Thẻ ghi nhớ: DPL302m (FPTU_AI) | Quizlet
1/99
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
100 Terms
D
What does the analogy AI is the new electricity refer to?
A: AI is powering personal devices in our homes and offices, similar to electricity.
B: Through the smart grid, AI is delivering a new wave of electricity.
C: AI runs on computers and is thus powered by electricity, but it is letting computers do things not possible before.
D: Similar to electricity starting about 100 years ago, AI is transforming multiple industries.
ACD
Which of these are reasons for Deep Learning recently taking off? (Check the two options that apply.)
A: We have access to a lot more computational power.
B: Neural Networks are a brand new field.
C: We have access to a lot more data.
D: Deep learning has resulted in significant improvements in important applications such as online advertising, speech recognition, and image recognition.
ABD
Recall this diagram of iterating over different ML ideas. Which of the statements below are true? (Check all that apply.)
A: Being able to try out ideas quickly allows deep learning engineers to iterate more quickly.
B: Faster computation can help speed up how long a team takes to iterate to a good idea.
C: It is faster to train on a big dataset than a small dataset.
D: Recent progress in deep learning algorithms has allowed us to train good models faster (even without changing the CPU/GPU hardware).
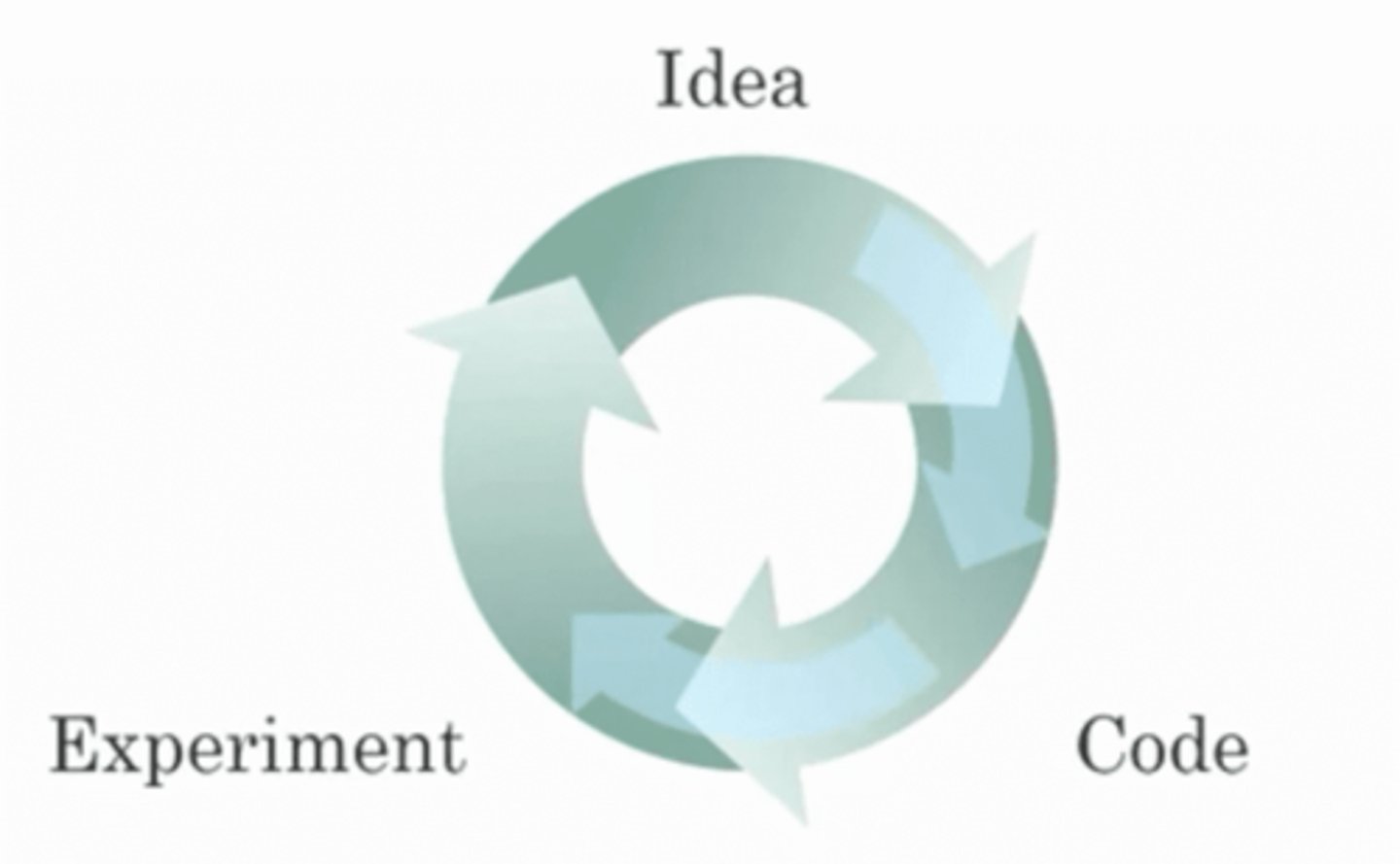
B
When an experienced deep learning engineer works on a new problem, they can usually use insight from previous problems to train a good model on the first try, without needing to iterate multiple times through different models. True/False?
A: True
B: False
Check [relu](https://en.wikipedia.org/wiki/Rectifier_(neural_networks)).
Formula:
f(x)=max(0,x)
𝑓
(
𝑥
)
=
𝑚
𝑎
𝑥
(
0
,
𝑥
)
Which one of these plots represents a ReLU activation function?
