CST IB - Distributed Systems
1/79
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
80 Terms
Why make a system distributed
it’s inherently distributed - e.g. sending a message from one device to another
better reliability - even if one node fails, the system as a whole keeps functioning
better performance - get data from a nearby node rather than one far away
to solve bigger problems - e.g. problems involving large amounts of data, that cannot be stored by one single machine
Why not make a system distributed
communication may fail without us knowing
processes may crash without us knowing
all of this may happen non-deterministically and without warning
requires fault tolerance - want the system as a whole to continue working, even when some parts are faulty, which makes distributed computing often harder than programming a single computer
What is the goal of distributed systems in practice
ensuring good performance in the common cases
What is the goal for distributed systems in theory
ensuring correctness in all cases
What is the difference between latency and bandwidth
latency - delay from the time a message is sent until it is received
bandwidth - volume of data that can be transferred per unit time
What is the availability of a service and how is it measured
the fraction of time that a service is functioning correctly
e.g. “two nines” means it is up 99% of the time, “three nines” means 99.9%, up to “five nines”
the availability of a service is measured in terms of its ability to respond correctly to requests within a certain time, formalised using an SLO and SLA
a Service Level Objective (SLO) specifies the percentage of requests that must return a correct response within a specified timeout, e.g. “99.99% of requests in a day get a response in 200ms”
a Service Level Agreement (SLA) is a contract that specifies the SLO, as well as the consequences for violating the SLO, e.g. offering a refund to customers
how to increase the availability of a service
faults are a common cause of unavailability
either reduce faults or design systems to be fault tolerant
reduce faults by getting better hardware and introducing redundancy
but there is still a nonzero chance of a fault occurring
instead, fault tolerance is used by many systems as it ensures the system still works despite some components being faulty, up to some maximum number of faults
allows software upgrades to be rolled out without clients noticing any interruption, so software can be updated frequently
What is a SPOF
Single Point of Failure
some systems have a single node that, if it becomes faulty, would cause an outage of the entire system
fault-tolerant systems aim to avoid having any SPOF
Why might higher availability not always be better
it requires highly focused engineering effort, and often conservative design choices
e.g. the old-fashioned fixed-line telephone network is designed for “five nines” availability, but downside is that it has been very slow to evolve
most Internet services don’t reach “four nines” because of diminishing returns - when the additional cost of achieving higher availability exceeds the cost of occasional downtime, so it is economically rational to accept a certain amount of downtime
How can an application call a function on another node
using Remote Procedure Call (RPC), or Remote Method Invocation (RMI) in Java
software that implements RPC is an RPC framework/middleware
when the application wants to call a function on another node, the RPC framework provides a stub with the same type signature as the real function
the stub marshals (encodes) the arguments into a message and sends it over to the remote node, asking to call the function
on the server side, the RPC framework unmarshals (decodes) the arguments and calls the desired function with the given arguments
the function then returns: the server RPC framework marshals the return value, sends the message back to the client RPC framework, the client RPC framework unmarshals the return value, and the stub returns this value to the main application program
achieves location transparency - it seems like a local function call within the application, hiding the actual location of the function
What are the practical considerations for RPC
networks and nodes may fail
if a client sends an RPC request but receives no response, it doesn’t know whether the server received and processed the request, whether a message was lost or if there is a delay
