H7 - Data processing architectures
1/15
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
16 Terms
Lambda architecture
figuur
streaming and batch layer
serving layer
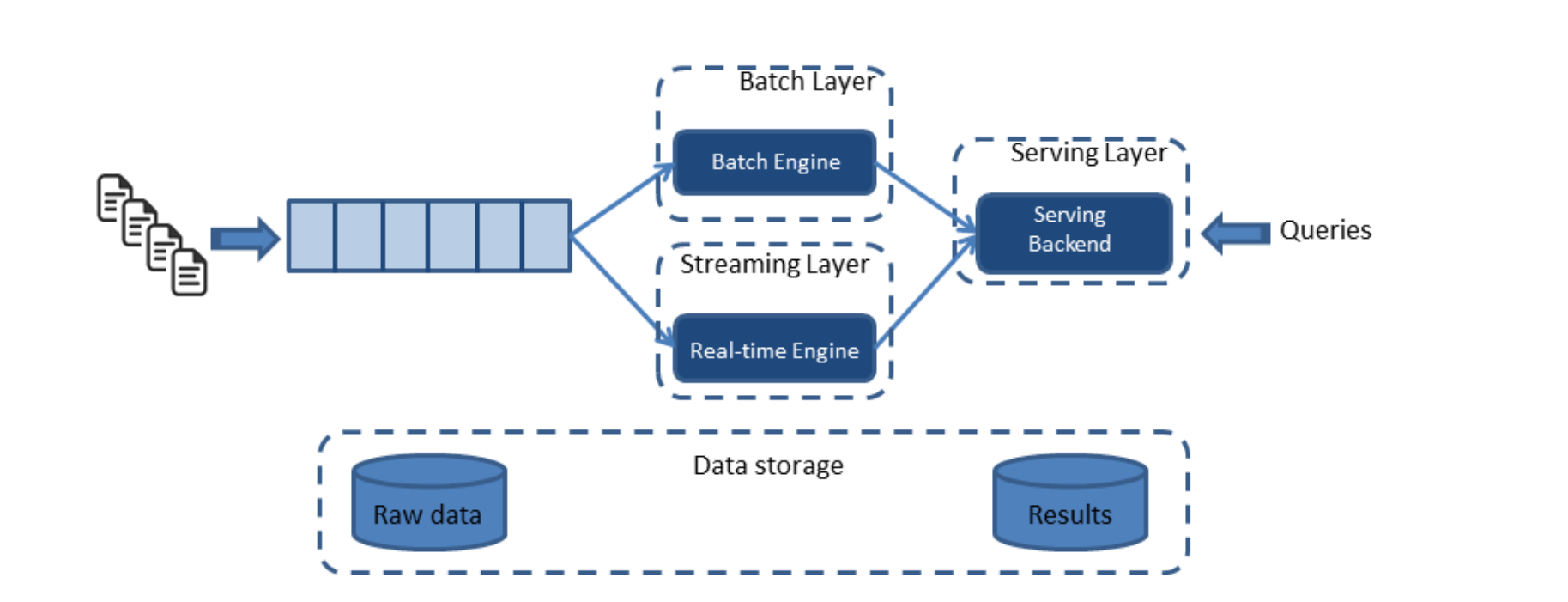
Streaming layer
Handles all requests that require low latency
Recent data only, providing a real-time view on that recent data
Technology used e.g. Apache Storm or Spark Streaming
Output usually stored in NoSQL DBs (e.g. Cassandra)
Batch layer
Manages master dataset (all data) - Append-only set of raw data usually on distributed filesystem
Computes batch views (e.g. via Apache Hadoop)
Accurate → processes all data when generating views
Output usually stored in read-only database
serving layer
Serves output from both batch and speed layer for querying
Stored on e.g. Hbase (open-source non-relational distributed database modeled after Google BigTable)
Lambda architecture
downsides
Need to maintain two complex distributed systems (batch and stream)
Need to create apps for two different systems
Streaming: Storm / Spark Streaming
Batch: Hadoop
Debugging and interaction with products is different
Implemented in Spring XD, which was given End-of-Life (EOL) in 2017
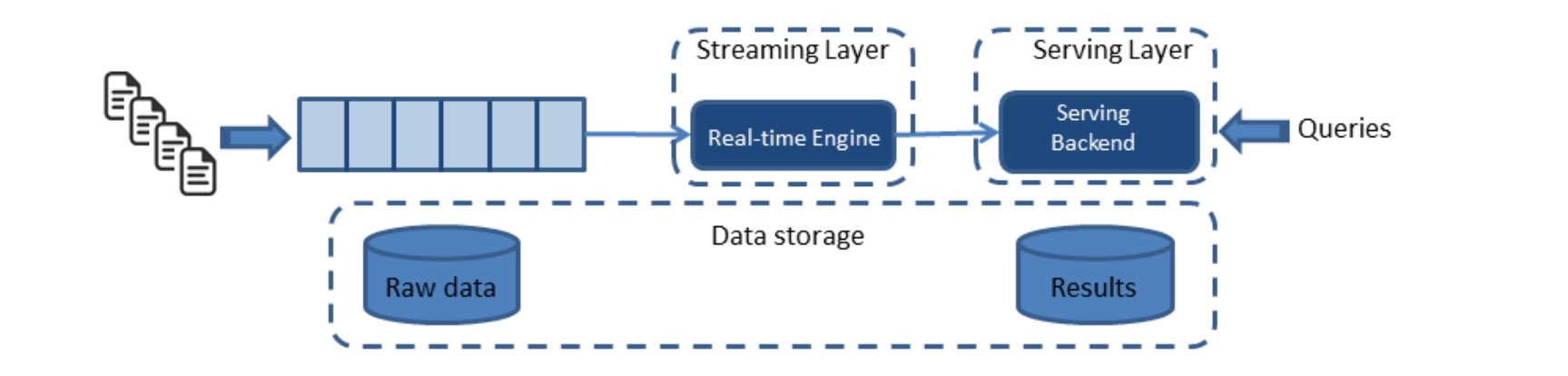
Kappa architecture
figuur