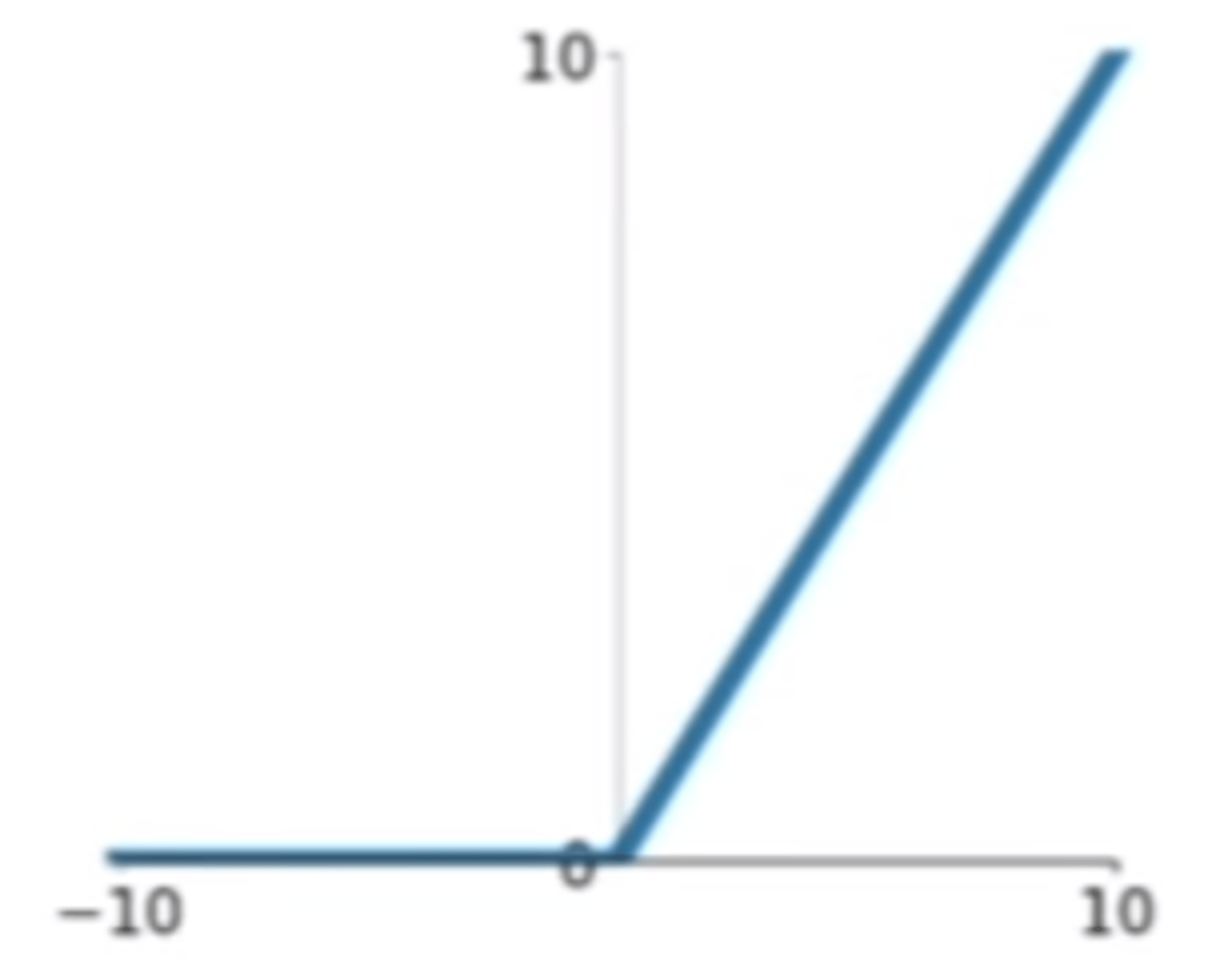
B
Images for cat recognition is an example of structured data, because it is represented as a structured array in a computer. True/False?
A: True
B: False
B
A demographic dataset with statistics on different cities' population, GDP per capita, economic growth is an example of unstructured data because it contains data coming from different sources. True/False?
A: True
B: False
AC
Why is an RNN (Recurrent Neural Network) used for machine translation, say translating English to French? (Check all that apply.)
A: It can be trained as a supervised learning problem.
B: It is strictly more powerful than a Convolutional Neural Network (CNN).
C: It is applicable when the input/output is a sequence (e.g., a sequence of words).
D: RNNs represent the recurrent process of Idea->Code->Experiment->Idea->....
D
In this diagram which we hand-drew in lecture, what do the horizontal axis (x-axis) and vertical axis (y-axis) represent?
A: • x-axis is the performance of the algorithm
• y-axis (vertical axis) is the amount of data.
B: • x-axis is the amount of data
• y-axis is the size of the model you train.
C: • x-axis is the input to the algorithm
• y-axis is outputs.
D: • x-axis is the amount of data
• y-axis (vertical axis) is the performance of the algorithm.
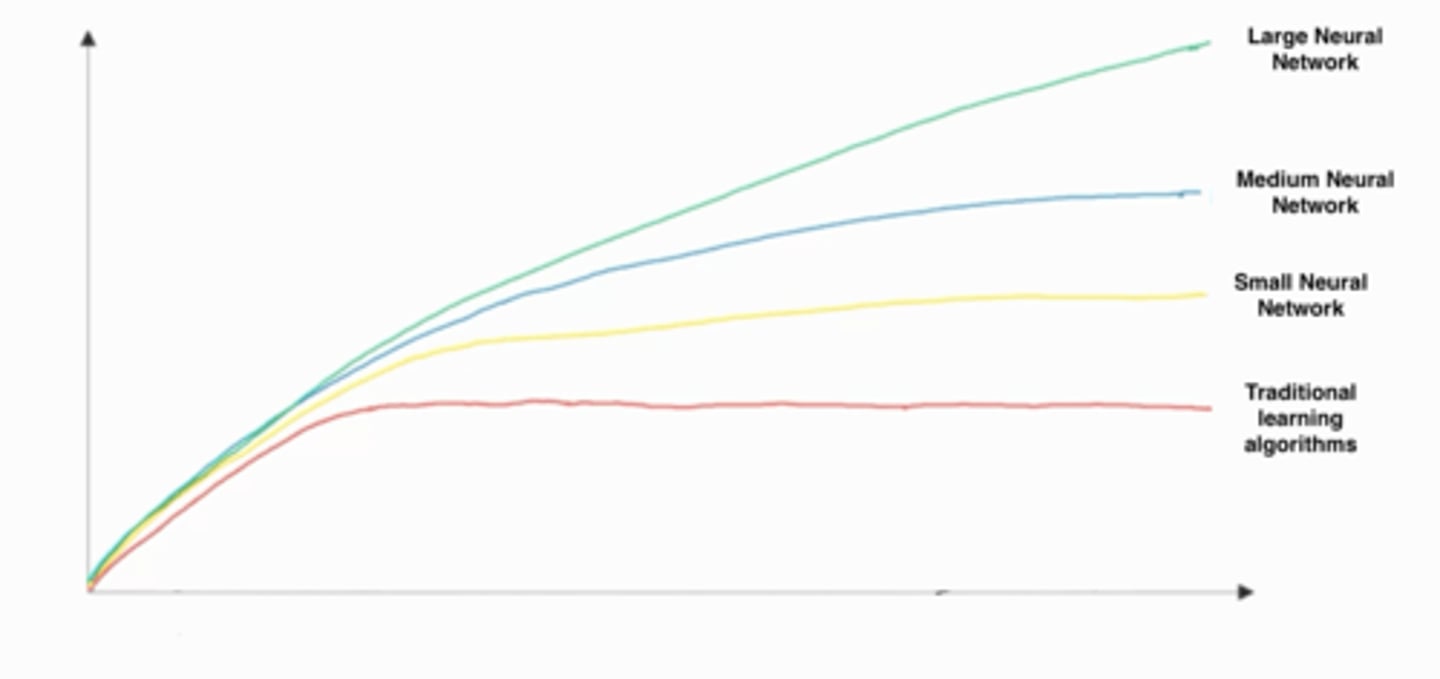
AB
Assuming the trends described in the previous question's figure are accurate (and hoping you got the axis labels right), which of the following are true?
A: Increasing the training set size generally does not hurt an algorithm's performance, and it may help significantly.
B: Increasing the size of a neural network generally does not hurt an algorithm's performance, and it may help significantly.
C: Decreasing the training set size generally does not hurt an algorithm's performance, and it may help significantly.
D: Decreasing the size of a neural network generally does not hurt an algorithm's performance, and it may help significantly.
