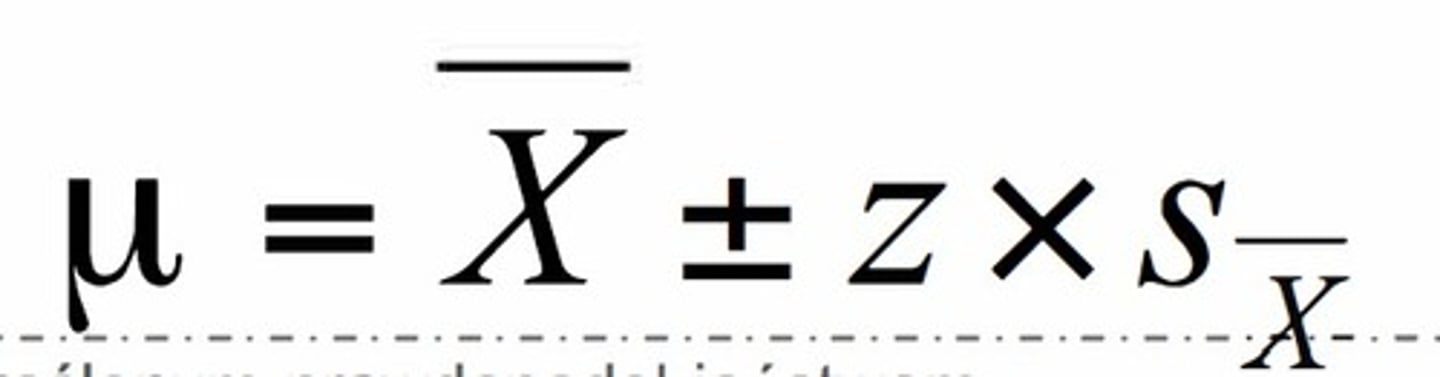Rozkład normalny, standaryzacja wyników, testowanie statystyczne hipotez | Quizlet
1/43
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
44 Terms
rozkład zmiennej jest normalny w populacji
im bardziej zwiększamy naszą próbkę tym bardziej rozkład zmiennej w próbie zbliża się do normalnego
rozkład normalny - oś rzędnych
gęstość - częstość występowania danych wartości
rozkład normalny - oś odciętych
możliwe wartości zmiennej X
asymptotyczność
krańce rozkładu normalnego stykają się z osią X w nieskończoności
rozkład normalny - kształt
symetryczny wokół średniej, mezokurtyczny
rozkład normalny jako funkcja średniej i odchylednia standardowego
znając średnią i odchylenie standardowe możemy wyznaczyć krzywą rozkładu normalnego
