content/criterion validity - class 6
1/53
Earn XP
Description and Tags
blue=lect notes, purple=textbook notes, green=chat
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
54 Terms
validity (3)
does the test measure what it was designed to measure?
the extent to which a test measures the attribute it is designed to measure
Whether the measurement we obtained from a test is accurate for the meaning of the test
Ex. A math test may be valid test for skills of 1st graders, but not 5th tests. It depends ont eh purposes we are using the test.
general points on validity (3)
1)do not accept a test’s name as an indicator of what the test measures
2)validity is not a yes/not decision
3)validity evidence: tells how well the test measures what it is intended to measure
1)do not accept a test’s name as an indictor of what the test measures
Don't take test name as evidence of what the test is meant to measure
the test name is only a vague label inferring what it's suppose to measure and NOT (validity) evidence of what it measure (in reality)
You have to look deeper beyond label to find true validity
2)validity is not a yes/not decision (3)
it (validity) comes in degrees *there is a degree/spectrum of validity
tests are valid for/it applies to a particular use and particular population
Ex. A test can be valid for highschoolers but not AS VALID for measuring math skills of college students
The test used for college students still measurea math skills but it's not as valid as when it measures math skills for high school students
it (validity) is a process: an ongoing process of gathering (valdity) evidence to ensure test scores are meaningful and accurate
Experts keep accumulating evidence that tells whether her test is accurate in measuring what it's supposed to measure
3)validity evidence (3)
*validity evidence: tells how well the test measures what it is intended to measure
*validity is the evidence for inferences made about a test score
There are 3 types of evidence: 1)construct-related, 2)criterion related and 3)content related
*Most recent standards emphasize that validity is a unitary concept that represents all of the evidence that supports the intended interpretation of a measure
With validity is separated into these convenient subcategories (e.g. construct, content etc), this use of categories does NOT imply that there are distinct forms of validity
correlation coefficents for validity VS reliability (2)
Reliability has one coefficient
Ex. Test retest
There is only ONE correlation coefficient we can obtain
But for validity there is NO single number that will indicate how valid or not valid a test is
There are many indicators of validity that are produced by the procedures we use
3 types of validity
1)content validity
b)criterion validity
c)construct validity
face validity (2)
face validity: whether a test appears to measure what it is supposed to measure (does the test(‘s face) appear valid?)
BUT not sufficent evidence of validity *not a real form of validity evidence
ex. “I care about ppl” — clearly indicative of s/o’s empathy, more valid
VS “i prefer baths to showers” — less face validity for measuring empathy
pros of a test having face validity (3)
1)induces cooperations and postive motivation before/during test administration
*If test looks relevant and appropriate, test takers are more likely to take it seriously, put in effort, and stay engaged during (test) administration
2)reduces dissatisfaction and feelings of injustice among low scorers
*Ppl who score poorly are less likely to complain that the test was “unfair” or irrelevant, since it looks like a valid measure of what it claims to measure.
3)convinces policymakers, employers and administrators to implement the test
*Policymakers, employers, administrators, or clients are more willing to accept and adopt a test if it appearsappropriate and valid. It gives the test more credibility in applied settings.
when might low face validity be useful? (3)
sometimes a test with low face validity can elicit more honest responses
For example, in personality or attitude tests, if the questions are too obviously linked to what’s being measured, people may try to fake their responses (social desirability bias).
Tests with lower face validity can hide their true purpose, which may actually produce more honest and unbiased responses
content validity *evidence (3)
content validity: evaluates how adequately the test samples the domain or the content of the construct *Degree to which the test samples the content of the construct
is the content of the test relevant and representative of the content domain?
*How representative are the items in the test representing the domain we want to test?
bc can't possible put every item that exists for s construct, so we have to sample from the domain of all possible behaviour. The representative of that sample is key to determine if there's content validity.
