Machine Learning - MIDTERMS
1/90
Earn XP
Description and Tags
4 TOPICS IN ONE
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
91 Terms
Numerical Data
Integers or floating-point values that behave like numbers
They are additive, countable, ordered, and so on
Examples of Numerical Data
Examples are:
Temperature
Weight
The number of deer wintering in a nature preserve
Feature Vector
Floating-point values comprising one example
Feature Engineering
The best way to represent raw dataset values as trainable values in the feature vector
Vital part of machine learning
Most common techniques are Normalization and Binning
Normalization
Converting numerical values into a standard range
Converts floating-point numbers to a constrained range that improves model training
Binning (bucketing)
Converting numverical values into bucket of ranges
Also called bucketing is a feature engineering technique that groups different numberical subranges into bins or buckets
It turns numerical data into categorical data
First Steps in creating feature vectors
Visualize your data in plots or graphs
Get Statistics about your data
Outlier
A value distant from most other values in a feature or label
It often cause problems in model training, finding it is important
Finding Outliers
When the delta between the 0th and 25th percentiles differs significantly from the delta between 75th and 100th percentiles
Categories of Outliers
Categories:
Due to a mistake
A legitimate data point
Importing the dataset in pandas
training_df = pd.read_csv()
Getting Basic Statistics in Pands
.describe()
Goal of Normalization
To transform features to be on a similar scale
Normalization Benefits
Benefits:
Helps models converge more quickly during training
Helps models infer better predictions
Helps avoid the NaN trap when feature values are very high
Helps the model learn appropriate weights for each feature
NaN
Not a number
NaN Trap
When a value in model exceeds the floating0point precision limit, the system sets the value to NaN instead of a number.
When one number in the model becomes a NaN, other numbers in the model also eventually becomes a NaN
Three Popular Normalization Methods
3 Methods:
Linear Scaling
Z-score scaling
Log Scaling
Linear Scaling
Converting floating-point values from their natural range into a standard-range usually 0 to 1 or -1 to +1
When the feature is uniformly distributed across a fixed range
Linear Scaling Conditions
The lower and upper bounds of your data don’t change much over time
The feature contains few or no outliers, and those outliers aren’t extreme
The feature is approximately uniformly distributed across its range. That is, a histogram would show roughly bars for most values
Z-Score
The number of standard deviations a value is from the mean
Z-Score Scaling
Storing that feature’s z-score in the feature vector
When the feature distribution does not contain extreme outliers
Log Scaling
Computes the logarithm of the raw value. In theory, the logarithm could be any base; in practice, log scaling usually calculates the natural logarithm (ln)
When the feature conforms to the power law
Power Law Distribution
Low values of X have very high values of Y
As values of X increase, the values of Y quickly decrease. Consequently, high values of X have very low values of Y
Clipping
A normalization technique to minimize the influence of extreme outliers
Usually caps (reduces) the value of outliers to a specific maximum value
Binning Conditions
It is a good alternative to scaling or clipping when either of the following conditions are met:
The overall linear relationship between the feature and the label is weak or nonexistent
When the feature values are clustered
Quantile Bucketing
Creates bucketing boundaries such that the number of examples in each bucket is exactly or nearly equal
It mostly hides the outliers
Scrubbing
The process of cleaning and fixing data by removing or correcting problematic examples like omitted values, duplicates, out-of-range values, and bad labels
Omitted Values
This occur when data is missing or not recorded, such as when a census taker fails to record a resident’s age
Duplicate Examples
When the same data appears multiple times in a dataset, such as when a server uploads the same logs twice
Out-of-range feature values
These are data points that fall outside the expected or valid range for that feature, often due to human error or equipment malfunctions, such as when a human accidentally types an extra digit
Bad Labels
this is when data is incorrectly labeled or categorized, such as when a human evaluator mislables a picture of an oak tree as a maple
Qualities of Good Numerical Features
Clearly named
Checked or Tested before Training
Sensible
Clearly Named
Each feature should have a clear, sensible, and obvious meaning to any human on the project
Checked or Tested before Training
Features should be checked for appropriate values and outliers
Sensible
Avoid magic values (purposeful discontinuities in continuous features)
Uses separate Boolean indicators
Polynomial Transform
A technique where a new, synthetic feature is created by raising an existing numerical feature to a power (e.g., squaring, cubing). For example, creating x₂ = x₁².
Use of Polynomial Transform
They allow linear models to capture non-linear relationships in the data. This is useful when the relationship between features and the target variable isn't linear, or when data points from different classes cannot be separated by a straight line but might be separable by a curve.