interpretacja rozkładu normalnego
pokazuje, na ile dane wartości są prawdopodobne do otrzymania: wartości przy większej gęstości są bardziej prawdopodobne do wystąpienia, im dalej od środka rozkładu, tym mniej prawdopodobne
standaryzowany rozkład normalny
zamieniamy wszystkie wartości x na wartości standaryzowane z tak, aby średnia wynosiła 0, a odchylenie standardowe równało się 1, powierzchnia pod krzywą jest równa 1
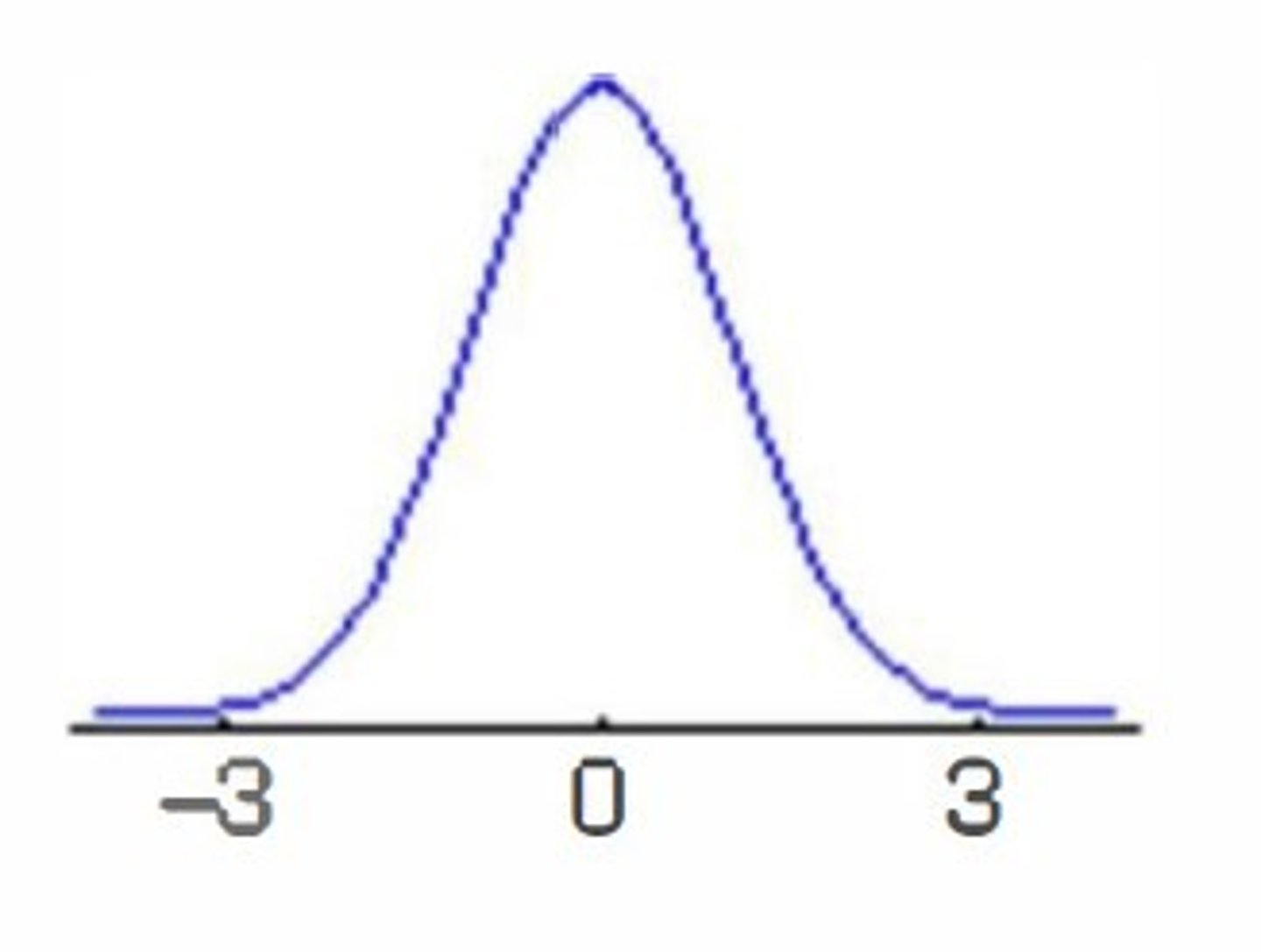
cel standaryzowania rozkładu normalnego
aby móc powiedzieć jaki procent obserwacji leży poniżej lub powyżej pewnego wyniku, jakie jest prawdopodobieństwo uzyskania wyniku z danego przedziału, można to odczytać z tabel dla wystandaryzowanego rozkładu normalnego
