Looks like no one added any tags here yet for you.
Functional and Non-functional requirements
-User enters address, gets 100 businesses back
- Can filter for types
- Gets reviews, contact info for business
- Owners can add/remove businesses
-low/moderate latency
- scalable
- available
- data privacy
BOE
100 million DAU, 200 million businesses, average of 5 searches a day
2000 QPS
DB Design and APIs
APIs
GET api/location/businesses
POST api/businesses
PUT api/businesses/id
DELETE api/businesses
DB can be relational. Key tables are business table and geospatial index
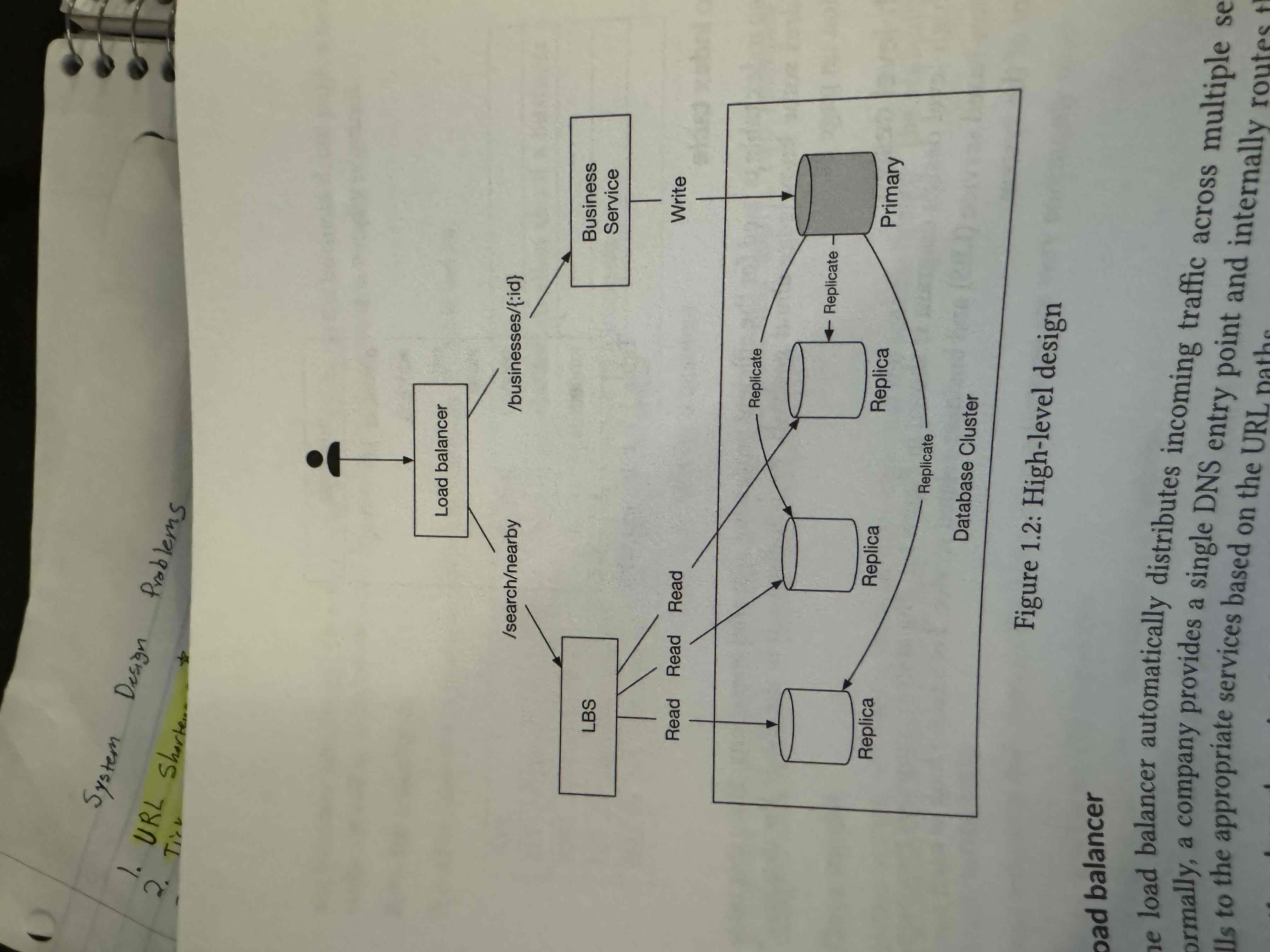
High Level Design Diagram
Location service finds nearby businesses for a given radius and location. Is read heavy with no write requests, high QPS, and stateless.