establishing content validity (5)
a)describe the content domain
identify boundaries of the content domain *We have to be clear about what is included vs not included in a domain (ex. Math test: boundaries=math knowledge, so if there are biology questions then the test doesn’t have content validity)
determine the structure of content boundaries
ex. For structure, there are multiple topics that are covered in a certain number of question covered in math classes, so the test of knowledge of the course should reflect the structure of the course. More questions on more imp topics than questions of topics less imp/less covered in the course
b)inspect test
c)form judgement that (*about whether) the test measures what it is supposed to measure…without gathering any external evidence
*It's judgment call from professionals that know the domain—they assess how representative the items are to the domain
When is content validity high? (2)
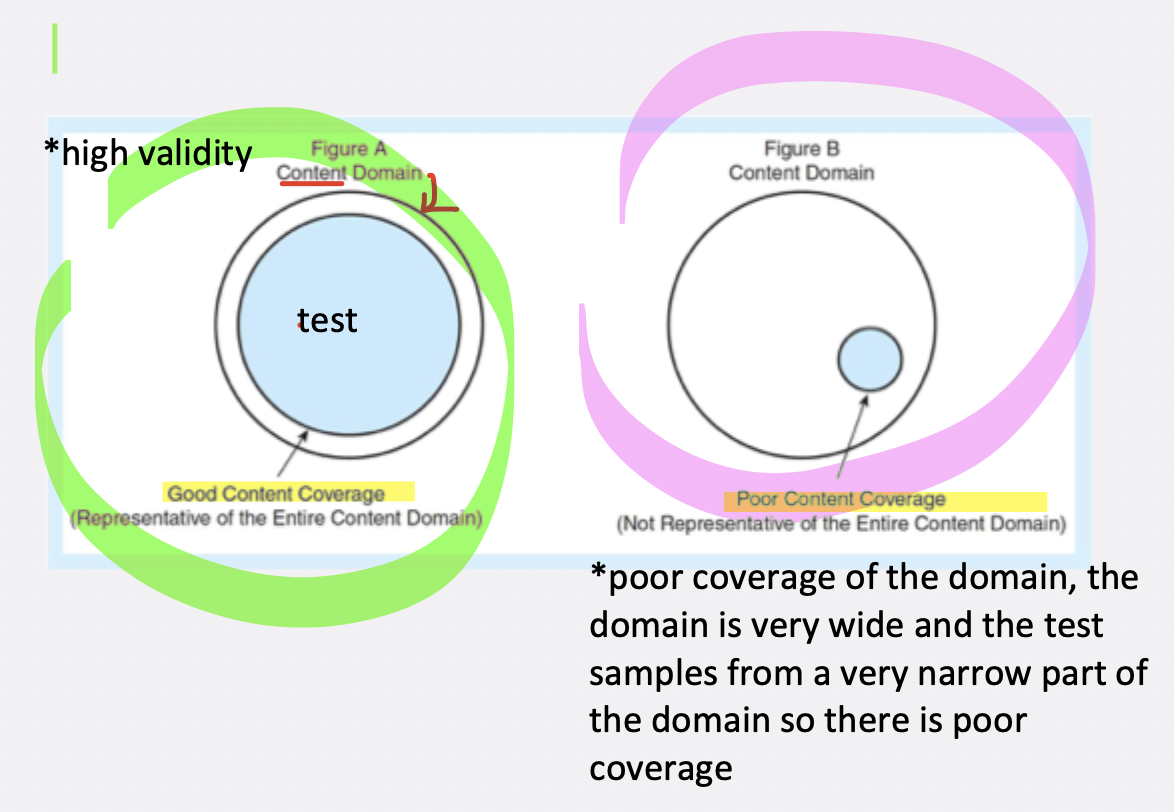
1) when the test content is representative of the tasks that define the content domain *representative of defining tasks of the content domain *there is good content coverage/high valdity: when the test content is a representative sample of the domain
there is poor coverage/low validity when the domain is very wide and the test samples from a very narrow part of the domain so there is poor coverage—not represenative of the entire content domain
2)when the items do NOT measure smth else *unrelated to content domain ex. if a psychometric test that asks you about biology, you are contaminating the psychometric test with biological elements that are irrelevant to psychometrics
evaluation of content validity (3) *limitations
not sufficient—it doesn't tell us how test scores relate to the test scores of other attributes (ex. performance)
it’s the beginning of the process of generalizing validity for a test
*due to no information about relation of test to external variables—doesn't tell us how well the test measures performance or predicts other constructs
*no info on how the test relates to external variables
criterion validity (definition in terms of prediction)
how accurately does the test predict specific variables that are considered direct indicators of the construct
Ex. Neuronticism: bc neuroticism can’t be directly measured, researchers use questionnaires or scales as indirect measures.