wyniki standaryzowane
przekształcone wyniki surowe na wyniki wyrażone w jednostkach odchylenia standardowego w celu porównania wyników (mierzonych różnymi narzędziami) lub sprawdzenia prawdopodobieństwa otrzymania danego wyniku
standaryzacja wyników
proste przekształcenie liniowe każdego wyniku x w z: wartość standaryzowana "z" danego wyniku = wynik surowy (x) minus średnia (M) dzielone przez odchylenie standardowe (SD)
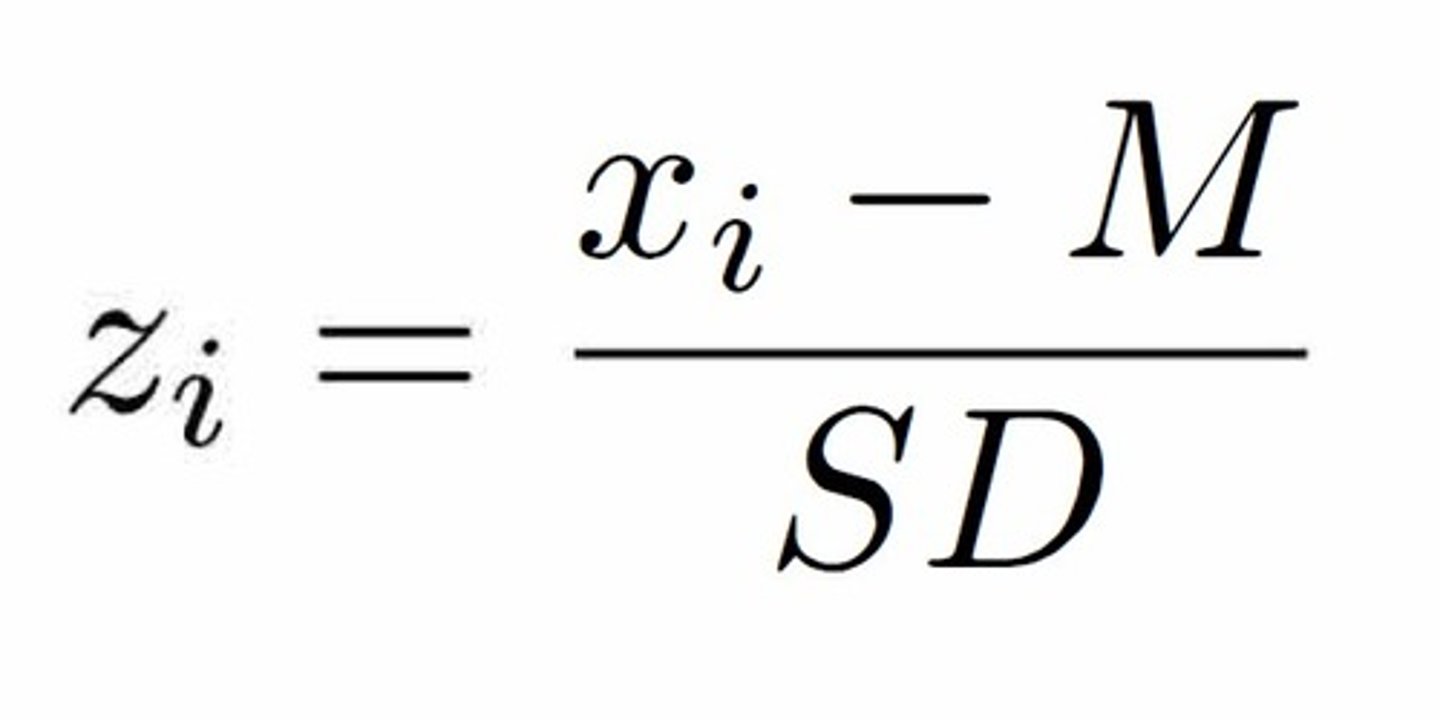
właściwości wyników standaryzowanych
średnia = 0, wariancja i odchylenie standardowe = 1, wyniki "z" dokładnie równe średniej = 0, wyniki "z" zbliżone do średniej są bliskie wartości 0, wartości "z" mniejsze od średniej są ujemne, większe od średniej są dodatnie