could resend request after a certain time limit, but could cause the request to be completed more than once (e.g. charging a credit card twice)
but even if we retry, no guarantee that retried messages will get through either
so in practice, client will have to give up after some timeout
How to achieve location transparency when a function could either call an RPC or a local API
the local API must sometimes fail, to hide that it is local, as the RPC can sometimes fail with network or node errors
What is the most common form of RPC
JSON data sent over HTTP
follows REST design principles
Why do most HTTP-based APIs follow REST principles
REST, aka representational state transfer, is popular because JavaScript code running in a web browser can easily make HTTP requests that follow REST
nowadays, it is common to use JavaScript to make HTTP requests to a server without reloading the whole page
RESTful APIs and HTTP-based RPC is also commonly used with other types of clients (e.g. mobile apps) or for server-to-server communication
What principles do RESTful APIs follow
6 REST design principles:
uniform interface - resources are represented by URLs, the state of a resource is updated by making a HTTP request with a standard method type (e.g. POST, PUT) to the appropriate URL
stateless communication - each request from client to server is independent from other requests, so must contain all information necessary
client-server design - separates user interface concerns (client) and data storage concerns (server)
cacheable - a response should label itself as cacheable (client has the right to reuse the response data for a specified period of time) or uncacheable
layered system - architecture is composed of hierarchical layers, a layer can only interact with layers directly above or below
code on demand (optional) - allows servers to extend client functionality by sending executable code in the form of applets or server-side scripts like JavaScript
what is service-oriented architecture (SOA)
splitting a large software application into multiple services on multiple nodes that communicate via server-to-server RPC
different services may be implemented in different languages, so RPC frameworks need to facilitate communication between them, by implementing datatype conversions so that the caller’s arguments are understood by the code being called, and same with the return values
a common solution is to use Interface Definition Language (IDL) to provide language-independent API specifications of the type signatures of the functions made available over RPC
Is the two generals problem applicable to online shopping, where there is an RPC framework linking the online shop dispatching the goods and the payments service charging the customer
if the shop doesn’t dispatch the goods and the payments service doesn’t charge - nothing happens
if the shop dispatches the goods and the payments service doesn’t charge - shop loses money
if the shop doesn’t dispatch the goods and the payments service charges - customer complaint
if the shop dispatches the goods and the payments service charges - desired outcome, everyone is happy
however, unlike two generals problem where defeat of an army cannot be undone, payment can be undone, so use this protocol to get desired outcome:
payments service tries charging customer’s credit card. if charge successful, shop tries dispatching goods. if dispatch unsuccessful, refund credit card payment.
so the online shop dispatches iff payment has been made
What is the Byzantine generals problem
similar setting to two generals problem, but with 3 or more armies wanting to capture a city
each general is either malicious or honest
up to f generals might be malicious
honest generals don’t know who the malicious ones are, but malicious generals may collude
must ensure that all honest generals agree on the same plan (e.g. attack or retreat)
theorem - need 3f + 1 generals to tolerate f malicious generals, i.e less than a third of the generals may be malicious
cryptography (digital signatures) could help prove who said what, e.g. general 3 could prove to general 2 that general 1 said to attack, but problem still remains challenging
if a distributed system deals with the possibility that some nodes may be controlled by a malicious actor, it is called Byzantine fault tolerant
What do the two generals problem and the Byzantine generals problem model
two generals - network behaviour
Byzantine generals - node behaviour
