Ch 1 - Psychometrics and the Importance of Psychological Measurement (Furr)
1/82
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
83 Terms
When a patient responds to a psychopathology assessment, when a student completes a test of cognitive ability or academic aptitude, or when a job applicant fills out a personality inventory, there is an attempt to
measure some type of psychological characteristic.
Without a solid understanding of the basic principles of psychological measurement, test users risk misinterpreting or misusing the information derived from psychological tests. Such misinterpretation or misuse might
harm patients, students, clients, employees, and applicants, and it can lead to lawsuits for the test user.
Ppsychologists, educators, and others use psychological tests as instruments to measure observable events in the physical world. In the behavioral sciences, these observable events are
typically some kind of behavior
Behavioral measurement is usually conducted for two purposes:
- Sometimes, psychologists measure a behavior because they are interested in that specific behavior in its own right.
- Much more commonly, however, behavioral scientists observe human behavior as a way of assessing unobservable psychological attributes such as intelligence, depression, knowledge, aptitude, extroversion, or ability.
In most but not all cases, psychologists develop psychological tests as a way to
sample the behavior that they think reflects the underlying psychological attribute.
Unfortunately, there is no known way to observe directly working memory—we cannot directly "see" memory inside a person's head. Therefore, we must
look for something that we can see (e.g., some type of behavior) and that could indicate how much working memory someone has. For example, we might ask the students to repeat a series of numbers presented to them rapidly.
Inference from an observable behavior to an unobservable psychological attribute: .
That is, we assume that the particular behavior that we observe reflects or reveals working memory
If an inference is reasonable, then we would say that
our interpretation of the behavior has a degree of validity.
Although validity is a matter of degree, if the scores from a measure seem to be actually measuring the mental state or mental process that we think they are measuring, then we say that our interpretation of scores on the measure is valid.
In the behavioral sciences, we often make an inference from an observable behavior to an unobservable psychological attribute. Therefore, measurement in psychology often, but not always, involves
