Lecture 4: Perceiving and Recognizing Objects
1/88
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
89 Terms
Idealism:
Reality is inseparable from perception; reality is a mental construct
Reality as a top-down process starting from the mind
Materialism:
The mind can be explained in terms of matter and physical phenomena
(Outdated) Reality is a bottom-up process starting from the sensors
Some ventral stream areas
Lateral occipital complex (LOC)
Parahippocamp al Place Area (PPA): Scenery, locations
Fusiform Face Area (FFA): Faces
Extrastriate Body Area (EBA): Bodies
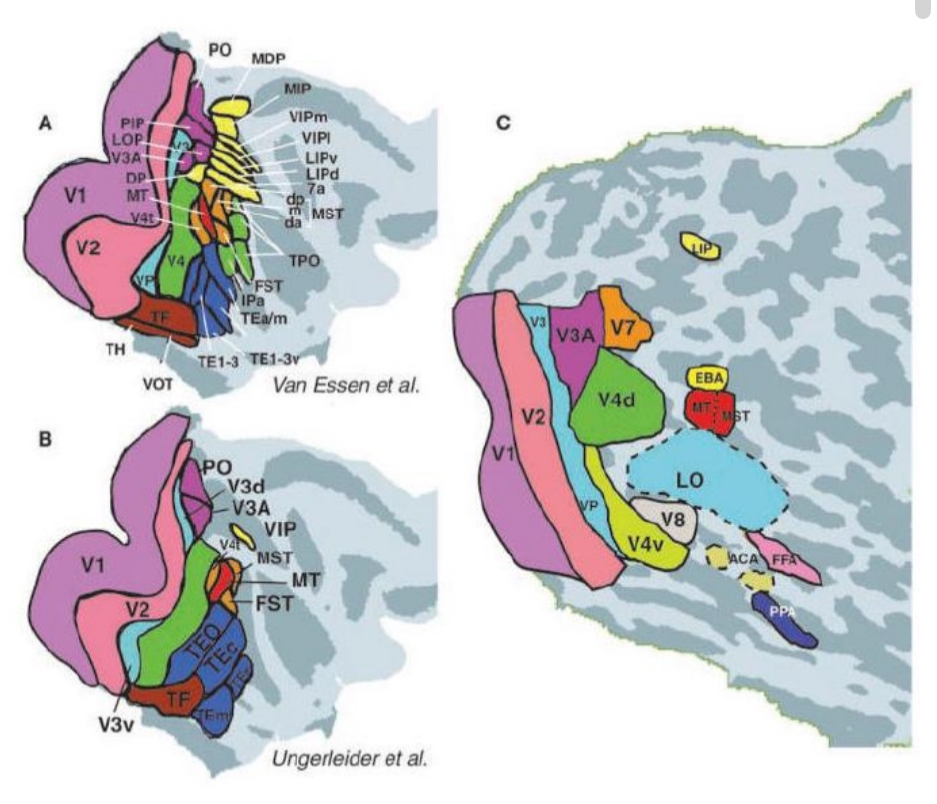
Lateral occipital complex (LOC)
Object perception
lesions in both you can see colour, texture but not shapes.
Can’t tell difference between cat and car
Parahippocamp al Place Area (PPA):
Scenery, locations
Recognizing the sight of scenes
Ex. I recognize a picture of campus as UTSC
In hippocampus, because hippocampus has to do with navigating And processing scenes helps with navigating
Fusiform Face Area (FFA):
Processing Faces
Extrastriate Body Area (EBA):
Responds to sight of body
Doesn’t care whether face is there
Process non verbal signals in body language like emotional state
Two streams for visual processing
Dorsal stream vs ventral stream
Superior temporal sulcus pathway also proposed
Not separated, connected to one another
Broad generalization: cross connections, feedback as well as feed forward.
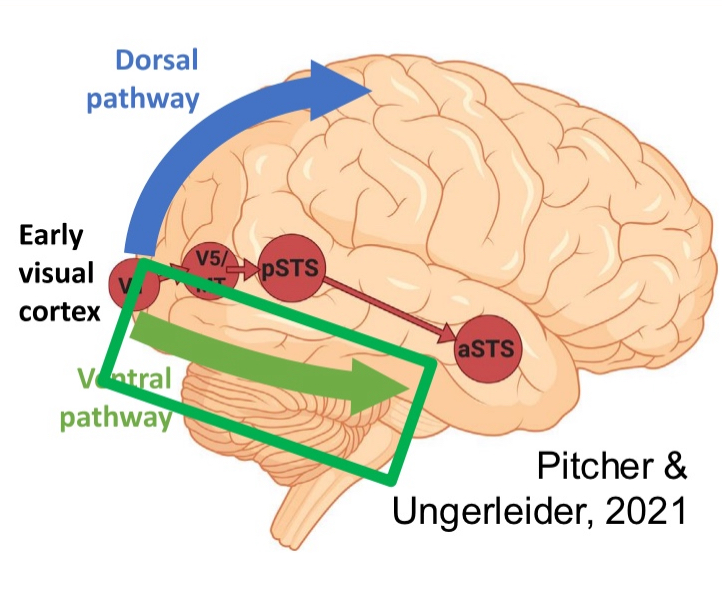
Dorsal stream
Visual processing and location
focuses on spatial location and guides actions related to objects
processes where, how information.
Fast but colourblind
Ventral stream
processes what information (what is there)
Responsible for object recognition, form, and color perception, essentially helping us understand "what" an object is
Superior temporal sulcus pathway
for biological motion and social perception
Object perception
set of lines that belong together
Piece things together to say → thats an object
Middle vision combines
features into objects.
The result is object perception.
Object recognition
We say “that picture is a house”
Set of objects that belong together into a learned category in our memory
we match a perceived object representation to a representation encoded in memory.
These memory traces can contain information about object categories
the ability to identify and categorize objects visually
Aliens landing on earth would have to learn this category
Ex. “That is a house” or “thats a face”
Object identification
Special case of recognition
Recognizing the same object in relation to you when you interact with it more than once
These memory traces from object recognition can contain information about that particular object. That’ s object identification.
“That house is my grandmothers’” or “thats my friends face” → sub categories within categories of object recognition
Object naming
Attaching labels to object
involves retrieving the linguistic label associated with that object
Recognized objects usually have semantic labels and names assigned to them. – Language functions
What V1 sees
Break up things into edges and lines through simple cells
Challenges to what V1 sees:
curved lines, overlap, gaps
What belongs together?
Figure vs. ground?
Challenges to what V1 sees: curved lines, overlap, gaps
Simple cells detect edges in hyper columns if the edges respond to the same orientation in its receptive field
Ex. A simple cell that responds to horizontal orientation or vertical and will recognize those edges
Doesn’t work as well for curved edges, overlap, gaps
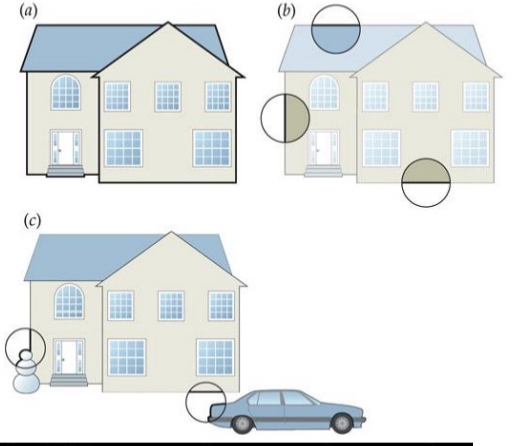
Challenges to what V1 sees: What belongs together?
When area V1 processing the picture, it get the second picture. It’s a mess of lines. So what belongs together?

Gestalt:
German for “whole”
“The whole is greater than the sum of its parts”
Wertheimer, Köhler, Koffka (1920s–1950s); Palmer and Rock (1990s)
Reaction to earlier structuralist school of psychology
Gestalt laws (grouping rules):
set of rules describing which elements in an image will appear to group together
Includes
Gestalt law of “good continuation”
Gestalt law of similarity
group parallel and symmetric elements together
Gestalt law of common fate
Gestalt law of synchrony
Common region
Connectedness
Gestalt law of “good continuation”:
two elements tend to group together if they seem to lie on the same smooth contour
In area V1, the neurons N1 and N2 get excited because they both see lines of the same orientations
They inhibit N3 because it has similiar reseptive field but not the same orientations
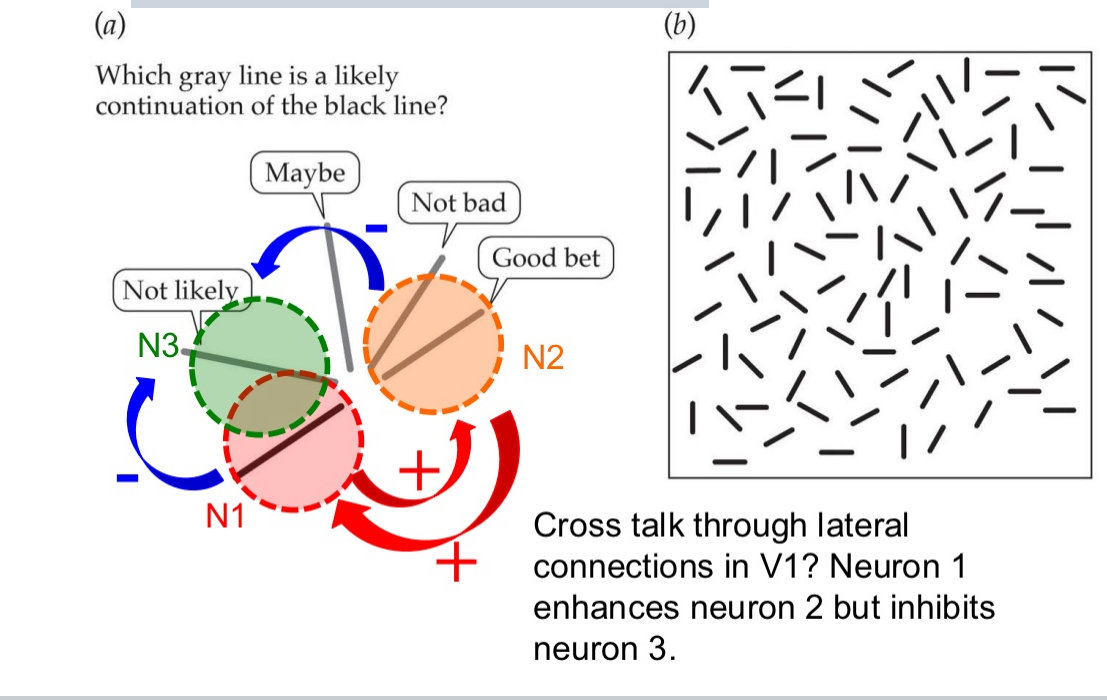
Gestalt law of “good continuation”
what is considered smooth
Geisler et al. (2001): natural scene statistics explain the gestalt law of good continuation.