algemeen
Simplification of Lambda architecture (Kappa origin: LinkedIn)
In short: remove the batch processing system
Make the streaming system also deal with historical data
Data stored in a Kappa architecture is an append-only immutable log (e.g. Kafka)
Log streams data through stream processing system e.g. Apache Storm, Spark Structured Streaming, Kafka Streams, Flink
Only one (streaming) code set needs to be maintained
Output stored in auxiliary stores for serving (any type of DB suffices)
Can be deleted & regenerated from source of truth (data on immutable log)
Kappa architecture
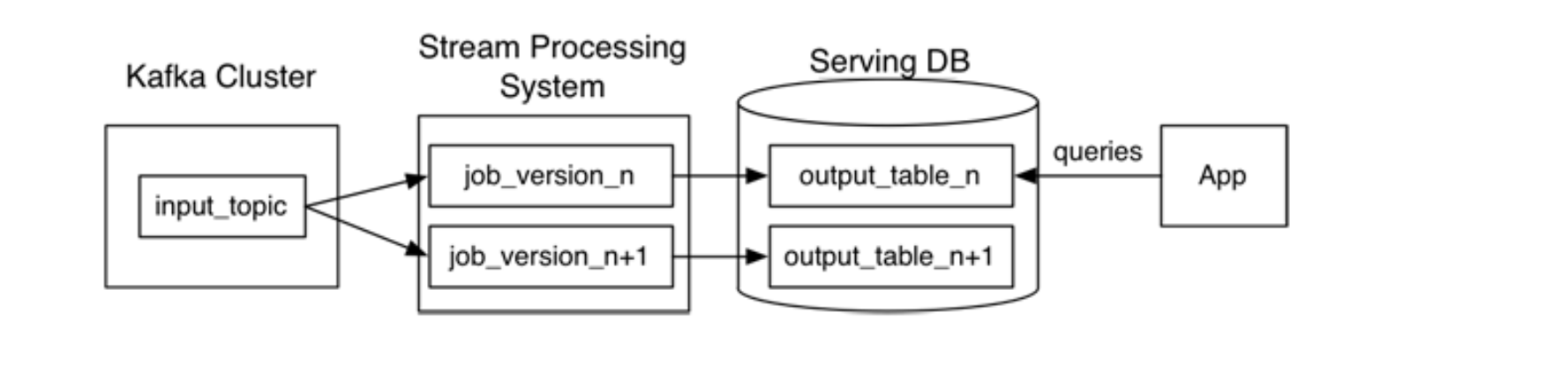
dealing with processing changes
figuur
Use e.g. Kafka to store incoming data in an immutable log
Retain full log of data you wish to reprocess (retention interval)
Allows multiple subscribers
When wishing to reprocess
Start second instance of stream processing job
Begin processing from beginning of retained data
Direct output to a new output table
When second job catches up
Switch application to read from new table
Stop old version of the stream processing job and optionally delete old output table
Kappa architecture
conclusion
Four pillars
Data is immutable
Everything is a stream
Single stream engine is used