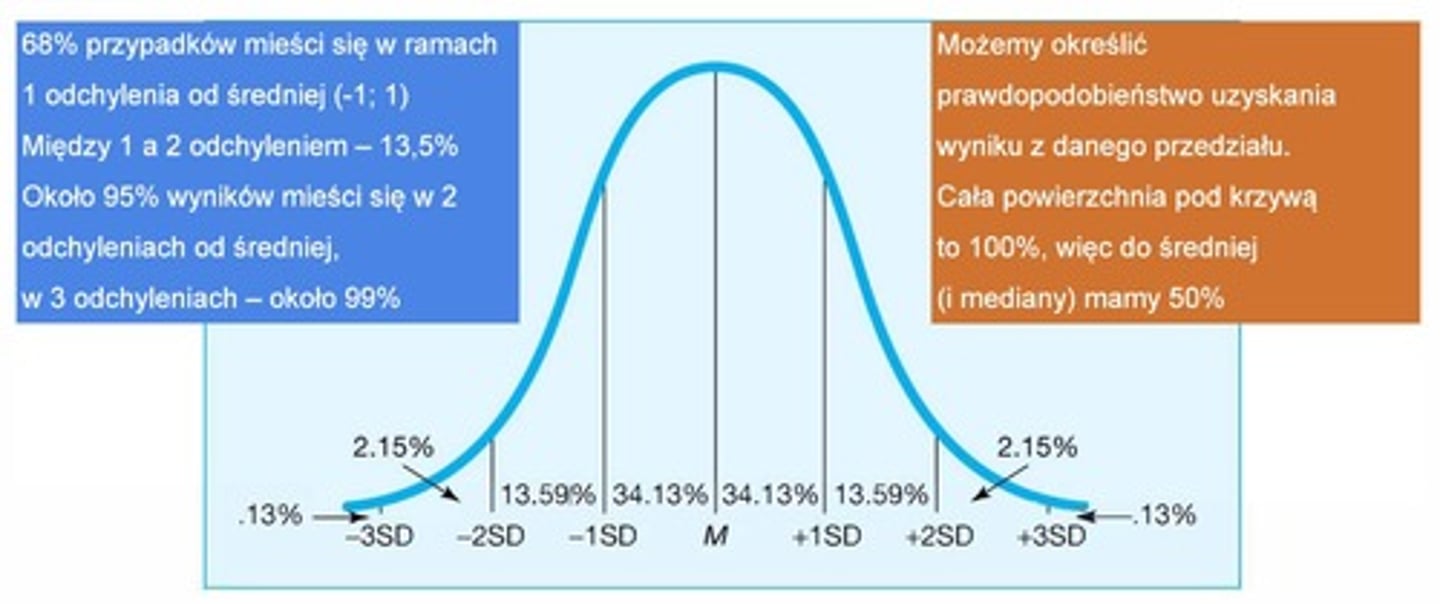
standaryzowany rozkład normalny jako rozkład prawdopodobieństwa
możemy określić prawdopodobieństwo uzyskania wyniku z danego przedziału, cała powierzchnia pod krzywą to 100%, więc do średniej (i mediany) jest 50%; 68% przypadków mieści się w ramach 1 odchylenia od średniej (-1; 1); między 1 a 2 odchyleniem - 13,5%; ok. 95% wyników mieści się w 2 odchyleniach od średniej, w 3 odchyleniach - ok 99%
tabele wartości z
korzystamy z tabel, aby znaleźć obszar pod krzywą normalną, możemy obliczyć, jaki procent obserwacji będzie mieścił się w przedziale między dowolnymi dwoma punktami na krzywej normalnej wyrażonymi w wartościach "z"
populacja
dowolnie określony zespół przedmiotów, osób, zdarzeń itp.