What are the system models for network behaviour
assume bidirectional point-to-point/unicast communication (real networks sometimes allow broadcast/multicast communication but assuming unicast-only is a good model for the Internet) between two nodes, with one of:
reliable (perfect) links - a message is received iff it is sent. messages may be reordered
fair-loss links - messages may be lost, duplicated, or reordered. if you keep retrying, a message eventually gets through
arbitrary links (active adversary) - a malicious adversary may interfere with messages (eavesdrop, modify, drop, spoof, replay)
What is a network partition/network interruption
when some links drop or delay all messages for an extended period of time
How can fair loss links turn into reliable links
retry sending message infinitely many times until received
deduplicate messages - filter out duplicated messages on recipient side
How can arbitrary links almost turn into fair-loss links
use TLS so that adversary cannot interfere with the link
but not quite fair-loss because adversary can still block communication
What are the system models for node behaviour
crash-stop (fail-stop) - a node is faulty if it crashes. after crashing it stops executing forever
crash-recovery (fail-recovery) - a node may crash at any moment, losing its in-memory state. it may resume executing sometime later. data stored on disk survives the crash
Byzantine (fail-arbitrary) - a node is faulty if it deviates from the algorithm. faulty nodes may do anything, including crashing or malicious behaviour
What are the system models for timing assumptions
synchronous - message latency no greater than a known upper bound. nodes execute algorithm at a known speed
partially synchronous - system is asynchronous for some finite, unknown periods of time, synchronous otherwise
asynchronous - messages can be delayed arbitrarily. nodes can pause execution arbitrarily. no timing guarantees at all
What is a failure detector
an algorithm that detects whether a node is faulty
How does a failure detector work typically
periodically sends messages to other nodes
label a node as crashed if no response is received within some timeout
ideally, timeout occurs iff node has really crashed, so labels node as faulty iff it has crashed - perfect failure detector
perfect timeout-based failure detector exists only in a synchronous crash-stop system with reliable links
two generals problem tells us this is not totally accurate as we cannot tell the difference between a crashed node, temporarily unresponsive node, lost message, or delayed message
What is a useful failure detector in partially synchronous systems
eventually perfect failure detector
may temporarily label a node as crashed, even though it is correct
may temporarily label a node as correct, even though it has crashed
but eventually labels a node as crashed iff it has crashed
What are the two types of clocks
physical clocks - count number of seconds elapsed
logical clocks - count events, e.g. messages sent
How do quartz clocks work
quartz crystal laser-trimmed to mechanically resonate at a specific frequency
piezoelectric effect - when mechanical force is applied to the crystal, it produces electric charge. likewise, when electric charges are applied to the crystal, it will bend
oscillator circuit produces a signal at the resonant frequency
count number of oscillations (frequency) to measure elapsed time
cheap, but not totally accurate
manufacturing imperfections mean some clocks run slightly faster than others
oscillation frequency varies with temperature - they are tuned to be quite stable around room temperature, but significantly higher or lower temperatures slow down the clock
What is drift
the rate by which a clock runs fast or slow
measured in parts per million (ppm)
1 ppm = 1 microsecond/second = 86 ms/day = 32 s/year
most computer clocks are correct within 50 ppm
How do atomic clocks work
(the time unit of 1 second in the International System of Units (SI) is defined to be exactly 9,192,631,770 periods of a particular resonant frequency of the Caesium-133 atom)
Caesium-133 has a resonance at approx 9 GHz
tune an electronic oscillator to that resonant frequency
1 second = 9,193,631,770 periods of that signal
accuracy = approx 1 in 10-14 (1 second in 3 million years)
price = approx £20,000, can get cheaper Rubidium clocks for approx £1,000
How to use GPS satellites as a time source
31 satellites, each carrying an atomic clock