Photo of forest, do 2 lines belong to same twig was done in study
Lines that are more smooth will belong to same object.
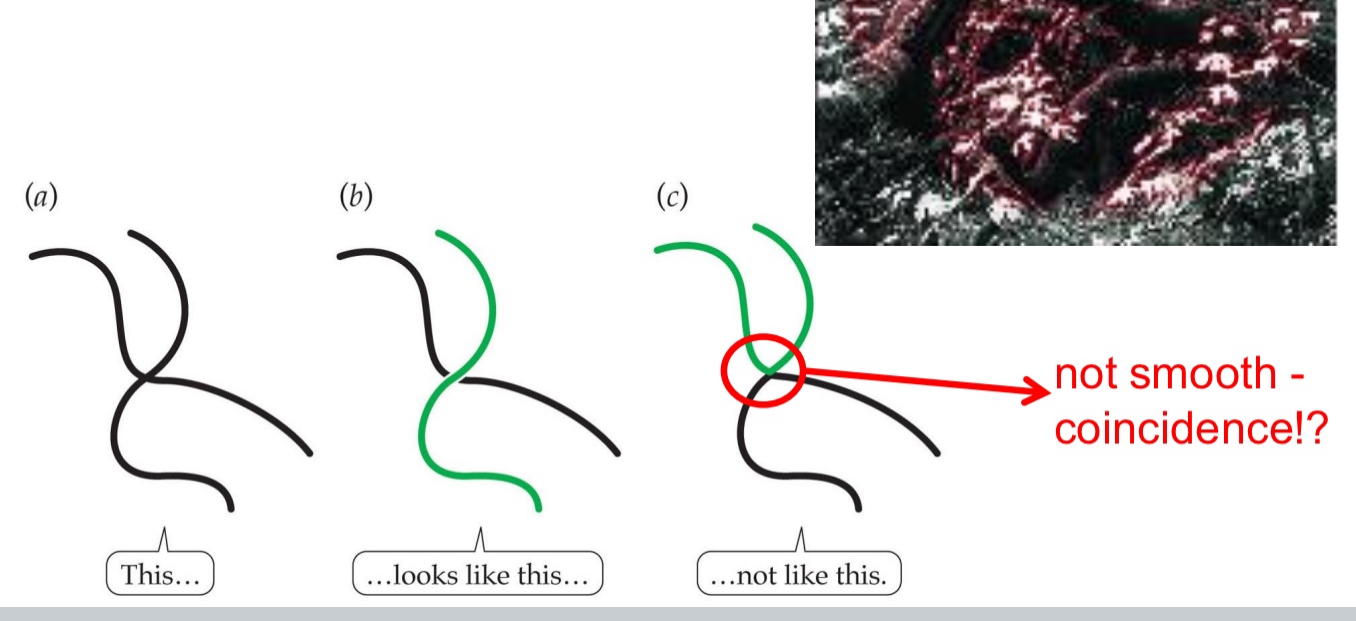
What to do with gaps in contours?
A sudden stop in an edge
Illusory contours:
Kanizsa figures
Visual interpretation of several “aligned” end stopping
that’s no coincidence there must be an occluding contour!

Murray et al. (2002): late (higher level) visual processes
Different pigments = 126 ms to Process
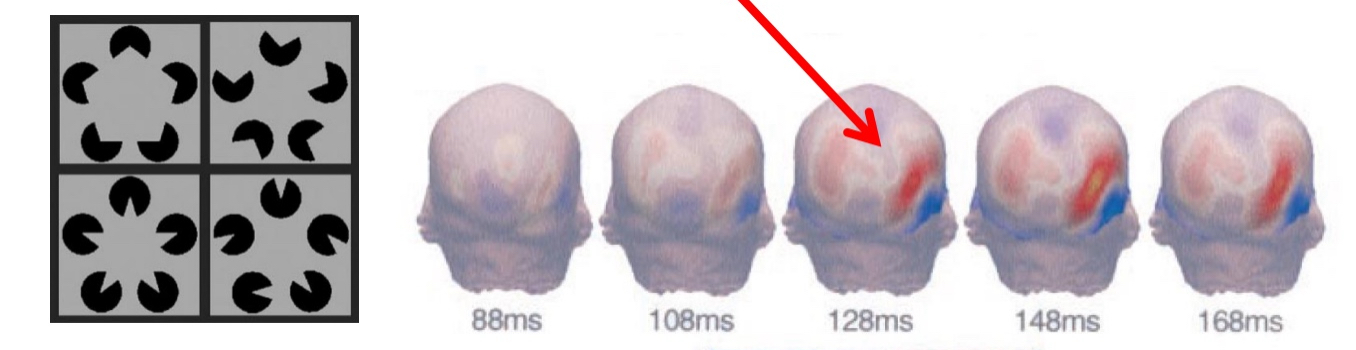
Texture segmentation:
carving (parsing) an image into regions of common texture properties
Doesn’t always work very well, unstable, dependent on image quality

Gestalt law of similarity:
elements group together if they are similar
Camouflage is the attempt to
trick texture segmentation.
If we are tricking Gestalt law of similarity meaning we use it to some extent

Gestalt law of “proximity”
two elements group together if their distance is small
The stars form rows and lines

Somewhat weaker Gestalt grouping principles
group parallel and symmetric elements together
Gestalt law of common fate:
groups together elements that are moving in the same direction.

Gestalt law of synchrony:
groups elements together that are changing at the same time.