To determine whether these tests are valid, they look at how well the test scores predict observable behaviours that are considered direct indicators of neuroticism (e.g., anxiety reactions, mood instability, stress sensitivity). *ex. observable neuroticism-related behvaiours = criterion
Criterion validity tests whether a measure can successfully predict a relevant, observable outcome that directly reflects the construct.
Criterion validity means evaluating how well a test predicts (or corresponds) with a real-world/direct indicators/outcome (the criterion) that represents the construct.
*how do scientists establish criterion valdity
To do this, they:
1)Identify or create a “pure” behavioural indicator of neuroticism (a criterion).
2) Compare test scores to that indicator (criterion).
3)Look for a strong correlation between the scale (scores on their test) and the behavioural criterion.
If the test scores correspond well with/predict the criterion (those direct behavioural indicators(, the test shows good criterion validity.
Explain criterion validity ex. Academic aptitude tests to predict school success (construct, indirect measure, direct indicator, process)
Construct: Academic aptitude (cannot be directly observed)
Indirect measure (the test): Aptitude test scores
Direct indicator (criterion): Real school outcomes (e.g., GPA, grades, graduation rates)
Process: Since academic aptitude itself can’t be directly measured, we use test scores as an indirect measure.
We choose a “pure”/direct indicator of academic success, like semester GPA or standardized grades. *criterion = standard against which the test is compared
Then we check how well the test scores correlate with those outcomes (criterion).
A strong correlation = good criterion validity.
✅ Prediction-based criterion validity → Do high aptitude scores actually predict strong academic performance?
Explain criterion validity ex. personality tests to predict health risk behaviour
Construct: Personality traits (e.g., impulsivity, conscientiousness)
Indirect measure (the test): Personality questionnaire or scale
Direct indicator (criterion): Observable health-related behaviours, like: Smoking, excessive alcohol use, risky sexual behaviour, poor diet or lack of exercise
Process:
Since personality traits can't be directly measured, the personality test is an indirect indicator.
Researchers select a behavioural criterion that reflects the trait of interest (e.g., impulsivity predicting smoking or binge drinking).
They then assess whether people with certain test scores are more likely to engage in those behaviours. *are ppl with higher impulsivity scores more likely to smoke, engage in risky sexual behaviour, etc.
Strong correlations between test scores and real behaviours provide criterion-related evidence.
✅ Outcome-based criterion validity → Do personality test results help predict actual health risk behaviours?
criterion (def) (3)
criterion: a standard used by researchers to measure (*test) outcomes (slides)
Criterion as a benchmark: we see how well our test performs relative to the benchmark
criterion—the standard against which the test is compared—Criterion-related evidence shows how well a test matches up with a standard or "gold standard" measure (aka criterion)
criterion is the outcome or standard you ultimately care about and want to measure—something that the test is supposed to predict or match.
Ex: If you design a premarital test to predict relationship outcomes, the criterion is “marital success” (the real-world outcome you want to know about).
The test itself is just a stand-in to estimate or predict that criterion, since you can’t measure it directly at the time of testing.