próba
dowolny podzbiór, podgrupa wybrana z populacji
statystyka opisowa
analiza danych w odniesieniu do próby np. statystyki rozkładu wyników; wstępny proces analizy danych
statystyka inferencyjna
oparta o reguły wnioskowania indukcyjnego - na podstawie uzyskanych danych wyciągamy ogólne wnioski, na podstawie próby wnioskujemy o populacji
statystyki w próbie
są estymatorami odpowiednich parametrów w populacji
stawiamy hipotezy
o różnicy między warunkami eksperymentalnymi; o związkach między zmiennymi
etapy testowania hipotez
stawiamy hipotezę badawczą, zbieramy dane, stawiamy hipotezę zerową, konstruujemy rozkład prawdopodobieństwa otrzymania danego wyniku przy założeniu, że hipoteza zerowa jest prawdziwa, porównujemy wynik uzyskany z rozkładem, znajdujemy prawdopodobieństwo uzyskania naszego wyniku, podejmujemy decyzję o odrzuceniu bądź nie odrzuceniu hipotezy zerowej
hipoteza badawcza (h1)
hipoteza stawiana przez badacza, najlepsze z możliwych wytłumaczeń obserwowanego zjawiska w przypadku, kiedy hipoteza zerowa jest fałszywa; w badaniach staramy się dostarczyć danych wspierających naszą hipotezę badawczą, alternatywną względem hipotezy zerowej, jednak z metodologicznego punktu widzenia nie jest możliwe, aby w pełni udowodnić jej prawdziwość - wystarczy, że pojawi się jeden przypadek zaprzeczający hipotezie i staje się ona fałszywa (odnosi się to również do teorii)
hipoteza niekierunkowa
nie twierdzi nic o kierunku zależności czy różnicy; trudniejsze do przyjęcia statystycznie - obszar dla odrzucenia hipotezy zerowej z dwóch stron rozkładu (testowana dwustronnie)
hipoteza kierunkowa
określa kierunek zależności czy różnicy; łatwiejsze do przyjęcia statystycznie; obszar dla odrzucenia hipotezy zerowej z jednej strony rozkładu (testowana jednostronnie)