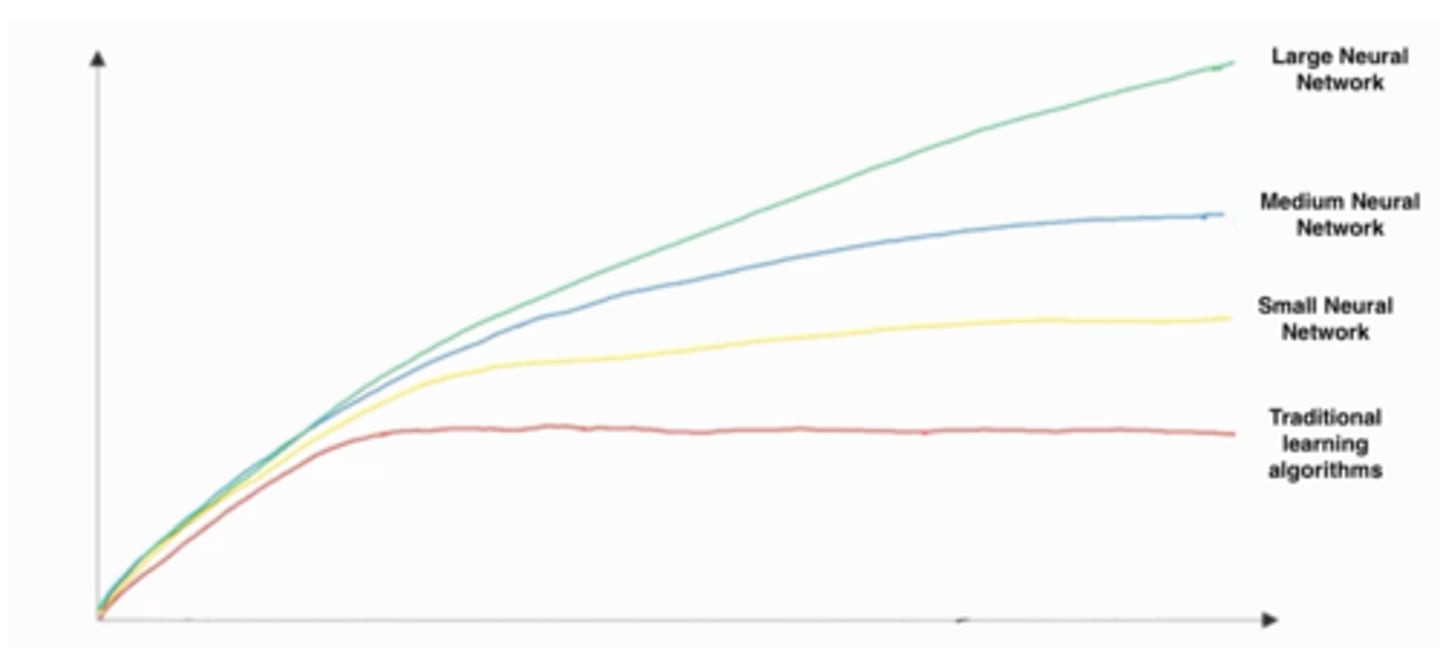
B
What does a neuron compute?
A: A neuron computes an activation function followed by a linear function (
z=Wx+b
𝑧
=
𝑊
𝑥
+
𝑏
)
B: A neuron computes a linear function (
z=Wx+b
𝑧
=
𝑊
𝑥
+
𝑏
) followed by an activation function
C: A neuron computes a function
g
𝑔
that scales the input
x
𝑥
linearly (
Wx+b
𝑊
𝑥
+
𝑏
)
D: A neuron computes the mean of all features before applying the output to an activation function
D
Which of these is the "Logistic Loss"?
A:
L(
y
^
,y)=|
y
^
−y|
𝐿
(
𝑦
^
,
𝑦
)
=
|
𝑦
^
−
𝑦
|
B:
L(
y
^
,y)=max(
y
^
−y,0)
𝐿
(
𝑦
^
,
𝑦
)
=
𝑚
𝑎
𝑥
(
𝑦
^
−
𝑦
,
0
)
C:
L(
y
^
,y)=|
y
^
−y
|
2
𝐿
(
𝑦
^
,
𝑦
)
=
|
𝑦
^
−
𝑦
|
2
D:
L(
y
^
,y)=−(ylog(
y
^
)+(1−y)log(1−
y
^
))
𝐿
(
𝑦
^
,
𝑦
)
=
−
(
𝑦
log
(
𝑦
^
)
+
(
1
−
𝑦
)
log
(
1
−
𝑦
^
)
)
A
Suppose img is a (32,32,3) array, representing a 32x32 image with 3 color channels red, green and blue. How do you reshape this into a column vector?
A: x = img.reshape((32323,1))
B: x = img.reshape((32*32,3))
C: x = img.reshape((1,32323))
D: x = img.reshape((3, 32*32))
D
Consider the two following random arrays "a" and "b":
```
a = np.random.randn(2, 3) # a.shape = (2, 3)
b = np.random.randn(2, 1) # b.shape = (2, 1)
c = a + b
```
What will be the shape of "c"?
A: c.shape=(3,2)
B: c.shape=(2,1)
C: Error
D: c.shape=(2,3)
C
Consider the two following random arrays "a" and "b":
```
a = np.random.randn(4, 3) # a.shape = (4, 3)
b = np.random.randn(3, 2) # b.shape = (3, 2)
c = a * b
```
What will be the shape of "c"?
A: (3,3)
B: (4,2)
C: Error
D: (4,3)
B
Suppose you have
n
x
𝑛
𝑥
input features per example. Recall that
X=[
x
(1)
,
x
(2)
...,
x
(m)
]
𝑋
=
[
𝑥
(
1
)
,
𝑥
(
2
)
.
.
.
,
𝑥
(
𝑚
)
]
. What is the dimension of
X
𝑋
?
A:
(1,m)
(
1
,
𝑚
)
B:
(
n
x
,m)
(
𝑛
𝑥
,
𝑚
)
C:
(m,
n
x
)
(
𝑚
,
𝑛
𝑥
)
D:
(m,1)
(
𝑚
,
1
)
D
Recall that `np.dot(a,b)` performs a matrix multiplication on a and b, whereas `a*b` performs an element-wise multiplication.
Consider the two following random arrays "a" and "b":
```
a = np.random.randn(12288, 150) # a.shape = (12288, 150)
b = np.random.randn(150, 45) # b.shape = (150, 45)
c = np.dot(a, b)
```
What is the shape of c?
A: Shape error
B: (12288, 50)
C: (150, 150)
D: (12288, 45)
C
Consider the following code snippet:
```
# a.shape = (3,4)
# b.shape = (4,1)
for i in range(3):
for j in range(4):
c[i][j] = a[i][j] + b[j]
```
How do you vectorize this?
A: c = a.T + b.T
B: c = a+b
C: c = a + b.T
D: c = a.T + b
A
Consider the following code:
```
a = np.random.randn(3, 3)
b = np.random.randn(3, 1)
c = a * b
```
What will be c?