selecting a criterion *2 types of criterion
when selecting a criterion, the criterion can be objective or subjective
1)objective criteria—observable and measurable
ex. for employee work performance, number of accidents, days of absence
2)subjective criteria—based on a person’s judgement
ex. supervisor’s ratings, peer ratings
E.g. if want to assess our job performance test: for criterion valdity, we first ask supervisor to rate performance of employees. then we assess validity of our new test with the supervisor's rating—the supervisor's rating as criterion
types of criterion validity (evidence)
1)concurrent
2)predictive
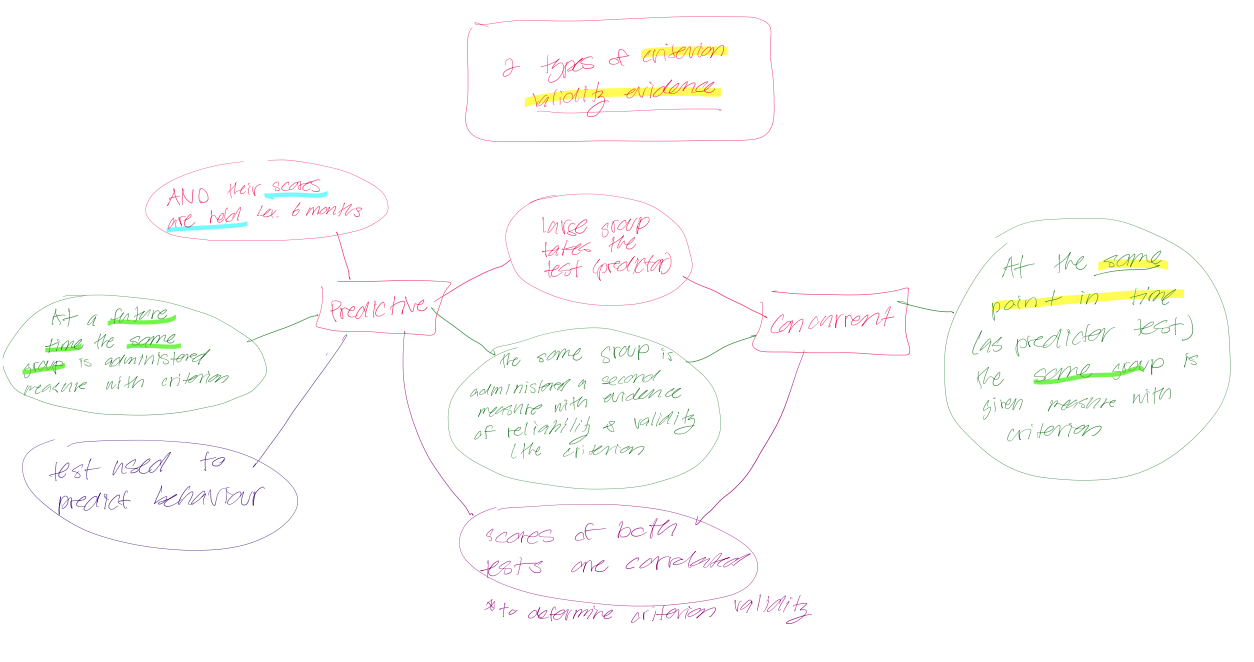
concurrent validity (def)
concurrent validity: criterion available at THE same time as test
large group takes the test (predictor)
same group takes another measure (the criterion) with evidence of reliability and validity
test are taken at the same point in time
scores are correlated
Concurrent validity evidence applies when the test and the criterion can be measured at the same time
It comes from assessment of the simultaneous relationship between the test and criterion
Ex. the relationship between learning disability and school performance—measures are taken at the same time bc the test is designed to explain why the person is now having difficulty in school
predictive validity (def)
predictive validity: criterion measure available in the future
large group takes the test (predictor) and their scores are held (e.g. for 6 months)
at future time, same group is administered a second measure with evidence of reliability and validity (the criterion)
scores are correlated
Predictive validity evidence: type of criterion validity evidence that uses test to predict behavior
Ex. SAT Critical Reading Test serves as predictive validity evidence if it accurately predicts how well high-school students will do in their college studies
predictive vs concurrent criterion validity

goal of test? possible criterion options?
goal: to determine whether the new admissions test effectively selects candidates who will be successful counsellors.
Possible Criteria (i.e., real-world indicators of success):
1)Undergraduate Grades: These could be compared with test scores.However, grades may not truly reflect future counselling performance, so this might be a weak criterion.
2)Career Outcomes. How many admitted students go on to become practising counsellors.This is a stronger, behavioural indicator of long-term success in the field.
3)Client Ratings. Feedback from clients (e.g., satisfaction, perceived helpfulness) could serve as a direct measure of counselling effectiveness. This would reflect the construct (*counsellor success)more accurately.

✅ Goal: Validate a new procrastination scale made up of self-report items.
✅ What’s needed: A behavioural criterion—a real-world indicator that reflects actual procrastination—to compare against test scores.
✅ Possible Criteria (examples discussed):
1)Professor ratings. Professors could rate whether a student typically submits assignments late. Late submissions serve as a direct behavioural indicator.
2)Task initiation behavior. Ask students whether they’ve started specific assignments. Compare scale scores between those who have started vs those who haven’t.