satellites broadcast location and time at a very high resolution
receivers measure the time it took for the signal from each satellite to reach them, compute their distance from each satellite, calculate their positions
can connect a GPS receiver to a computer
accuracy within a fraction of a microsecond, provided receiver can get a clear signal from the satellites
in datacenters, there is too much electromagnetic interference so a GPS receiver requires an antenna on the roof of the datacenter building
What is UTC and why is it used
Coordinated Universal Time
two definitions of time - International Atomic Time (TAI) based on caesium-133’s resonant frequency, and the rotation of the Earth
they don’t align because the speed of the Earth’s rotation is not constant
UTC is TAI with corrections to account for Earth’s rotation, by including leap seconds
Why is it not true that a day always has 86,400 seconds in the UTC timescale
leap seconds
every year, on 30 June and 31 December at 23:59:59 UTC, one of 3 things happens:
clock moves to 00:00:00 after one second, as usual
negative leap second - clock skips one second and immediately jumps to 00:00:00
positive leap second - clock moves to 23:59:60 after one second, then 00:00:00 after another second
this decision is announced several months beforehand
so a day can be 86,399s, 86,400s, or 86,401s
How do computers represent timestamps
timestamp - a representation of a particular point in time
2 representations:
Unix time - number of seconds since 1 January 1970 00:00:00 UTC (the “epoch”), not counting leap seconds
ISO 8601 - year, month, day, hour, minute, second, and timezone offset relative to UTC, e.g. 2021-11-09T09:50:17+00:00
What is the difference between clock drift and clock skew
clock drift is the difference between the rate of oscillations of 2 clocks
clock skew is the difference between the times of the 2 clocks
How do computers implement clock synchronisation
computers track physical time/UTC with a quartz clock
clock drift means clock skew increases
use Network Time Protocol (NTP) or Precision Time Protocol (PTP) to synchronise
periodically get current time from a server that has a more accurate time source, like atomic clock or GPS receiver
How does Network Time Protocol (NTP) work
hierarchy of clock servers arranged into strata:
stratum 0 - atomic clock or GPS receiver
stratum 1 - synced directly with stratum 0 device
stratum 2 - servers that sync with stratum 1, etc
to reduce effects of random variations, takes several samples of time measurements, even from the same server, applies statistical filters to eliminate outliers, averages the rest
How does NTP estimate the clock skew between the client and the server
t1 is timestamp that client sends request
t2 is timestamp server receives client's request
t3 is timestamp server sends response
t4 is timestamp client receives server's response
clock skew is difference between the time on the client's clock that the client receives the response (t4) and the estimated time on the server's clock that the client receives the response (t3 + d/2)
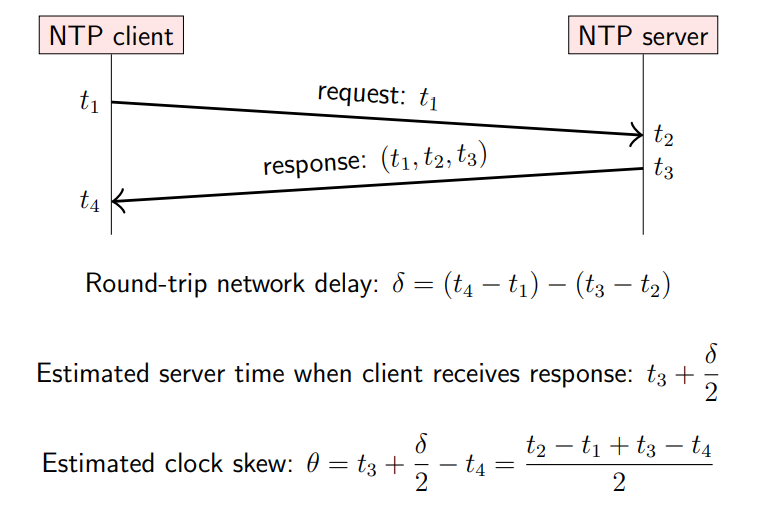
How does NTP correct clock skew for a client
once it has estimated clock skew θ:
if |θ| < 125 ms: slew the client clock - slightly speed it up or slow it down by up to 500 ppm, which brings the clocks in sync within approx 5 minutes
if 125 ms <= |θ| < 1000 s: step the client clock - suddenly reset client clock to estimated server timestamp
if |θ| >= 1000 s: client gets stuck in panic state where it refuses to adjust the clock, so a human operator must resolve it
Why do most operating systems and programming languages provide both a time-of-day clock and a monotonic clock
both useful for different purposes
time-of-day clocks:
time since a fixed date (e.g. 1 Jan 1970 epoch)
may suddenly move forwards or backwards due to NTP stepping and leap second adjustments
timestamps can be compared across synced nodes
e.g. Java: System.currentTimeMillis()
e.g. Linux: clock_gettime(CLOCK_REALTIME)
monotonic clock:
time since an arbitrary point (e.g. when the machine was booted up)
always moves forwards at an almost constant rate
good for comparing timestamps from the same node, but not across different nodes
e.g. Java - System.nanoTime()
e.g. Linux - clock_gettime(CLOCK_MONOTONIC)
What does a → b mean (where a and b are events)
a happens before b
iff:
a and b occurred at the same node, and a occurred before b in that node’s local execution order
or