hipotezy w badaniach
falsyfikujemy a nie udowadniamy ich prawdziwość; aby udowodnić hipotezę w badaniu empirycznym konieczne byłoby zbadanie całej populacji; badania robimy na próbach z populacji
wnioskowanie statystyczne
możemy wykorzystać testy statystyczne do oszacowania prawdopodobieństwa, że uzyskane w badaniu wyniki są przypadkowe; jeśli to prawdopodobieństwo jest małe, można wnioskować, że różnica (czy też związek) nie jest przypadkowy i rzeczywiście występuje w populacji
teoretyczny rozkład średnich z próby
losujemy z populacji możliwie wiele prób ze zwracaniem,liczymy dla każdej próby średnią, średnie te traktujemy jako dane i obliczamy statystyki rozkładu, średnia ze średnich z tych prób byłaby bliska rzeczywistej średniej w populacji, co więcej rozkład z tych prób jest bliski normalnemu
centralne twierdzenie graniczne
wraz ze wzrostem liczebności prób, niezależnie od kształtu rozkładu w populacji, rozkład z próby średnich zbliża się do normalnego ze średnią i wariancją
odrzucenie hipotezy zerowej
jeśli prawdopodobieństwo uzyskania takiego wyniku jest co najmniej p < 0,05; p < 0,01 (lepiej); p < 0,001 (najlepiej); często nazywane jako obszar odrzucenia, poziom istotności
prawdopodobieństwo 5% (p < 0,05)
prawdopodobieństwo, że wyniki są przypadkowe (wystarczające, żeby odrzucić h0)
poziom alfa
prawdopodobieństwo, że uzyskalibyśmy takie wyniki, przy założeniu, że h0 jest prawdziwa - nie jest to prawdopodobieństwo, że h0 jest prawdziwa
istotna statystycznie różnica
prawdopodobieństwo przypadkowego uzyskania tych wyników było tak małe, że więcej sensu miało stwierdzenie, że różnica jest istotna statystycznie; przyjmujemy hipotezę badawczą