3)Cramming before exams. Measure how many hours of sleep someone gets the night before an exam. Assumption: less sleep may indicate last-minute studying (procrastination). BUT: Sleep loss could also be due to stress, so it may not be a clean indicator.
selection a criterion for criterion valdity (def of right criterion, 2 problems with selecting a criterion)
which is the right criterion? the “right” criterion is one that measures the same construct (or very close to it) that your test is supposed to measure — not less, not more, not something different.
if the criterion *measure measures fewer dimensions that those measured by the test→there is decreased evidence of validity based on its content bc it has underrepresented some important characterisitcs
if the criterion measures more dimensions than those meaured by the test→there is criterion contamination
criterion underepresentation (ex. math test)
Problem 1: Criterion measures too little (underrepresentation).
If the criterion only covers part of what the test measures, it weakens validity evidence. This is because important dimensions of the construct are left out.
Example: Your test measures math reasoning, algebra and geometry. But your criterion is only algebra grades.→ This ignores reasoning and geometry, so you can't fully validate the test.
→there is decreased evidence of criterion validity
criterion contamination (ex. math test)
Problem 2: Criterion measures too much (contamination).
If the criterion includes extra things your test isn’t meant to measure, the comparison gets “contaminated.” This can make your test look more or less valid than it really is.
Example: Your test measures only math reasoning. But the criterion is the overall math course grade, which includes: homework effort, attendance, participation → These extra factors distort the comparison.
criterion contamination: test may look less/more valid due to ‘contaminated’ criterion
✅ Your test may look more valid than it really is if:
The extra components in the criterion happen to correlate with your test scores by accident.
Example: Your test measures math reasoning. The criterion is overall math grade, which also includes attendance and participation. Students who are strong in reasoning may also tend to show up and participate more. → This extra overlap artificially inflates the correlation, making your test look more valid than it actually is.
✅ Your test may look less valid than it really is if:
The extra components in the criterion do not align with what your test measures—or even work against it.
Example: Your test still measures math reasoning. But some students with strong reasoning don’t participate or submit homework regularly.
→ Their grades drop for reasons unrelated to reasoning, weakening the correlation.
→ Your test appears less valid even though it may measure the construct well.

what is a validity coefficient (3)
It is the correlation between: ➝ Test scores and ➝ Criterion scores.
When assessing criterion validity, we correlate the two sets of scores and compute a correlation coefficient (r).
It shows how well the test predicts/corresponds to the criterion.
In other words, it reflects how useful or valid the test is for making statements about real-world outcomes.
what is the size of a validity coefficients (4)
Validity coefficients are rarely higher than r = 0.60 (Cronbach, 1990). *Coefficients above 0.60 are uncommon and not expected.
In applied settings, values below 0.60 can still indicate good criterion validity.
r = 0.30 to 0.40 is generally considered adequate.
Very high correlations (close to 1.0) may imply the test and criterion are too similar or measuring the exact same thing.
*A validity coefficient is just a correlation ranging from –1 to +1, but in practice we focus on whether it's strong enough to show meaningful prediction.
validity coefficient tells us the extent to which the test is valid for making statement about the criterion—shows how valid (useful) the test is for predicting or describing something about the criterion.

magnitude of validity coefficients: effects sizes for medical vs psychological tests (3)
debate on whether psycholgical tests were less valid than other disciplines (e.g. medicine)
but when they compared the validity correlations coefficients in psychological vs medical tests (see paper) it was found that psychological tests perform as well as medical tests
*psychoglical tests were NOT less valid than medical tests
take home message: psychological tests can provide information that is as valid as common medical tests

3 factors limiting validity coefficients (3)
1)range of scores—restricted range of scores decreases validity coefficients
2)unreliability of test scores—low reliability decreases validity coefficients *when test scores are less reliable, the relationship/correlation between the test and criterion (aka validity coefficient) is weaker
There is greater correction (aka adjustment for attentuation) (*needed) when reliability is lower than when reliability is higher
3)unreliability in criterion—RE: low reliability decreases validity coefficients
Restricted range (def)
Restricted range: a variable has restricted range if all scores for that variable fall very close together
(ex. GPAs of graduate student in a PHD programs tend to fall within a limited range of the scale—usually above 3.5 on a 4 point scale)
1)problem with restricted range (3)
Key Idea: Restricting the range of scores lowers the observed validity coefficient.
RE: A validity coefficient is the correlation between a test and the outcome it’s meant to predict.