a is the sending of some message m, and b is the receipt of that message m
or
there exists an event c such that a → c and c → b
it is possible that neither a → b nor b → a, in which case a || b, meaning a and b are concurrent
How does the happens-before relation encode potential causality
when a → b, then a might have caused b
when a || b, we know that a cannot have caused b
let ≺ be a strict total order on events:
if (a → b) ⇒ (a ≺ b) then ≺ is a causal order or ≺ is consistent with causality
What is the difference between physical and logical clocks
physical - count number of seconds elapsed. may be inconsistent with causality
logical - count number of events occurred. designed to capture causal dependencies: (e1 → e2) ⇒ (T(e1) < T(e2)). e.g. Lamport or vector clocks
How do Lamport clocks work
each node has a counter t, incremented on every local event e
let L(e) be the value of t after that increment
attach the current t to messages sent over the network
recipient moves its clock forward to timestamp in the message (if it’s greater than the local counter), then increments the local counter (for the event of receiving the message)
properties:
if a → b, then L(a) < L(b)
if L(a) < L(b), it does not mean a → b, it could be that a || b, we cannot tell
it is possible that L(a) = L(b) while a ≠ b
let N(e) be the node at which event e occurred
the pair (L(e), N(e)) uniquely identifies event e
What is the definition of a total order ≺ using Lamport timestamps
(a ≺ b) ⇐⇒ (L(a) < L(b) ∨ (L(a) = L(b) ∧ N(a) < N(b)))
What type of clock do we need to detect which events on different nodes are concurrent
vector clocks
How do vector clocks work
assume N nodes in the system, N = ⟨N0, N1, …, Nn−1⟩
for an event a, let V(a) be the vector timestamp, V(a) = ⟨t0, t1, …, tn−1⟩
ti is the number of events observed by node Ni
each node has a current vector timestamp T
on an event at node Ni, increment vector element T[i]
attach current vector timestamp to each message
recipient Ni merges message vector into its local vector by getting the max of each element between them and incrementing T[i]
![<ul><li><p>assume <em>N</em> nodes in the system, <em>N</em> = ⟨N<sub>0</sub>, N<sub>1</sub>, …, N<sub>n−1</sub>⟩</p></li><li><p>for an event <em>a</em>, let V(<em>a</em>) be the vector timestamp, V(<em>a</em>) = ⟨t<sub>0</sub>, t<sub>1</sub>, …, t<sub>n−1</sub>⟩</p></li><li><p><em>t<sub>i</sub></em> is the number of events observed by node <em>N<sub>i</sub></em></p></li><li><p>each node has a current vector timestamp <em>T</em></p></li><li><p>on an event at node <em>N<sub>i</sub></em>, increment vector element <em>T</em>[<em>i</em>]</p></li><li><p>attach current vector timestamp to each message</p></li><li><p>recipient <em>N<sub>i</sub></em> merges message vector into its local vector by getting the max of each element between them and incrementing <em>T</em>[<em>i</em>]</p></li></ul><p></p>](https://knowt-user-attachments.s3.amazonaws.com/70295a14-5740-44a7-a5eb-c19c7995539f.png)
What is the partial order defined over vector timestamps (in a system with n nodes)
T = T ′ iff T[i] = T ′ [i] for all i ∈ {0, …, n − 1}
T ≤ T ′ iff T[i] ≤ T ′ [i] for all i ∈ {0, ..., n − 1}
T < T ′ iff T ≤ T ′ and T ≠ T ′
T || T ′ iff T !≤ T ′ and T ' !≤ T
V(a) ≤ V(b) iff ({a} ∪ {e | e → a}) ⊆ ({b} ∪ {e | e → b})
properties:
(V(a) < V(b)) ⇐⇒ (a → b)
(V(a) = V(b)) ⇐⇒ (a = b)
(V(a) || V(b)) ⇐⇒ (a || b)
two vectors are incomparable if one vector has a greater value in one element, and the other has a greater value in a different element, e.g. T = ⟨2, 2, 0⟩ and T ′ = ⟨0, 0, 1⟩
this partial order corresponds exactly to the partial order defined by the happens-before relation
What are broadcast protocols
a message is sent to all nodes in some group
set of group members may be fixed/static or dynamic
if one node is faulty, remaining group members carry on
can be best-effort (may drop messages) or reliable (non-faulty nodes deliver every message by retransmitting dropped messages)
asynchronous or partially synchronous timing model, no upper bound on message latency
What happens when an application wants to send a message to all nodes in the group
broadcast algorithm sends some messages to other nodes over point-to-point (unicast) links
another node receives the message when it arrives over the point-to-point link
broadcast algorithm on receiving node then delivers the message to the application
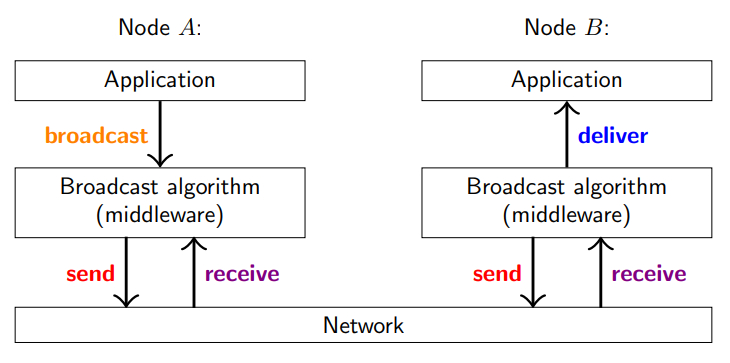
What are some different forms of reliable broadcast
