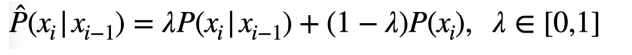Document Analysis
1/203
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
204 Terms
structural ambiguity definition
when a grammar can assign more than one parse to a sentence
types of structural ambiguity
attachment ambiguity, coordination ambiguity
attachment ambiguity definition
a particular constituent can be attached to the parse tree at more than one place, e.g. “We saw the Eiffel Tower flying to Paris.”
coordination ambiguity definition
ambiguity that occurs from the use of coordinators such as ‘and’, ‘or’, e.g. “old men and women”
part-of-speech tagging
the process of assigning a part-of-speech to each word in a text (=part-of-speech disambiguation)
part-of-speech ambiguity
words are ambiguous, they may have more than one possible part-of-speech
part-of-speech disambiguation
determining the correct part-of-speech for a word in a text (=part-of-speech tagging)
BIO notation
tagging notation for tokens/characters where B = beginning of chunk immediately following different chunk, I = inside chunk, O = outside chunk.
Universal dependencies
a framework for consistent annotation of grammar (parts of speech, morphological features, and syntactic dependencies) across different human languages
multilingual word embeddings
embeddings in a word embedding space that is shared across multiple languages, such that similar words in different languages are close
two methods for multilingual word embedding constructiong
supervised (use parallel corpus to learn mapping) or unsupervised (use adversarial training to learn mapping)
supervised approach to multilingual word embeddings
Given word vectors x_i from language A, y_i from language B, small dictionary (x_i, y_i), learn vector mapping W s.t. y_i = W x_i, W is orthogonal
Train by minimising loss on supervised set (sum(l(W x_i, y_i)/n).
Use Euclidean loss, or Cross-domain Similarity Local Scaling
unsupervised approach to multilingual word embeddings
Given word vectors x_i from language A, y_i from language B, learn vector mapping W s.t. y_i = W x_i, W is orthogonal
Key idea: employ discriminator D to distinguish samples from WX and Y
MUSE
Multilingual Unsupervised and Supervised Embeddings
A Python library for multilingual word embeddings
low resource language
languages which lack large monolingual or parallel corpora and/or manually crafted linguistic resources sufficient for building statistical NLP applications
problems for low resource languages
– SOTA NLP models require large amounts of training data and complex language-specific engineering
– Language-specific engineering is expensive, requiring linguistically trained speakers of the language
reasons why work on low resource languages is important
preservation
emergency response
educational applications
monitoring demographic and political processes
knowledge expansion
machine learning methods suitable for low resource NLP
active learning
transfer learning
multi-task learning
learning-to-learn
meta-learning
semi-supervised learning
dual learning (E → F, F → E)
unsupervised learning
types of unsupervised learning for low resource languages
unsupervised POS tagging
unsupervised syntactic parsing
cross-lingual transfer learning
train a model on one language and apply it to another
also includes transfer of annotations, like POS tags, via cross-lingual bridges, and transfer of features
XLM
cross-lingual language model
BERT type model trained on 15 languages
XLM training
One method of pretraining used for XLM is translation language modelling (TLM). Concatenate parallel sentence pairs from Wikipedia in different languages, and randomly mask words in both sentences for MLM.
intrinsic evaluation
direct quality of performing a test task, e.g. evaluate POS tagging by comparison to a gold standard/ground truth
extrinsic evaluation
test whether the output is useful for downstream tasks e.g. evaluate summarisation by implementing in an information retrieval system
technique for small datasets?
cross validation
purpose of splitting dataset
split into
train (for training model)
validation (for tuning hyperparameters)
test (for evaluating model)
accuracy
number of correct predictions / total number of instances
do NOT use for imbalanced data
precision
TP / (TP + FP)
recall
TP / (TP + FN)
F-measure
F_a = 1/(a/precision + (1-a)/recall), a:[0,1]
AUC
area under the curve
ROC
receiver operating characteristics
AUROC
area under receiver operating characteristics
allows for trade-off between precision and recall
plot false positive rate (FPR) on x-axis, true positive rate (TPR) on y-axis, and measure area beneath.
false positive rate
FP/(FP+TN)
true positive rate
TP/(TP+FN)
meaning of AUROC=0.5
random model
meaning of AUROC=1
perfect classifier
good evaluation metric for semantic parsing
accuracy
UAS
unlabelled attachment score
for dependency parsing, proportion of words whose head is correctly assigned
LAS
labelled attachment score
for dependency parsing, proportion of words whose head is correctly assigned with the right dependency label
evaluation metrics for dependency parsing
precision and recall of unlabelled/labelled attachment score
macro-averaging precision/recall
evaluation strategy for multi-class classification
arithmetic mean of precision/recall for each class
micro-averaging precision/recall
evaluation strategy for multi-class classification
don’t treat classes as equal (that’s macro) - aggregate the contributions of all classes by calculating precision/recall with every instance.
evaluation metric for named entity recognition
macro-averaged precision/recall
evaluation metric for multi-label classification
macro-averaged precision/recall
evaluation metric for coreference resolution
mean average precision / mean reciprocal rank
average precision
for a single query q with m relevant documents
AP(q) = sum(Precision(R_k) for k in 1..m)/m
where R_k is the set of ranked retrieval results from the top document down to the kth relevant document
mean average precision
mean of the average precision score across many queries
mean reciprocal rank
averaged inverse rank of the first relevant document
tasks that use Term Overlap Evaluation (TOE) Metrics
image caption generation, machine translation, text simplification, text summarisation, question answering, chatbots
popular Term Overlap Evaluation (TOE) Metrics
BLEU, ROUGE
BLEU
BiLingual Evaluation Understudy
n-gram precision = (number of n-grams in both texts)/(number of n-grams in generated text)
BLEU = exp (sum(log(p_n), n=1..N)/N)
May use smoothing to avoid log0
meaning of BLEU=1.0
perfect match
meaning of BLEU=0.0
perfect mismatch
ROUGE
Recall-Oriented Understudy for Gisting Evaluation
ROUGE-n: overlap of n-grams between system and gold standard
count(matching n-grams in generated text)/count(n-grams in reference summaries)
Should be used instead of BLEU for summarisation and simplification, as precision is trivial.