some type of THEORY linking a psychological characteristic, process, or state to an observable behavior that is thought to reflect differences in that psychological attribute.
Psychologists, educators, and other social scientists often use theoretical concepts such as working memory to explain differences in people's behavior. Psychologists refer to these theoretical concepts as
hypothetical constructs or latent variables.
They are theoretical psychological characteristics, attributes, processes, or states that cannot be directly observed, and they include things such as knowledge, intelligence, self-esteem, attitudes, hunger, memory, personality traits, depression, and attention.
The operations or procedures that we use to measure hypothetical constructs, or for that matter to measure anything, are called
operational definitions.
All sciences rely on unobservable constructs to some degree, and they all
measure those constructs by measuring some observable events or behaviors.
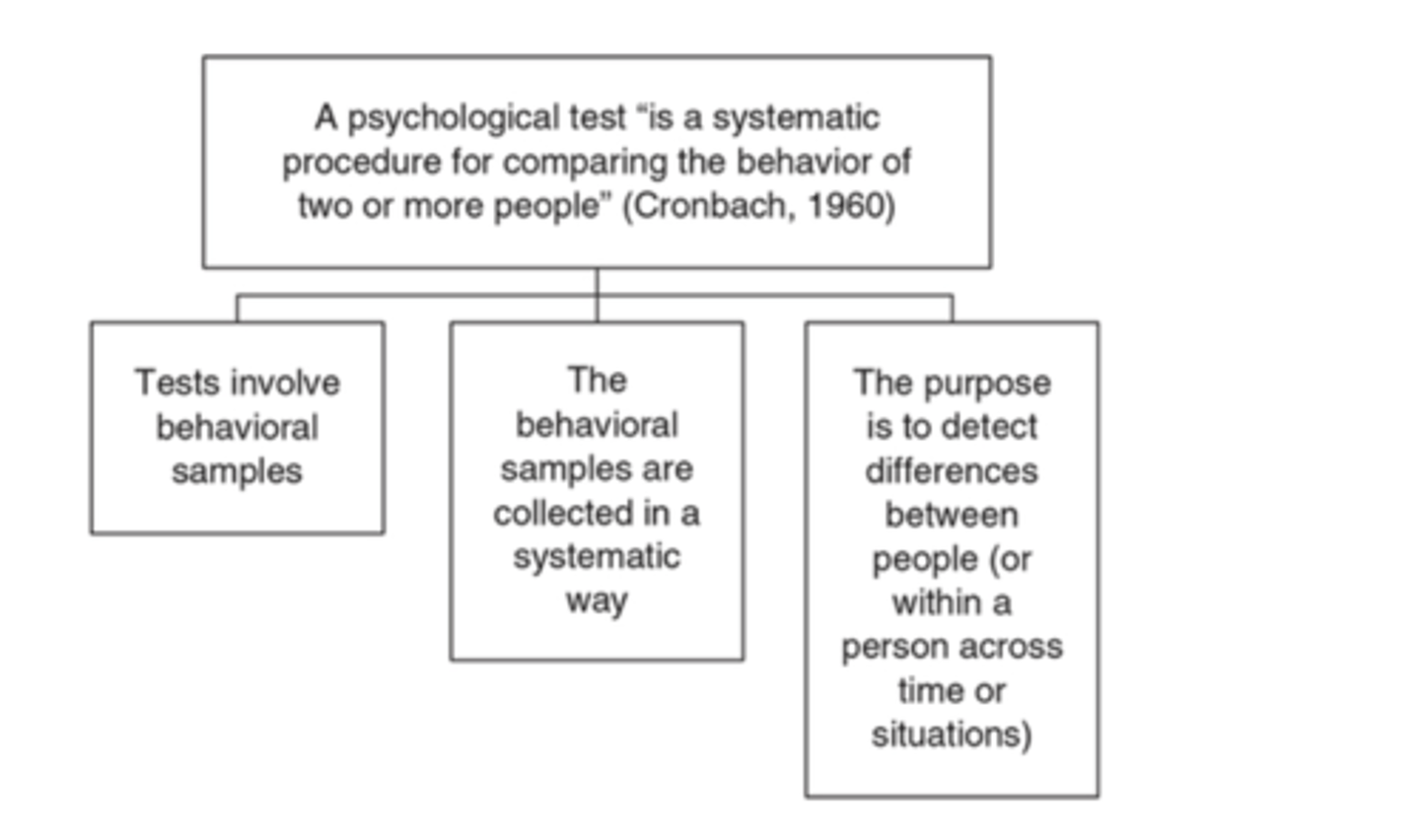
According to Cronbach (1960), a psychological test is
"a systematic procedure for comparing the behavior of two or more people"
Cronbach (1960)'s definition of a test includes three important components:
(1) tests involve behavioral samples of some kind
(2) the behavioral samples must be collected in some systematic (i.e., clear and standardized) way
(3) the purpose of the tests is to detect differences between people.
Cronbach (1960)'s test definition table
One appealing feature of Cronbach's test definition is
its generality.
The idea of a test is sometimes limited to paper-and-pencil tests, but psychological tests can come in many forms.
The generality of Cronbach's definition also extends to the type of information produced by tests:
- Some tests produce numbers that represent the amount of some psychological attribute possessed by a person
- Other tests produce categorical data— people who take the test can be sorted into groups based on their responses to test items
Another extremely important feature of Cronbach's definition concerns the general purpose of psychological tests. Specifically, tests must be capable of
comparing the behavior of different people (interindividual differences) or the behavior of the same individuals at different points in time or under different circumstances (intraindividual differences).
The purpose of measurement in psychology is
to identify and, if possible, quantify such interindividual or intraindividual differences.
