Biology D1.2 Protein synthesis
1/18
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
19 Terms
Transcription as the synthesis of RNA using a DNA template
Transcription is the process by which a section of DNA is used as a template to synthesize a molecule of messenger RNA (mRNA), and it is carried out by the enzyme RNA polymerase. This process occurs in the nucleus of eukaryotic cells and in the cytoplasm of prokaryotes, since DNA is located in the nucleus and cannot leave. Transcription begins when RNA polymerase binds to a promoter region at the start of a gene and separates the two strands of DNA by breaking their hydrogen bonds. Only the template strand is used to build the RNA molecule; the other strand has the same sequence as the RNA (except RNA contains uracil instead of thymine). As RNA polymerase moves along the DNA, it pairs free RNA nucleotides with their complementary DNA bases on the template strand through hydrogen bonding. It then links these RNA nucleotides together by forming covalent bonds between the sugar of one nucleotide and the phosphate of the next, building a continuous strand of RNA. Once the gene has been fully transcribed, the mRNA strand detaches, the DNA strands re-form their hydrogen bonds and rewind into a double helix, and the RNA polymerase detaches from the DNA. The completed mRNA molecule exits the nucleus through nuclear pores and enters the cytoplasm, where it carries the genetic instructions to ribosomes for translation into a protein.
Role of hydrogen bonding and complementary base pairing in transcription
During transcription, cytosine (C) pairs with guanine (G) and adenine (A) on the DNA template strand pairs with uracil (U). Temporary hydrogen bonds form between the bases on the DNA template strand and the incoming RNA nucleotides, guiding the correct sequence of the RNA strand. RNA polymerase then forms covalent bonds between the RNA nucleotides to create a single-stranded mRNA molecule.
Stability of DNA templates
DNA is a highly stable molecule due to the strong covalent phosphodiester bonds between its sugar and phosphate groups, which form a sturdy backbone, and the hydrogen bonds between complementary bases in the double helix. This structural stability allows DNA to act as a reliable template for transcription without its base sequence changing. Especially in somatic cells such as neurons or muscle cells that do not divide preserving the genetic code over the cell’s lifetime is very important. This stability is essential for maintaining continuous and accurate gene expression, ensuring the cell can produce the proteins it needs to function properly.
Transcription as a process required for the expression of genes
Gene expression is the process by which the information stored in DNA is used to produce proteins. During transcription, a specific gene is "switched on" and used to produce an RNA copy of its base sequence, which can then be translated into a protein. However, not all genes in a cell are expressed at the same time. Cells only express the genes necessary for their specialized functions, meaning most genes remain "switched off." For example, while all cells contain the complete genome, only certain genes are active in muscle cells, nerve cells, or insulin-producing cells. Transcription allows the cell to regulate gene expression by determining which genes are active at any moment, responding to developmental cues or external signals like hormones.
Translation as the synthesis of polypeptides from mRNA
Translation is the process by which the base sequence of messenger RNA (mRNA) is used to synthesize a polypeptide (a chain of amino acids that folds into a functional protein). This stage of gene expression occurs in the cytoplasm at the ribosomes, which can either float freely or be attached to the rough endoplasmic reticulum. Each group of three bases on the mRNA, called a codon, codes for one specific amino acid. The sequence of codons along the mRNA determines the precise order in which amino acids are added to the growing polypeptide chain. The mRNA itself is a complementary copy of a gene transcribed from DNA, and typically contains the information to produce a single polypeptide.
Roles of mRNA, ribosomes and tRNA in translation
mRNA (messenger RNA) carries the genetic code from DNA in the nucleus to the ribosome in the cytoplasm. It is a single-stranded molecule made during transcription. The sequence of bases in mRNA is divided into codons (triplets), each coding for one amino acid.
Ribosomes has two subunits: a small subunit and a large subunit. The mRNA binds to the small subunit. The large subunit has three binding sites for tRNA, but only two are occupied at the same time during translation. The ribosome moves along the mRNA in the 5’ to 3’ direction, reading codons one by one. It catalyses the formation of peptide bonds between amino acids using a catalytic site on the large subunit. The ribosome is made of rRNA and proteins and acts like a biological machine that ensures everything is correctly aligned.
tRNA (transfer RNA) with an anticodon (a triplet of bases that is complementary to the codon on mRNA) and an attachment site for a specific amino acid. Each tRNA is specific to one amino acid, and the correct amino acid is attached in the cytoplasm by a specific enzyme using ATP. tRNA brings the correct amino acid to the ribosome by base pairing its anticodon with the matching codon on mRNA.