Same 4 dots change colour
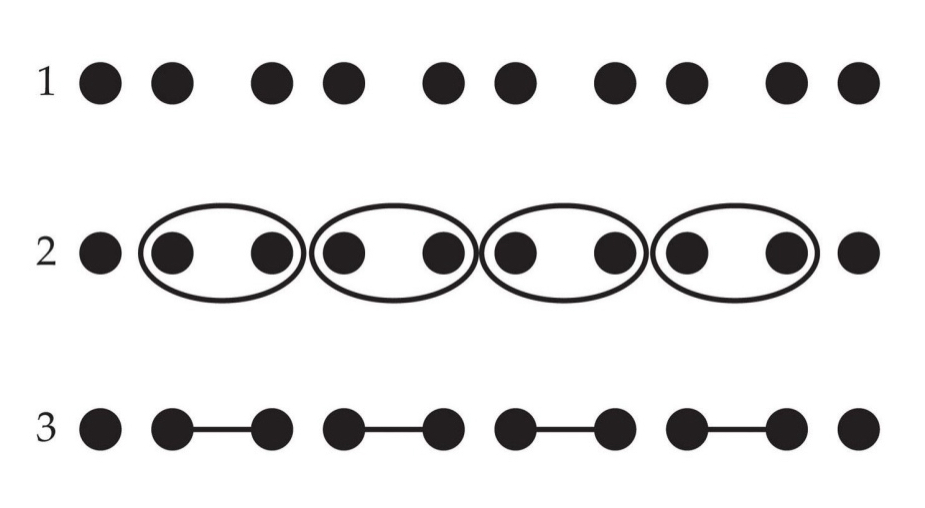
Common region:
Elements perceived to be part of a larger region group together
Row 2
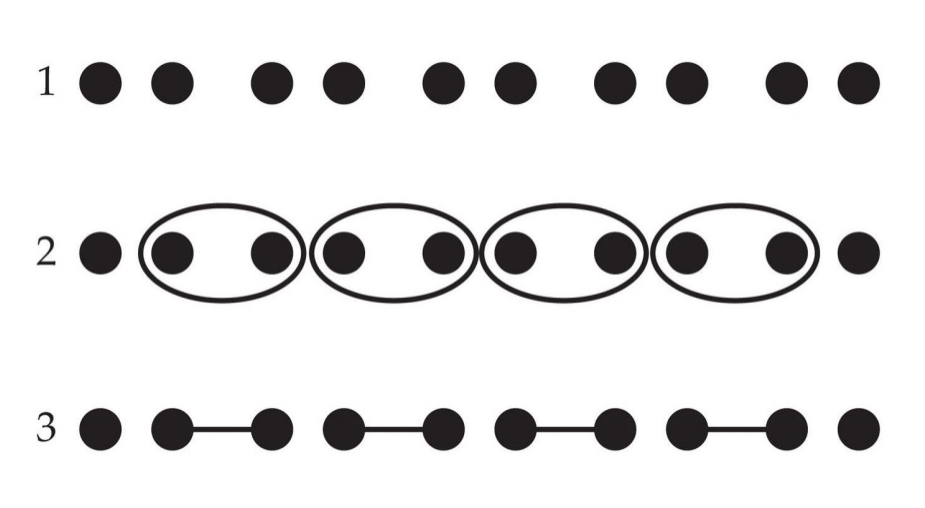
Connectedness:
Elements that are connected to each other group together
Row 3
How do multiple gestalt principles work together
Parallel processing
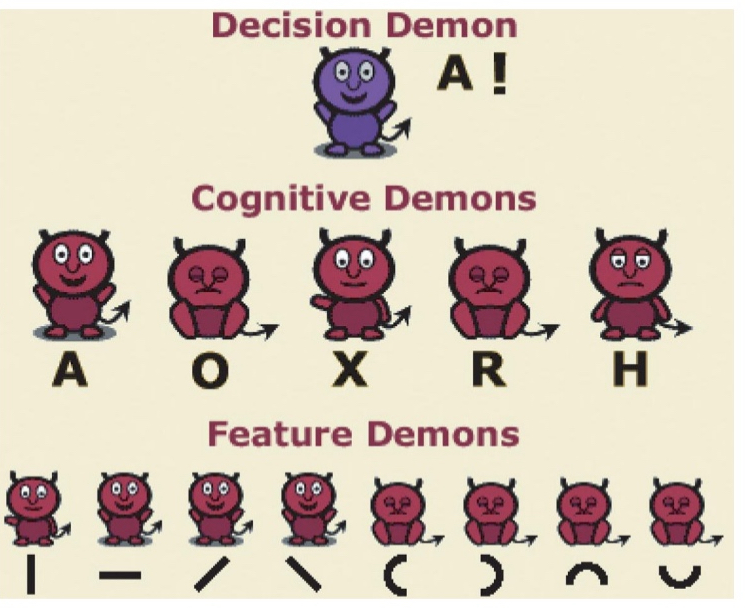
Perceptual committee models: middle vision similar to a collection of “specialists” for certain features (feature values) who vote on their opinions
E.g., pandemonium model (Selfridge, 1959)
Each demon is like a simple cell or neuron
Feature demon → cognitive demon → decision demons
Letter recognition
“Demons” loosely represent (sets of) neurons; each level = different brain area
Committee rules
Honour the laws of physics (& biology)
Nothing is going to defy gravity on earth. The pallet has concave and convex circles, not floating circles
Resolve ambiguity (Necker cube)
Perceiving squares from below or above, different perceptions
Stats: reject accidental viewpoints
What is likely what is unlikely
Dismiss coincidences
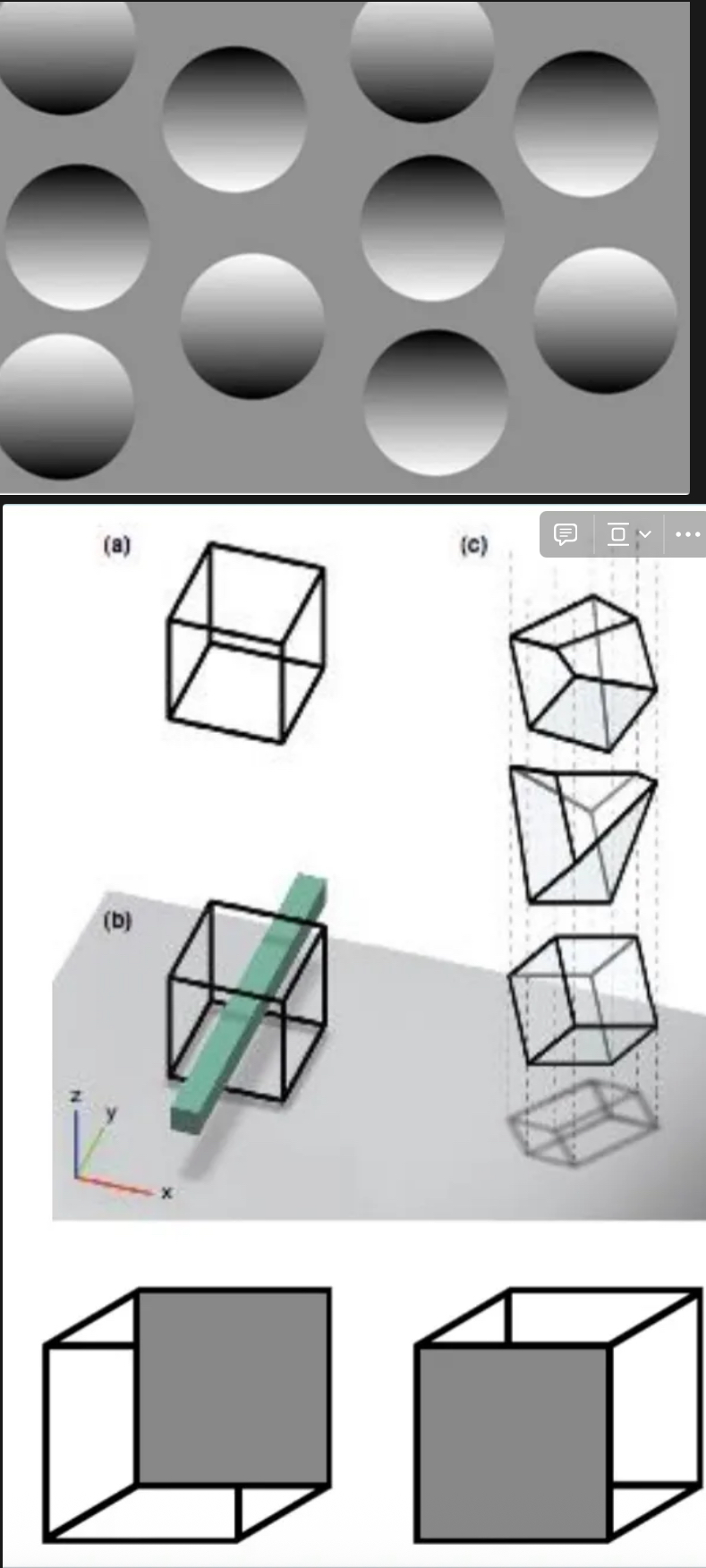
Multiple gestalt principles for figure-ground segmentation
What is the to-be- recognized object and what is the background?
Foreground is more symmetrical, parallel

Figure-ground assignment:
determines that some image region belongs to an object in the foreground, other regions are part of the background.
Uses heuristics
Gestalt figure–ground assignment principles:
Suroundedness , size, symmetry, parallelism
Extremal edges:
horizons of self-occlusion on smooth convex surfaces
powerful figure-ground cue

Heuristics for partially occluded features
We complete edges behind occluders when the edges are relatable by an “elbow curve”
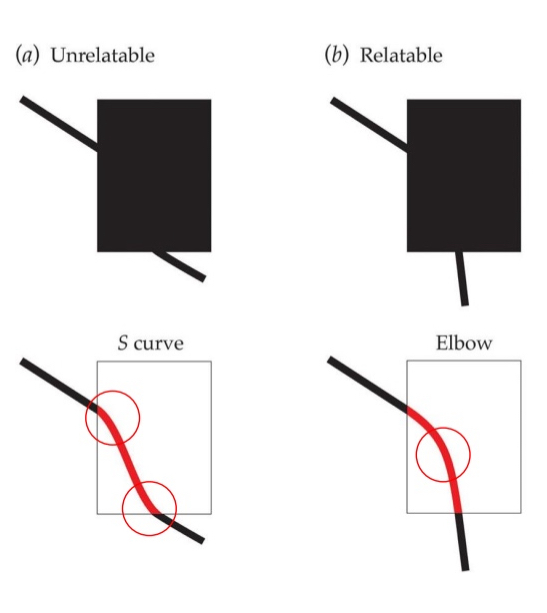
Heuristics
are mental shortcuts that work most of the time but not always.
Relatability
degree to which two line segments appear to be part of the same contour.
More heuristics that serve as cues for depth & occlusion:
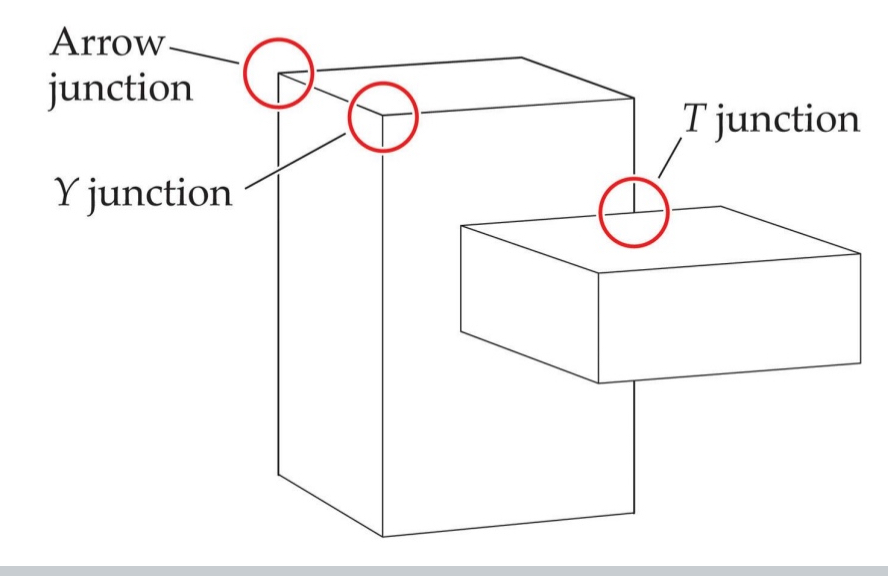
Non-accidental features provide clues to object structure. Don’t depend on exact viewing position.
