DAT255: Deep Learning Lecture 7 - Sequences and Time Series
1/15
Earn XP
Description and Tags
Flashcards based on lecture notes about sequences, time series, and recurrent neural networks.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
16 Terms
What are Sequences?
Ordered series of data, like natural language, time series, audio, video, or DNA.
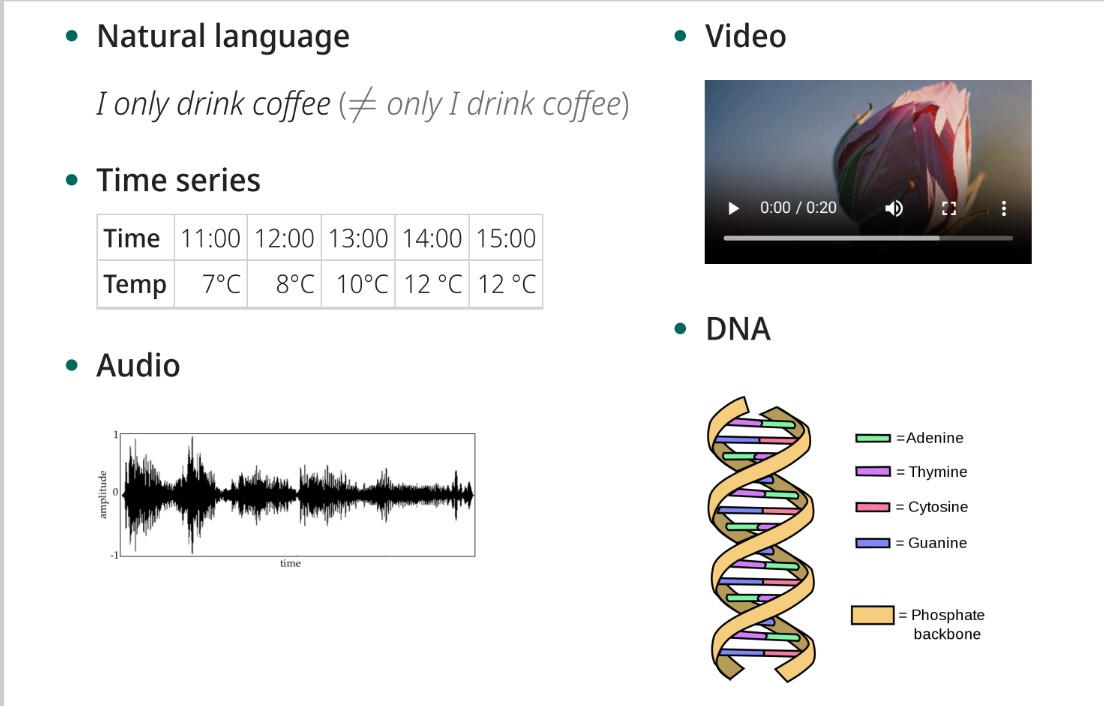
Give examples of Sequence Classification Tasks.
Speech recognition, fraud detection, medical diagnostics, sentiment analysis, topic classification.
Give examples of Forecasting tasks.
Predicting weather, energy prices, or stock prices.
Give examples of Sequence-to-sequence learning tasks
Language translation, image captioning, or text summarization.
How do sequence classification methods work with 1D sequences?
Instead of needing patterns between neighboring pixels in 2D, you look for patterns between neighboring elements in 1D.
What is cross-correlation?
The operation is similar to convolution but reverses one of the functions.
In forecasting, what assumption is typically made about recent data?
Recent data is more informative than old data.
What is a limitation of standard neural networks?
Networks without state, unable to 'remember' previous inputs.
How is state introduced in recurrent neural networks?
Each node stores its previous output.
What is the simplest possible autoregressive forecast model?
The value tomorrow is the same as the value today. yi = yt-1
What is a more advanced autoregressive forecast?
Accounts for the value tomorrow being a weighted sum of previous time steps plus a noise term.
What are two common approaches to mitigate vanishing/exploding gradients in RNNs?
LSTMs and GRUs.
When stacking recurrent layers in a deep RNN, what is important?
Intermediate layers should return the entire sequence.
What are some tricks to efficiently train RNNs?
Use saturating activation functions (tanh, sigmoid), layer normalization, and recurrent dropout.
What is one bonus trick for training RNNs using CNN processing?
Extract small-scale patterns with convolutional layers first, then apply recurrent layers.
What do bidirectional RNNs do?
Process sequences both forwards and in reverse.