Complementary base pairing between tRNA and mRNA
During translation, complementary base pairing between tRNA and mRNA ensures that the correct amino acids are added to a growing polypeptide chain. The mRNA sequence is read in sets of three bases called codons, each of which codes for a specific amino acid. Each tRNA molecule has a region known as an anticodon, which is a set of three bases that is complementary to a specific codon on the mRNA. This allows the tRNA to bind temporarily to the mRNA through hydrogen bonding. Attached to the other end of the tRNA is the corresponding amino acid, which is then added to the polypeptide chain.
Features of the genetic code
The genetic code is based on a triplet system, 3 RNA bases code for one specific amino acid.
Degeneracy: With four different RNA bases, this allows for 64 possible codon combinations (4³), which is more than enough to encode the 20 amino acids found in proteins. This excess results in degeneracy of the genetic code: most amino acids are specified by more than one codon. For example, leucine is coded by six different codons, which helps protect against the effects of mutations.
Universality: the universality of the genetic code: with very few exceptions, all organisms use the same codons to represent the same amino acids. This strongly supports the idea of a common origin of life and enables practical applications such as genetic engineering, where genes from one organism can be inserted into another to produce useful proteins.
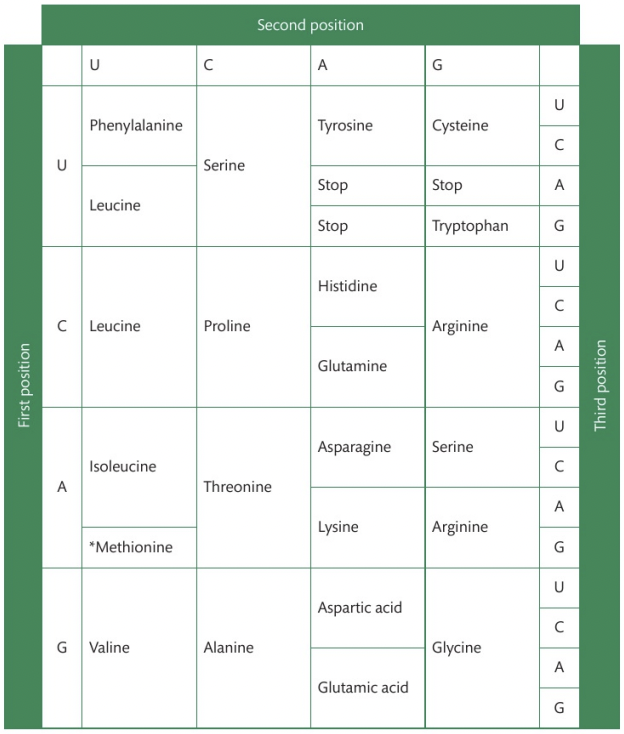
Using the genetic code expressed as a table of mRNA codons
To deduce the sequence of amino acids coded by an mRNA strand using the genetic code, follow these clear steps:
Transcribe DNA to mRNA: If you are given a DNA sequence, first transcribe it into its complementary mRNA sequence (A-U, C-G)
Break the mRNA into codons: The mRNA sequence is read in triplets of bases called codons.
Use the codon table: Refer to the mRNA codon chart, which shows which amino acid corresponds to each codon. Start by looking at the first base in the codon, then the second, and finally the third. Locate the appropriate amino acid in the chart.
Construct the amino acid sequence: Once you’ve decoded all the codons, write out the amino acids in sequence.
Stepwise movement of the ribosome along mRNA and linkage of amino acids by peptide bonding to the growing polypeptide chain
The elongation of a polypeptide chain during translation is a repetitive process in which amino acids are added to the growing polypeptide. Initially, a tRNA molecule, carrying an amino acid, binds to the A site of the ribosome, where its anticodon is complementary to the mRNA codon. This allows the correct amino acid to be added to the polypeptide chain. The ribosome, which consists of two subunits, catalyzes the formation of a peptide bond between the amino acid at the A site and the growing polypeptide chain held by the tRNA in the P site. This process is facilitated by ribosomal RNA (rRNA) in the large subunit of the ribosome. After the peptide bond is formed, the ribosome moves three bases along the mRNA, shifting the tRNA in the P site to the E site, where it exits the ribosome. Meanwhile, the tRNA with the growing polypeptide moves from the A site to the P site, leaving the A site vacant for the next tRNA. This cycle repeats, with the ribosome continuing to move along the mRNA, one codon at a time, adding amino acids to the chain. As this process continues, the polypeptide chain elongates until a stop codon is reached, signaling the end of translation.