T junction = occlusion; not arrow/Y junctions → not coincident or depend on differing viewpoints
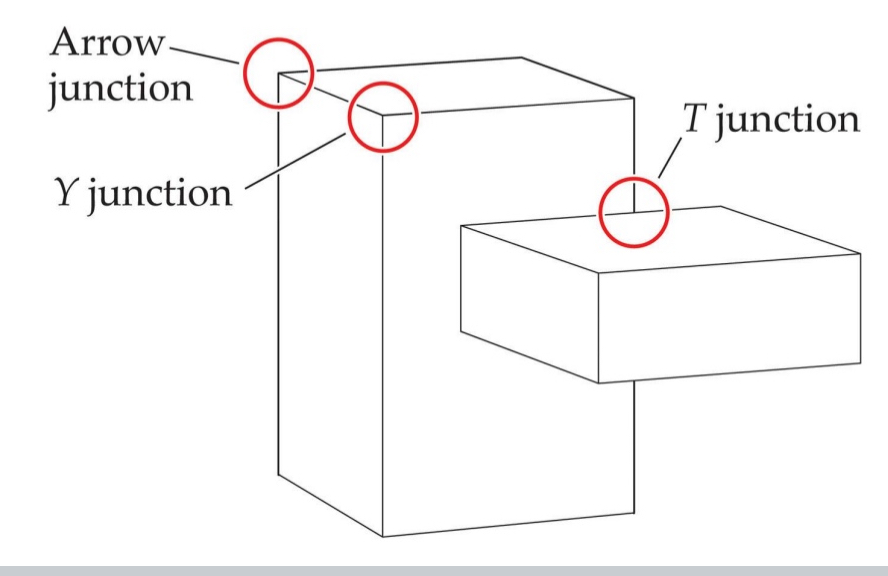
An arrow junction has one line extending
"into" a "v" formed by the other two
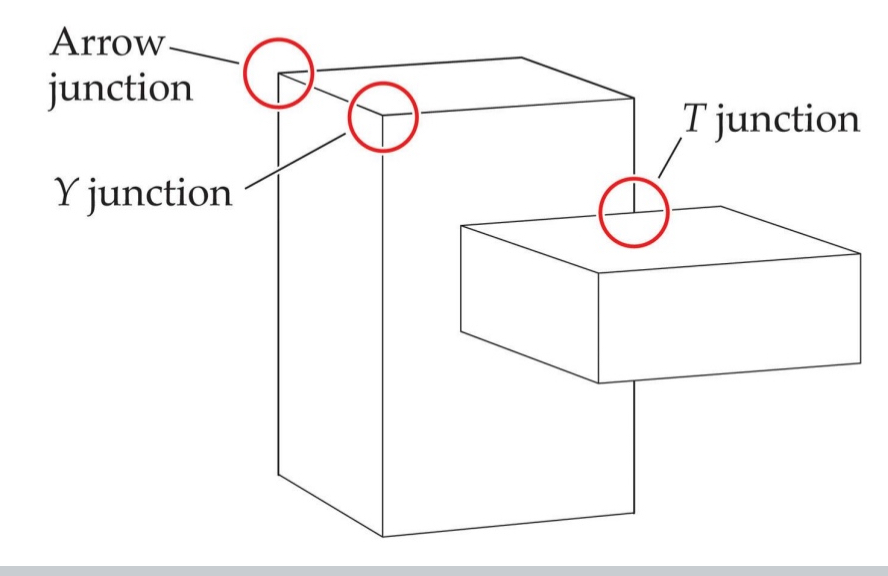
Y-junction has the three lines
meeting at an angle less than 180 degrees, forming a "Y" shape
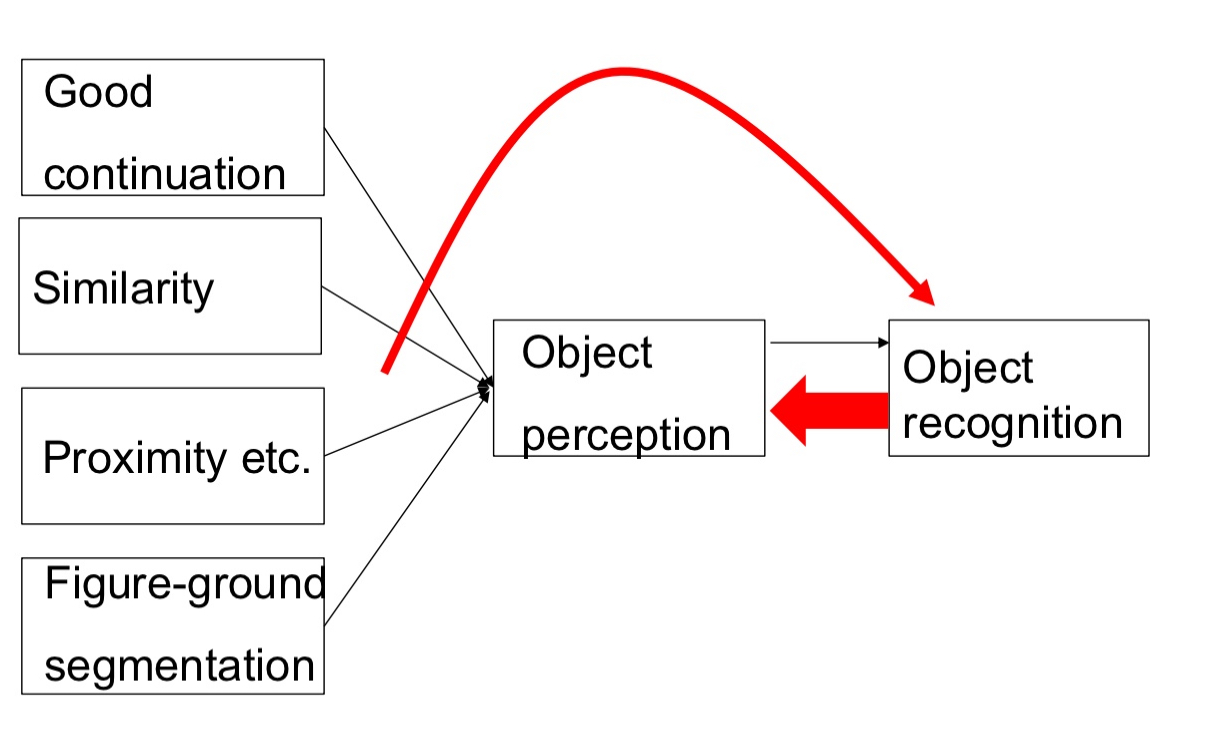
Gestalt laws → object recognition → object perception in middle vision through button up
bottom-up processing
refers to building perceptions from basic sensory information, like individual light patterns or sound frequencies.
Top-down processing
uses prior knowledge, expectations, and context to interpret those sensations
Rubin figure:
Ambiguous image
Has to do with gestalt law to with figure ground segmentation
Orange surrounded by white: vase, symmetrical, you would assume its at the front and white is background, therefore object is a vase
But if orange is background, the object is 2 faces looking at each other, also symmetrical
Is brown or white the figure here?
Object recognition starts before figure–ground assignment finishes!
If perception was only feed forward (apply rules of figure ground segmentation, then recognize things) you would say “i see vase” and never see the 2 faces because brain already dismissed it
Therefore bottom up and top down processing you can switch between the 2

Global superiority effect
Children see local stuff first (details) before global (whole picture/ objects)
Adults are opposite
See forest before you see the tree, less to deal with
Properties of a whole object take precedence over parts of the object.

Naive Template Theory
says that we hold a sample template of objects in our memories, and so exemplar methods allow for matching new stimuli to existing examples, or prototypes, in their memory
“Lock-and- key” representations
Object that you perceive (key) stuff stored in memory (lock). When key goes in lock, you preform recognition
However only one key works for each lock (template would not work only work for different object but also different versions of one object or letter. The fonts below of would not be recognized by the pixel lock and key) sooo….
Problem: You would need too many templates!
