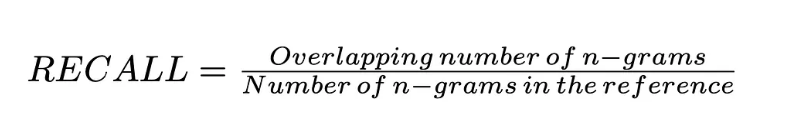Advancements in AI
1/127
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
128 Terms
what is a language model
A type of machine learning model that predicts the probability of a word based on 1 or more preceding words (or characters) - using conditional probability
what is the conditional probability that language models use
P(Text | Preceding Text)
has implicit order
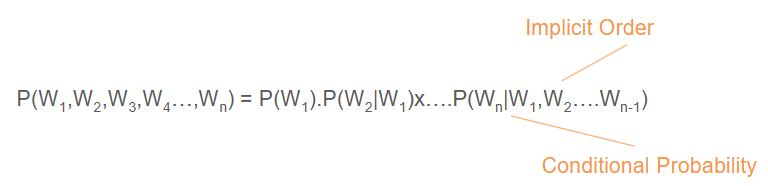
what are QA systems
Computer programs that use natural language processing (NLP) techniques to understand and answer questions posed by users.
what are the different types of QA systems
open vs. closed domain
open vs. closed book
conversational vs. mathematical vs. visual
what are open vs. closed domain QA systems
questions on any topic vs. specialised to one topic area
what are open vs. closed book QA systems
access to external data sources vs. rely on training knowledge
what are conversational vs. mathematical vs. visual QA systems
maintain context and continuity over long conversations vs. answer Qs about mathematical logic and reasoning vs. combines NLP with computer vision like describe an image or image accessibility
why are QA systems difficult to create
- need to handle complex language structures
- questions can be phrased in various ways so need advanced NLP understanding
- need to retrieve relevant information from vast amounts of data
- answers need to be verified for reliability
how can LLMs improve QA systems
allows for information retrieval
what are large language models
models that have been trained of a large volume of data (text) in order to predict the next tokens
what are LLMS based on
[[Transformers]] based deep learning architecture - great for natural language processing and can maintain long range dependencies and contexts
what type of media can LLMS accept
LLMs prompts are not restricted to only text, but can include other multi-media like image or audio, but for [[QA Systems]], prompts are primarily text, requires an instruction or a question (optionally, input data and examples).
what are the two types of LLMs
closed: business model requiring license and payment monetisation
open: open to programming community for fine tuning
where can LLMs be used
using LLMs for different industries require different techniques, or using LLMS tuned on industry specific data
what are the cons of LLMs
poor adaptability to having out-dated training data
too generalist, hard to adapt them to specific use cases and enterprise applications
stochastic response - randomly determined to some extent even when re-using the same prompt - deal with this by tweaking the temperature parameter, but this alone is not enough to prevent unwanted variability in responses