Mutations that change protein structure
Mutations, even as small as a point mutation, can significantly alter protein structure. A point mutation involves a change in a single nucleotide base in the DNA sequence. This small alteration can lead to the substitution of one amino acid for another in the resulting protein.
An example of this is sickle cell disease, which is caused by a point mutation in the gene for hemoglobin. This substitution results in a hydrophobic patch on the hemoglobin protein, causing the molecules to stick together and form long chains. These chains distort the red blood cells into a sickle shape, which reduces their ability to carry oxygen and causes blockages in small blood vessels.
Directionality of transcription and translation
The directionality of both transcription and translation refers to the specific 5' to 3' orientation in which these processes occur.
In transcription, RNA polymerase synthesizes the RNA strand in a 5' to 3' direction by adding RNA nucleotides to the 3' end of the growing mRNA molecule. This directionality ensures that the RNA strand is synthesized correctly, as RNA polymerase only adds nucleotides in this direction, requiring a free 3'-OH group for the process.
In translation, the ribosome reads the mRNA codons in the 5' to 3' direction, assembling the corresponding amino acids in the correct order to form a polypeptide chain. This ensures that the mRNA is read in the correct orientation, producing a functional protein.
Initiation of transcription at the promoter
Consider transcription factors that bind to the promoter as an example. However, students are not required to name the transcription factors.
The initiation of transcription begins at the promoter region, a specific sequence of DNA located just before the gene. In prokaryotes, RNA polymerase directly binds to this region, initiating transcription. In eukaryotes, however, transcription factors first bind to the promoter or nearby regions, enabling RNA polymerase to attach and begin transcription. These transcription factors can either promote or inhibit transcription, and their activity can be influenced by other signals, such as hormones. Once RNA polymerase is properly positioned, it unwinds the DNA and begins synthesizing RNA in the 5' to 3' direction. The promoter does not code for proteins but plays a crucial role in regulating gene expression by controlling the binding of RNA polymerase and ensuring transcription occurs at the correct time and in the right cells.
Non-coding sequences in DNA do not code for polypeptides
Limit examples to regulators of gene expression, introns, telomeres and genes for rRNAs and tRNAs in eukaryotes.
Non-coding sequences in DNA do not directly code for polypeptides but play vital roles in the cell's functioning. These non-coding regions include regulators of gene expression, introns, telomeres, and genes for rRNAs and tRNAs.
Regulator sequences, such as promoters, enhancers, and silencers, control the transcription of genes by influencing the binding of transcription factors.
Introns are non-coding sequences within genes that are removed from mRNA during processing, allowing the gene to be expressed correctly.
Telomeres, located at the ends of chromosomes, protect them from damage and prevent loss of genetic information during cell division.
Additionally, genes for tRNA and rRNA are involved in protein synthesis but do not translate into proteins themselves. These non-coding regions are essential for regulating gene activity, maintaining chromosomal integrity, and supporting cellular processes.
Post-transcriptional modification in eukaryotic cells
Include removal of introns and splicing together of exons to form mature mRNA and also the addition of 5' caps and 3' polyA tails to stabilize mRNA transcripts.
In eukaryotic cells, post-transcriptional modification is essential for producing mature mRNA that can be translated into a functional protein. After transcription, the initial RNA product—called pre-mRNA—undergoes several modifications before leaving the nucleus.
First, a modified guanine nucleotide, known as the 5' cap, is added to the 5' end of the transcript. This cap, which contains three phosphate groups and a methyl group, protects the mRNA from degradation by exonucleases and helps initiate translation.
Similarly, a poly-A tail consisting of 100–250 adenine nucleotides is added to the 3' end. This tail also increases mRNA stability and assists in export from the nucleus.
In addition to these modifications, the non-coding introns—intervening sequences that do not contribute to the protein product—are removed in a process called splicing. This is carried out by large complexes called spliceosomes, which excise the introns and join the exons together to form a continuous coding sequence.
Together, the addition of the 5' cap, poly-A tail, and the splicing of exons ensure that the resulting mature mRNA is stable, protected, and ready for translation in the cytoplasm.