But this correlation can look smaller than it truly is when the range of scores is restricted
why does restricted range decrease validity coefficient (3)
Why restriction weakens the correlation:
When you only look at a limited group (e.g., only high scorers), you remove part of the natural variation in scores (e.g. lower scorers)
With less variation (less lows and highs), the relationship between the test and the criterion appears weaker — even if the true relationship hasn't changed.
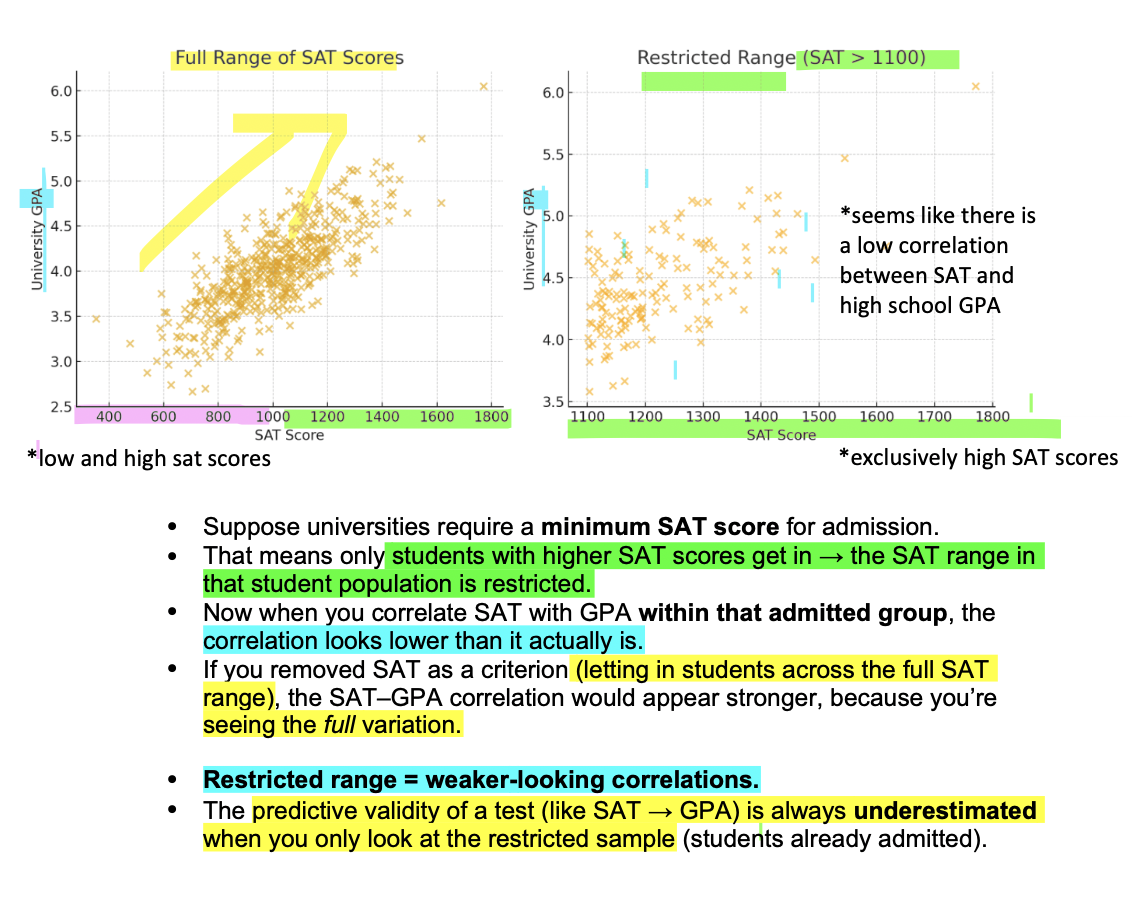
problem with restricted range (ex. SAT and GPA): (3)
Example (SAT test scores and GPA criterion):
If a university only admits students with high SAT scores, the SAT range in that group is restricted *restricted range of SAT scores
When you correlate SAT and GPA within that admitted *limited group, the correlation (validity coefficient) will look artificially low.
If students across the full SAT range were included (high and low scorers), you'd see the true, stronger relationship (btwn SAT test scores and GPA criterion)— because the full variation in scores is visible.
