Statistical Modelling
1/39
Earn XP
Description and Tags
cries
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
40 Terms
Var(AY+b)
A (sigma) AT
Least Squares Estimates
Beta_hat = (XTX)-1XTy
Fitted Values
XB_hat = X(XTX)-1XTy
Unbiased Linear Estimator for Lamba
var(aTY) >= var(LambaTeta)
iff a = X(XTX)-1XTLamba
Confidence Interval for Bj
B_hatj +- t(alpha/2) * Standard Error * sqrt(cjj)
Confidence Interval for eta0
add 1+ to the sqrt for the prediction interval
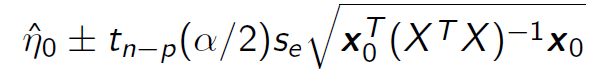
Leverage
OR for an mxn matrix => n/m
OR 1/n + (xi-x_bar)² / sum (xi-x_bar)²
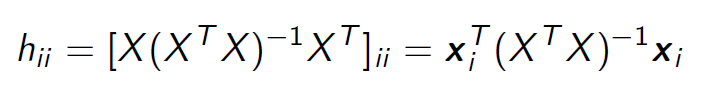
Cook’s Distance
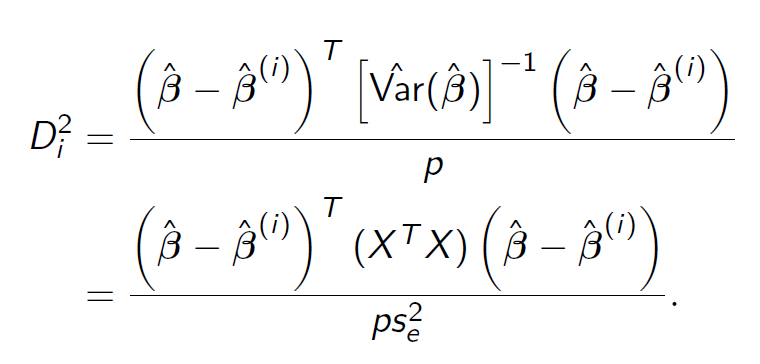
B_hat for GLS
(XTV-1X)-1XTV-1Y
Var(B_hat) for GLS
sigma² (XTV-1X)-1
Weighted Least Squares
wi = 1/vi
Box Cox Transformation
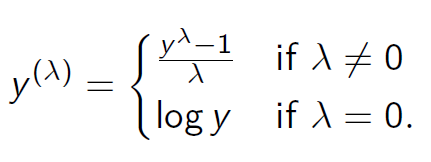
Inverse Box Cox Transformation
for lamba ≠ 0 => lamba*y + 1
for lamba = 0 => exp(y)
pii
exp(eta) / (1 + exp(eta))
eta
log(pii/(1-pii)) = logit(pii) = B0+B1x
Log-Likelihood Function
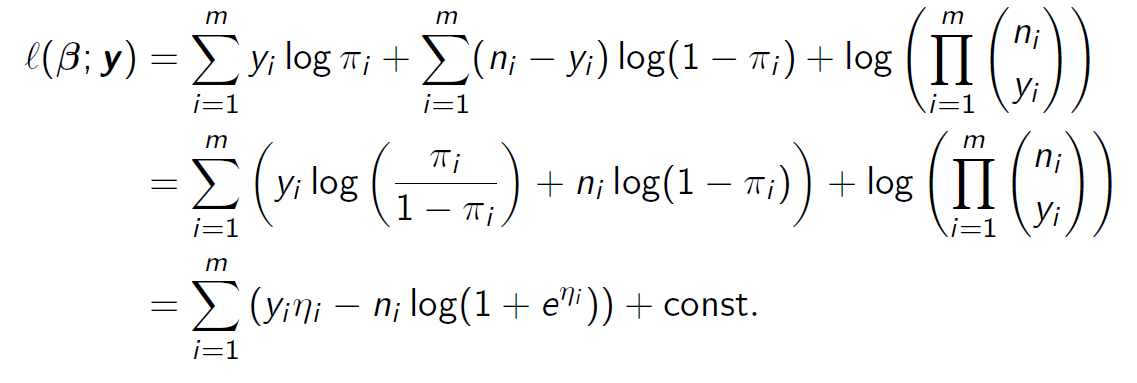
Fisher Information Matrix
Var(S(B)) = I(B)
= Var(XT(Y - mu))
= XTVar(Y) X
= XTDX
Where S(B) = XT(Y-mu)
Newton - Raphson Algorithm
B(t+1) = B(t) - [S’(B(t))]-1S(B(t))
where S’(B(t)) = partial derivative of Sj wrt Bk
= partial derivate squared L/BjBk
Fisher Scoring
B(t+1) = B(t) + [I(B(t))]-1 + S(B(t))
= B(t) + (XTD(t)X)-1 XT(y-mu(t))
where mu(t) = nipii and D(t) = diag(nipii(1-pii))
B(0)
B(0) = (XTX)-1XTv
where v = log[(yi + 0.5)/(ni - yi + 0.5)]
Confidence Interval for Bj
B_hatj +- z(alpha/2) sqrt( [I(B)-1]jj )
Log Likelihood Ratio Test Statistic
G² = 2( L(B_hat) - L(B_hat0) )
Null Deviance
2 ( L(Saturated) - L(Null) )
Residual Deviance
2 ( L(Saturated) - L(Residual) )
Overdispersion
Var(Yi) > nipii (1-pii)
Underdispersed => Var(Yi) < nipii (1-pii)
Properly dispersed/fine => Var(Yi) = nipii (1-pii)
Log Odds Ratio
Bi = log ( (pi2/(1-pi2)) / (pi1/(1-pi1)) )
= logit(pi2) - logit(pi1) = B2 - B1
Increasing xi by 1 - Poisson
Y’i = exp(B_hat1) * Yi
Predict Y for Poisson Regression
Y = exp(B0 + B1x)
Predict Y for Poisson Rate Regression
Y = offset * exp(B0 + B1x)
Root Mean Square Error (RMSE)
sqrt( 1/n + sum( yi - f(xi) ) ² )
R²
cor( y , f(x) )²
= (TSS-RSS) / TSS = 1 - RSS/Tss
= 1 - sum( yi - f(x) )² / sum ( yi - y_bar )²
Adjusted R²
1 - ( RSS / (n-k-1) ) / (TSS / (n-1) )
Cp
1/n (RSS + 2k(sigma)²)
Mallow’s C’p
RSS/(sigma)² + 2k - n
AIC (Akaike Information Criterion)
2k - 2 ln (L)
AICc (Akaike Information Criterion Corrected)
AIC + [ 2k (k+1) / (n - k - 1) ]
BIC (Bayesian Information Criterion)
ln(n)k - 2 ln(L)
Cross Validation Estimate
sum [ nk /n MSEk]
where MSEk = (yi - y_hati)² / nk
Mean Absolute Error
1/n sum |yi - f(xi)|
Point Prediction
B0 + B1x + …