Some Key Ways in Which Psychological Tests Differ (table)
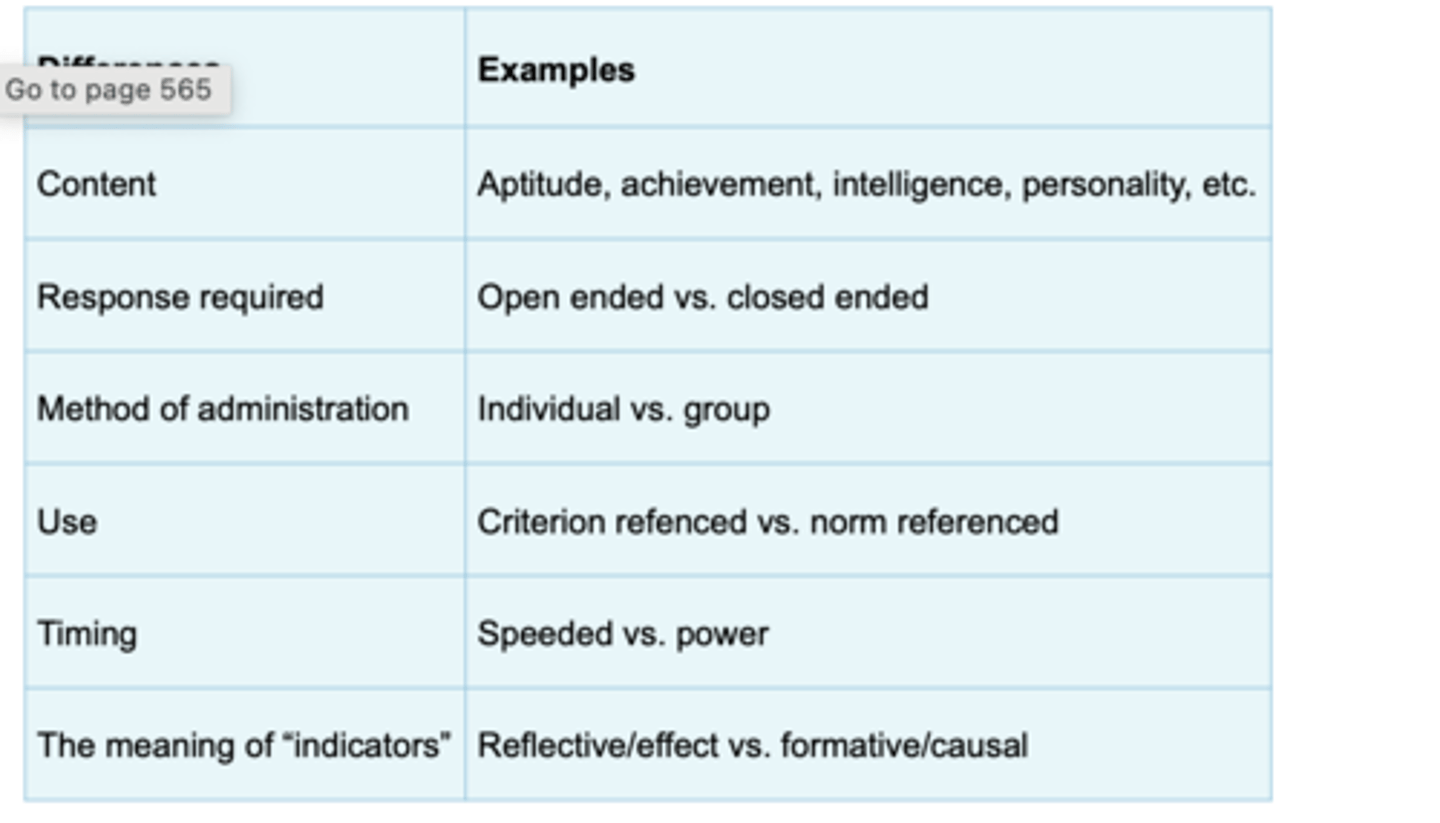
Tests can vary in:
- content
- response required
- method of administration
- use
- timing
- the meaning of "indicators"
Tests can vary in content:
There are achievement tests, aptitude tests, intelligence tests, personality tests, attitude surveys, and so on.
Tests also vary with regard to the type of response required:
There are open-ended tests, in which people can answer test questions by saying anything they want in response to the questions on the test, and there are closed-ended tests, which require people to answer questions by choosing among alternative answers provided in the test.
Tests also vary according to the methods used to administer them:
Some are individually administered, in which one person administers the test to one test taker at a time. Other tests can be administered to multiple people all at the same time.
Another major distinction concerns the intended purpose of test scores. Psychological tests are often categorized as either
criterion referenced (also called domain referenced) or norm referenced
Criterion-referenced tests are most often seen in settings in which
a decision must be made about a person's skill level.
In those settings, a cutoff test score is established as a criterion, and it is used to sort people into two groups: (1) those whose performance exceeds the criterion score and (2) those whose performance does not.
Norm-referenced tests are usually used to
understand how a person compares with other people. This is done by comparing a person’s test score with scores from a reference sample or normative sample .
A reference sample is typically a sample of people who complete a test, and the sample is thought to be representative of some broader population of people. Thus, a person's test score can be compared with the scores obtained from the people in the reference sample, telling us, for example,
whether the individual has a higher or lower score than the "average person" (and how much higher or lower) in the relevant population
Scores on norm-referenced tests can be valuable when
the reference sample is representative of some population, when the relevant population is well defined, and when the person being tested is a member of the relevant population.
In principle, none of these issues arise when evaluating a score on a criterion-referenced test.