Business Service is for owners to create, update, and delete businesses. Also, for customers to view detailed business data.
Databases replicated because services are stateless.
Algorithms for nearby businesses
2D search- draw circle with pre defined radius, do a bunch of joins on lats and lons between certain values. Can only improve speed in one direction though. SOOO many values
Evenly Divided Grid- Divide grid into even sections. Not even in number of businesses tho
Geohash- Recursively divide map into smaller and smaller areas. Use 0s and 1s. Convert this to base32 and that is hash. Has 12 precisions, only levels 4-6 really used. Boundary issues by meridian/equator. If not enough businesses, remove end of hash .
QuadTree- Memory solution. Keep recursively dividing until only 100 businesses on node. that is now leaf node.
Explain all
Memory/Aspects of QuadTree
200 million businesses, each leaf node has 100 businesses, so 200 mil/100 = 2 million leaf nodes. Internal nodes are 1/3 the size of leaf nodes, so 670,000.
Data on leaf node has 16 bytes for top left coordinates and 16 for bottom right, plus 100 × 8 bytes for list of business ids. That is 832 bytes. Internal node has same 32 bytes for coordinates, plus 8 bytes for each child node so another 32. so 2 mil 832 bytes + 670,000 * 64 bytes if about 1.6 to 1.7 GB. Easily can fit on one server, but replicate to handle all the requests
Quadtree will take a little while to build with 200 million businesses, if we want to update/remove businesses we will need to rebuild. Maybe do Blue/Green deployment.
Geohash vs Quadtree
Geohash is easy to implement and use, easy to update businesses.
Quadtree is harder to implement bc tree has to build, supports fetching k-nearest businesses though. Can dynamically resize grid based on population density. Updating is more complicated (must rebuild tree, OR traverse to delete but this can get complicated with multi-threading).
Deep Dive
Scale the Database
Caching
Region and Availability Zones
Filter results by time or business type
Scale the database
Do we scale the business table or the geospatial index?
Business table has 200 million businesses with all their info. Shard this! Do it by business id.
Geospatial index needs to be replicated. The full dataset is not that big (similar to quad tree) so no need to shard. (this is the geohash option). Just make read replicas!
Cache
Should we cache location coordinates of user?? NO, not that accurate and people can move.
