Computer Science - 1.1.1: CPU structure and function
1/38
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
39 Terms
Purpose of the CPU
Process (searching, sorting, calculating and decision making) data.
Interact with the other hardware
Execute instructions from the RAM
What is the fetch-decode-execute cycle? (brief overview)
The order in which data is processed in the CPU
Fetch: next instruction is fetched from the main memory
Decode: instruction is translated into opcode and operand (in the CIR)
Execute: the appropriate opcode is carried out on the operand
What's inside the CPU
Arithmetic Logic Unit: Make logical decisions. Carry out arithmetic operations.
Control Unit: Controls the signals that control the flow of data around the CPU and between components. Decodes instructions.
The registers: Super fast memory inside the CPU
Each register is specialised to its function within the FDE cycle.
What are system buses
Communication channels
What are the different system buses
Address bus, data bus, control bus
Data bus
Bidirectional.
Carries the data from one place to another.
Move data and instructions between the CPU and the main memory (and I/O devices)
Address Bus
carries the memory locations of the data/instructions that need to be fetched or the memory address where the data will be stored.
unidirectional - from the CPU to RAM and other devices
Control Bus
transmits control signals from the control unit to other parts of the processor.
Bi-directional flow
Different registers
program counter (PC)
memory address register (MAR)
memory data register (MDR)
accumulator (ACC)
Current Instruction register (CIR)
Program counter
stores the address of the next instruction to be accessed. The value is sent to the MAR and then the value increments.
Memory Address Register (MAR)
Contains the address of the instruction to be accessed from memory. The address of the instruction is sent from the PC.
Memory Data Register (MDR)
Contains the instruction/data which has been accessed from the memory. If an instruction, it's sent to the CIR.
CIR
current instruction register. Holds the instruction while it is being decoded / executed. used so the instruction is still there in case the MDR is needed in the execute stage.
Accumulator
Temporary storage for data being processed, or during calculations (holds result from ALU)
Stores the input or output in the processor, used as a buffer
Stores results of calculations in the ALU.
Fetch Stage (in detail)
The address on the PC is copies onto the MAR.
PC increments.
Data in the MAR is passed onto the address bus.
Read signal is sent onto the control bus.
RAM copies data from the location specified by the address bus onto the data bus.
Data on the data bus passed into the MDR.
Data copied from the MDR onto the CIR.
Decode Stage (in detail)
Contents in the CIR are split into two parts...
Operation code is first part of
instruction...
...operation code is decoded (so that
CU knows what to do)
Rest of the content is address of data
to be used with the operation / actual
data to be used (if immediate operand
is used)...
...operand is copied to MAR if it is an
address
...operand is copied to MDR if it is data
Execute stage (in detail)
Decoded instruction is executed:
- if there is data to be loaded, the address is sent to the MAR, and put in the accumulator.
- if data is to be stored, the value from the accumulator is sent to the MDR, across the data bus to be stored in the memory space of the address in MAR (recieved from the decoded instruction in the CIR)
The CIR sends data to the MAR for the address of the new data to be added/subtracted to the value in the ACC.
If the instruction is branch, the comparison takes place in the ALU and the PC changes it's value accordingly.
Instruction sets
A list of instructions that the CU understands and knows what to do with.
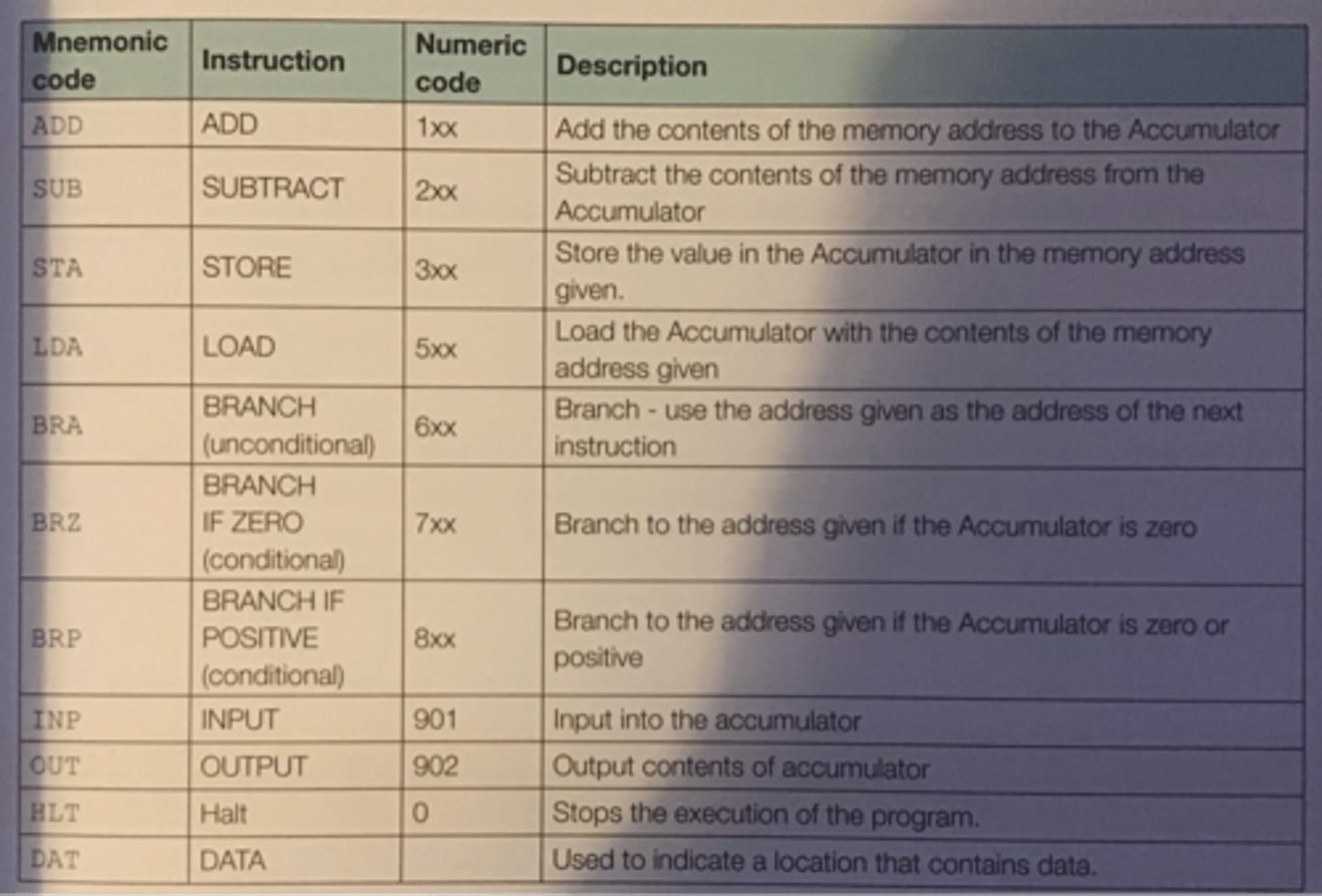
Assembly language main commands
Factors Affecting the Performance of the CPU
Clock Speed
Primary and Secondary Storage
Cache
Cores
Pipelining
Clock speed
The amount of FDE cycles that happen a second is determined by the CPU's clock chip.
faster the clock speed the more instructions can be executed per second.