Not practical

solutions to Naive Template Theory
Structural Description Theory
View dependent models
Structural Description Theory
CAD-like 3D (“view-invariant”) models
Represent the structure of objects, not single views
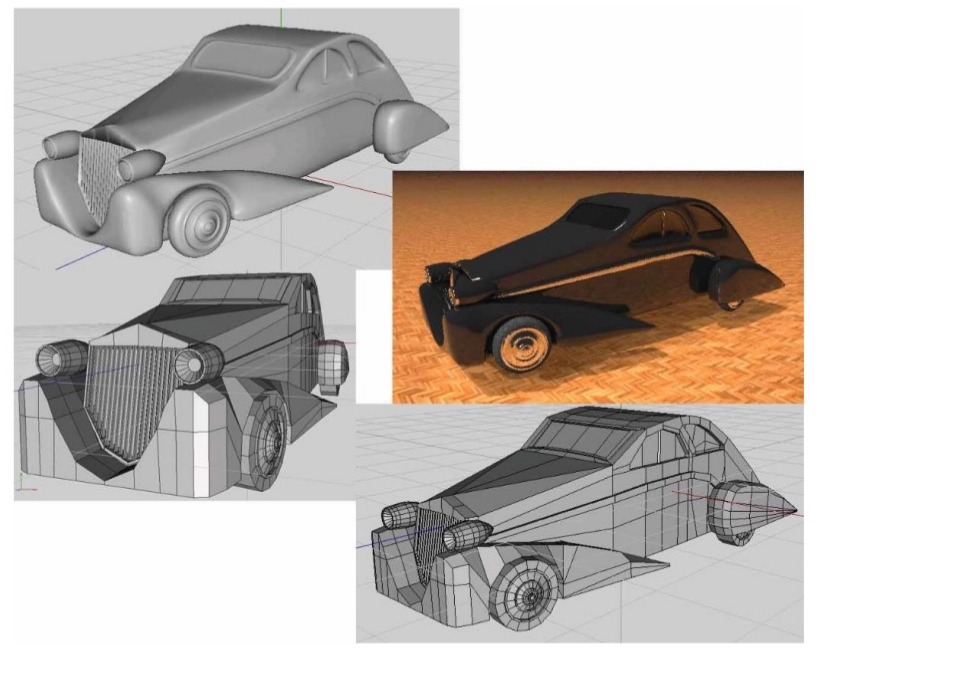
Marr & Nishihara (1978): cylinders
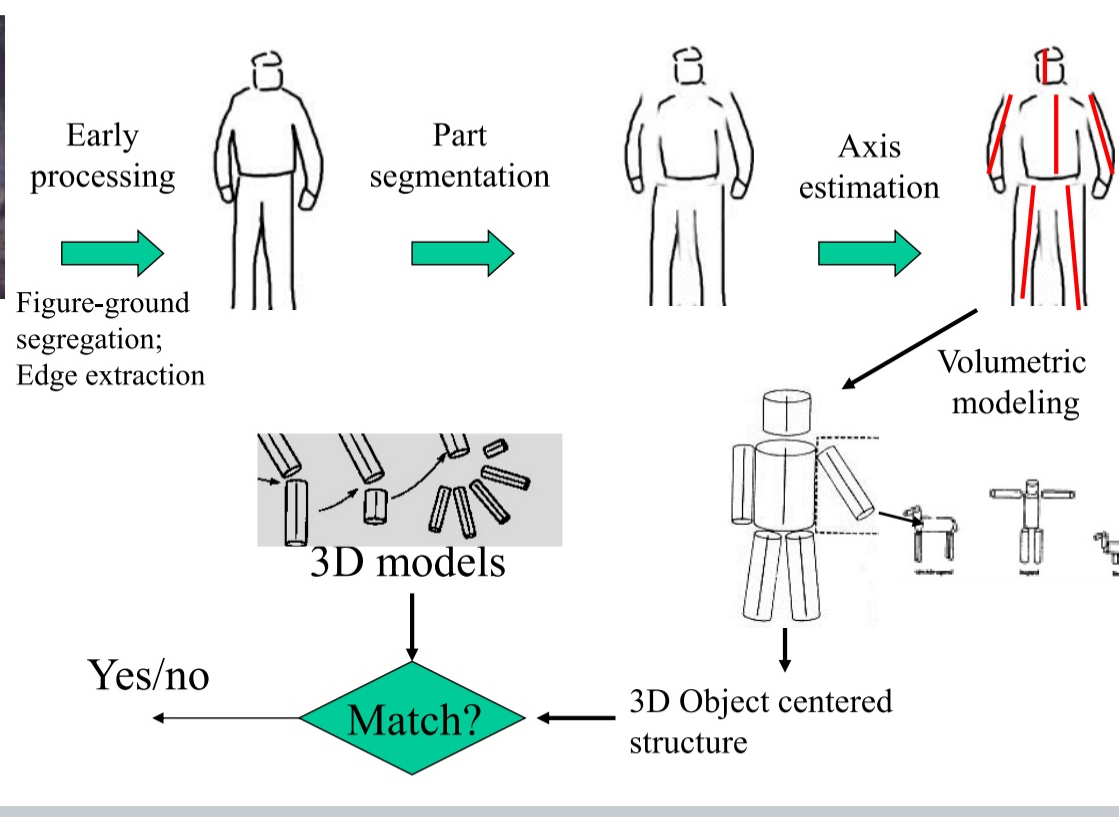
Theory on how Structural Description Theory occurs
Early processing: figure ground segregation, edge extraction
Part segmentation: seperate object to parts (head, arms, legs, torso)
Axis estimation : which body parts on which axis / orientation
Volumetric modelling ( same axis have same shaped cylinder, like 2 arms different then 2 legs , different from torso and head) → length of cylinder and orientation
See if 3D models match what you have stored in memory
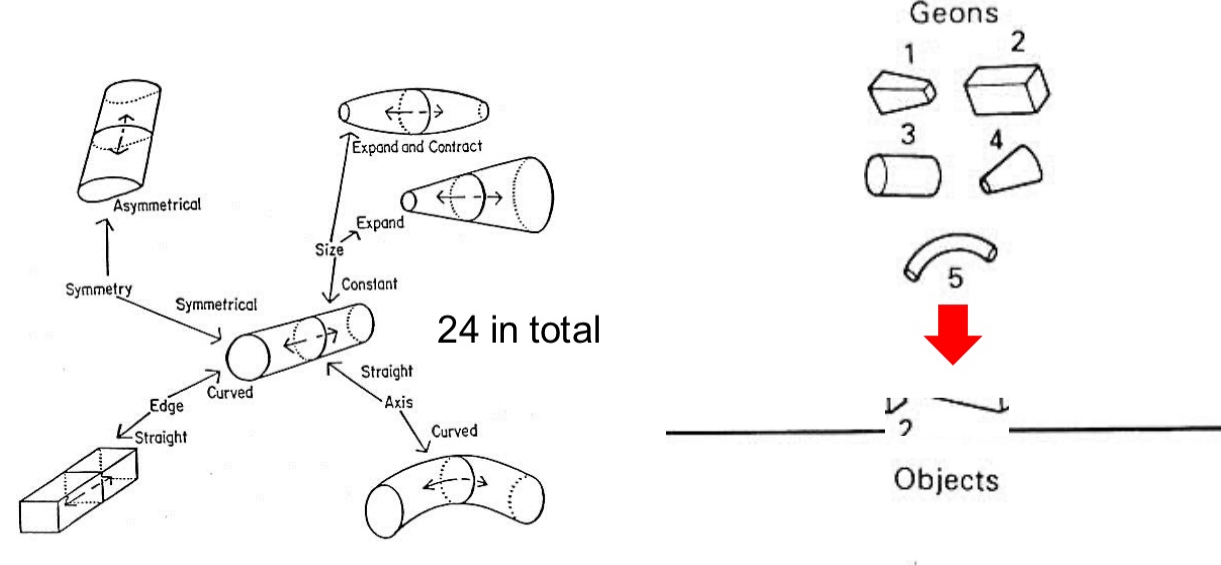
Biederman (1987): Recognition-By-Components (RBC)
Don’t have cylinders but geons
geons - generalized cylinders where the cross-section can vary over the length of the axis, which itself might not be straight
Did Picasso inspire structural description theory & RBC
Cubism: Picasso, Braque and others
Attempt to depict the visual world with basic shapes (neck recognized by cylinder)

Flaw in structural description theory & RBC
Geons/cylinders difficult to extract from real images
Subordinate level recognition?
Different orientation as the same person
Natural objects with complex structures?
That’s a lot of cylinder
Total viewpoint invariance??
an object can be identified consistently regardless of the viewing angle or orientation. → not true we dont have Total viewpoint invariance

view-dependent models
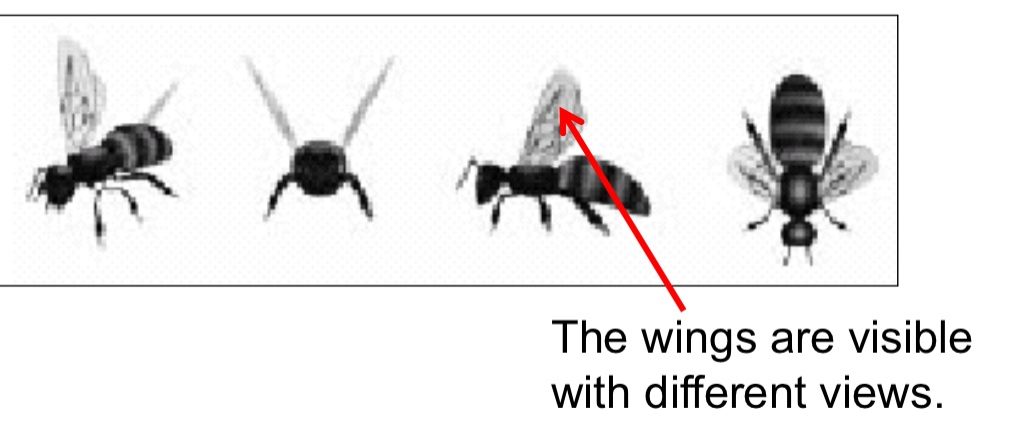
Tarr, Buelthoff and others assume that we store (a small set of) different views of the same image.