A: This will invoke broadcasting, so b is copied three times to become (3,3), and * is an element-wise product so c.shape will be (3, 3)
B: This will invoke broadcasting, so b is copied three times to become (3, 3), and * invokes a matrix multiplication operation of two 3x3 matrices so c.shape will be (3, 3)
C: This will multiply a 3x3 matrix a with a 3x1 vector, thus resulting in a 3x1 vector. That is, c.shape = (3,1)
D: It will lead to an error since you cannot use to operate on these two matrices. You need to instead use np.dot(a,b)
B
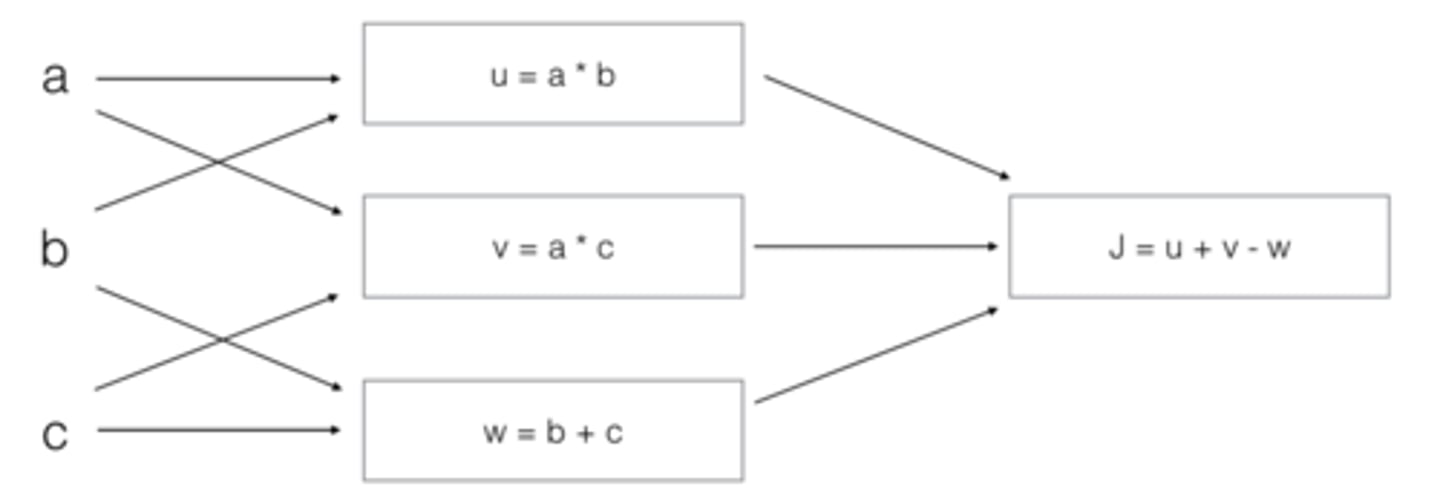
Consider the following computation graph.
What is the output J?
A:
J=(c−1)∗(a+b)
𝐽
=
(
𝑐
−
1
)
∗
(
𝑎
+
𝑏
)
B:
J=(a−1)∗(b+c)
𝐽
=
(
𝑎
−
1
)
∗
(
𝑏
+
𝑐
)
C:
J=ab+bc+ac
𝐽
=
𝑎
𝑏
+
𝑏
𝑐
+
𝑎
𝑐
D:
J=(b−1)∗(c+a)
𝐽
=
(
𝑏
−
1
)
∗
(
𝑐
+
𝑎
)
activation layer at layer l, at the nth neuron and the mth training example
What does n, l m mean in Neural Network?
a
[l](m)
n
𝑎
𝑛
[
𝑙
]
(
𝑚
)
A
The tanh activation usually works better than sigmoid activation function for hidden units because the mean of its output is closer to zero, and so it centers the data better for the next layer. True/False?
A: True
B: False
Z
[l]
=
W
[l]
∗
A
[l−1]
+
b
[l]
𝑍
[
𝑙
]
=
𝑊
[
𝑙
]
∗
𝐴
[
𝑙
−
1
]
+
𝑏
[
𝑙
]
A
[l]
=
g
[l]
(
Z
[l]
)
𝐴
[
𝑙
]
=
𝑔
[
𝑙
]
(
𝑍
[
𝑙
]
)
Which of these is a correct vectorized implementation of forward propagation for layer
l
𝑙
, where
1≤l≤L
1
≤
𝑙
≤
𝐿
?
C
You are building a binary classifier for recognizing cucumbers (y=1) vs. watermelons (y=0). Which one of these activation functions would you recommend using for the output layer?
A: ReLU
B: Leaky ReLU
C: Sigmoid
D: tanh
C
Consider the following code:
```
A = np.random.randn(4,3)
B = np.sum(A, axis = 1, keepdims = True)
```
What will be B.shape?
A: (1,3)
B: (,3)
C: (4,1)
D: (4,)
A
Suppose you have built a neural network. You decide to initialize the weights and biases to be zero. Which of the following statements is true?
A: Each neuron in the first hidden layer will perform the same computation. So even after multiple iterations of gradient descent each neuron in the layer will be computing the same thing as other neurons.
B: Each neuron in the first hidden layer will perform the same computation in the first iteration. But after one iteration of gradient descent, they will learn to compute different things because we have "broken symmetry'.
C: Each neuron in the first hidden layer will compute the same thing, but neurons in different layers will compute different things, thus we have accomplished "symmetry breaking" as described in lecture.
D: The first hidden layer's neurons will perform different computations from each other even in the first iteration; their parameters will thus keep evolving in their own way.
B
Logistic regression's weights w should be initialized randomly rather than to all zeros, because if you initialize to all zeros, then logistic regression will fail to learn a useful decision boundary because it will fail to break symmetry, True/False?
A: True
B: False
D
You have built a network using the tanh activation for all the hidden units. You initialize the weights to relative large values, using np.random.randn(..,..)*1000. What will happen?
A: It doesn't matter. So long as you initialize the weights randomly gradient descent is not affected by whether the weights are large or small.
B: This will cause the inputs of the tanh to also be very large, thus causing gradients to also become large. You therefore have to set alpha to be very small to prevent divergence; this will slow down learning.
C: This will cause the inputs of the tanh to also be very large, causing the units to be highly activated and thus speed up learning compared to if the weights had to start from small values.
D: This will cause the inputs of the tanh to also be very large, thus causing gradients to be close to zero. The optimization algorithm will thus become slow.
b
[1]
𝑏
[
1
]
will have shape (4, 1)
W
[1]
𝑊
[
1
]
will have shape (4, 2)
W
[2]
𝑊
[
2
]
will have shape (1, 4)
b
[2]
𝑏
[
2
]
will have shape (1, 1)
Consider the following 1 hidden layer neural network:
What are the shapes of
b
[1]
,
W
[1]
,
b
[2]
,
W
[2]
𝑏
[
1
]
,
𝑊
[
1
]
,
𝑏
[
2
]
,
𝑊
[
2
]
?
Note: Check [here](https://user-images.githubusercontent.com/14886380/29200515-7fdd1548-7e88-11e7-9d05-0878fe96bcfa.png) for general formulas to do this.
![<p>Consider the following 1 hidden layer neural network:</p><p>What are the shapes of </p><p>b</p><p>[1]</p><p>,</p><p>W</p><p>[1]</p><p>,</p><p>b</p><p>[2]</p><p>,</p><p>W</p><p>[2]</p><p>𝑏</p><p>[</p><p>1</p><p>]</p><p>,</p><p>𝑊</p><p>[</p><p>1</p><p>]</p><p>,</p><p>𝑏</p><p>[</p><p>2</p><p>]</p><p>,</p><p>𝑊</p><p>[</p><p>2</p><p>]</p><p>?</p><p>Note: Check [here](https://user-images.githubusercontent.com/14886380/29200515-7fdd1548-7e88-11e7-9d05-0878fe96bcfa.png) for general formulas to do this.</p>](https://knowt-user-attachments.s3.amazonaws.com/bee01389-39c1-4e7b-ad62-72990108136d.png)
Z
[1]
𝑍
[
1
]
and
A
[1]
𝐴
[
1
]
are (4,m)
In the same network as the previous question, what are the dimensions of
Z
[1]
𝑍
[
1
]
and
A
[1]
𝐴
[
1
]
?