what optimisation methods exist for LLM behaviour to be improve
fine tuning
prompt engineering
retrieval augmented generation
what is fine tuning
Adapting a model for a specific task or use case, using the broader knowledge gained from pre-training and honing it towards specific concepts
what are the two types of fine tuning
fully fine tuned
parameter efficient fine tuning
what is full fine tuning
updating all parameters
what is parameter-efficient fine tuning
updates only the most relevant parameters
allows for the fine-tuning to occur on lower spec hardware
what are the pipeline steps for fine tuning
pre-training
fine-tuning
quantizing
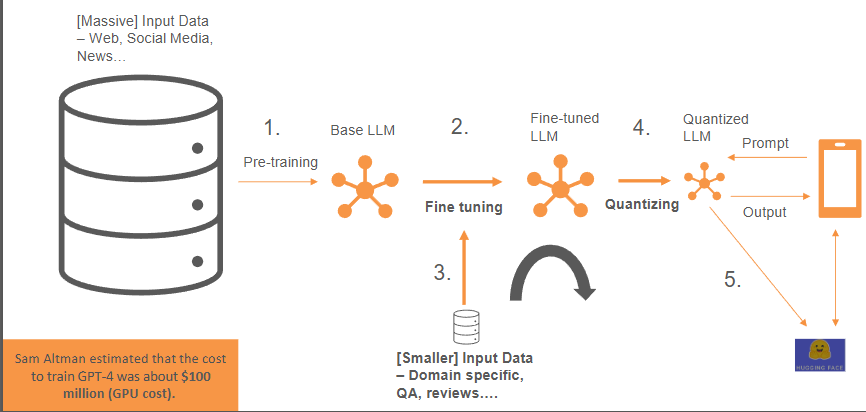
can also be done using reinforcement learning with human feedback
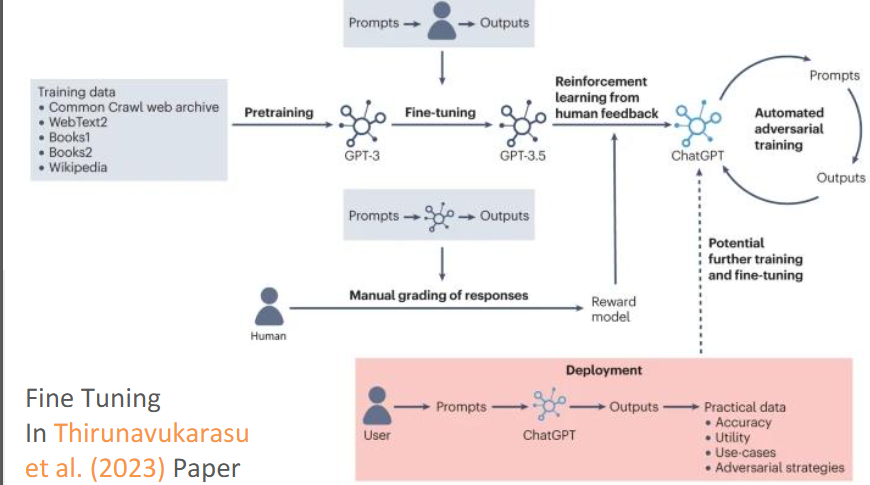
what is the difference between pre-raining and fine-tuning
Pre-training uses large datasets while fine tuning uses smaller, specialised datasets
what is the goal of fine tuning
adapts pre-trained LLM models with new content to performed better and better suit a particular task or application domain
what is the scope of knowledge in fine tuning
limited to knowledge in base model
how up to date is fine tuning
static - expensive to extend
how transparent is fine tuning
less transparent
what are the pros of fine tuning
gives us greater influence in how the model behaves and reacts since the context is baked into the weights instead of being supplemented on top as an extra technique
better for speed when running the model - smaller prompt context windows to still get the best responses for specific use cases
good for when datasets are available, specific industries that have easily identifiable patterns (specific jargon)
can produce highest accuracy in [[Chaubey et al.'s]] comparison paper and outperform their base models
what are the cons of fine tuning
information cut-off (outdated)
upfront resource cost data preparation and training processes are so compute-intensive and time-consuming -> powerful GPUs running in parallel and large memory to store the fine-tuned LLM
poor generalisation, can't be used in multiple application, only for the specific application it was fine tuned for
poor datasets will impact the effectiveness of the final model
what is prompt engineering
the practice of designing inputs for generative AI tools that will result in better outputs without altering the model's parameters or expanding its knowledge base
what does prompt engineering require an understanding of to do
the domain to incorporate the goal into the prompt like what good or bad responses look like.