To limit the number of views that have to be stored we may interpolate between the views.→ all the bees have wings this consistent features help us interpolate
This requires cues that are fairly robust to the vantage point (non-accidental features).
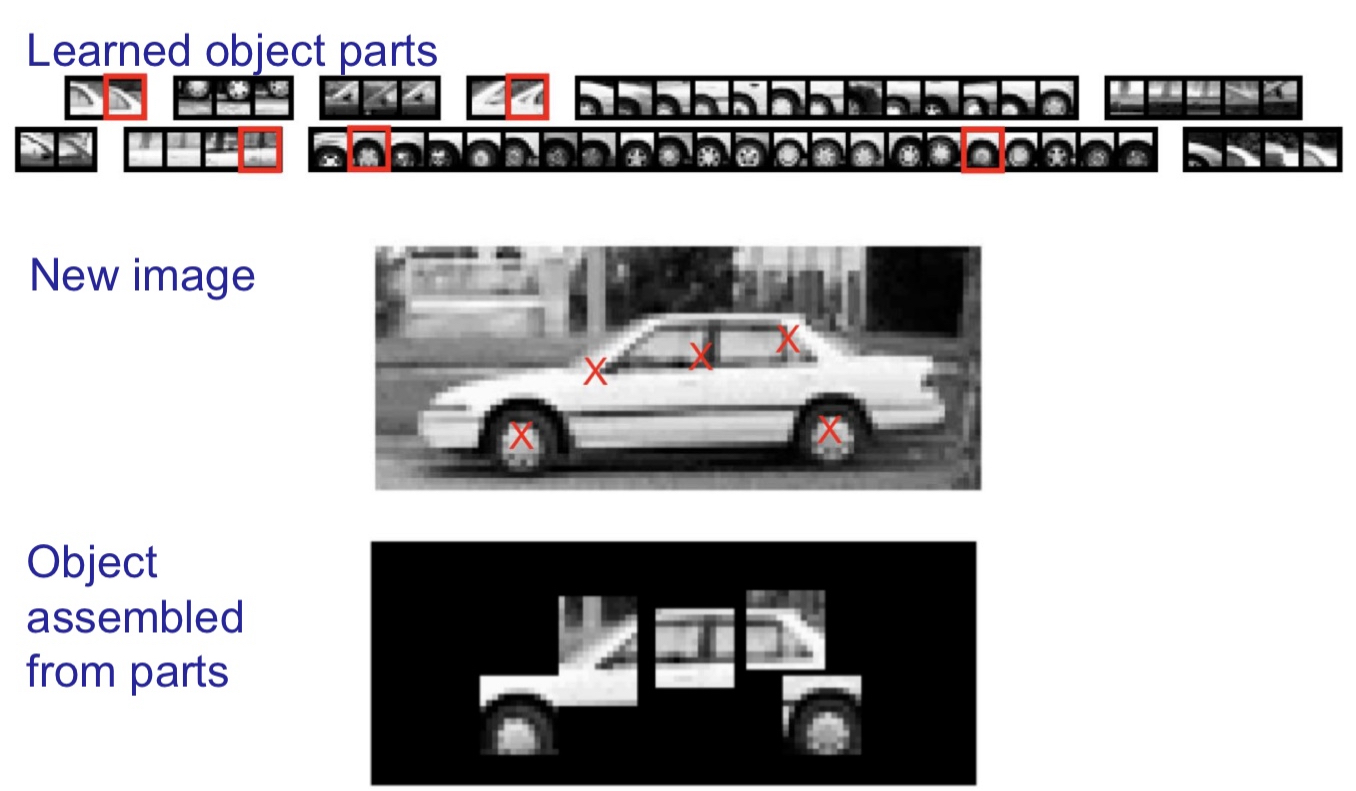
view-dependent models E.g., object pieced together from individual parts
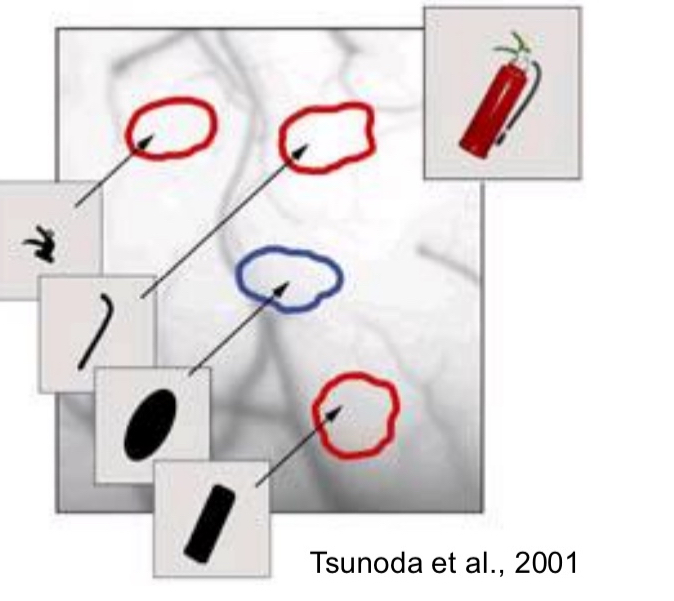
Optical imaging in view dependant models
When they showed monkey a fire extinguisher, these parts in red of IT cortex were active. The blue portion was not
Then they took the fire extinguisher apart and showed each part to the monkey individually to see which part correlated with each brain activity
shows neurons in IT are organized in feature columns that serve as basic building blocks of recognition. ➔ Perception/recognition may work through distributed processes within and across many areas
Multiple recognition committees
Perhaps more than one object recognition strategy?
When we see a normal bird we say “thats a bird” but when we see an ostrich we don’t say that a bird even though it’s also a bird. But its not a typical representative of birds
Object recognition often associates a percept with a category of objects.
Categories are discrete, hierarchically organized.
Objects are usually named at entry level.
Atypical category members ➔ subordinate level
Experts ➔ subordinate level
This shows object recognition relies on different acts of recognition
E.g., recognition at subordinate level might be difficult to perform with Biederman’s geons.
Involve different brain areas
“Special” processes may be involved in identifying individual faces
Reason 1: evolutionary/learning arguments
Reason 2: cognitive argument
Reason 3: Patients with prosopagnosia.
Reason 4: Special face area
Reason 5: Jennifer Aniston cell
Reason 1: evolutionary/learning arguments
Faces are important for us and have been for long time
Evolutionary advantage
Learning argument, we encounter faces a lot in our daily lives so we have lots of experience so its not surprising our face recognition is good because we have lots of practice
Reason 2: cognitive argument
We Identify faces all the time: we don’t think “is this a face” we think “who’s face is this”
We could identify other objects like a car, I want to get into my car not someone else’s, but we do it more with faces
Reason 3: Patients with prosopagnosia.
In right temporal cortex Patient can’t recognize faces
They know its a face, not a car, but they can’t identify who’s face it is
Reason 4: Special face area
Fusiform face area
Special area of brain that recognizes faces, this is damaged in patients with prosopagnosia
No part of brain that is only for car or trees
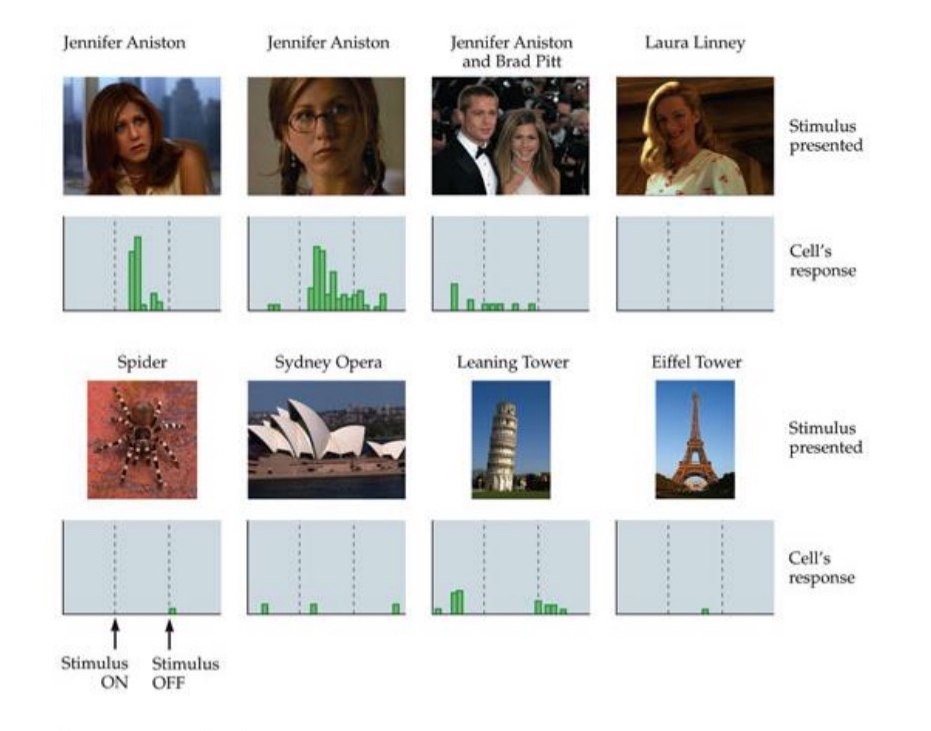
Reason 5: Jennifer Aniston cell
Cells that identify faces
Showed monkey picture of faces and objects and saw the response of the neurons action potentials
Cells recognize parts of face like nose or eye (like the fire extinguisher)
But are faces really special?
