CIS 1210- finals advanced topics Hashing - Testing Sortedness
1/35
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
36 Terms
What operations do hash tables support?

What is a direct-address table?
There is a universe U = {0, 1, …, m - 1} of m keys where m is not too large and the table has m slots from T[0…m -1]. If a slot is empty it contains nil.
What are the search, insert, and delete operations in a direct address table?

What is the down-side of direct address tables?
While the look-ups, inserts, and deletes are O(1), the table takes O(|U|) space which is impractical. Also, the size of K, the actual keys in the table, might be a lot smaller than U which leads to a lot of wasted space.
Is direct adressing hashing?
no
Whats the difference between direct addressing and hashing?
With direct addressing, an element with key k is stored in slot k. With hashing, this element is stored in slot h(k) as determined by the hash function h.
What does the hash function h do?
h maps the universe of keys to slots of a hash table T[0 … m - 1] of size m. Where the size of the table, m « |U|. We say that an element with key k hashes to slot h(k). We also say h(k) is the hash value of key k. The hash function reduces the range of array indices and hence the size of the array. Instead of a size of |U|, the array can have size m.
Pros and Cons of Hashtables with respect to direct addressing.
Pros: save space
Cons: search, insert, delete are average O(1). Worst case for some particular insert or lookup may be O(n) where n is the number of elements in the table instead of O(1).
What is a collison
2 or more keys hash to the same slot in the table
Good hashing functions minimize collisions, but we still need a method for resolving collisions. How do we resolve collisions?
chaining
open addressing
What is collision resolution by chaining?
Place all the elements that hash to the same slot into the same linked list. The linked list can be singly linked or doubly linked, but doubly linked is better because deletion is faster. Slot j will contain a pointer to the head of the list. If there are no elements hashed to slot j, j contains nill.
What do insert, search, and delete look like in hashing with chaining?

What is the load factor?
Where m is the number of slots and n is the number of elements stored in the table, the load factor is n/m.
What is the worst case behavoiur of hashing with chaining?
All n keys hash to the same slot, creating a list of n. The worst-case time for searching is thus Theta of n plus the time to compute the hash function- no better if u used one linked list for all elements. But we don’t use
What does the average-case performance of hashing depend on?
It depends on how well the hash function h distributes the set of keys to be stored among the m slots, on the average. We seek a hash function that evenly distributes the universe U of keys as evenly as possible among the m slots of our table. That is we want our hash table to satisfy SUHA.
What does the Simple Hashing Assumption (SUHA) state?
SUHA states that any key k is equally likely to be mapped to any of the m slots of our hash table T, independently of where any other key is hashed to. In other words, the probability of hashing some key k not already present into any arbitray slot in T is 1/m.
In hashing with chaining what do we need to consider to compute the expected runtime of search.
We assume computing our hash function and accessing the list at that slot is O(1). Thus, the time to search for key k depends linearly on the length of the list T[h(k)]. We need to find the expected number of elements that are scanned. There are two cases succesful and unsuccesful.
Consider the case where the search is unsuccesful. That is prove the theorem that in a hash table in which collisons are resolved by chaining, an unsuccesful search takes average-case O(1 + a) under the assumption of SUHA.

Consider the case of a succesful search in chaining.