Alternative splicing of exons to produce variants of a protein from a single gene
Alternative splicing is a process that occurs during the post-transcriptional modification of pre-mRNA in eukaryotic cells. Splicing does not always occur in the same way—different combinations of exons can be joined together to produce different mature mRNA transcripts from the same gene. As a result, a single gene can give rise to multiple variants of a protein, each with potentially different amino acid sequences, structures, and functions. This significantly increases the diversity of proteins that an organism can produce, without requiring a corresponding increase in the number of genes. Alternative splicing is an important mechanism for regulating gene expression and enabling the complexity observed in multicellular organisms.
Initiation of translation
The initiation of translation starts with the binding of the initiator tRNA with the anticodon (UAC) pairs with the start codon (AUG) on the mRNA, marking the beginning of translation. The small ribosomal subunit, along with the initiator tRNA, attaches to the 5' terminal of the mRNA and moves along the strand until the start codon is found. Once this codon is recognized, hydrogen bonds form between the codon and the anticodon, solidifying the connection. Subsequently, the large ribosomal subunit joins the small subunit, completing the ribosome assembly. The initiator tRNA occupies the P site, while the A and E sites remain vacant.
The elongation phase then begins. A second tRNA, carrying an amino acid complementary to the next codon in the mRNA, enters the ribosome and binds to the A site. This is where incoming tRNA molecules are matched with the codon on the mRNA to ensure the correct amino acid is added. The P site holds the tRNA with the growing polypeptide chain. A peptide bond is formed between the amino acid in the A site and the polypeptide held in the P site, catalyzed by the ribosomal RNA in the large subunit. Following peptide bond formation, the ribosome undergoes a conformational change and translocates one codon along the mRNA in the 5' to 3' direction. As a result, the tRNA that was in the P site (now without an amino acid) shifts to the E site (exit site) and is released from the ribosome, while the tRNA that was in the A site, now carrying the polypeptide chain, moves into the P site. This process continues codon by codon until a stop codon is reached on the mRNA, triggering termination of translation.
Modification of polypeptides into their functional state
Students should appreciate that many polypeptides must be modified before they can function. The examples chosen should include the two-stage modification of pre-proinsulin to insulin.
Once a polypeptide is synthesized by ribosomes, it is often not immediately functional. Many polypeptides must undergo post-translational modification to become active proteins. These modifications can include:
Folding into secondary, tertiary, and quaternary structures, often with the help of molecular chaperones to ensure correct folding.
Formation of disulfide bonds, which stabilize tertiary and quaternary structures.
Excising (removing) specific segments of the polypeptide chain.
Combining with other polypeptides or components to form quaternary structures.
Addition of side chains, such as glycosylation (addition of carbohydrates) to prevent clumping and aid function.
A example of polypeptide modification is the two-stage process of converting preproinsulin to insulin:
Preproinsulin, a 110-amino acid polypeptide, is synthesized in the β-cells of the pancreas.
It contains a signal peptide (28 amino acids), which directs the polypeptide to the rough endoplasmic reticulum (rER).
In the rER, this signal peptide is removed by a protease, forming proinsulin (86 amino acids).
Proinsulin folds and forms three disulfide bridges between its A and B chains, stabilizing the structure.
It is transported in vesicles to the Golgi apparatus, where another protease removes the C-peptide (31 amino acids), which lies between the A and B chains.
This leaves mature insulin, consisting of an A-chain (21 amino acids) and B-chain (30 amino acids), connected by disulfide bonds.
This final insulin molecule (51 amino acids total) is packaged into secretory granules and released into the bloodstream via exocytosis when blood glucose levels rise.
Recycling of amino acids by proteasomes
The proteome is the entire set of roteins that is or can be expressed by a cell, tissue or organism. To sustain a functional proteome, eukaryotic cells rely on the continuous breakdown and synthesis of proteins. This ensures that only functional, properly folded, and necessary proteins are present in the cell at any given time. Damaged, misfolded, or excess proteins are identified and tagged with a regulatory molecule called ubiquitin. This ubiquitin tag serves as a signal for degradation by a specialized protein complex known as the proteasome. The proteasome is an organelle that carries out proteolysis, a process where proteins are broken down through hydrolysis of peptide bonds. Proteins tagged with ubiquitin are recognized by regulatory subunits at the entrance of the proteasome, which then unfolds the protein and feeds it into the central catalytic core. Within this core, protease enzymes break down the protein into short polypeptides. These are then further digested into individual amino acids, which exit the proteasome and are reused in the synthesis of new proteins via translation.