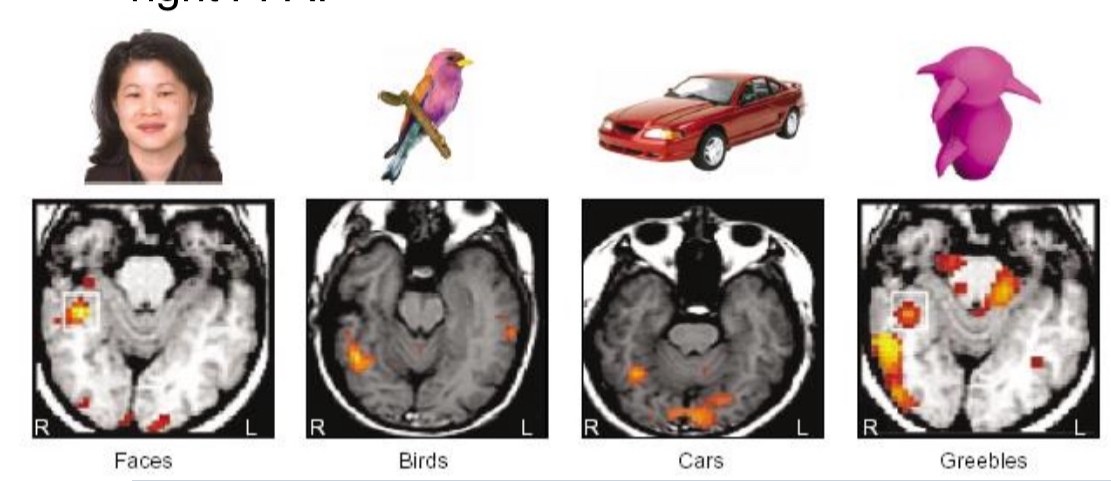
Gauthier et al. (1999): expertise in recognizing novel objects. After being trained on recognizing “greebles” subjects showed increased activity in the right FFA
People who have never seen greebles did not get activity in FFA upon seeing them.
Conclusion: expertise in recognizing objects that activate FFA. Not area of face recognition but area of visual expertise
Is the FFA an area of visual expertise? Example: Bird experts get activity in FFA for birds. Car experts get activity in FFA for cars
Line label idea:
Neural tuning functions (orientation, motion, etc.) are fixed such that neural response “means” that a stimulus with an attribute close to the neuron’s preference is present
Dynamic view:
top-down signals cause neurons to change the “meaning” of the info they carry to carry more info about the stimulus being discriminated
Higher-order areas sending top-down signals then ‘interpret’ the resulting bottom-up responses
The bottom-up and top-down of perception
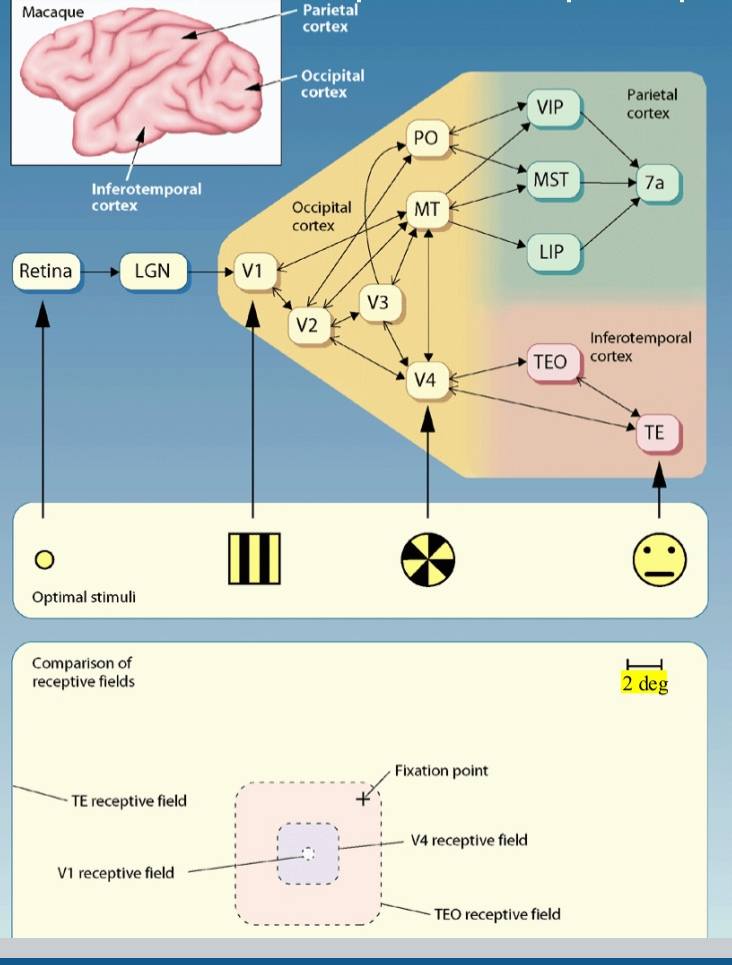
Increasingly complex stimuli drive neurons in different parts of the ‘What’ system.
(Larger receptive fields)
➔ bottom-up
“line label idea”
Object parts => whole objects <= context.
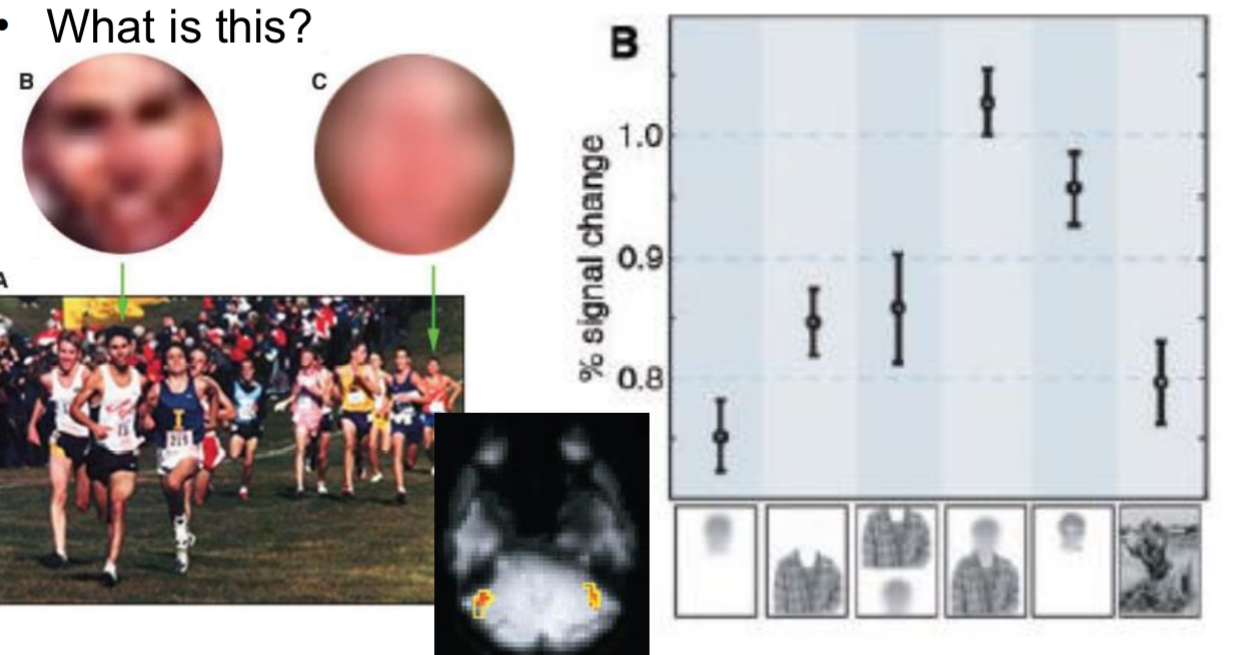
What is this?
Easy to detect face when there is blurry and some context
Blurred head no body : FFA will not respond very high when blurry
Body with face: respond a little more not much
Body and face but wrong arrangement : respond a little more not much
Head on body with right arrangement: more signal than with just head. Body is the context and is necessary for recognition
degraded faces activate fusiform face area when presented in the right context using top down processes
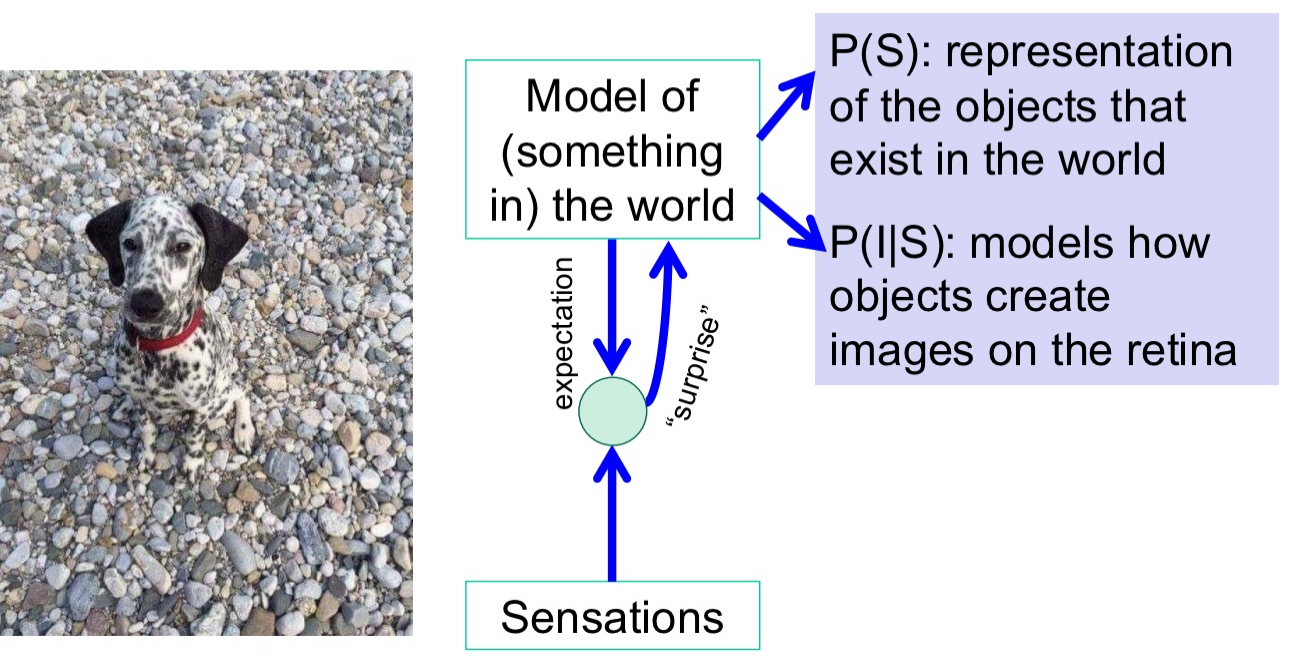
Bayesian inference:
The probability of a stimulus given an image is unknown.