best-effort
reliable
FIFO - if m1 and m2 are broadcast by the same node, and broadcast(m1) → broadcast(m2), then m1 must be delivered before m2
causal - if broadcast(m1) → broadcast(m2), then m1 must be delivered before m2
total order - if m1 is delivered before m2 on one node, then m1 must be delivered before m2 on all nodes
FIFO-total order - combination of FIFO and total order
order based on strength: best-effort → reliable → FIFO → causal → FIFO-total order AND reliable → total order → FIFO-total order
e.g. FIFO-total order broadcast is stronger than causal broadcast, so every valid FIFO-total order broadcast protocol is also a valid causal broadcast protocol
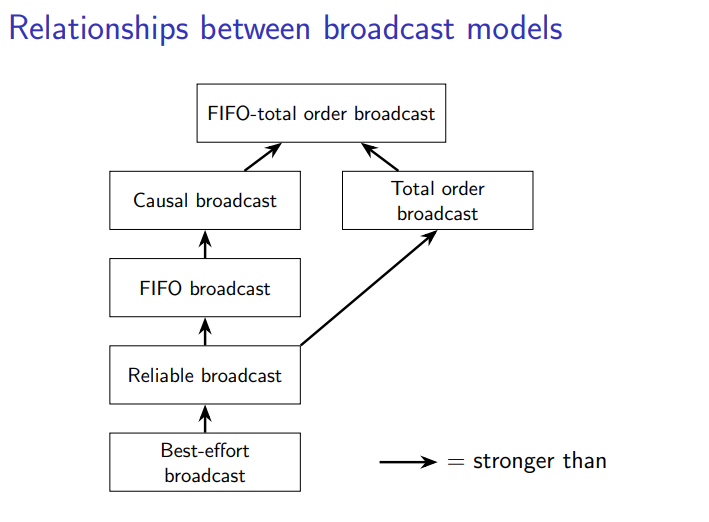
What is FIFO broadcast
weakest form of broadcast
messages sent from the same node are delivered in the order they were sent
but messages sent from different nodes may be delivered in any order
What is causal broadcast
stricter ordering property than FIFO
messages are delivered in causal order
e.g. if broadcast(m1) → broadcast(m2), the broadcast algorithm will hold back a message m2 until after m1 is delivered
if two messages are broadcast concurrently, a node may deliver them in either order
What is total order broadcast
enforces consistency across all nodes, ensuring that they all deliver messages in the same order
the exact deliver order is not defined, as long as it is the same on all nodes
in FIFO and causal, a node that broadcasts a message can immediately deliver that message to itself, but with total order, a node’s deliveries to itself will require communication with other nodes to ensure they all deliver in the same order
What is FIFO-total order broadcast
total order broadcast with the additional FIFO requirement that any messages broadcast by the same node are delivered in the order they were sent
What are some algorithms that can be used to implement reliable broadcast
eager reliable broadcast:
a node that wants to broadcast a message tries to send it directly to every other node
the first time a node receives a particular message, it forwards that message to every other node
ensures that even if some nodes crash, all of the remaining non-faulty nodes receive every message
inefficient - every message is sent O(n2) times in a group of n nodes, sends a large amount of redundant network traffic
gossip protocols (aka epidemic protocols):
a node that wants to broadcast a message sends it to a small fixed number of nodes that are chosen randomly
the first time a node receives a particular message, it forwards that message to a small fixed number of nodes
does not strictly guarantee all nodes will receive a message, but if parameters are chosen appropriately, probability of a message not being delivered can be very small
resilient to message loss and node crashes while also remaining efficient
Describe the FIFO broadcast algorithm
each node’s local state has:
sendSeq (sequence number, counts number of messages broadcast by this node)
delivered (a vector with one entry per node, counting the number of messages from each sender that this node has delivered)
buffer (a buffer for holding back messages until they are ready to be delivered)
each message m sent by node Ni is tagged with sending node number i, and sequence number: send (i, sendSeq, m)
when a message is received it is added to the buffer. the algorithm then checks for any messages from any sender that match the expected next sequence number, then increments that number, ensuring messages from each particular sender are delivered in order of increasing sequence number
Describe the causal broadcast algorithm
each node’s local state has:
sendSeq, delivered, buffer (same meanings as in FIFO)
when a node Ni wants to broadcast a message, attach the sending node number and i and deps, a vector indicating the causal dependencies of that message
construct deps by taking a copy of delivered - all messages that have been delivered locally prior to this broadcast must appear before the broadcast message in causal order.
then, update it by setting deps[i] = sendSeq, ensuring each message broadcast by this node has a causal dependency on the previous message broadcast by the same node
when a message is received it is added to the buffer. the buffer is searched for any messages that are ready to be delivered while deps <= delivered. this is true if the node has already delivered all of the messages that must precede this message in the causal order.