AI models as different models will respond differently to the same prompt
best to create a prompt template that can be programmatically modified according to some dataset or context

what are the types of prompt engineering
shot based prompting
prompt chaining
chain of thought prompting
prompt structuring
what are the pros of prompt engineering
cost-effective -> least time consuming or resource intensive and basic prompt engineering can be done manually
flexible to modify
quick to develop - e.g. for rapid deployment scenarios
most flexible and effective for open-ended situations where there are a diverse array of potential outputs like image and video generation
what are the cons of prompt engineering
less effective in proving coherent and accurate results compared to more advanced techniques like RAG or fine-tuning
what is shot based prompting
technique that uses a specific number of examples in the prompt to guide the model's output
what are the types of shot based prompting
zero shot
one shot
n shot
what is zero-shot prompting
No examples included in the prompt
what is one-shot prompting
1 example included in the prompt
what is n-shot prompting
n examples included in the prompt
what is prompt chaining
technique of proving a series of prompts to an NLP model to guide it to produce the desired response - where the output of one LLM becomes the input to another
what are simple prompts
prompt that contains a single question or instruction
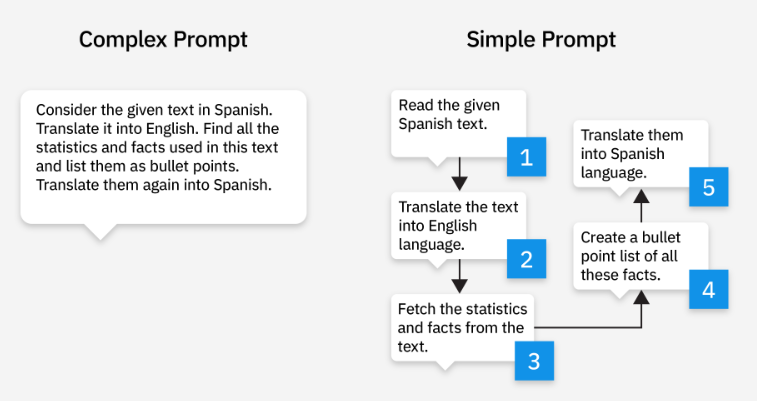
what are complex prompts
contain multiple instructions or questions where the model needs to perform a series of actions to provide a detailed response.
what is prompt chaining used for
simplify complex prompts
instead of giving one complex prompt, split up the complex prompt into multiple single prompts and chain them together
e.g. extract and categorise - get output
extract first - get output
categorise - get output
what are the pros of prompt chaining
traceability - allows users to understand the steps required to complete a request than a large monolithic prompt
accuracy and clarity - reduce the risk of errors or misunderstandings, can understand better and larger contexts and outperform monolithic prompts
troubleshooting - easier to identify at what point in the chain needs adjustments to produce optimal responses, more granular control
consistency - forcing the model to follow a series of prompts maintains consistency in tone or style or format which might be needed
widely applicable - most tasks can be functionally decomposed (although not all), making chaining a good solution
multiple instructions
multiple output transformations
when models seem to lose focus or forget context
what are the cons of prompt chaining
management difficulty - interrelated prompts can be hard to manage when the china becomes long or intricate, more room for error especially when using different AI models
hyper-dependency on the first prompt, if the initial prompt is bas then the failures will cascade throughout the rest of the chain
time consuming, the quality of each chain link needs to be (iteratively) tested and reviewed
longer processing time - multiple LLM calls instead of 1
higher costs - each part of the chain requires an LLM call which leads to higher costs for tokens for API usage (especially since prompt chaining produces longer outputs than one big prompt)
what are the applications of prompt chaining
structured prompt chains used for customer service chatbots, where prompts are linked together so the system can build upon previous responses and maintain context
any sort of multi step tasks like programming development, personalised recommendations, content creation from outline to editing
how can non-ai experts build prompt chains
[[key paper]] - using a visual interface
what is chain of thought prompting
the prompt guides the model to lay out its reasoning process, often resulting in more accurate and interpretable outcomes
what are the different ways to structure a prompt
COSTAR framework
delimiters to help LLM differentiate between information
direct language for more accurate responses
system prompts that persist before every response, rather than adding then to each request which the LLM can 'forget' over time, with guardrails to define what the LLM should not dot
what is retrieval-augmented generation (RAG)
an advanced, specific data architecture framework / technique for retrieving facts from an external knowledge base to optimise LLM responses on the most accurate and up-to-date information.