Note: Check [here](https://user-images.githubusercontent.com/14886380/29200515-7fdd1548-7e88-11e7-9d05-0878fe96bcfa.png) for general formulas to do this.
![<p>In the same network as the previous question, what are the dimensions of </p><p>Z</p><p>[1]</p><p>𝑍</p><p>[</p><p>1</p><p>]</p><p> and </p><p>A</p><p>[1]</p><p>𝐴</p><p>[</p><p>1</p><p>]</p><p>?</p><p>Note: Check [here](https://user-images.githubusercontent.com/14886380/29200515-7fdd1548-7e88-11e7-9d05-0878fe96bcfa.png) for general formulas to do this.</p>](https://knowt-user-attachments.s3.amazonaws.com/fb900782-4143-4e44-84a5-724db912db1d.png)
B
What is the "cache" used for in our implementation of forward propagation and backward propagation?
A: It is used to cache the intermediate values of the cost function during training.
B: We use it to pass variables computed during forward propagation to the corresponding backward propagation step. It contains useful values for backward propagation to compute derivatives.
C: It is used to keep track of the hyperparameters that we are searching over, to speed up computation.
D: We use it to pass variables computed during backward propagation to the corresponding forward propagation step. It contains useful values for forward propagation to compute activations.
ADFG
Among the following, which ones are "hyperparameters"? (Check all that apply.)
A: number of iterations
B: bias vector
b
𝑏
C: weight matrix
W
𝑊
D: number of layers
L
𝐿
in the neural network
E: activation values
a
𝑎
F: size of the hidden layers
n
[l]
𝑛
[
𝑙
]
G: learning rate
α
𝛼
A
Which of the following statements is true?
A: The deeper layers of a neural network are typically computing more complex features of the input than the earlier layers.
B: The earlier layers of a neural network are typically computing more complex features of the input than the deeper layers.
B
Vectorization allows you to compute forward propagation in an L-layer neural network without an explicit for-loop (or any other explicit iterative loop) over the layers l=1, 2, ..., L. True/False?
A: True
B: False
D
Assume we store the values for
n
[l]
𝑛
[
𝑙
]
in an array called layers, as follows: layer_dims =
[
n
x
,4,3,2,1]
[
𝑛
𝑥
,
4
,
3
,
2
,
1
]
. So layer 1 has four hidden units, layer 2 has 3 hidden units and so on. Which of the following for-loops will allow you to initialize the parameters for the model?
A: ```
for(i in range(1, len(layer_dims)/2)):
parameter[W + str(i)] = np.random.randn(layers[i], layers[i - 1])) * 0.01
parameter[b + str(i)] = np.random.randn(layers[i], 1) * 0.01
```
B: ```
for(i in range(1, len(layer_dims)/2)):
parameter[W + str(i)] = np.random.randn(layers[i], layers[i - 1])) * 0.01
parameter[b + str(i)] = np.random.randn(layers[i-1], 1) * 0.01
```
C: ```
for(i in range(1, len(layer_dims))):
parameter[W + str(i)] = np.random.randn(layers[i - 1], layers[i])) * 0.01
parameter[b + str(i)] = np.random.randn(layers[i], 1) * 0.01
```
D: ```
for(i in range(1, len(layer_dims))):
parameter[W + str(i)] = np.random.randn(layers[i], layers[i - 1])) * 0.01
parameter[b + str(i)] = np.random.randn(layers[i], 1) * 0.01
```
A
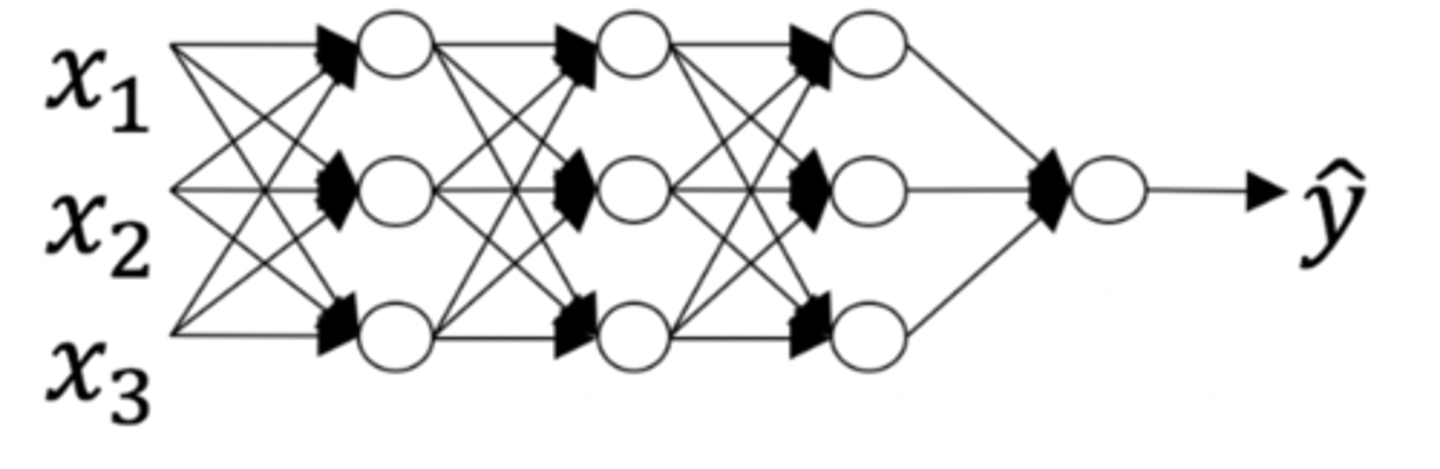
Consider the following neural network.
How many layers does this network have?
A: The number of layers L is 4. The number of hidden layers is 3
B: The number of layers L is 3. The number of hidden layers is 3
C: The number of layers L is 4. The number of hidden layers is 4
D: The number of layers L is 5. The number of hidden layers is 4
A
During forward propagation, in the forward function for a layer l you need to know what is the activation function in a layer (Sigmoid, tanh, ReLU, etc.). During backpropagation, the corresponding backward function also needs to know what the activation function for layer l is, since the gradient depends on it. True/False?
A: True
B: False
A
There are certain functions with the following properties:
(i) To compute the function using a shallow network circuit, you will need a large network (where we measure size by the number of logic gates in the network), but (ii) To compute it using a deep network circuit, you need only an exponentially smaller network. True/False?
A: True
B: False
-
W
[1]
𝑊
[
1
]
will have shape (4, 4)
-
b
[1]
𝑏
[
1
]
will have shape (4, 1)
-
W
[2]
𝑊
[
2
]
will have shape (3, 4)
-
b
[2]
𝑏
[
2
]
will have shape (3, 1)
-
b
[3]
𝑏
[
3
]
will have shape (1, 1)
-
W
[3]
𝑊
[
3
]
will have shape (1, 3)
Consider the following 2 hidden layer neural network:
What is the shape of
W
[1]
,
b
[1]
,
W
[2]
,
b
[2]
,
W
[3]
,
b
[3]
𝑊
[
1
]
,
𝑏
[
1
]
,
𝑊
[
2
]
,
𝑏
[
2
]
,
𝑊
[
3
]
,
𝑏
[
3
]
?