2)unreliability of test scores (3)
2)unreliability of test scores—low reliability decreases validity coefficients *when test scores are less reliable, the relationship/correlation between the test and criterion (aka validity coefficient) is weaker
there is potential for random error in testing—leading to unreliability of test scores
low reliability decreases validity coefficients
Measures with perfect reliability have reliability = 1
measuring unreliability of test scores (4)
to measure the unreliability of test scores affecting a correlation coefficient, we want to assess:
how much of correlation is impacted by unreliability of test scores
we do this using is correction for attenuation: correcting for unreliability in test
When test is impacted by error—it is attenuated
So the correction for attenuation is adjustment for attenuation
what do the variables r, x and y mean in this context? (4)
r: Stands for the correlation coefficient — the statistical measure of how two variables relate.
It’s always the first part of the notation (e.g., ryx, rxx′).
x: Represents the predictor variable — usually your test or assessment tool. (Ex. SAT scores, personality test, aptitude test.)
y: Represents the criterion variable — the outcome you’re trying to predict. (Ex. GPA, job performance, health outcomes)
𝑟ᵧₓ (3)
𝑟ᵧₓ (Observed validity coefficient) *which is the score we obtain from the test
This is the actual correlation you obtained between:
✅ Your test (predictor) and
✅ The criterion (outcome).
It’s “observed” because it comes from real data — but it’s affected by measurement error in your test.
𝑟ₓₓ′ (4)
𝑟ₓₓ′ (Reliability coefficient of the predictor test)
This reflects how consistent and accurate your test is. *reliability
It ranges from 0 to 1: High reliability (e.g., .90+) → scores are stable, low error AND Low reliability (e.g., .50) → scores contain a lot of error
This matters because unreliable tests underestimate validity *low reliability decreases validity coefficient
"r" = correlation, "xx′" = test correlated with itself (across time/items)
✅ So: Reliability of the predictor/test.
rᵧₓ (corrected) or rᵧₓcorr (3)
𝑟ᵧₓ₍𝚌ₒᵣᵣ₎ (Corrected / estimated validity coefficient)
This is a hypothetical estimate of what the validity would be if the test were perfectly reliable.
It adjusts the observed validity coefficent (𝑟ᵧₓ) to account for test unreliability.
It tells you: ➝ “How strong would the test–criterion relationship be if the test had no measurement error?”
“r" = correlation, "y" = criterion, "x" = predictor, "corr" = corrected for unreliability
✅ So: Estimated correlation between test and criterion if the test were perfectly reliable.
correcting for attenuation formula—unreliability in test *scores)
we correlate the observed validity coefficient (ryx) (which we obtained from our test) with the reliaibiity coefficient of predictor test (rxx’) to ge the estimated valdity coefficient (ryxcorr) *which is hypothetical
this shows how much of this correlation is impacted by the unreliability of test scores
This tells us that if we improved the test (made more reliability) how predictive it would be of the test criterion
*If we have perfect measure with reliability of 1, what would be the correlation coefficient (for validity) be?
Get estimated validity coefficient and compare the 2

interpretation of estimated validity coefficent (in correction for attentuation: correcting for unreliability in test) (4)
This estimated (corrected) validity coefficient (ryxcorr) is hypothetical (you can’t actually observe it).
It shows how much of the low observed valdity coefficient is due to test unreliability *test measurement error
If reliability improved, the test’s predictive validity would rise — but it’s capped by the true relationship between the construct and the criterion.
RE: unreliability of test scores—low reliability decreases validity coefficients *when test scores are less reliable, the relationship/correlation between the test and criterion (aka validity coefficient) is weaker
how high vs low reliability coefficient of predictor test (𝑟ₓₓ′) affects estimated validity coefficient (rᵧₓcorr )
There is greater correction (aka adjustment for attentuation) for the estimated validity coefficient (rᵧₓcorr ) when reliability coefficient of predictor text (𝑟ₓₓ′) is lower than when it is higher
Lower the reliability of test (𝑟ₓₓ′), the greater the correction for attenuation/value of the estimated validity coefficient attenuation (rᵧₓcorr )
*the lower the reliability coefficient of predictor test, the higher estimated validity coefficient (correction)

3)unreliability in criterion (3)
There is not only unreliability in test scores, but there can also be unreliability in criterion scores (e.g. both SAT test scores AND GPA criterions scores)
When we transfer criterion data from database there may be error, thus unreliability of criterion
We can correct for BOTH unreliability of test and criterion scores, in doing so, correcting for both potential sources of error

rᵧᵧ′ (3)
rᵧᵧ′ (reliability coefficient of the criterion)
r = correlation
ᵧᵧ′ = the criterion correlated with itself
Measures how consistently the outcome (*the criterion) is measured.
rᵧcₒᵣᵣₓcₒᵣᵣ (3)
rᵧcₒᵣᵣₓcₒᵣᵣ (estimated/corrected validity coefficient) for test AND criterion
How much unreliability is dragging down your observed validity.