what are the tree parts of RAG
knowledge base
retriever
LLM
what does a basic RAG architecture look like
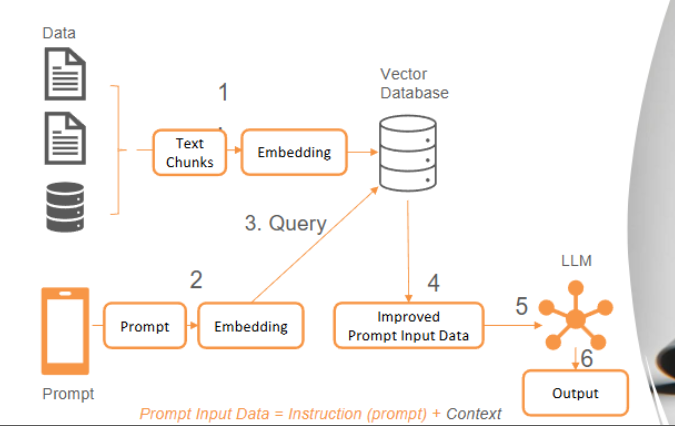
can be built using langchain
how does RAG work
query: user submit a query to the LLM (initially the prompt goes straight to LLM)
information retrieval: instead, an algorithm or API is used to retrieve relevant information first from the [[Vector Databases]]
integration: combine the retrieved data with the user's query to produce and augmented query, and then give it to the LLM
response: LLM generates an accurate response based on retrieve data and own training knowledge, this allows the LLM to give evidence for why it gave a certain response
what are the different types of RAG
naive
modular
advanced
what is the aim of RAG
improves retrieval and generation and guide the LLM to produce relevant and accurate output
how up to data is RAG
integrates latest knowledge
how transparent is RAG
uses sourced data
what is the resource use of RAG
user driven resource cost, datasets and pipelines to connect the LLM to the dataset need to be constructed
what common issues does RAG solve over base LLMs
regular LLMs have no source to derive their responses from, so information can be inaccurate - RAGs are directed to focus on primary source data, so less likely to leak data or hallucinate
information given can be out of date, instead of having to retrain the entire model for new information, augment the data store with updated information. much less computational effort is required.
any info can be part of the corpus, documents, PDFs, anything relevant to the business operations
hallucination from not knowing the answer and giving something random - encourages the LLM to admit when it doesn't know things based on what is or is not available in the vector database (but this can be a negative effect if the initial user prompt doesn't get an answer despite being answerable)
what are the pros of RAG
best for dynamic data sources like databases
best for trust essential systems (because of sources and less hallucinations) and for systems where accurate, relevant, and current information is essential
for ethical concerns
good use cases include documentation chatbots
allows non-public data to be leveraged
what are the cons of RAG
How we determine and select which information needs to be considers, as a poor calculation of similarity between the prompt and sources will produce inaccurate responses
not enhancing the base model itself
requires extensive data architecture construction and maintenance to build the pipelines between the organisation's data and the LLM
need to have precise prompt engineering to locate the right data and ensure the LLM can handle it properly