![<p>Consider the following 2 hidden layer neural network:</p><p>What is the shape of </p><p>W</p><p>[1]</p><p>,</p><p>b</p><p>[1]</p><p>,</p><p>W</p><p>[2]</p><p>,</p><p>b</p><p>[2]</p><p>,</p><p>W</p><p>[3]</p><p>,</p><p>b</p><p>[3]</p><p>𝑊</p><p>[</p><p>1</p><p>]</p><p>,</p><p>𝑏</p><p>[</p><p>1</p><p>]</p><p>,</p><p>𝑊</p><p>[</p><p>2</p><p>]</p><p>,</p><p>𝑏</p><p>[</p><p>2</p><p>]</p><p>,</p><p>𝑊</p><p>[</p><p>3</p><p>]</p><p>,</p><p>𝑏</p><p>[</p><p>3</p><p>]</p><p>?</p>](https://knowt-user-attachments.s3.amazonaws.com/0ed85b85-a4d5-43ba-8431-22ce409e4dc1.jpg)
A
Whereas the previous question used a specific network, in the general case what is the dimension of
W
[l]
𝑊
[
𝑙
]
, the weight matrix associated with layer l?
A:
(
n
[l]
,
n
[l−1]
)
(
𝑛
[
𝑙
]
,
𝑛
[
𝑙
−
1
]
)
B:
(
n
[l−1]
,
n
[l]
)
(
𝑛
[
𝑙
−
1
]
,
𝑛
[
𝑙
]
)
C:
(
n
[l+1]
,
n
[l]
)
(
𝑛
[
𝑙
+
1
]
,
𝑛
[
𝑙
]
)
D:
(
n
[l]
,
n
[l+1]
)
(
𝑛
[
𝑙
]
,
𝑛
[
𝑙
+
1
]
)
A
If you have 10,000,000 examples, how would you split the train/dev/test set?
A: 98% train, 1% dev, 1% test
B: 33% train, 33% dev, 33% test
C: 60% train, 20% dev, 20% test
A
The dev and test set should:
A. Come from the same distribution
B. Come from different distributions
C. Be identical to each other (same (x,y) pairs)
D. Have the same number of examples
CE
If your Neural Network model seems to have high variance, what of the following would be promising things to try?
Note: Check [here](https://user-images.githubusercontent.com/14886380/29240263-f7c517ca-7f93-11e7-8549-58856e0ed12f.png).
A: Make the Neural Network deeper
B: Get more test data
C: Get more training data
D: Increase the number of units in each layer
E: Add regularization
AC
You are working on an automated check-out kiosk for a supermarket, and are building a classifier for apples, bananas and oranges. Suppose your classifier obtains a training set error of 0.5%, and a dev set error of 7%. Which of the following are promising things to try to improve your classifier? (Check all that apply.)
A: Increase the regularization parameter lambda
B: Decrease the regularization parameter lambda
C: Get more training data
D: Use a bigger neural network
A
What is weight decay?
A: A regularization technique (such as L2 regularization) that results in gradient descent shrinking the weights on every iteration.
B: Gradual corruption of the weights in the neural network if it is trained on noisy data.
C: The process of gradually decreasing the learning rate during training.
D: A technique to avoid vanishing gradient by imposing a ceiling on the values of the weights.
A
What happens when you increase the regularization hyperparameter lambda?
A: Weights are pushed toward becoming smaller (closer to 0)
B: Weights are pushed toward becoming bigger (further from 0)
C: Doubling lambda should roughly result in doubling the weights
D: Gradient descent taking bigger steps with each iteration (proportional to lambda)
A
With the inverted dropout technique, at test time:
A. You do not apply dropout (do not randomly eliminate units) and do not keep the 1/keep_prob factor in the calculations used in training
B. You do not apply dropout (do not randomly eliminate units), but keep the 1/keep_prob factor in the calculations used in training.
C. You apply dropout (randomly eliminating units) and do not keep the 1/keep_prob factor in the calculations used in training
D. You apply dropout (randomly eliminating units) but keep the 1/keep_prob factor in the calculations used in training.
BD
Increasing the parameter keep_prob from (say) 0.5 to 0.6 will likely cause the following: (Check the two that apply)
A: Increase the regularization effect
B: Reducing the regularization effect
C: Causing the neural network to end up with a higher training set error
D: Causing the neural network to end up with a lower training set error
DEF
Which of these techniques are useful for reducing variance (reducing overfitting)? (Check all that apply.)
A: Exploding gradient
B: Vanishing gradient
C: Xavier initialization
D: Dropout
E: L2 regularization
F: Data augmentation
G: Gradient Checking
C
Why do we normalize the inputs
x
𝑥
?
A: It makes it easier to visualize the data
B: It makes the parameter initialization faster
C: It makes the cost function faster to optimize
D: Normalization is another word for regularization--it helps to reduce variance
B
Which notation would you use to denote the 3rd layer's activations when the input is the 7th example from the 8th minibatch?
Note: *[i]{j}(k) superscript means i-th layer, j-th minibatch, k-th example*
A:
a
[8]{7}(3)
𝑎
[
8
]
{
7
}
(
3
)
B:
a
[3]{8}(7)
𝑎
[
3
]
{
8
}
(
7
)
C:
a
[3]{7}(8)
𝑎
[
3
]
{
7
}
(
8
)
D:
a
[8]{3}(7)
𝑎
[
8
]
{
3
}
(
7
)
A
Which of these statements about mini-batch gradient descent do you agree with?
A: One iteration of mini-batch gradient descent (computing on a single mini-batch) is faster than one iteration of batch gradient descent.
B: Training one epoch (one pass through the training set) using mini-batch gradient descent is faster than training one epoch using batch gradient descent.
C: You should implement mini-batch gradient descent without an explicit for- loop over different mini-batches, so that the algorithm processes all mini- batches at the same time (vectorization).
AC
Why is the best mini-batch size usually not 1 and not m, but instead something in-between?
A: If the mini-batch size is m, you end up with batch gradient descent, which has to process the whole training set before making progress.
B: If the mini-batch size is m, you end up with stochastic gradient descent, which is usually slower than mini-batch gradient descent
C: If the mini-batch size is 1, you lose the benefits of vectorization across examples in the mini-batch.
D: If the mini-batch size is 1, you end up having to process the entire training set
before making any progress.