Categorical data
This data has a specific set of possible values such as:
Different Species
Names of streets in a particular city
Whether email is spam
Colors that house exteriors are paintet
Encoding
This means converting categorical or other data to numerical vectors that a model can train on
Dimension
Synonym for the number of elements in a feature vector
Vocabulary
When a categorical feature has a low number of possible categories, you can encode it as _____
Index Numbers
ML models can only manipulate floating-point numbers, therefore, you must convert each string to a unique ____ _____
One-hot Encoding
The next step in building a vocabulary is to convert each index number to its _____
Each category is represented by a vector of N elements, where N is the number of categories
Exactly one of the elements in a one-hot vector has the value 1.0; all the remaining elements have the value of 0.0
Multi-hot encoding
Multiple values can be 1.0
Sparse Representation
A feature whose values are predominately zero (or empty)
This means storing the position of the 1.0 in a sparse vector
Consumes far less memory than the eight-element one0hot vector
Out-of-vocabulary Category (OOV)
Where you store the outlier categories into a single outlier bucket
The system learns a single weight for that outlier bucket
Embeddings
This substantially reduce the number of dimensions, which benefits models by making the model train faster and infer predictions more quickly
Feature Hashing
Less common way to reduce the number of dimension
Used when the number of categorical feature values is very large
Human Raters
This is the gold label of rating data, more desirable than machine-labeled data due to better data quality
There is still human errors, bias and malice
Inter-rater agreement
Any two human beings may label the same example differently, this is the difference between the raters’ decision
Machine Raters
Categories are automatically determined by one or more classification models
Often referred as silver labels
High dimensionality
Feature vectors having a large number of eelements
This increases training costs and making training more difficult
Feature crosses
Created by crossing two or more categorical or bucketed features of the dataset
Allow linear models to handle nonlinearities
Polynomial Transforms vs Feature Crosses
The first one combines numerical data while the latter combines categorical data
Types of Data
Numerical Data
Categorical Data
Human Language
Multimedia
Outputs from other ML systems
Embedding vectors
Reliability of Data
Refers to the degree to which you can trust your data
A model trained on this dataset is more likely to yield useful predictions
Measuring reliability
How common are label errors?
Are your features noisy?
Is data properly filtered for your problem?
Unreliable Data Causes
Omitted Values
Duplicate Examples
Bad feature values
Bad labels
Bad Sections of Data
Imputation
It is the process of generating well-reasoned data, not random or deceptive data.
Good _____ can improve your model; but bad ______ can hurt your data
Direct Labels
Labels identical to the prediction your model is trying to make
The prediction your model is trying to make is exactly as a column in your dataset
Better than proxy label
Proxy Labels
Labels that are similar—but not identical—to the prediction your model is trying to make
A compromise—an imperfect approximation of a direct label
Human-generated data
One or more humans examine some info and provide value, usually for the label
Automatically-generated Data
Software determines the value of a Data
Imbalanced Datasets
One label is more common than the other label
The predominant label is called the majority class while the less common is called the minority class
Don’t contain enough minority class examples to train a model properly
Mild Degree of Imbalance
20-40% of the dataset belonging to the minority class
Moderate Degree of Imbalance
1-20% of the dataset belonging to the minority class
Extreme Degree of Imbalance
<1%of the dataset belonging to the minority class
Downsampling
Means training on a disproportionately low subset of the majority class examples
Extract random examples from the dominant class
Upweighting
Means adding an example weight to the downsampled class equal to the factor by which you downsampled
Add weight to the downsampled examples
Rebalancing Ratio
This answers the question: How much should you downsample and upweight to rebalance your dataset
You would do this just as you would experiment with other hyperparameters
Testing a model
Doing this on different examples is stronger proof of your model’s fitness than testing on the same set of examples
Approach to Dividing the Dataset
Three Subsets:
Training Set
Validation Set
Test Set
Validation Set
This set performs the initial testing on the model as it is being trained
Used to evaluate results from the training se
Test Set
This set is used to double-check the model
Problems with test Sets
Many of the examples in the test set are duplicates of examples in the training set
Criteria of a Good Test Set
Large Enough to yield statistically significant testing results
Representative of the dataset as a whole
Representative of the real-world data that the model will encounter
Zero examples duplicated in the training set
What to do with Too much data
Sample the data when there is plenty
Generalization
Broadening the knowledge of the model to make it useful to real-world data
The opposite of overfitting
A model that makes good predictions on new data
Overfitting
Means creating a model that matches (memorizes) the training set so closely that the model fails to make correct predictions on new data
Performs well in the lab but is worthless in the real world
Underfit model
Doesn’t even make good predictions on the training data
Is like a product that doesn’t even do well in the lab
Detecting Overfiting
These can help you detect it:
Loss curves
Generalization curves
The loss on the training data decreases over time but the loss on validation data is increasing
Overfitting Causes
The training set doesn’t adequately represent real life data (or the validation set or test set)
The model is too complex
Generalization conditions
Examples must be independently and identically distributed, the examples can’t influence each other
The dataset is stationary, meaning the dataset doesn’t change significantly over time
The dataset partitions have the same distribution, the examples in the training set are statistically similar to the examples in the validation set, test set, and real-world data
Occam’s Razor
The preference for simplicity in philosophy
This suggests that simple models generalizes better than the complex model
Regularization
One approach to keeping a model simple
Forcing the model to become simpler during training
L2 regularization
Large weights can have a huge impact
Weights close to zero doesn’t have an impact
This encourages weights toward 0, but never pushes weights all the way to zero which means it can never remove features from the model
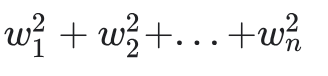
Regularization Rate (lambda)
Model developers tune the overall impact of complexity on model training by multiplying its value by this scallar
High Regularization Rate:
Strengthens the influence of regularization, thereby reducing the chances of overfitting
Tends to produce a histogram of model weights having the following characteristics:
a normal distribution
a mean weight of 0
Low Regularization Rate
Lowers the influence of regularization, thereby increasing the chances of overfitting
Tends to produce a histogram of model weights with a flat distribution
Removing Regularization
Setting the regularization rate to zero
Training focuses exclusively on minimizing loss, which poses the highest possible overfitting risk
Early stopping
A regularization method that doesn’t involve a calculation of complexity
Ending training before the model fully converges
It usually increases training loss, it can decrease test loss