may not be useful in all complex situations.
Dependent on the quality of provided rules/data — errors can cause incorrect results.
Expensive to create.
Require many components and a high level of skill to build.
Cannot easily adapt to new environments — the knowledge base may need editing to adjust.
Explain Forward Chaining.
Forward chaining is a type of reasoning used by the inference engine in an expert system.
It is data-driven reasoning.
The process starts with the available data or facts.
The system moves forward from rule to rule to reach a conclusion or outcome.
Suitable for open-ended problems where the desired outcome is not predefined.

Explain Backward Chaining.
Backward chaining is a type of reasoning used by the inference engine.
It is goal-driven reasoning.
The process starts with a potential conclusion or goal.
The system works backward, breaking the goal into sub-goals or required conditions.
It checks whether the necessary facts exist (or asks the user) to support the goal.
Useful for verifying specific hypotheses or checking if an outcome is possible.

What is the fundamental purpose of spreadsheet software?
Spreadsheet software is used to create and manipulate grids of data.
It's excellent for tasks involving calculations, analysis, and presentation of numerical data.
Spreadsheets can be used for various purposes, from simple calculations to complex models and simulations.
What are the basic building blocks of a spreadsheet?
A spreadsheet is made up of sheets or worksheets, which are like pages.
Each sheet contains a grid of cells, organised into rows and columns.
Rows are identified by numbers, and columns by letters.
A cell is the intersection of a row and a column and is identified by its column letter followed by its row number (e.g., A1, B3).
How can you control what the user sees in a large spreadsheet?
You can freeze panes and windows.
Freezing panes keeps specific rows (usually at the top) or columns (usually on the left) visible while you scroll.
Useful for keeping headers or key identifiers in view as you navigate large datasets.
How do spreadsheets perform calculations?
Calculations are performed using formulae.
A formula typically starts with an equals sign =.
Formulae can use mathematical operators:
+ (addition),
- (subtraction),
* (multiplication),
/ (division),
^ (exponentiation).
Spreadsheets follow the order of operations (e.g., BODMAS/PEMDAS).
Explain the difference between relative and absolute cell referencing in formulae.
Relative referencing (default): When you copy a formula, cell references adjust relative to their new position.
- E.g., A3 in cell B3 becomes A4 in B4.
Absolute referencing uses dollar signs ($) to fix a cell reference (e.g., $A$1).
- This reference does not change when copied.
Absolute references are used for fixed cells with constants or key values.
What is a function in a spreadsheet, and why are they used?
A function is a pre-defined formula.
Used for simplifying complex or repetitive calculations.
Examples:
SUM, AVERAGE, MIN, MAX.
Explain how conditional functions like COUNTIF work.
Conditional functions operate only when a condition is met.
COUNTIF counts how many cells in a range meet a criterion.
E.g., =COUNTIF(C3:C10,"Pass") counts how many cells contain "Pass".
What is a nested IF statement?
A nested IF statement is one IF inside another IF.
Used for more than two outcomes.
Evaluates the second IF only if the first is false.
Example use: Assigning grades (Distinction → Merit → Pass → Fail).
What is the IFS function and how does it compare to nested IF statements?
IFS checks multiple conditions, returns the value of the first true one.
Easier to read than deeply nested IFs.
Takes condition-value pairs.
No ELSE option, unlike nested IFs.
What are rounding functions in a spreadsheet?
Rounding functions change a number's precision.
Examples:
INT: Removes decimal part.
ROUND: Rounds to set decimal places.
ROUNDUP: Always rounds up.
ROUNDDOWN: Always rounds down.
What is the purpose of using lookup and reference functions like HLOOKUP, VLOOKUP, INDEX, and MATCH?
Used to search and retrieve data from tables/ranges.
VLOOKUP: Searches vertically in the first column.
HLOOKUP: Searches horizontally in the first row.
MATCH: Returns position of a value.
INDEX: Returns the value at a given position.
INDEX + MATCH is more flexible than VLOOKUP.
What is a named range and why is it useful?
A named range is a custom name for a cell or range.
E.g., instead of $A$1:$A$10, use SalesData.
Benefits:
- Easier to read and write formulae.
- Implicitly uses absolute referencing.
What is data validation in spreadsheets?
Restricts what kind of data can be entered.
Helps maintain accuracy and consistency.
Validation rules compare input against defined criteria.
Describe different types of data validation rules that can be applied in a spreadsheet.
Lookup list: Only allows values from a predefined list.
Range check: Only allows values within a min-max range.
Type check: Ensures input is a number, date, etc.
Length check: Limits the number of characters.