Data can be replayed
Only need to do reprocessing when you change the processing code
Downsides
Storing and managing large volumes of logs over time can be resource-intensive
Extra temporary storage required when reprocessing
Not ideal for cases where batch processing are clearly more suited (e.g. nightly analytical summary jobs) due to lower throughput
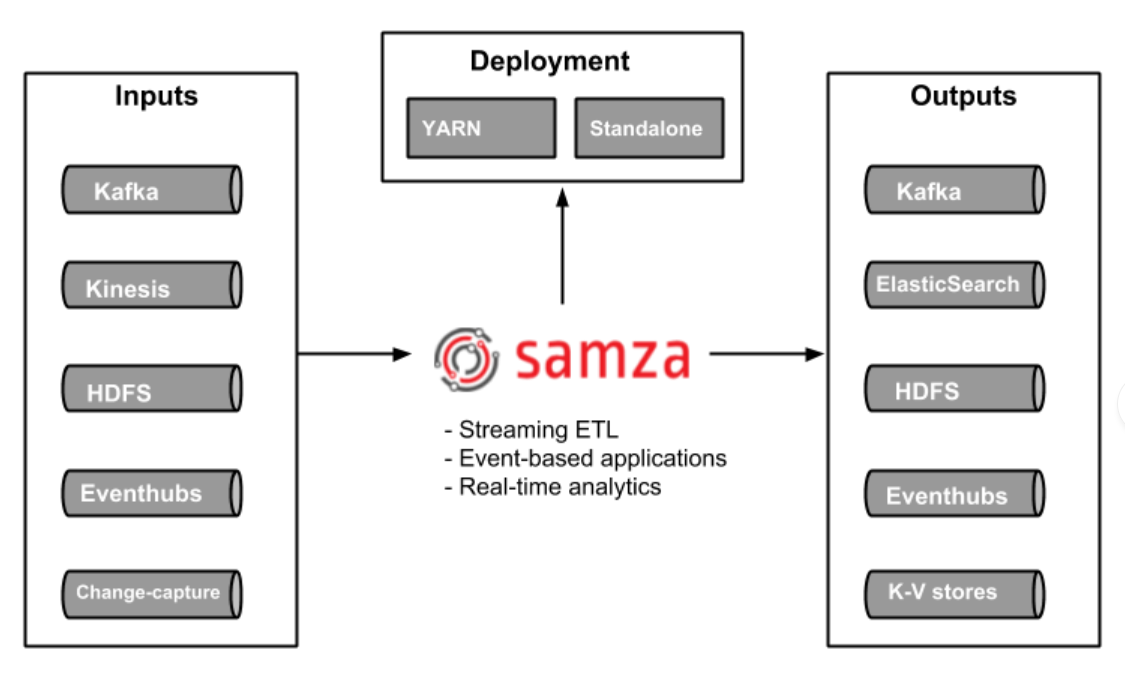
Apache samza
algemeen
figuur
Stream processing based on Kappa architecture, originated at LinkedIn (2013)
Optimised for fast, near-realtime processing (true streaming)
Inherent support for state
Scalable
LinkedIn has > million messages/s processed
Kafka + YARN / standalone
Not really tailored to Kubernetes
APIs: low-level + stream + Samza SQL
Fault tolerant
At-least-once message guarantees
Notable deployments
LinkedIn (origin), Slack, Ebay, TripAdvisor
Apache samza
voor en nadelen
voordelen:
Fault tolerant and high performance due to reliance on Kafka
If you already use Yarn and Kafka, Samza can be a natural choice
Low latency, high throughput, mature and tested at scale
nadelen:
Tightly coupled with Kafka and Yarn, Kubernetes not a target
At least once guarantees
Lack of advanced streaming features like watermarks, sessions, triggers, etc.