test jednostronny
odrzucamy hipotezę zerową, jeśli nasza wartość jest zbyt wysoka (zbyt niska); obieramy sobie tylko jeden z krańców rozkładu do odrzucenia hipotezy zerowej
test dwustronny
pozwala na odrzucenie hipotezy zerowej, jeśli otrzymujemy wartość, która jest zbyt skrajna, niezależnie od znaku
p < 0,05
odrzucamy h0
p > 0,05
brak podstaw do odrzucenia h0
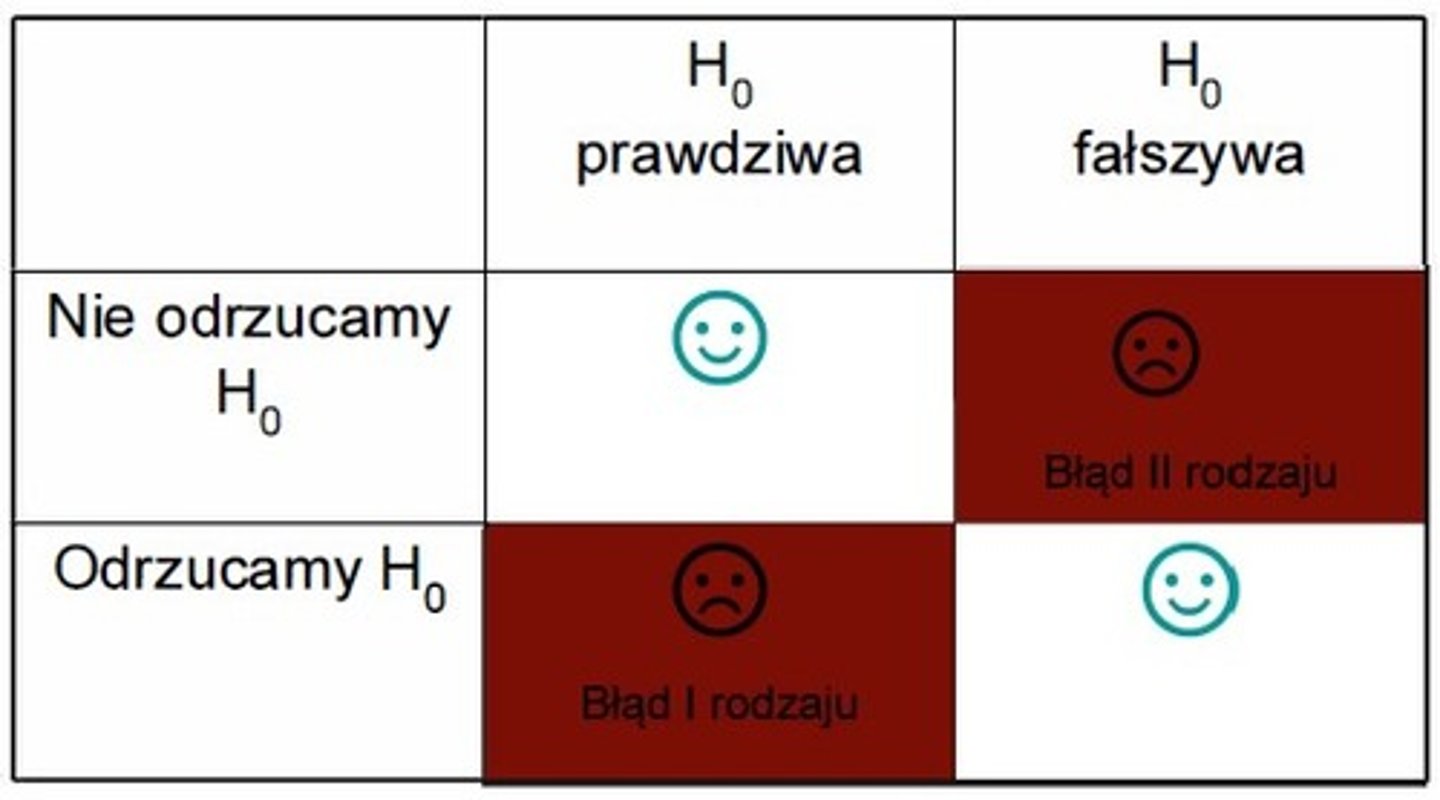
błąd I rodzaju - alfa
odrzucenie hipotezy zerowej, gdy jest prawdziwa, równy poziomowi istotności
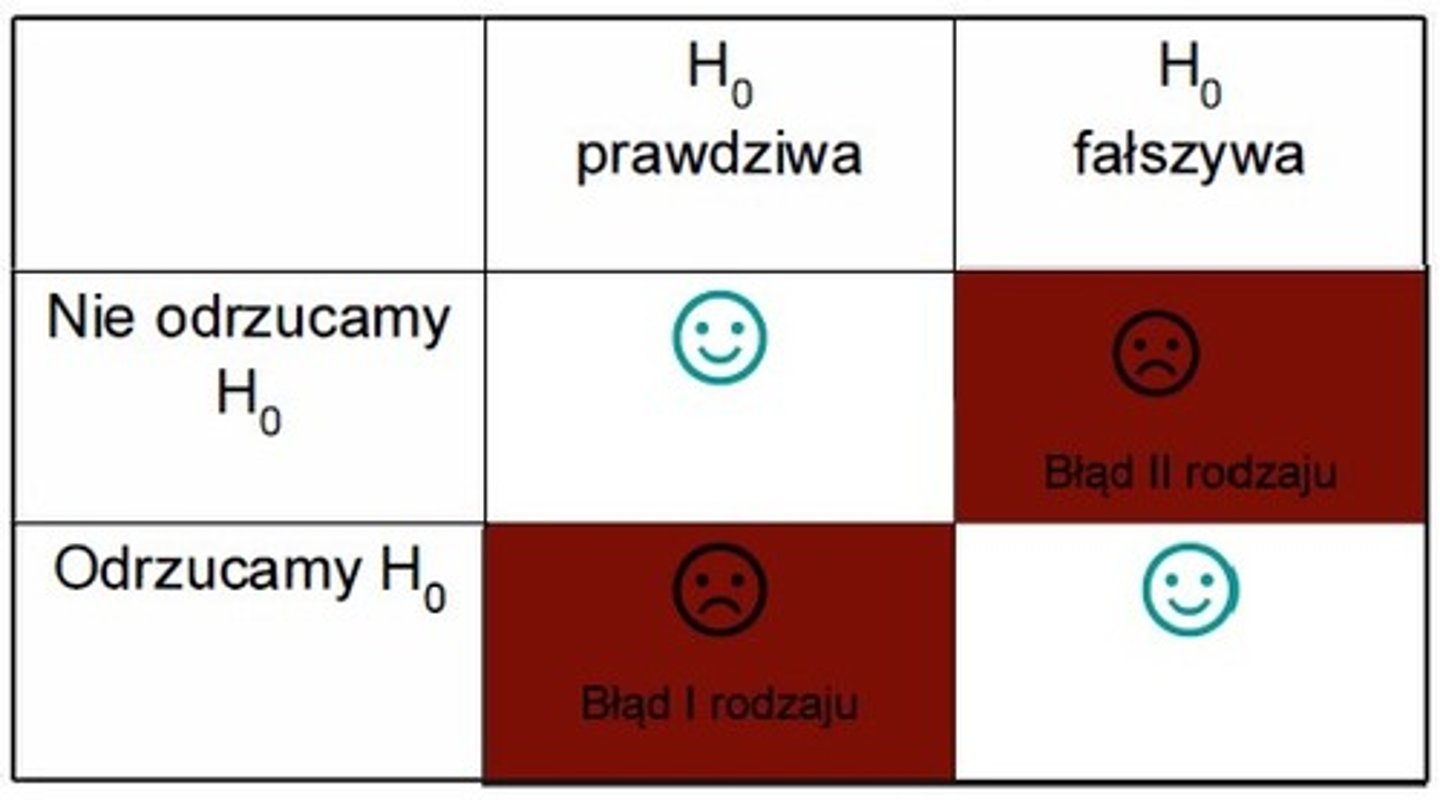
błąd II rodzaju - beta
nie odrzucenie hipotezy zerowej mimo, że jest fałszywa
rodzaje testów t
dla jednej próby, dla prób niezależnych, dla prób zależnych
założenia testu t
ilościowy poziom pomiaru (skala przedziałowa lub stosunkowa), normalność rozkładu zmiennej zależnej
wykorzystanie testu t
małe n< 30 (umownie), nie znamy odchylenia standardowego w populacji; do wyciągania wniosków statystycznych na podstawie wartości testów t posługujemy się teoretycznym rozkładem wartości t; rozkład t wykorzystujemy w podobny sposób jak rozkład z
test t dla jednej próby
pozwala porównać średnią w próbie ze średnią w populacji; sprawdzić istotność statystyczną tej różnicy
oszacowanie średniej w populacji
oszacowanie średniej jest zawsze oszacowaniem przedziałowym, a nie punktowym, powinniśmy więc oszacować granice przedziału, w jakim zmieści się średnia, wykorzystamy do tego błąd standardowy średniej
przedział ufności dla średniej
określa przedział wartości, w jakim z określonym prawdopodobieństwem (tradycyjnie przyjmuje się 95% przedział ufności) znajduje się rzeczywista średnia w populacji