any messages that are causally ready are then delivered to the application and removed from the buffer.
the appropriate element of the delivered vector is incremented
Describe the single leader approach to total order broadcast algorithms
one node is designated as leader
to broadcast a message, send it to the leader
leader broadcasts it via FIFO broadcast
problem: leader is a SPOF, changing the leader safely is difficult
not fault-tolerant
Describe the Lamport clocks approach to total order broadcast algorithms
attach Lamport timestamp to every message
deliver messages in total order of timestamps
problem: how do you know if you have seen all messages with timestamp < T. need to use FIFO links and wait for message with timestamp >= T from every node. the crash of a single node can stop all other nodes from being able to deliver messages
not fault-tolerant
What needs to be done when managing changes to replicated data, for example with social media like counts
changes might take effect multiple times due to requests being received, but acknowledgements sent back not being received
need to deduplicate requests, making them idempotent so they can be retried safely
update f is idempotent if f(x) = f(f(x))
instead of incrementing like count, have a likeSet = likeSet Union {userID}
allows an update to have exactly-once semantics
When retrying a request to change replicated data, what are the different semantics
at-most-once semantics: send req, don’t retry, update may not happen
at-least-once semantics: retry req until acknowledge, may repeat update
exactly-once semantics: retry as many times, with idempotence or deduplication so the effect is as if it had only applied once
When a client is removing an element from a set in 2 replicas, how can it make sure this action is done if the message is lost
attach a logical timestamp to every update operation
remove requests are actually updates, marking records as false to indicate that it is a tombstone (deleted)
so every record has a logical timestamp of the last write, which could be an update or remove
What is anti-entropy
protocol to reconcile the differences in replicas so they are consistent
propagates record with the latest timestamp for a given key (the value being updated), discarding records with earlier timestamps
What can happen when there are concurrent writes by different clients to a register (replicated variable whose value can be updated)
2 common approaches:
Last Writer Wins (LWW) register:
use Lamport clocks which have a total order
keep v2 and discard v1 if t2 > t1 (arbitrarily based on how the timestamps are assigned)
data loss when multiple updates are performed concurrently, but in some systems this is fine
multi-value register
use vector clocks which have a partial order, so it is possible that events are concurrent
if t1 || t2, preserve both {v1,v2}, called conflicts or siblings
application can later merge conflicts back into a single value
but vector clocks are expensive, so with large number of clients, vector is large, potentially larger than the data
Why do many systems require read-after-write consistency
if a client writes the key x to 2 servers A and B, and only B receives the update, then the client reads x, and only A receives the read request and sends back its x, then the client will not have seen their update
but strictly, if another client overwrites the value before the first client reads, then the first client reads the last value written, which is not their own
need at least 3 servers, requests are successful if the client receives a quorum of responses
to ensure read-after-write consistency, the write quorum and read quorum must have a non-empty intersection (i.e. read quorum must contain at least 1 node that has acknowledged the write)
In a quorum approach to replication, how to bring replicas back in sync with each other
can use anti-entropy or
read repair
if client reads and gets an old value from one server, newer from another
client helps propagate new value to other servers that did not send it the new value
The quorum approach to replication uses best-effort broadcast, how to implement replication using FIFO-total order broadcast
State Machine Replication (SMR)
FIFO-total order broadcast every update to all replicas
replica delivers update message, applies it to its own state
applying an update is deterministic
replica is a state machine: starts in fixed initial state, goes through same sequence of state transitions in same order for each replica, so all end up in the same state
needs fault-tolerant total order broadcast, downsides are the limitations of total order broadcast:
cannot update state immediately, have to wait for delivery through broadcast

What is passive/primary-backup replication
designating one node as the leader
route all broadcast messages through the leader to impose a delivery order
the leader may execute multiple transactions concurrently, but it commits them in a total order
when the transaction commits, the leader replica broadcasts the writes from that transaction to all the follower replicas
followers apply those writes in commit order
implements total order broadcast of transaction commits
Can replication be implemented using a weaker broadcast than total order
yes, but it is not sufficient to just ensure that the state update is deterministic in order for replicas to end up in the same state
need to make concurrent updates commutative, ensuring the final result is the same no matter which order those updates are applied
updates f and g are commutative if f(g(x)) = g(f(x))
causal: concurrent updates commute
reliable: all updates commute
best-effort: commutative, idempotent, tolerates message loss