The chip uses a vibrating crystal that maintains a constant rate.
Clock speed is measured in hertz (amount of cycles per second)
Overclocking
Increasing the clock speed of a CPU - more instructions processed quicker.
However, the CPU's get hot the more they work so overclocking is dangerous without proper management (fan). FIRE
Secondary Storage vs Primary Storage (how it affects the CPU performance)
Data held in primary storage (cache and RAM) will be accessed faster because they are physically closer. Secondary storage is further away and connected by cables so it is much slower to access the data. Hence, the CPU will work more efficiently if the data is held in primary storage.
Cache
Additional memory space for frequently used data and instructions and continuing instructions.
Cache has similar read speeds to the CPU, both of which are much faster than RAM, so it's more efficient for the CPU to work with cache.
Larger the cache, more instructions can be held and accessed faster. If too many are stored there, it could take just as long because it takes time to search through all that data.
Cores
single processors that can carry out their very own fetch-decode-execute cycle, allowing instructions to be processed concurrently.
more data processed in the same time period.
Parallel processing: 2 or more processors handle separate parts of an overall task, completing two instructions of one program at the same time.
Multitasking: Each core can process two different program's instructions at the same time.
Limitations of Cores
Might not necessarily work faster because some programs only allow one instruction to be processed at any one time.
Pipelining
Concurrent processing of multiple instructions.
One instruction can be fetched while the previous is being decoded...
And the one before is being executed.
Increases speed of execution because latency is reduced, the CPU is never idle, and so it's much more efficient.
Pipelining limitations
It only works if the CPU knows what instruction needs to be fetched next. SO in case of branching, pipeline is flushed.
Where is pipelining used in a computer system
Instruction processing - some
processors allow parts of instructions
to be processed without waiting to
complete the whole instruction cycle
Pipes to pass data between programs
from programs to peripherals/to
programs from peripherals
Graphics pipelines separate
processor renders graphics from data
supplied by other processes, parts
(vertices) of the image are pipelined at
the same time as custom software
(shaders) that render the display.
Von Neumann Architecture description
All data and instructions sent together over the data bus, stored together in RAM.
Single ALU, Single CU, special registers in the CPU
Where is Von Neumann architecture used?
General purpose computers
Harvard Architecture description
Instructions and data sent separately over different buses and stored in separate parts within the memory.
Where is Harvard Architecture used
specialist computers and embedded systems because there is a fixed instruction size, there's no need for data to be shared between data and instructions and removes the need for secondary storage.
Von Neumann advantages
Only one data bus so less complex for the control unit to manage
Cheaper to develop as the control unit is easier to design
Memory can be used more efficiently as all memory can be used for either instructions or data.
Von Neumann disadvantages
This architecture can only process one instruction / item of data at a time and so cannot carry out parallel processing.
Harvard advantages
Quicker execution as data and instructions can be fetched in parallel.
Harvard disadvantages
Wasted memory is more likely
More expensive to manufacture and difficult to design and develop
Contemporary architecture
Combination of Harvard and Von Neumann Architecture.
Two separate areas for memory/cache - one for instructions, one for data and data can be accessed concurrently.
Different sets of buses - one for instructions and one for data. Data can be accessed concurrently.
Array processor architecture
Single Instruction Multiple Data (SIMD)
Allows same instruction to operate simultaneously on multiple data locations / many ALU's