D
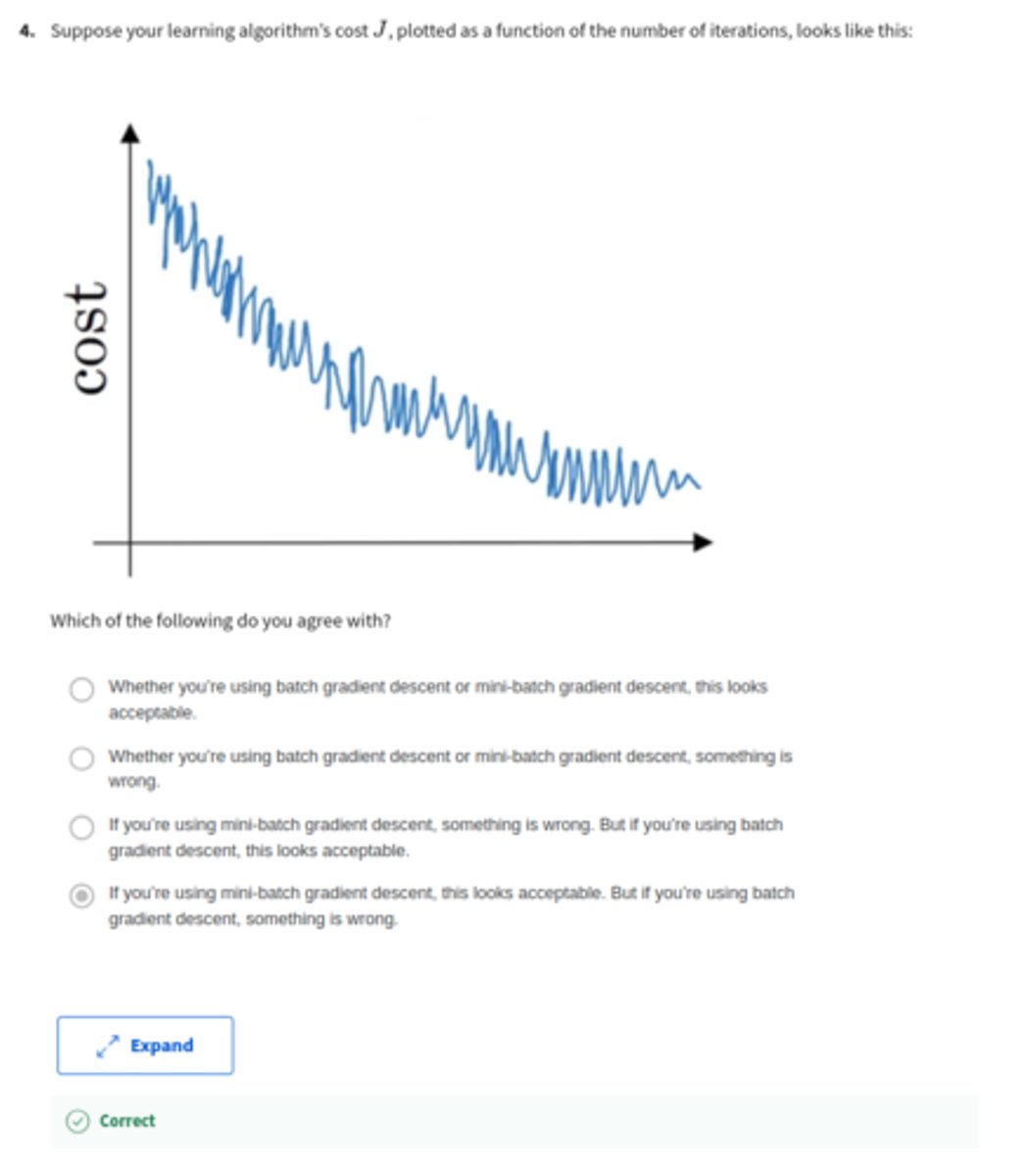
Suppose your learning algorithm's cost J, plotted as a function of the number of iterations, looks like this:
Which of the following do you agree with?
A: If you're using mini-batch gradient descent, something is wrong. But if you're using batch gradient descent, this looks acceptable.
B: Whether you're using batch gradient descent or mini-batch gradient descent, this looks acceptable.
C: Whether you're using batch gradient descent or mini-batch gradient descent, something is wrong.
D: If you're using mini-batch gradient descent, this looks acceptable. But if you're using batch gradient descent, something is wrong.
A
Suppose the temperature in Casablanca over the first three days of January are the same:
Jan 1st:
θ
1
=10°C
𝜃
1
=
10
°
𝐶
Jan 2nd:
θ
2
=10°C
𝜃
2
=
10
°
𝐶
Say you use an exponentially weighted average with
β=0.5
𝛽
=
0.5
to track the temperature:
v
0
=0,
v
t
=β
v
t−1
+(1−β)
θ
t
𝑣
0
=
0
,
𝑣
𝑡
=
𝛽
𝑣
𝑡
−
1
+
(
1
−
𝛽
)
𝜃
𝑡
. If
v
2
𝑣
2
is the value computed after day 2 without bias correction, and
v
corrected
2
𝑣
2
𝑐
𝑜
𝑟
𝑟
𝑒
𝑐
𝑡
𝑒
𝑑
is the value you compute with bias correction. What are these values?
A:
v
2
=7.5,
v
corrected
2
=10
𝑣
2
=
7.5
,
𝑣
2
𝑐
𝑜
𝑟
𝑟
𝑒
𝑐
𝑡
𝑒
𝑑
=
10
B:
v
2
=10,
v
corrected
2
=10
𝑣
2
=
10
,
𝑣
2
𝑐
𝑜
𝑟
𝑟
𝑒
𝑐
𝑡
𝑒
𝑑
=
10
C:
v
2
=10,
v
corrected
2
=7.5
𝑣
2
=
10
,
𝑣
2
𝑐
𝑜
𝑟
𝑟
𝑒
𝑐
𝑡
𝑒
𝑑
=
7.5
D:
v
2
=7.5,
v
corrected
2
=7.5
𝑣
2
=
7.5
,
𝑣
2
𝑐
𝑜
𝑟
𝑟
𝑒
𝑐
𝑡
𝑒
𝑑
=
7.5
C
Which of these is NOT a good learning rate decay scheme? Here t is the epoch number
Hint: learning rate decay = learning rate giảm theo thời gian
A:
α=
1
1+2t
α
0
𝛼
=
1
1
+
2
𝑡
𝛼
0
B:
α=
0.95
t
α
0
𝛼
=
0.95
𝑡
𝛼
0
C:
α=
e
t
α
0
𝛼
=
𝑒
𝑡
𝛼
0
D:
α=
1
t
√
α
0
𝛼
=
1
𝑡
𝛼
0
BC
You use an exponentially weighted average on the London temperature dataset. You use the following to track the temperature:
v
t
=β
v
t−1
+(1−β)
θ
t
𝑣
𝑡
=
𝛽
𝑣
𝑡
−
1
+
(
1
−
𝛽
)
𝜃
𝑡
. The red line below was computed using
β=0.9
𝛽
=
0.9
. What would happen to your red curve as you vary
β
𝛽
? (Check the two that apply)
A: Decreasing
β
𝛽
will shift the red line slightly to the right.
B: Increasing
β
𝛽
will shift the red line slightly to the right
C: Decreasing
β
𝛽
will create more oscillation within the red line.
D: Increasing
β
𝛽
will create more oscillations within the red line.
B
These plots were generated with gradient descent; with gradient descent with momentum (
β=0.5
𝛽
=
0.5
) and gradient descent with momentum (
β=0.9
𝛽
=
0.9
). Which curve corresponds to which algorithm?