In practice, the distinction between norm-referenced tests and criterion-referenced tests is often blurred. Criterion-referenced tests are always
"normed" in some sense. That is, criterion cutoff scores are not determined at random. The cutoff score will be associated with a decision criterion based on some standard or expected level of performance of people who might take the test.
The distinction between criterion- and norm-referenced tests is further blurred when scores from norm-referenced tests are used as cutoff scores.
Despite the problems with the distinction between criterion- referenced tests and norm-referenced tests, there are slightly different
methods used to assess the quality of criterion-referenced and norm-referenced tests
Yet another common distinction is between speeded tests and
power tests
Speeded tests are
time-limited tests. In general, people who take a speeded test are not expected to complete the entire test in the allotted time.
Speeded tests are scored by counting the number of questions answered in the allotted time period. It is assumed that there is a high probability that each question will be answered correctly; each of the questions on a speeded test should be of comparable difficulty.
In contrast, power tests are
not time limited, and test takers are expected to answer all the test questions. Often, power tests are scored also by counting the number of correct answers made on the test.
Test items must range in difficulty if scores on these tests are to be used to discriminate among people with regard to the psychological attribute of interest.
As is the case with the distinction between criterion-referenced tests and norm-referenced tests, slightly different methods are used to
assess the quality of speeded and power tests
It is worth noting that most of the procedures outlined in this book are relevant mainly for scores based on what are called reflective (or effect) indicators. For example,
scores on intelligence or personality tests are of this kind. A person's responses on an intelligence test are typically seen as being caused by his or her actual level of intelligence.
Such tests are very common in psychology.
There are, however, different types of scores that are based on what are called formative (or causal) indicators.
Socioeconomic status (SES) is the classic example.
You could quantify a person's SES by quantitatively combining "indicators" such as her income, education level, and occupational status. In this case, the indicators are not viewed as being "caused" by the person's SES. Instead, the indicators of SES are, in part, exactly what define SES.
A brief note concerning terminology: Several different terms are often used as synonyms for the word test. The words
measure, instrument, scale, inventory, battery, schedule, and assessment have all been used in different contexts and by different authors as synonyms for the word test.
The word battery will refer to
bundled tests, which are tests that are intended to be administered together but are not necessarily designed to measure a single psychological attribute.
The word measure can be used as
- a verb, as in “The BDI was designed to measure depression.”
- but it is also often used as a noun, as in “The BDI is a good measure of depression.” This book will use both forms of the term and rely on the context to clarify its meaning.
Just as psychological tests are designed to measure psychological attributes of people (e.g., anxiety, intelligence), psychometrics is
the science concerned with evaluating the attributes of psychological tests.
Three of the attributes of psychological tests will be of particular interest:
(1) the type of information (in most cases, scores) generated by the use of psychological tests
(2) the reliability of data from psychological tests
(3) issues concerning the validity of data obtained from psychological tests.
Note that just as psychological attributes of people (e.g., anxiety) are most often conceptualized as hypothetical constructs (i.e., abstract theoretical attributes of the mind), psychological tests also have
attributes that are represented by theoretical concepts, such as validity or reliability.
Just as psychological tests are about theoretical attributes of people, psychometrics is about
theoretical attributes of psychological tests.
Just as psychological attributes of people are unobservable and must be measured, psychometric attributes of tests are
also unobservable and must be estimated.
Psychometrics is about the procedures used to estimate and evaluate the attributes of tests.
The field of psychometrics has been built on two key foundations. One foundation is
the practice of psychological testing and measurement.
The practice of using formal tests (of some kind) to assess individuals' abilities goes back
2,000 or perhaps even 4,000 years in China, as applicants for governmental positions completed various exams.
Psychological measurement increased in the 19th century as psychological science emerged and
as researchers began systematically measuring various qualities and responses of individuals in experimental studies.
The practice of psychological measurement increased even more dramatically in the 20th century, with
the development of early intelligence tests and early personality inventories
Over the course of the past 100+ years, the number, kinds, and applications of psychological tests have exploded. With such development comes the desire to
create high-quality tests and to evaluate and improve tests. This desire inspired the development of psychometrics as the body of concepts and tools to do this.
A second and related historical foundation is the development of particular statistical concepts and procedures. Starting in the 19th century, scholars began to
develop ways of understanding and working with the types of quantitative information that are produced by psychological tests.
Among the early pioneers of psychometric work are scholars such as
Charles Spearman, Karl Pearson, and Francis Galton, all making key contributions in the late 1800s and early 1900s.