Probability of things depend on context
But the reverse can be learned through experience, i.e., the probability of an image, given a stimulus.
So does the a-priori probability of stimuli (our prior knowledge that there are dogs etc.)
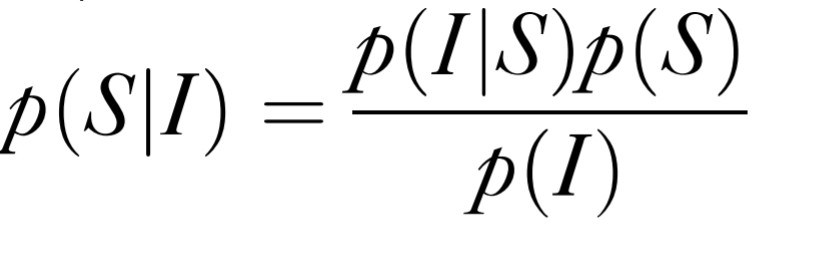
p(S|I): posterior probability
i.e., given what we see what is really out there in the world? Can’t know directly.
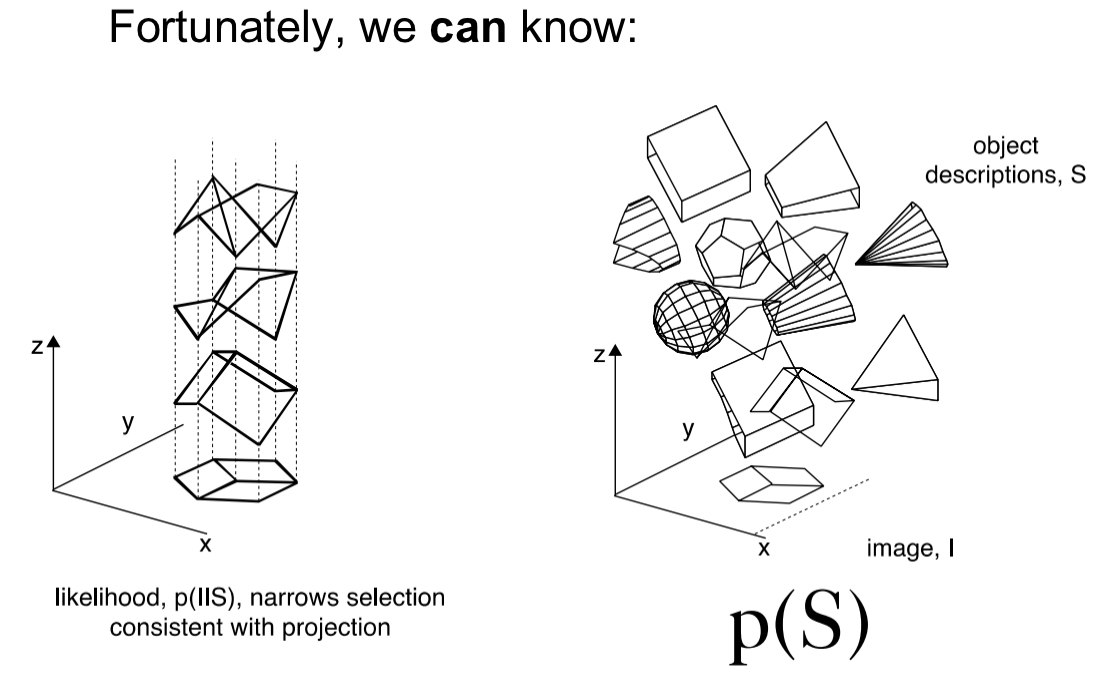
p(I|S):
given that there is a soccer ball, how likely will its projection be a Necker cube (VERY unlikely) etc.
models how objects create images on the retina
p(S)
a-priori probability of the things in the world, what we know exists and how likely.
representation of the objects that exist in the world
p(I)
a-priori probability of stimulation; usually not so important…Our image on the retina:
p(S|I) ~ p(I|S)p(S)
Combining p(I|S) and p(S)
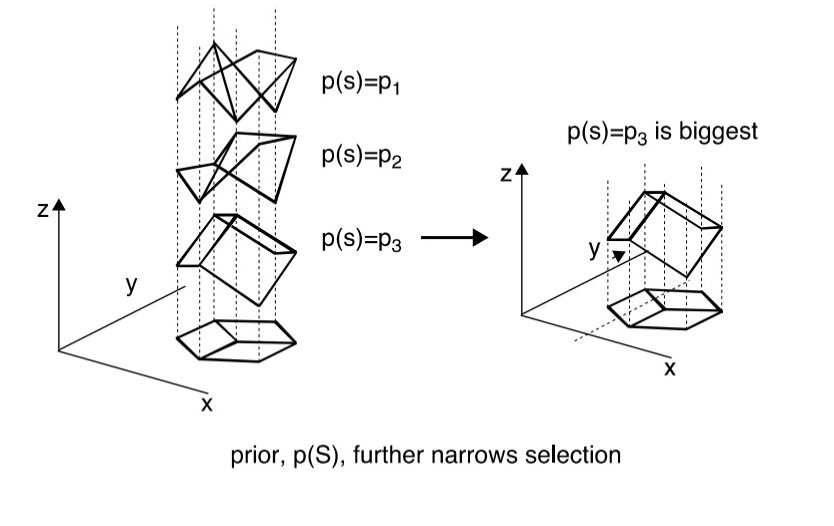
The idea that perception can be described as Bayesian inference means that perception is
governed by learned expectations.
Bayesian inference combines:
Inference
Generation
Inference:
given the image, what object do I see
Generation:
given what I know about objects what should they look like?
Important influence on computer science…
Imagine letter U, I can picture it
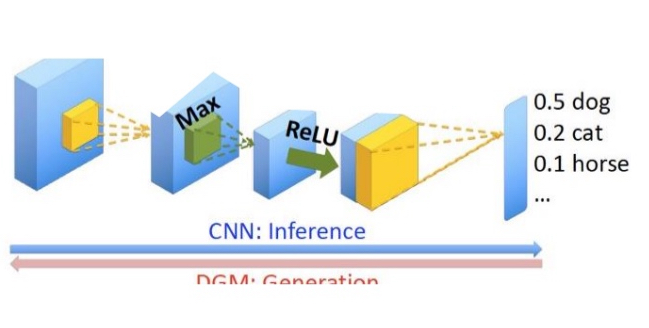
Convolutional neuralnetworks (CNNs):
image classification through bottom-up (feed-forward) processes
Problem with these is it is susceptible to noise
Deconvolutional generative
models (DGMs) create images from text
E.g., DALL-E 2
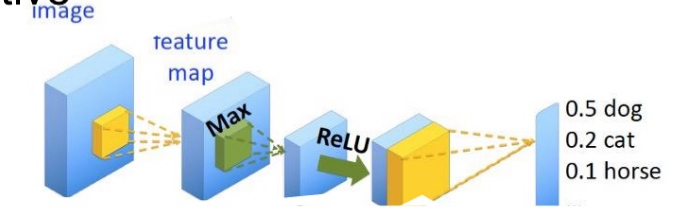
Neural networks with feedback (e.g., CNN-Fs)
combine inference and generation through bottom-up (feed-forward) and top-down (feedback) processes, respectively
Early stagepsychosis patients vs. healthy control ptcpts.
(1) Before: “Which half-tone image shows a person?”
(2) Presentation of colour images
(3) After: First test repeated more noticeable to notice the object because you saw the colour version
Patients improved more than controls!
Conclusion : [Perception can be considered a form of] controlled hallucination [that depends on the…] interaction between top-down, brain-based predictions and bottom-up sensory data.“
[This is in contrast to a] hallucination as a kind of false perception
In sum… perception uses generative models,
i.e., it generates models/representations of the world to understand how the world creates our sensations.
Model of (something in) the world
P(S)
P(IlS)
We can’t expect everything in the world just by closing our eyes and imagining it. That’s the element of surprise