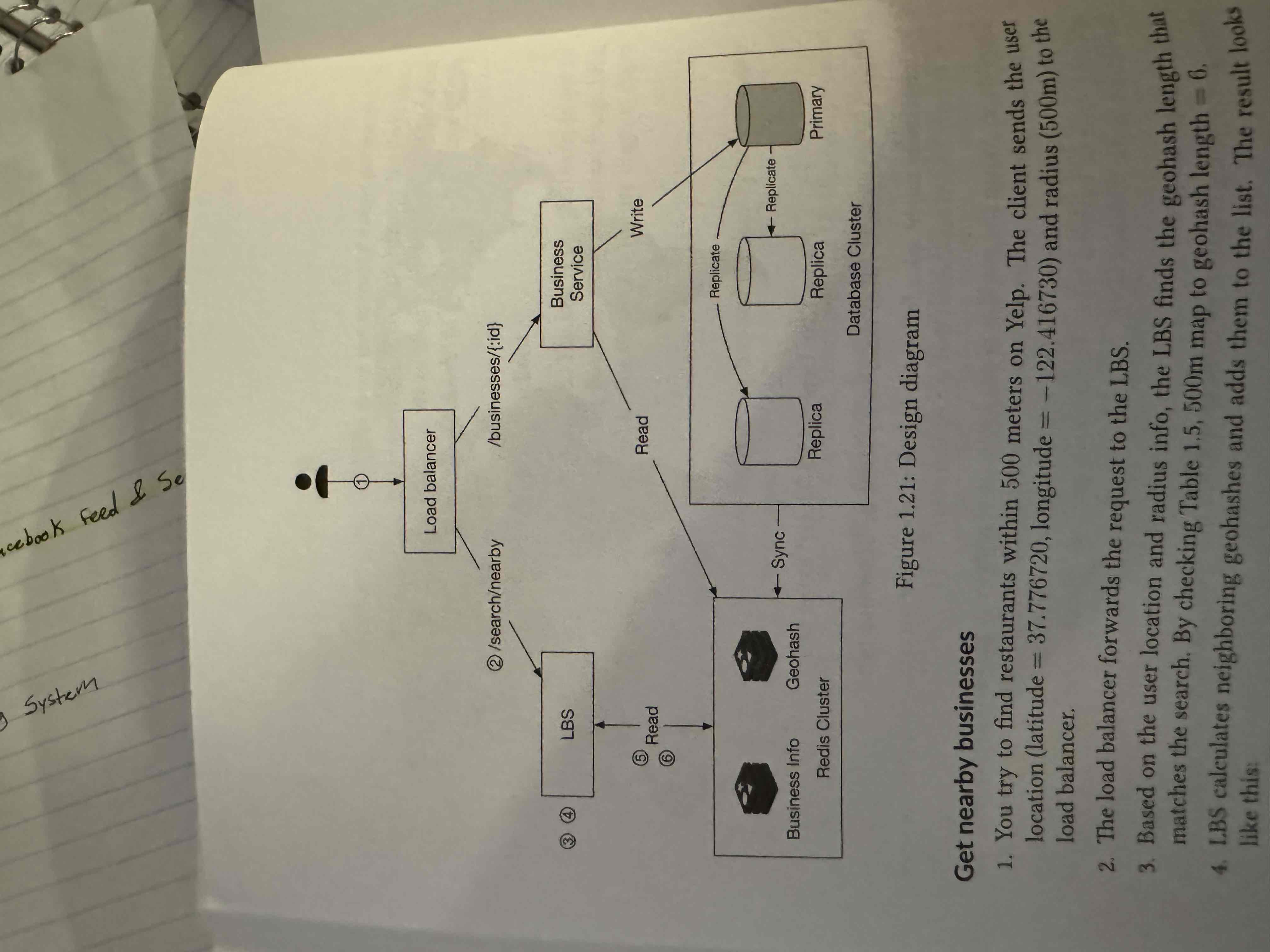
Instead, cache business ids for a given geohash! Use a Redis cache for key-value store. Storage- 8 bytes 200 million 3 precisions is about 5GB. Call this Geohash cache
Also, cache Business info (images, name, address) in Business Info cache.
Region and availability zones
Deploy LBS to multiple regions, makes us physcially closer to service, gives flexibility to spread traffic evenly across population, and different privacy laws met with storage of data locally.
Filtering??
When world divided into small grids, number of businesses returned from search result is relatively small. Acceptable to return business IDs first, hydrate business objects, then filter them.
Final Diagram
Google S2
In memory solution that uses a 1d index based on Hilbert curve. Two points close to each other on curve are close in 1D space.
Complicated library, widely used though.
Great for geofencing because it can cover arbitrary areas with varying levels. Allows us to define perimeters that surround areas of interest and to send notifications to users who are out of areas.