Not seeing much activity lately
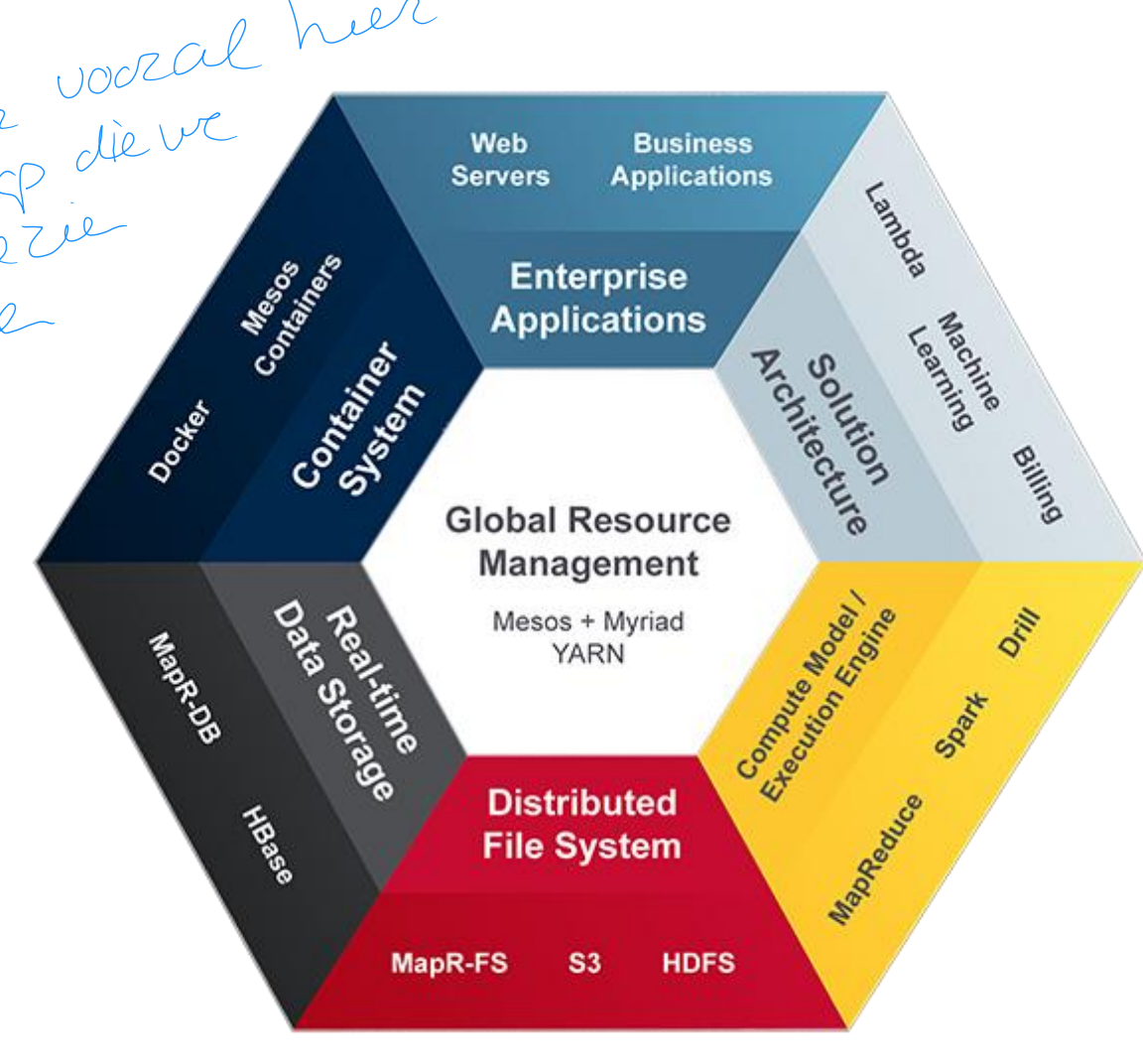
Zeta architecture
7 componenten (ezelsbrug)
figuur!