not as robust to unexpected queries
what is a vector database
A specific type of database that stores multi-dimensional data points instead of scalar values, the vectors represent data in numerous dimensions
how many dimensions do vectors in a vector database have
few to a thousand
what type of content can a vector database store
this content store can be open (internet) or closed (classified documents) depending on the need.
how is a vector database queried
quickly and precisely locate data based on vector proximity or resemblance
searches don't just rely on exact matches but can match based on semantic or contextual relevance
using measures of similarity to find the closest matches - APP, Approximate Nearest Neighbour
what are examples of vector databases
Chroma
Pinecone
Weaviate
Faiss
Qdrant
Milvus
PGVector
what features does Chroma have
open source, easy to implement with langchain and python

what features does Pinecone have
better indexing and search capabilities for high-dimensional data, low-latency search and highly scalable, fully managed. best for rea-time searching
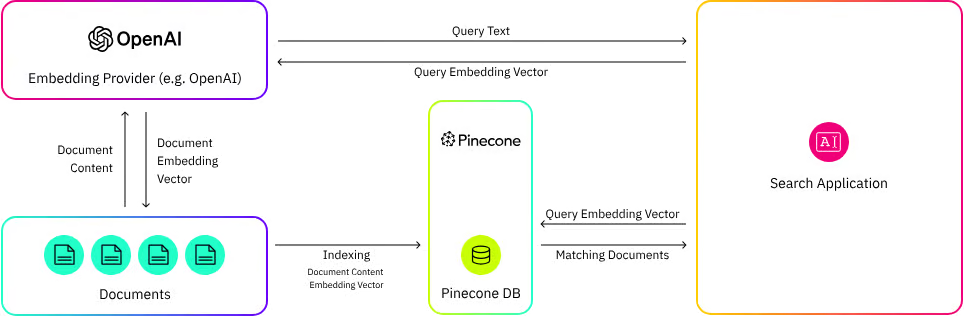
what features does Weaviate have
open-source, can search nearest neighbour of millions of objects in milliseconds, also includes recommendations, summarisations
how to create a vector database
need to create [[Embeddings]] for unstructured data, allows us to use all media types including images, text, audio, into the vector database
neural networks can be used to convert the text / data chunk into a numerical embedding
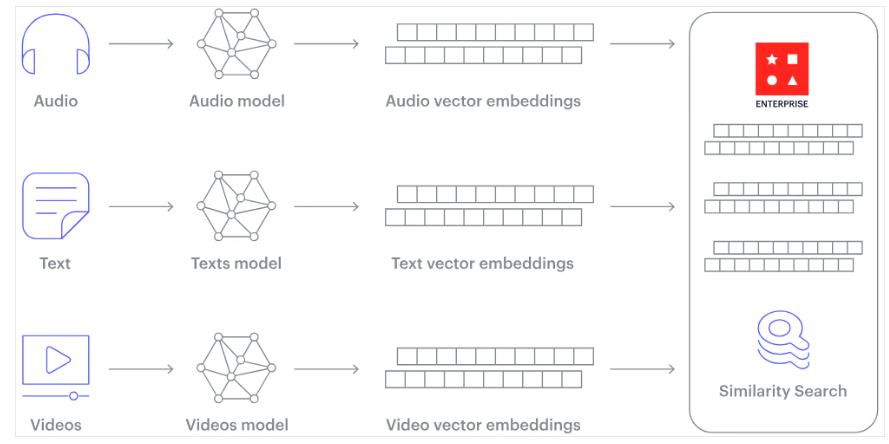
what are the pros of vector databases
scalability and adaptability - as data grows it can scale across multiple nodes, the system can be tuned to include any new data as needed
multi-user support and data privacy - data isolation by ensuring changes made to one data collection are unseen unless explicitly shared
flexible for development if they offer a comprehensive set of APIs and SKDs
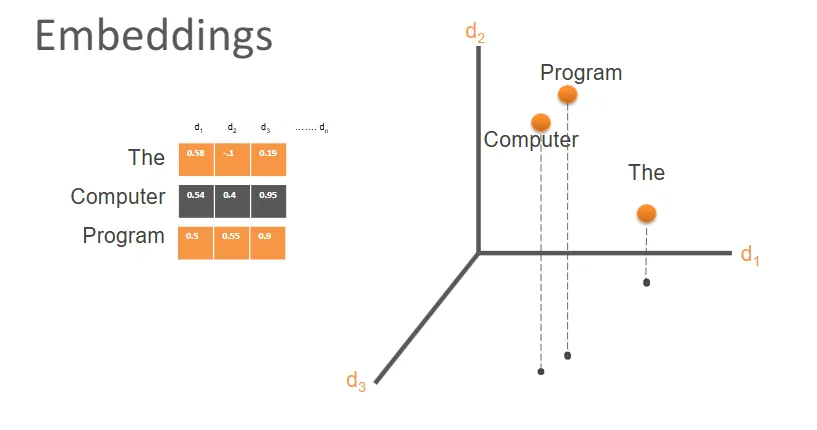
what is an embedding
a vector (multi-numerical) representations of words/phrases that capture the semantic meanings in a high-dimensional space
how is the relatedness of vectors measured
based on how close the embeddings are in the dimensional space -> closer together = semantically similar / related and vice versa
aka. each word represented over a set of numbers e.g. a 3d embedding will have 3 different numbers to make up a piece of text - in real applications there are many more axis than 3
what existing embedding libraries are there
existing models include GloVe, Word2Vec to generate the embeddings, and then store the embeddings in the DB