How predictive (*or more valid) your test could be if BOTH: The test were more reliable AND the criterion were measured more accurately
This gives you a hypothetical “best-case” estimate of how valid the test could be in predicting the outcome.
correcting for attenuation (formula)—unreliability in test AND criterion (rᵧcₒᵣᵣₓcₒᵣᵣ)
we correlate the observed validity coefficient (ryx) (which we obtained from our test) with the reliaibiity coefficient of predictor test (𝑟ₓₓ′) AND reliability coefficient of criterion (rᵧᵧ′) to ge the estimated valdity coefficient (rᵧcₒᵣᵣₓcₒᵣᵣ) *which is hypothetical
this shows how much of this correlation is impacted by the unreliability of test AND criterion scores
This tells us that if we improved the test and criterion (made BOTH more reliability) how predictive the test would of the criterion (valdity coefficient)
how high vs low reliability coefficient of predictor test (𝑟ₓₓ′) and reliability coefficient of criterion (rᵧᵧ′) affects estimated validity coefficient (rᵧcₒᵣᵣₓcₒᵣᵣ)
if observed validity coefficient held constant (ryx):
the higher the reliability of predictor test (𝑟ₓₓ′) and the higher the reliability coefficient of criterion (rᵧᵧ′), the lower the (corrected) estimated validity coefficient (rᵧcₒᵣᵣₓcₒᵣᵣ)
the lower the reliability of predictor test (𝑟ₓₓ′) and the lower the reliability coefficient of criterion (rᵧᵧ′), the higher the (corrected) estimated validity coefficient (rᵧcₒᵣᵣₓcₒᵣᵣ)

estimated validity coefficient when reliability of predictor test (𝑟ₓₓ′) and the reliability coefficient of criterion (rᵧᵧ′) are the same (3)
if observed validity coefficient held constant (ryx):
but if the reliability coefficient of predictor test (𝑟ₓₓ′) and the reliability coefficient of criterion (rᵧᵧ′) are the same (e.g. both are 0.5), then the estimated validity coefficient (rᵧcₒᵣᵣₓcₒᵣᵣ) will be above 1 (e.g. 1.2)
this means that we are overcorrecting the estimated validity coefficient (rᵧcₒᵣᵣₓcₒᵣᵣ) to the point that is it not realistic
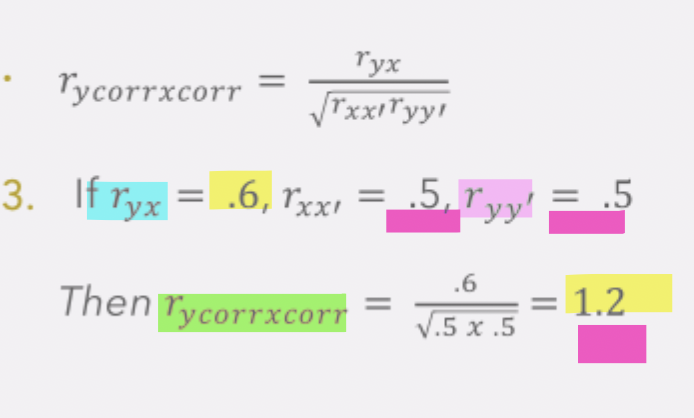
summary of criterion valdity (2 main takeaways)
1)importance of choosing appropriate criterion *to assess the validity of our test
*Be thoughtful when choosing criterion to assess validity of our test
Think if criterion reflect attribute/construct or not
2)(even) small validity coefficients can have practical utility
E.g. medical test vs psycholgical test, criterion validity of both tests is the same
So if we trust medical tests to make decisions, why don’t we trust psyc tests to do the same