SCU
Summarisation Content Unit
clause-length semantic units shared by some number of reference summaries.
based on meaning, not n-grams.
types of baseline models
trivial models (always predict common class, guess randomly etc.)
simple models (e.g. logistic regression)
well-known methods for a task
current SOTA
ablation study
systematically remove aspects of a model (e.g. feature sets) to verify necessity
evaluation - what to compare?
algorithms
feature sets
baselines
ablation studies
different datasets
semantics
a branch of linguistics and logic concerned with meaning
difference between semantics and syntax
semantics is meaning, syntax is the structure of language
components of first order logic
constants, functions, variables, predicates, logical connectives, quantifiers
semantic parsing
the transformation of sentences to a meaning representation (usually in lambda calculus)
semantic parsing datasets
GEO, ATIS, WikiSQL
predicate-argument semantics
light semantic representation - represent meaning through predicates (properties characterising subjects) and arguments (which are constrained)
homonymy
multiple words coincidentally share an orthographic form (e.g. bank)
polysemy
a word has multiple different but related senses (e.g. solution)
homophone
same pronunciation but different spelling (e.g. wood/would)
homograph
same orthographic form, but different pronunciation (e.g. bass)
hyponym
one sense is a hyponym of another sense if it is more specific (e.g. ‘car’ is a hyponym of ‘vehicle’)
hypernym
one sense is a hypernym of another sense if it is more general (e.g. ‘colour’ is a hypernym of ‘red’)
WordNet
hand-constructed database of lexical (ontological) relations
distributional hypothesis
words with similar meanings tend to appear in similar contexts
distributional word representations
a way to represent words as vectors describing the contexts in which they appear
coreference resolution
solve referential ambiguity by determining which text spans refer to the same entity
mentions (coreference resolution)
text spans that mention an entity
coreferent (coreference resolution)
text spans that refer to the same entity
antecedent (coreference resolution)
(of a mention) coreferent mentions earlier in the text
strategy for coreference resolution of pronouns
search for candidate antecedents (any noun phrase in preceding text)
match against hard agreement constraints (e.g. ‘he’ —> singular, masculine, animate, third person)
select with heuristics (recency, subject > object)
strategy for coreference resolution of proper nouns
match syntactic head words of the reference with the referent
include a range of matching features: exact match, head match, string inclusion
Gazetteers of acronyms (ANU=Australian National University)
strategy for coreference resolution of nominals
requires world knowledge (e.g. that Apple Inc. is a firm and China is a growth market)
coreference resolution algorithms
identify text spans mentioning entities
1.1 get noun phrases (e.g. by constituent parsing)
1.2 filter with simple rules (e.g. remove numbers, nested noun phrases)
cluster mentions
2.1 Mentioned-based models: supervised learning or ranking
2.2 Entity-based models: clustering
syntactic constituency
groups of words behaving as single units (constituents)
context free grammar
formal system for modelling constituent structure in natural language
set of productions
lexicon of words (terminals)
set of symbols (non-terminals)
start symbols
parse tree
representation of a sequence of CFG production expansions (derivation)
probabilistic context-free grammar
CFG where each production has an associated probability (for resolving structural ambiguity)
estimate probabilities with maximum-likelihood estimation using a treebank (P(a—>b) = count(a—>b)/count(a))
treebank
a corpus in which each sentence is annotated with a parse tree
CFG equivalence
two grammars are equivalent if they generate the same language (i.e., the same set of strings)
Chomsky Normal Form (CNF)
The right-hand side of each rule either has two non-terminals or one terminal, except 𝑆 → 𝜖 (where 𝜖 is the empty string)
constituency parsing
Given a sentence (i.e., a sequence of terminals) and a CFG, determine whether the sentence can be generated by the grammar, and return parse tree(s)
CKY algorithm
algorithm for constituency parsing
based on dynamic programming (derive parse trees for constituents)
purpose of [CLS] token in BERT
added to the beginning of a sentence as a single representation for the entire sentence
used for sentence-level classification
goal of language models
to predict upcoming words
applications of language models
speech recognition, spelling correction, collocation error correction, machine translation, summarisation etc.
technique used to compute 𝑝(𝑤1, 𝑤2, … , 𝑤𝑙)
chain rule (𝑃 (𝑥1, 𝑥2, … , 𝑥𝑛) = 𝑃 (𝑥1) 𝑃 (𝑥2 | 𝑥1) 𝑃 (𝑥3 | 𝑥1, 𝑥2) … 𝑃(𝑥𝑛|𝑥1, 𝑥2, … , 𝑥𝑛−1))
Markov assumption
𝑃(𝑤𝑘|𝑤1:𝑘−1) ≈ 𝑃(𝑤𝑘|𝑤𝑘−1)
(N-1)th-order Markov Assumption
𝑃(𝑤𝑘|𝑤1:𝑘−1) ≈ 𝑃(𝑤𝑘|𝑤𝑘−N+1:k-1)
method to handle small probability multiplication for language modelling
log probabilities
method to address language model overfitting
smoothing (prevent a language model from assigning a zero probability to an unseen event)
adjust low probabilities (such as zero probabilities) upwards and high probabilities downwards
interpolation smoothing
mix with lower order n-gram probabilities using a set of lambda hyperparameters