Galton in particular is sometimes considered
the founding father of modern psychometrics. He had diverse scholarly interests, including—it should be acknowledged—an advocacy for the now-rejected theory of eugenics.
It is Galton's, Spearman's, and Pearson's important conceptual and technical innovations that are relevant for our discussion. In fact, you might already be familiar with some of these—
the standard deviation and the correlation coefficient, factor analysis, the use of the normal distribution (or "bell curve") to represent many human characteristics, and the use of sampling for the purpose of identifying and treating measurement error.
These crucial statistical concepts and tools were adopted quickly and sometimes developed explicitly in order to make sense out of the numerical information gathered through the use of psychological tests
Based on the application of these new statistical tools to the evaluation of psychological tests,
the field of psychometrics truly came into its own by the 1930s and 1940s.
By this time, many tenets of what is now known as classical test theory (CTT) had been articulated —providing the foundation for the most widely known perspective on test scores and test attributes. Somewhat later (1970s), CTT was expanded into generalizability theory by Lee Cronbach and his colleagues. At approximately the same time (or a bit earlier, in the 1950s and 1960s), an alternative to CTT was emerging, leading to what's now known as
item response theory (IRT). Also in the 1950s, the crucial concept of test validity was undergoing robust development and articulation, with additional important reconceptualizations in the 1990s.
Over the past few decades, the field of psychometrics has expanded in all of these directions. CTT itself has evolved, as, for example, researchers recognize the limits of commonly used indices of reliability. IRT has enjoyed increased attention as well, with the development of various models and applications. Moreover, as statistical tools such as structural equation modeling have evolved,
researchers have discovered ways of using those tools to conceptualize and examine key psychometric concepts.
In sum, psychometrics, as a scientific discipline, is relatively young but
has enjoyed a quick evolution and widespread application.
Despite the many similarities among all sciences, measurement in the behavioral sciences has special challenges that do not exist or are greatly reduced in the physical sciences (see Figure 1.2). These challenges affect our confidence in our understanding and interpretation of behavioral observations. These challenges are:
- complexity of concepts
- participant reactivity
- observer expectancy/bias
- composite scores
- score sensitivity
- (lack of) awareness of psychometrics
One of these challenges is related to the complexity of psychological phenomena; notions such as intelligence, self-esteem, anxiety, depression, and so on may have many different aspects to them. Thus, one key challenge is
to identify and capture the important aspects of these types of human psychological attributes in a single number or score.
Given the richness of human psychology and the extraordinary variety of ways in which people differ from each other, no single number or set of numbers would fully represent any individual in some general or holistic sense. We cannot reduce someone's "total psychology" to a single number any more than we can reduce their "total physicality" to a single number.
However, it might indeed be possible to quantify something like creativity, or at least specific aspects or dimensions of creativity. Again, no one seriously attempts to quantify an individual's "total physicality"; however, we do
quantify specific physical dimensions such as height, weight, and blood pressure.
In a similar way, psychologists and others attempt to quantify specific psychological dimensions such as verbal intelligence, self-esteem (or specific forms of self-esteem), achievement motivation, attentional control, and so on.
A key challenge is to make sure that the way in which we quantify such specific psychological dimensions does indeed reflect
the complexity of those dimensions adequately. If psychologists can identify specific, coherent dimensions along which people differ, then they may be able to quantify those differences quite precisely.
Participant reactivity is a second difficult challenge. Because, in most cases, psychologists are measuring psychological characteristics of people who are conscious and generally know that they are being measured, the act of measurement can
itself influence the psychological state or process being measured.
People's knowledge that they are being observed or assessed can cause them to react in ways that obscure the meaning of their behavior.
Participant reactivity can take many forms. In research situations, some participants may try to
figure out the researcher’s purpose for a study, changing their behavior to accommodate the researcher (demand characteristics).
In both research and applied measurement situations, some people might
become apprehensive, others might change their behavior to try to impress the person doing the measurement (social desirability), and still others might even change their behavior to convey a poor impression to the person doing the measurement (malingering).
In each case, the validity and meaning of the measure is compromised —the person’s “true” psychological characteristic is obscured by a temporary motivation or state that is a reaction to the very act of being measured.
Yet another challenge to psychological measurement is that, in the behavioral sciences, the people collecting the behavioral data (observing the behavior, scoring a test, interpreting a verbal response, etc.) can
bring their own biases and expectations to their task.