ESC DRCG
7 components (Zeta = 7)
Enterprise applications
Solution architecture
Compute model / execution engine
Distributed file system
Real-time data storage
Container system
Global Resource Management
Google one of the pioneers
Properties
All servers under supervision of global resource management and participate in Distributed File System
Dynamic allocation of resources: resources do not have to be hardwired to specific applications, reducing cost
Data locality: store and process data where it was created
cloud dataproc
Managed Spark, Flink, Presto and Hadoop service integrated with Google Cloud Platform
Ease-of-use
Create, monitor, delete Cloud Dataproc clusters and jobs through Google Developers console
Latest stable Spark, Flink and Hadoop software releases
Low-cost
Dataproc solutions costs 0.01 $ per virtual CPU in your cluster per hour
But this comes on top of compute engine + disk storage + cloud storage + monitoring (also billed per hour)
Speed: cluster start and stop operations take 90 seconds or less
cloud dataflow
Unified programming model (donated to Apache Beam)
For building batch and streaming data processing pipelines
Monitor their execution
Google-proprietary solution, integrated with Google Cloud Platform
Fully managed service
Handles resource lifetime (serverless)
Dynamically provision resources to reach latency goal or high utilization efficiency
Competitive pricing (retrieved 26/04/2025)
Microsoft
azure hdinsight
User-friendly set up of open-source big data solutions + cluster
Managed Hadoop, Spark service (PaaS)
Hive, Kafka, etc. available
.NET SDK and Powershell integration
On top of Microsoft Azure Cloud, integrating with Data Factory and Data Lake Storage
Microsoft
azure stream analytics
Microsoft Azure based stream processing solution
Standalone Microsoft solution
SQL-like language to transform, enrich and correlate data
Pro: easy to use, easy to scale, good integration with Azure, cheap
Con: proprietary / vendor lock, limited integration with non-Azure products, aimed at on-complex streaming applications
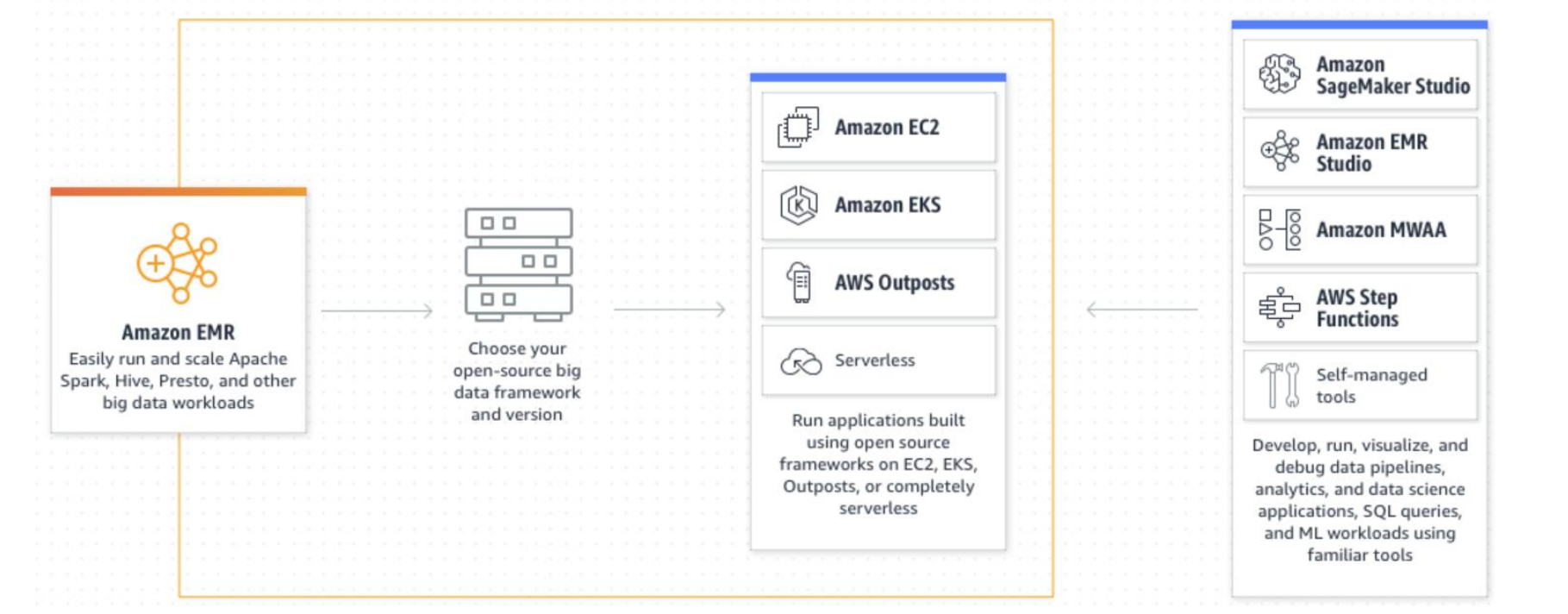
Amazon
elastic map reduce (EMR)
Amazon managed Spark, Hive, Presto framework on EC2
Processes data from HDFS, Amazon S3, DynamoDB, Kinesis
CloudWatch monitors performance and can trigger scale-up / scale down