OpenAI Embeddings could be best for RAG, since it’s optimised for GPT models and works with Pinecone - API interface, 3 different models to choose from depending on price and embedding length
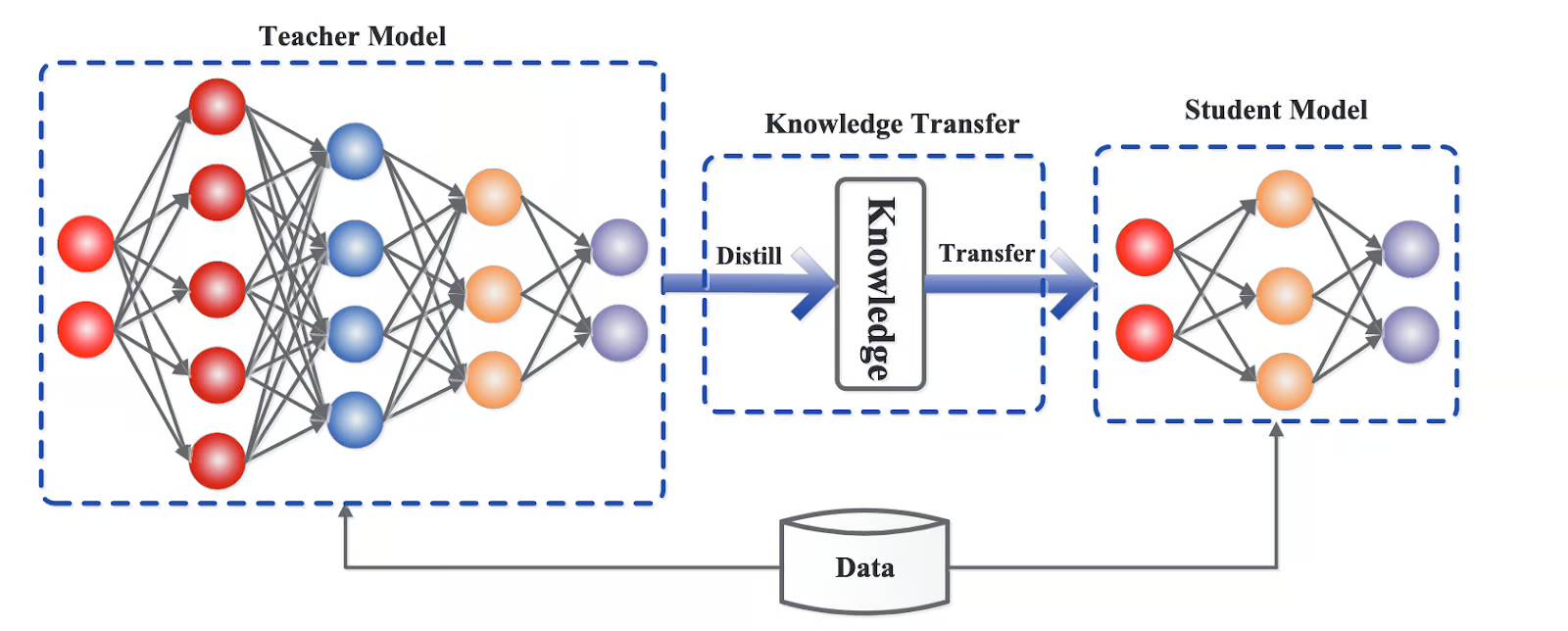
what is distillation
Training smaller, more efficient (student) models to mimic the behaviour and reasoning patters of the larger models by using it as a teacher - transferring the knowledge and capabilities parameter model into more compact architectures
how does distillation work
Given some unlabelled data, the teacher LLM is asked to label it. This synthetically labelled data is given to train the student model
what are the pros of distillation
generates predictions much faster, good for real-time applications or resource-constrained devices
reduced parameters = requires fewer computational and environmental resources (energy consumption), easier to store and mange
less expensive to host an LLM with fewer parameters via API
what are the cons of distillation
predictions are usually not as good as the original LLM's
the student is limited to the teacher e.g. generalised LLMS don't do well with specialised tasks
still requires lots of unlabelled data
the OG LLM labelled data might be sensitive and not usable
knowledge loss
what is the key roles of distillation for LLMs
enhancing capabilities
traditional compression for efficiency
emerging trend of self-improvement via self-generate knowledge
what can be done to mitigate knowledge loss in distillation
augment the data generated by the teacher model to provide broader range of training examples
iterative distillation - can capture more of the teacher's knowledge
adjust hyperparameters like temperature and learning rate
temperate - smoothness of probability distribution and creativity of responses
learning rate - balance speed and stability of training process so the model can converge without under or over fitting
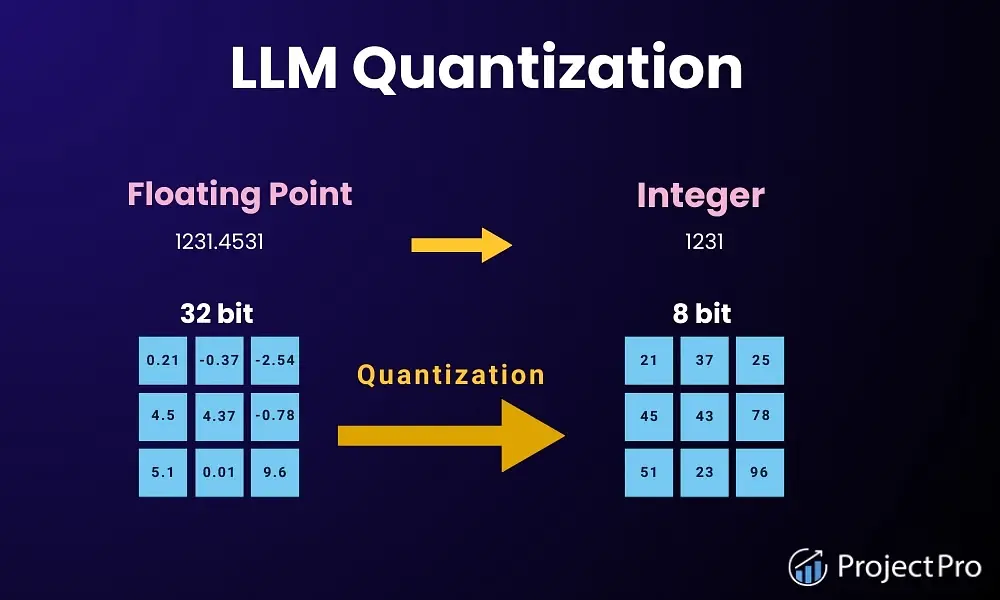
what is quantization
compressing a LLM by converting weights and activation values of high precision data, usually 32-bit floating point (FP32) or 16-bit floating point (FP16), to a lower-precision data, like 8-bit integer (INT8).
what are the most common quantization cases
The two most common quantization cases are float32 -> float16 and float32 -> int8.
what are the types of quantization
linear quantization
block-wise quantization
what is linear quantization
mapping the range of floating-point values of the original weights to a range of fixed-point values evenly, using the high-precision data type for inference
what is block-wise quantization
quantizing weights in smaller blocks rather than across the entire range, better handles variations within different parts of the model
when can quantization be performed
post-training quantization
