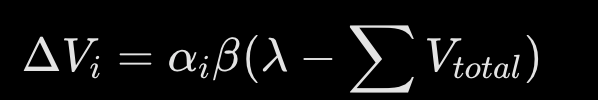Introduction to Reinforcement Learning
1/47
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
48 Terms
Supervised learning
Dataset is fully provided with explicit input-to-output mappings (full feedback).
Unsupervised Learning
Data is given without feedback labels (identifying hidden clusters or structures).
Reinforcement Learning
Agent lacks pre-existing dataset. It actively collects data through environmental interactions. Feedback is partial and scalar (agent learns what reward it achieves for a chosen action but never receives the ground-truth optimal action).
Multi-Armed Bandit
One-step decision-making problem. Isolates core challenge of data collection and exploration/exploitation dilemma without burden of temporal credit assignment.
Sequential Reinforcement Learning
Multi-step dependencies where action influences immediate reward and next environment state. Creates temporal credit assignment problem.
Action value
Q(a) = E[r|a]
Incremental Mean Update rule
Avoids massive memory storage overhead.
Qn = Qn-1 + (1/n) * [rn - Qn-1]
Learning Rate Update
Non-stationary environments (reward distributions shift over time).
Q(a) ← Q(a) + α * [r-Q(a)]
ε-Greedy (random perturbation)
Acts greedily with probability 1-ε and selects random action with probability ε. Maximize performance by decaying ε over time.
Optimistic Initialization
Initializes action-value estimates to unrealistic high valuation (ψ). Selects actions greedily and forces immediate exploration (unchosen actions will always have higher value placeholders than recent).
Upper Confidence Bound (UCB)
Optimism in the face of uncertainty by standard deviation/error bounds.
At = argmaxa [Qt(a) + c * sqr(ln(t)/Nt(a))]
![<p>Optimism in the face of uncertainty by standard deviation/error bounds.<br>A<sub>t</sub> = argmax<sub>a</sub> [Q<sub>t</sub>(a) + c * sqr(ln(t)/N<sub>t</sub>(a))] </p>](https://assets.knowt.com/user-attachments/627f722c-34ee-408b-9219-9c8882bfe9f1.png)
Markov Decision Processes (MDPs)
Sequential decision-making.
State Space (S)
Action Space (A)
Transition Probability Function (p(s’|s,a))
Reward Function (r(s,a,s’))
Discount Factor (γ = [0,1])
State Space (S)
All valid environmental situations. States can be atomic (distinct elements with no crossover) or factorized (represented as vector/matrix allowing for generalization).
Action Space (A)
Set of choices available to an agent.
Transition Probability Function (p(s’|s,a))
Dynamics defining the environment’s response.
Reward Function (r(s,a,s’))
Scalar feedback loop optimizing specific behaviors.
Discount Factor (γ = [0,1])
Determines the current valuation of feature rewards.
Curse of dimensionality
Cardinality (number of elements in a set) of a state space grows exponentially with dimensionality.
Fundamental Bellman Relations
State values: vπ(s)
State-action values: qπ (s,a)
Policy π(a|s)
Complete recursive equation for state values
vπ (s) = Σa π(a|s) Σs’ p(s’|s,a) [r(s,a,s’) + γ vπ(s’)]
![<p>v<sup>π</sup> (s) = Σ<sub>a</sub> π(a|s) Σ<sub>s’</sub> p(s’|s,a) [r(s,a,s’) + γ v<sup>π</sup>(s’)]</p>](https://assets.knowt.com/user-attachments/ed6b2588-628c-45bf-bdab-14e9654e8786.png)
Policy iteration
Couples explicit evaluation and improvement steps. Iterates Policy Evaluation (repeated sweeps using formula until convergence) and Policy Improvement (π’(s) ← argmaxa qπ (s,a)) within the Generalized Policy Iteration (cycle).
Bellman Optimality Equation
vk+1 (s) = maxa Σs’ p (s’|s,a) [r(s,a,s’) + γ vk(s’)]
Monte Carlo Methods
Wait until absolute termination of an episode to compute exact realized empirical return Gt and update values. Updates are unbiased but have high variance.
V(st) ← V(st) + α[Gt - V(st)]
Requires unfeasible assumption of Exploring Starts.