What is the running time of insert, delete, and search in hashing with chaining?
insert and delete are O(1) worst case. Search takes expected O(1 + a) time where a = n/m.
What is open-addressing?
In open-addressing, all elements occupy the hash-table itself. That is, each table entry contains either an element of the dynamic set or NIL. When searching for an element, we systematically examine table slots until either we find the desired element or we have ascertained that the element is not in the table. Thus, in open addressing, the hash table can “fill up” so that no further insertions can be made, one consequence is that the load factor a can never exceed 1.
The load factor can never exceed ____ in open adressing
1
In open-adressing what do we do instead of looking at pointers in a linked list?
We compute a probe sequence so we don’t have to store extra memory
How do we perform an insertion on open-addressing?
we successively examine or probe the hash table until we find an empty slot in which to put the key. The sequence of positions probed depends on the key being inserted, so searching for a spot isn’t going to be flat out Theta(n).
modified hash function for open-addressing
The old hash function just took in a universe of keys. Now it takes in a universe of keys and a probe number. Every key in open-addressing requires the probe sequence (h(k, 0), h(k, 1), …, h(k, m - 1)) be a permutation of 0 to m -1 so that every slot is considered a position for a new key.
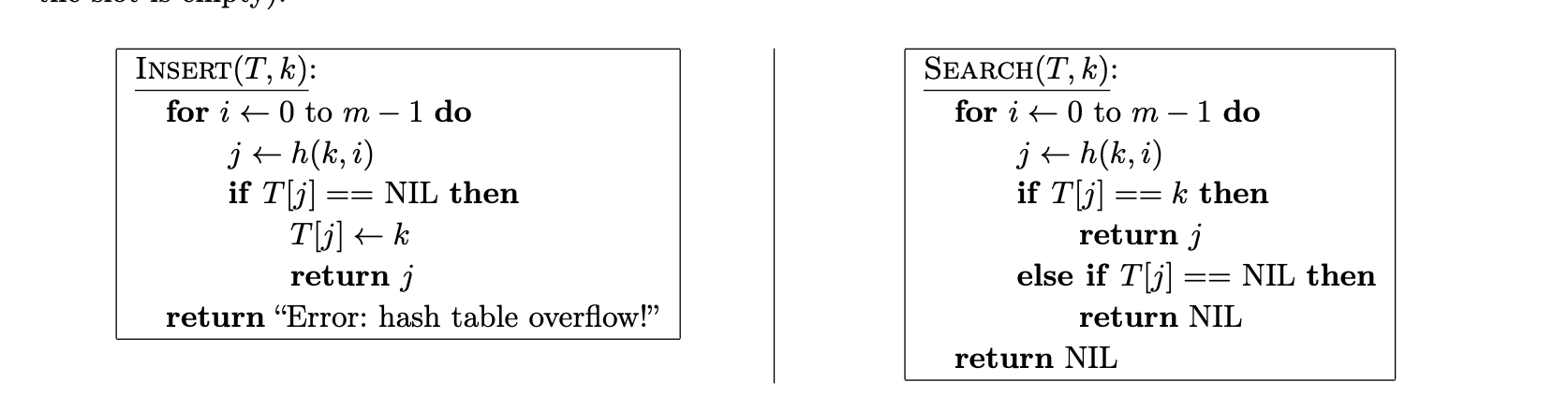
What is insert and search for open-addressing?
What does deletion from an open-address table look like?
When we delete a key from slot i, we cannot simply mark that slot as empty by storing NIL in it. If we did, we might be unable to retrieve any key k during whose insertion we had probed slot i and found it occupied. We replace it with DELETED.
What is linear probing.
Given an ordinary hash function h’: U → {0, 1, … m - 1} which we refer to as an auxiliary hash functino the method of linear probing uses the hash function h(k, i) = (h’(k) + i) mod m for i = 0, 1, …, m - 1. Given key k, we first probe T[h’(k)] and then wrap around until the slot T[h’(k) - 1']. Because the initial probe determines the entire probe sequence, there are only m distinct probe sequences.
How many distinct probe sequences are in linear probing
m
What is bad about linear probing
While easy to implement it doesn’t work well in practice because it suffers from primary clustering. Long runs of occupied slots build up, increasing the average search time. Clusters arise because an empty slot preceded by i full slots gets filled next with probability (i + 1)/m. Long runs of occupied slots tend to get longer and the average search time increases.
What is quadratic probing?
h(k, i) = (h’(k) + c1i + c2i²) mod m where c1 and c2 are constants. The initial probed spot is T[h’(k)]. Later positions are offset by amounts that depend in a quadratic manner on the probe number i. If two keys have the same initial probe positon then their probe sequences are the same. This leads to a milder form of clustering called secondary clustering. The initial probe determines the entire probe sequence so there are m distinct possible probe sequences.
What is double hashing.
It uses the hash function h(k, i) = (h1(k) + ih2(k)) mod m where both h1 and h2 are auxiliary hash functions. The initial probe goes to position T[h1(k)] and successive probe positions are offset by h2(k) modulo m.
In open addressing at most one element occupies each slot so n <= m which implies a <= 1.


succesfull search open-addressing double hashing

Search in open-addressing using double hashing succesful and unsuccesful expected runtimes
O(1/(1 - a)) and O(1/a * lg 1/(1 - a))