Measurement quality is compromised when these factors distort the observations that are made.
Expectation and bias effects can be difficult to detect. In most cases, we can trust that people who collect behavioral data are not consciously cheating; however,
even subtle, unintended biases can have effects.
Observer (or scorer) bias can occur in the physical sciences, but it is less likely to occur because
physical scientists rely more heavily than do social scientists on mechanical devices as data collection agents.
The measures used in the behavioral sciences tend to differ from those used by physical scientists in a fourth important respect as well. Psychologists tend to rely on
composite scores when measuring psychological attributes. Many of the tests used by psychologists involve a series of questions, all of which are intended to measure a specific psychological attribute or process.
It is common practice to score each question and then to sum or otherwise combine the items’ scores to create a total or composite score. The composite score represents the final measure of the relevant construct—for example, an extroversion score or a “knowledge of algebra” score.
A fifth challenge to psychological measurement is score sensitivity. Score sensitivity refers to
a measure's ability to discriminate between meaningful amounts of the dimension being measured.
A psychologist may find that a particular procedure for measuring a psychological attribute or process may not be sensitive enough to discriminate between the real differences that exist in the attribute or process.
For psychologists, the sensitivity problem is exacerbated because we might not anticipate
the magnitude of meaningful differences associated with the mental attributes being measured. Social scientists may be unaware of the scale sensitivity issue even after they have collected their measurements.
A final challenge to mention at this point is an apparent lack of awareness of important psychometric information. In the behavioral sciences, particularly in the application of behavioral science, psychological measurement is often a social or cultural activity. Unfortunately, such measurement often seems to be conducted with
little or no regard for the psychometric quality of the tests.
The ability to identify and characterize psychological differences is
at the heart of all psychological measurement, and it is the foundation of all methods used to evaluate tests.
The purpose of measurement in psychology is to
identify and quantify the psychological differences that exist between people, over time, or across conditions.
These psychological differences contribute to differences in test scores and are the basis of all psychometric information.
Even when a practicing psychologist, educator, or consultant makes a decision about a single person based on that person's test score, the meaning and quality of the person's score can be understood only
in the context of the test's ability to detect differences among people.
All measures in psychology require that we obtain behavioral samples of some kind. Behavioral samples might include scores on a paper-and-pencil test, written or oral responses to questions, or records based on behavioral observations. Useful psychometric information can be obtained only if
people differ with respect to the behavior that is sampled.
If a behavioral sampling procedure produces scores that differ between people (or that differ across time or condition), then the psychometric properties of those scores can be assessed.
If we think that a particular test is a measure of a particular psychological attribute, then we must be able to argue that
differences in the test scores are related to differences in the relevant underlying psychological attribute.
Eg. before firmly concluding that a procedure is indeed interpretable as a measure of visual attention, the psychologist must accumulate evidence that there is an association between individuals' scores on the test and their "true" levels of visual attention. The process by which the psychologist accumulates this evidence is called
the validation process
There is a misunderstanding that psychometrics, or even a general concern about psychological measurement, is relevant only to
those psychologists who study a certain set of phenomena that are sometimes called "individual difference" variables.
It is true that psychometrics evolved largely in the context of certain areas of research, such as intelligence testing, that would be considered part of "differential" psychology. For example, Galton was primarily interested in
the ways in which people differ from each other—some people are taller than others, some are smarter than others, some are more attractive than others, and some are more aggressive than others. He was interested in understanding the magnitude of those types of differences, the causes of such differences, and the consequences of such differences.
The approach to psychology that was taken by Galton, Spearman, and others became known as
differential psychology, the study of individual differences.
There is no hard-and-fast definition or classification of what constitutes differential psychology, but it is often seen to include intelligence, aptitude, and personality. This is usually seen as contrasting with experimental psychology, which focused mainly on the average person instead of the differences among people.
Perhaps because Galton is closely associated with both psychometrics and differential psychology, people sometimes view psychometrics as an issue that concerns only those who study "individual differences" topics such as intelligence, ability/aptitude, or personality. Some seem to believe that psychometrics is not a concern for
those who take a more experimental approach to human behavior. This belief is incorrect. This belief is incorrect.
Psychometric issues are by no means limited to so-called differential psychology. Rather, all psychologists, whatever their specific area of research or practice, must be concerned with
measuring behavior and psychological attributes. Therefore, they should all understand the problems associated with measuring behavior and psychological attributes, and these problems are the subject matter of psychometrics.