![<p>Wait until absolute termination of an episode to compute exact realized empirical return G<sub>t</sub> and update values. Updates are unbiased but have high variance.<br>V(s<sub>t</sub>) ← V(s<sub>t</sub>) + α[G<sub>t</sub> - V(s<sub>t</sub>)] <br>Requires unfeasible assumption of Exploring Starts.</p>](https://assets.knowt.com/user-attachments/5fbea183-a93b-4336-92ec-ada062e6ed01.png)
Exploring Starts
Every episode starts at a randomized state-action pair (ensure every action gets performed).
Temporal-Difference Learning: TD(0)
Eliminates the endpoint restriction via bootstrapping (updating current estimation using single-step future estimate target, reducing variance at the cost of introduction of bias).
V(st) ← V(st) + α[Rt+1 + γ V(st+1) - V(st)]
![<p>Eliminates the endpoint restriction via bootstrapping (updating current estimation using single-step future estimate target, reducing variance at the cost of introduction of bias).<br>V(s<sub>t</sub>) ← V(s<sub>t</sub>) + α[R<sub>t+1</sub> + γ V(s<sub>t+1</sub>) - V(s<sub>t</sub>)] </p>](https://assets.knowt.com/user-attachments/5aa43020-184c-490e-b5db-59c003692ded.png)
SARSA
On-policy. Learns values of the current exploratory policy (safer in online systems).
Q(s, a) ← Q(s, a) + α [ R + γ Q(s', a') - Q(s, a) ]
![<p>On-policy. Learns values of the current exploratory policy (safer in online systems).</p><p>Q(s, a) ← Q(s, a) + α [ R + γ Q(s', a') - Q(s, a) ]</p>](https://assets.knowt.com/user-attachments/81c47bc2-f802-4cea-ab8f-7c527d142abb.png)
Q-Learning
Off-policy. Learns values of the absolute optimal policy directly (regardless of behavior choices).
Q(s, a) ← Q(s, a) + α [ R + γ maxa’ Q(s', a') - Q(s, a) ]
![<p>Off-policy. Learns values of the absolute optimal policy directly (regardless of behavior choices).<br>Q(s, a) ← Q(s, a) + α [ R + γ max<sub>a’ </sub>Q(s', a') - Q(s, a) ]</p>](https://assets.knowt.com/user-attachments/3d625fa9-6d90-4997-9799-3d3803241c39.png)
Expected Sarsa
Flexible. Computes exact policy expectation over the target state (reduces sampling variance).
Q(s, a) ← Q(s, a) + α [ R + γ Σa’ π(a'|s')Q(s', a') - Q(s, a) ]
![<p>Flexible. Computes exact policy expectation over the target state (reduces sampling variance). <br>Q(s, a) ← Q(s, a) + α [ R + γ Σ<sub>a’</sub> π(a'|s')Q(s', a') - Q(s, a) ]</p>](https://assets.knowt.com/user-attachments/c0a53997-51ec-43d1-b164-500447f5978b.png)
On-policy
The agent learns the value of the exact policy it is currently using to interact with the environment. It improves upon its own current strategy (chef learning only by tasting their own cooking)
Off-policy
The agent can learn optimal behavior from data collected by entirely different policies, past experiences or even random actions (chef learns by watching other chefs cook, reading books, and analyzing other people's recipes).
Maximization Bias
Taking the maximum of noisy values systematically overestimates true expectations.
Double Q-Learning
Solves maximization bias by decoupling action selection from action evaluation using two independent value arrays.
QA(s,a) ← QA(s,a) + α [ R + γ QB(s', argmaxa’ QA(s', a')) - QA(s,a) ]
Model-Based RL & Sample-Based Planning
Environmental interactions in the real world are irreversible. MBRL allows agents to construct a learned tabular forward model from experiences real-world data tuple logs (s, a, r, s’).
p̂(s' | s, a) = n(s, a, s') / Σs’’ n(s, a, s'')
r̂(s, a, s') = Rsum(s, a, s') / n(s, a, s')
Dyna Framework
Unifies real-world model-free updates with simulated background planning updates. After real transition and updating the table it samples randomized previously seen states/actions from internal model. Running simulated updates maximizes data efficiency.