Notable users: Netflix, Expedia, Yelp
Amazon
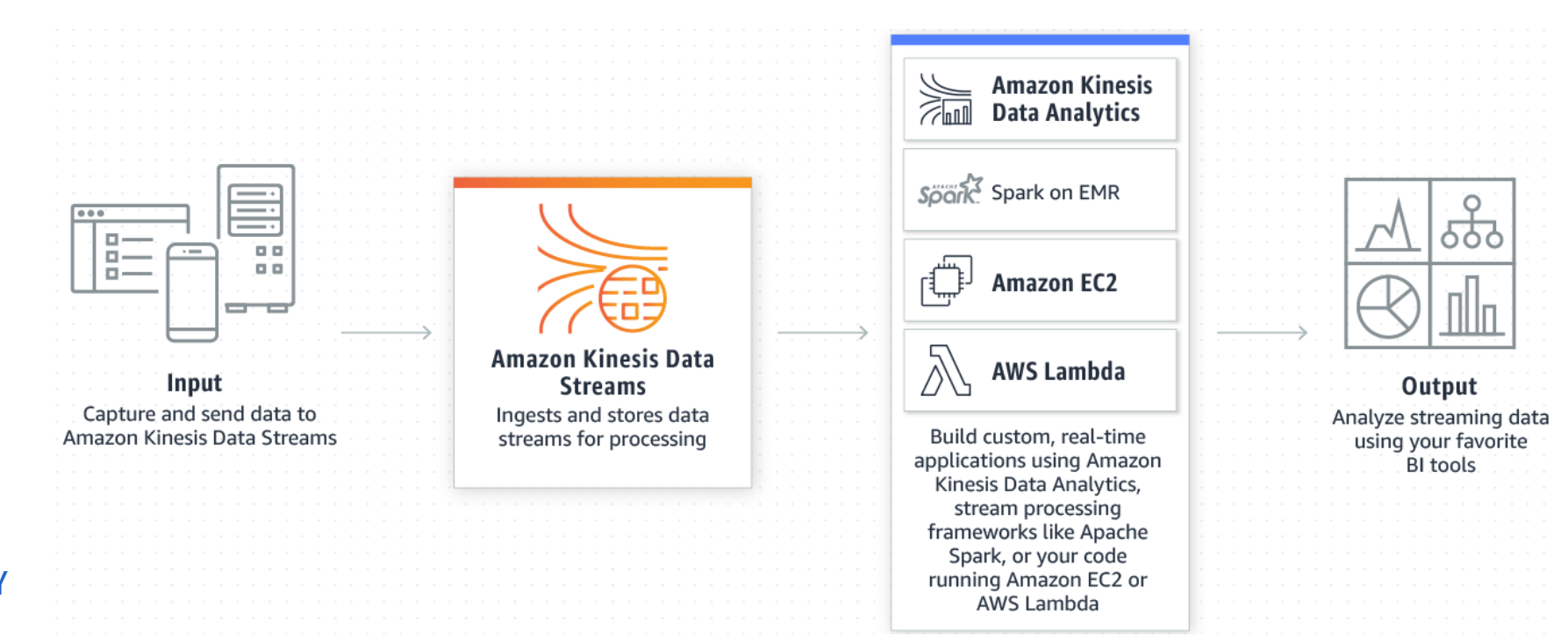
Kinesis
Amazon’s AWS stream processing solution
Collect and process data streams in real time (proprietary or Spark on EMR)
Thread with care when choosing the proprietary solution
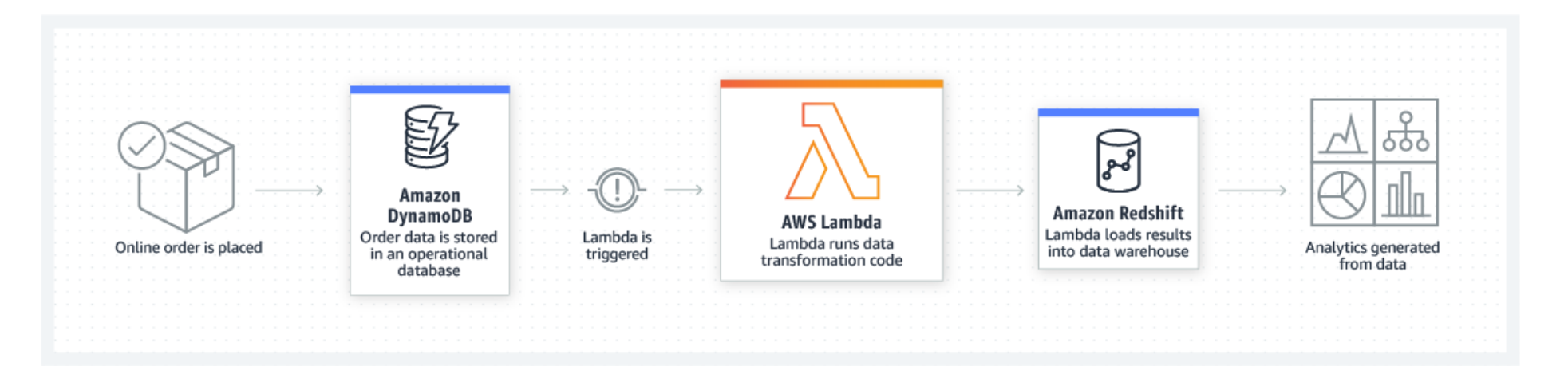
Amazon lambda
serverless architecture
Build and run applications without thinking about servers (function-as-a-service)
Run code without provisioning / managing servers, just provide triggers (e.g. response time) which will be monitored
Other Cloud vendors soon followed and released their own serverless solutions
Hortonworks + Cloudera
Hortonworks: US-based company offering enterprise data processing solutions (Hadoop/Spark)
Cloudera: US-based company focussed on enterprise data cloud solutions (private + public)
Merged in January 2019, considered one of the larger players now in enterprise data solutions
High focus on open-source solutions and paid-for support
More than likely surviving due to the big cloud vendors initially not focussing on the on-premise market (note: this is changing!)