What is the atomic commitment problem
ensuring atomicity when carrying out distributed transactions
if a transaction updates data on multiple nodes:
either all nodes must commit, or all must abort
if any node crashes, all must abort
most common algorithm to ensure atomic commitment is two-phase commit (2PC)
What is the two-phase commit (2PC) algorithm
a client starts a regular single-node transaction on each replica in the transaction
performs the usual transaction execution
when the client is ready to commit the transaction, it sends a commit request to the transaction coordinator
phase 1 - coordinator sends a prepare message to each replica participating in the transaction, and each replica replies with a message whether they can commit or not
replicas must write all of the transaction’s updates to disk and check any integrity constraints before replying that they can commit, while holding any locks for the transaction
phase 2 - coordinator collects the responses and decides whether or not to commit the transaction (if all nodes reply ok to prepare, then decide to commit, else, abort)
coordinator sends its decision to all of the replicas, who commit/abort as instructed
What is the main problem with 2PC
the coordinator is a SPOF
in case it crashes, coordinator can write its decision to disk and when it recovers, read and send the decision to the replicas
but if coordinator crashes after prepare but before broadcasting decision, other nodes do not know what has been decided
transactions that have prepared but not yet committed/aborted at the time of the coordinator crash are called in-doubt transactions
to not violate atomicity, algorithm is blocked until coordinator recovers
How to make sure the coordinator in 2PC is not a SPOF
use a total order broadcast protocol to create a fault-tolerant 2PC algorithm that doesn’t have a coordinator
every node participating in transaction uses total order broadcast to vote whether to commit or abort
if node A suspects node B has failed (because no vote from B was received within some timeout), then A may try to vote to abort on behalf of B
introduces a race condition - if B is slow, it might be that node B broadcasts its own vote to commit around the same time A suspects B to have failed and votes to abort
each node counts all the received votes independently, count only the first vote from any given replica and ignore subsequent votes from the same replica so that all nodes can agree that they are receiving the same vote from the same node (because in total order broadcast, messages from the same node arrive in the same order for all nodes)
if a node wants to abort, it can immediately abort and broadcast the abort decision
otherwise, the node must add its id to the list of replicas that have sent their vote
once all the votes have been delivered and none of the replicas have voted to abort, the transaction can be committed
When multiple nodes concurrently access replicated data, how do we maintain consistency
implement linearizability:
every operation takes effect atomically sometime after it starts (e.g. when the operation is requested by the application) and before it finishes (e.g. when the operation result is returned to the application)
all operations behave as if executed on a single copy of the data
results in strong consistency - every operation returns an up-to-date value
the main thing linearizability cares about is whether an operation finished before another operation started
How to make get and set operations linearizable using quorum reads and writes
ABD algorithm:
assume set operations are only performed by one designated node
set - send update to all replicas, wait for acknowledgement from a quorum of replicas
get - client first sends get request to all replicas, waits for responses from a quorum, if some responses include a more recent value than other responses, then client must write back the most recent value to all replicas that did not already respond with the most recent value (read repair)
get operation only finishes after the client is sure that the most recent value is stored on a quorum of replicas, which is after a quorum of replicas responded ok to the read repair or already responded with the most recent value before
How to generalise the ABD algorithm to a setting where multiple nodes may perform set operations
need to ensure timestamps of operations reflect real-time order
e.g. if set(x,v1) has timestamp t1, set(x,v2) has timestamp t2, and set(x,v1) finishes before set(x,v2) starts, then we must ensure t1 < t2
have each set operation request the latest timestamp from each replica and wait for responses from a quorum (like a get operation)
logical timestamp for set operation is 1 + max. timestamp received from the quorum
but if two different clients are concurrently performing set operations, this could result in two different operations having the same timestamp
to tell them apart, give each client a unique ID, and incorporate that into the timestamps generated by that client
when a get operation encounters responses with the same timestamp but different client IDs, it can use a total ordering on client IDs to determine which one is the “winner” and perform read repair
How to implement a linearizable CAS operation in a distributed, replicated system
ABD algorithm is not able to implement CAS, as different replicas may see operations in a different order, reaching inconsistent conclusions about whether a particular CAS operation succeeded or not
to implement linearizable CAS, use total order broadcast
broadcast every operation we want to perform
when an operation is finally delivered, it can be executed