Prioritized Sweeping
Learns a backward model and updates a priority queue of states whose values are most significantly altered by the latest reward update (optimizing computational allocation).
Back-up Architectures
Dynamic Programming (full-width, shallow)
TD Learning (sample-width, shallow)
Monte Carlo (sample-width, deep)
Exhaustive Search (full-width, deep)
Parametric function networks
Eliminate tracking bottlenecks of continuous or extremely large state spaces.
vπ(s) ≈ v(s, w)
qπ(s, a) ≈ q(s, a, w)
Mean Squared Value Error
Using Gradient Descent.
VE(w) = Σs μ(s) [ vπ(s) - v(s, w) ]2
Policy Gradient Methods
Parameterize a probabilistic policy mapping π(a|s,θ) instead of optimizing values and picking actions indirectly via ε-greedy.
REINFORCE algorithm
Policy Gradient Theorem to update parameters directly from sampled trajectories.
θt+1 = θt + α Gt ∇ ln π(At | St, θt)
We stabilize learning speed by shifting updates to reward advantages.
θt+1 = θt + α [ Gt - v(St, w) ] ∇ ln π(At | St, θt)
![<p>Policy Gradient Theorem to update parameters directly from sampled trajectories.<br>θ<sub>t+1</sub> = θ<sub>t</sub> + α G<sub>t</sub> ∇ ln π(A<sub>t</sub> | S<sub>t</sub>, θ<sub>t</sub>)<br><br>We stabilize learning speed by shifting updates to reward advantages.<br>θ<sub>t+1</sub> = θ<sub>t</sub> + α [ G<sub>t</sub> - v(S<sub>t</sub>, w) ] ∇ ln π(A<sub>t</sub> | S<sub>t</sub>, θ<sub>t</sub>)</p>](https://assets.knowt.com/user-attachments/e28f33e1-cab6-461b-9986-4ff576cc84e7.png)
Actor-Critic Methods
Combine paradigms: actor parameterizes and improves the explicit policy π(a|s,θ) while critic tracks parameters w to learn a single-step bootstrapped TD baseline value function used to judge actor’s selections.
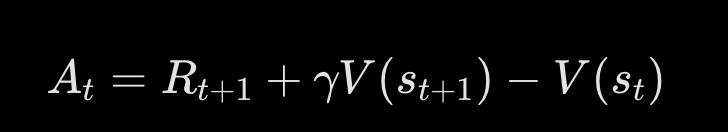
Psychology & Neuroscience Connections
Classical Conditioning (Pavlovian)
Instrumental/Operant Conditioning (Skinnerian)
Habitual vs. Goal-Directed Behavior
Classical Conditioning (Pavlovian)
Matches prediction problem (policy evaluation). Burst of neurotransmitter dopamine inside the brain mathematically mirror the exact functional operation of Temporal-Difference Error signals (δ). Learning saturates when rewards are fully expected and extinction when expected rewards are removes. This tracks behavior mechanism of the Rescorla-Wagner learning rule.
Instrumental/Operation Conditioning (Skinnerian)
Matches control problem (policy improvement) shifting active behaviors based on reinforcement feedback.
Habitual vs. Goal-Directed Behavior
Distinction between raw reactive instincts (Model-Free RL) and forward planning cognitive maps (Model-Based RL).
AlphaGO
GO has massive search branching factor (b=250) and game depth (d=150) making traditional chess-style Minmax lookahead search impossible.
Integrations of MCTS:
Narrowing Search Width: human move logs were cloned via supervised learning to train policy network (pσ) and guids MCTS selection formula to prioritize high-potential actions.
Pruning Search Depth: self-play policy gradient architectures (REINFORCE) optimized a deep value network (vθ) to evaluate intermediate game state tables directly (bypassing the computational need for full deep tree search evaluations).
AlphaGo Zero
Simplified complex structure. Bypassing all human imitation data entirely. Utilized raw observations and treats MCTS simultaneously as a dual-engine iteration step (MCTS acts as continuous policy improvement step and policy neural network directly learns to clone the tree-search distribution patterns via structural reinforcement updates).
Rescorla-Wagner
Change in strength of stimuli = salience x learning rate( max associative strength - summed associative strength)