quantization-aware training
what is post-training quantization
quantizes after the LLM has been trained
what is quantization-aware training
fine tune on data that can quantization can be done easily one e.g. including rounding or clipping the training data
both the quantized and original weights are stores, the quantized version is used for inference but the unquantized version is updated during backpropagation
usually higher accuracy than PTQ
what are the pros of quantization
faster inference - quicker calculations which reduces latency despite reducing accuracy
efficiency - reduced computational and memory costs of an inference
allows models to run on embedded devices that only support int types
better compatibility with integer operations to support older computers that don’t support floating point operations
what are the cons of quantization
- loss of accuracy (often negligible though)
why is the loss of accuracy in quantization okay
LLMs require a lot of processing power and memory so we can sacrifice some (negligible) precision in favour of less processing requirements - balance
how can we evaluate QA systems
Benchmarking with metrics
LLM performance comparison e.g. latency
Expert reviews of output depending on the context
Comparing results to existing documents e.g. financial contracts
Repeat the same prompt multiple times to access clarity, readability, repeatability - and identify any bias or hallucinations
AI judging acting as experts e.g. ChatBot Arena, LLMCompare
what metrics can be used
ROUGE metric
BLEU metric
accuracy
perplexity
what is BLEU score
(BiLingual Evaluation Understudy) is a metric for automatically evaluating machine-translated text. A number between zero and one that measures the similarity of the machine-translated text to a set of high quality reference translations
what is perplexity
capture the degree of 'uncertainty' a model has in predicting (ie assigning probabilities to) text
higher perplexity means more uncertainty and more incoherent, inaccurate text
why can’t metrics alone be used
metrics cannot capture complexity and understanding of responses so human evaluation is needed to…
determine the reasoning and synthesis quality
review responses that may be subjective
identify out-of-vocabulary words
what can poor performance help us do
areas where the model underperforms signals that more development is needed
what is ROUGE metric
the F1 score (overlap) for N-gram precision and recall
what is an n-gram
sequence of N words
e.g. can be ROUGE-1 or ROUGE-2 for N word sequences
##for unigrams it is
(I),(love),(Machine),(Learning)
##for bigrams it is
(I love),(love Machine),(Machine Learning)
what is recall
quality of accurate n-grams
how do you calculate recall