A: (1) is gradient descent. (2) is gradient descent with momentum (large
β
𝛽
) . (3) is gradient descent with momentum (small
β
𝛽
)
B: (1) is gradient descent. (2) is gradient descent with momentum (small
β
𝛽
). (3) is gradient descent with momentum (large
β
𝛽
)
C: (1) is gradient descent with momentum (small
β
𝛽
). (2) is gradient descent. (3) is gradient descent with momentum (large
β
𝛽
)
D: (1) is gradient descent with momentum (small
β
𝛽
), (2) is gradient descent with momentum (small
β
𝛽
), (3) is gradient descent
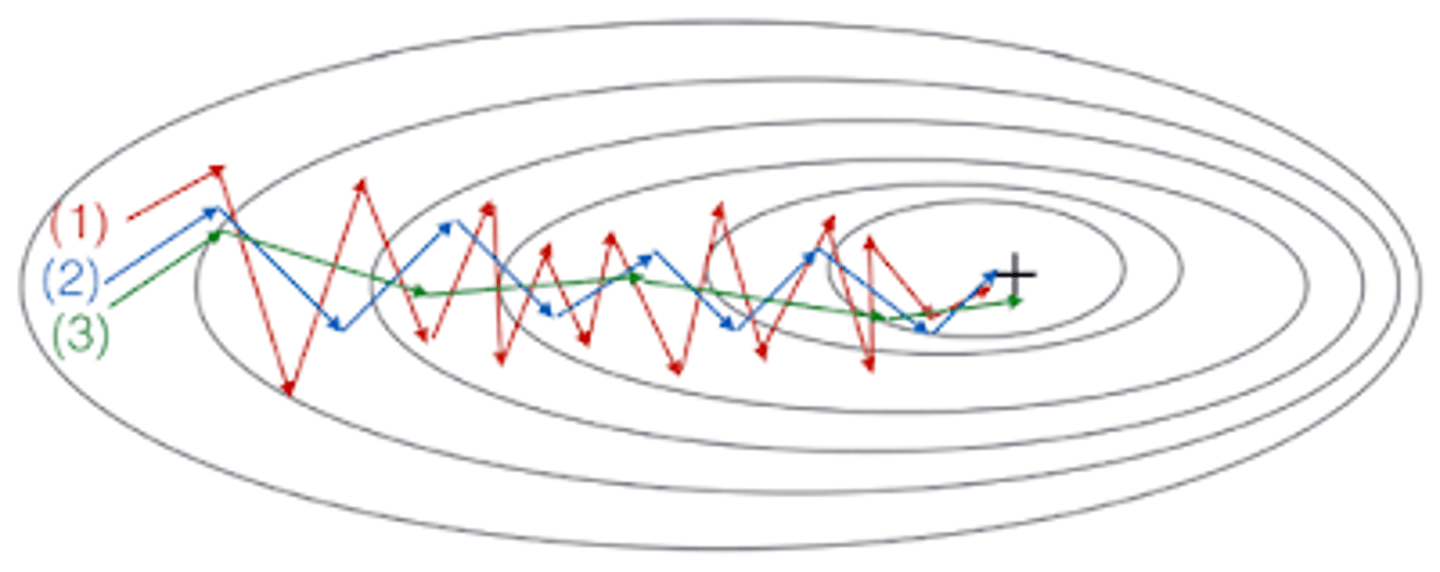
ABCE
Suppose batch gradient descent in a deep network is taking excessively long to find a value of the parameters that achieves a small value for the cost function
J(
W
[1]
,
b
[1]
,...,
W
[L]
,
b
[L]
)
𝐽
(
𝑊
[
1
]
,
𝑏
[
1
]
,
.
.
.
,
𝑊
[
𝐿
]
,
𝑏
[
𝐿
]
)
. Which of the following techniques could help find parameter values that attain a small value for
J
𝐽
? (Check all that apply)
A: Try using Adam
B: Try better random initialization for the weights
C: Try tuning the learning rate
α
𝛼
D: Try initializing all the weights to zero
E: Try mini-batch gradient descent
D
Which of the following statements about Adam is False?
A: We usually use "default" values for the hyperparameters
β
1
,
β
2
𝛽
1
,
𝛽
2
and in Adam
(
β
1
=0.9,
β
2
=0.999,ϵ=
10
−8
)
(
𝛽
1
=
0.9
,
𝛽
2
=
0.999
,
𝜖
=
10
−
8
)
B: The learning rate hyperparameter
α
𝛼
in Adam usually needs to be tuned.
C: Adam combines the advantages of RMSProp and momentum
D: Adam should be used with batch gradient computations, not with mini-batches.
A
If searching among a large number of hyperparameters, you should try values in a grid rather than random values, so that you can carry out the search more systematically and not rely on chance. True or False?
A: False
B: True
A
Every hyperparameter, if set poorly, can have a huge negative impact on training, and so all hyperparameters are about equally important to tune well. True or False?
A: False
B: True
C
During hyperparameter search, whether you try to babysit one model (Panda strategy) or train a lot of models in parallel (Caviar) is largely determined by:
A: Whether you use batch or mini-batch optimization
B: The presence of local minima (and saddle points) in your neural network
C: The amount of computational power you can access
D: The number of hyperparameters you have to tune
B
If you think ß (hyperparameter for momentum) is between on 0.9 and 0.99, which of the following is the recommended way to sample a value for beta?
A: r = np.random.rand()
beta = r*0.09 + 0.9
B: r = np.random.rand()
beta = 1-10**(-r-1)
C: r = np.random.rand()
beta = 1-10**(-r+1)
D: r = np.random.rand()
beta = r*0.9 + 0.09
B
Finding good hyperparameter values is very time-consuming. So typically you should do it once at the start of the project, and try to find very good hyperparameters so that you don't ever have to revisit tuning them again. True or false?
A: True
B: False
B
In batch normalization as presented in the videos, if you apply it on the lth layer of your neural network, what are you normalizing?
A:
W
[l]
𝑊
[
𝑙
]
B:
z
[l]
𝑧
[
𝑙
]
C:
b
[l]
𝑏
[
𝑙
]
D:
a
[l]
𝑎
[
𝑙
]
D
In the normalization formula, why do we use epsilon?
z
norm
=
z−μ
σ
2
+ϵ
−
−
−
−
−
√
𝑧
𝑛
𝑜
𝑟
𝑚
=
𝑧
−
𝜇
𝜎
2
+
𝜖
A: To speed up convergence
B: To have a more accurate normalization
C: In case
μ
𝜇
is too small
D: To avoid division by zero
BD
Which of the following statements about
γ
𝛾
and
β
𝛽
in Batch Norm are true?
A: The optimal values are
γ=
σ
2
+ϵ
−
−
−
−
−
√
𝛾
=
𝜎
2
+
𝜖
and
β=μ
𝛽
=
𝜇
B: They set the mean and variance of the linear variable
z
[l]
𝑧
[
𝑙
]
of a given layer
C:
γ
𝛾
and
β
𝛽
are hyperparameters of the algorithm, which we tune via random sampling
D: They can be learned using Adam, Gradient descent with momentum, or RMSprop, not just with gradient descent.
E: There is one global value of
γ∈R
𝛾
∈
𝑅
and one global value of
β∈R
𝛽
∈
𝑅
for each layer, and applies to all the hidden units in that layer.
C
After training a neural network with Batch Norm, at test time, to evaluate the neural network on a new example you should:
A: If you implemented Batch Norm on mini-batches of (say) 256 examples, then to evaluate on one test example, duplicate that example 256 times so that you're working with a mini-batch the same size as during training.
B: Use the most recent mini-batch's value of g and to perform the needed normalizations.
C: Perform the needed normalizations, use and estimated using an exponentially weighted average across mini-batches seen during training.
D: Skip the step where you normalize using
μ
𝜇
and
σ
2
𝜎
2
since a single test example cannot be normalized.
AB
Which of these statements about deep learning programming frameworks are true? (Check all that apply)
A: A programming framework allows you to code up deep learning algorithms with typically fewer lines of code than a lower-level language such as Python.
B: Even if a project is currently open source, good governance of the project helps ensure that the it remains open even in the long term, rather than become closed or modified to benefit only one company.
C: Deep learning programming frameworks require cloud-based machines to run.
A
They want an algorithm that: has high accuracy, runs quickly and takes a short time, can fit in a small amount of memory.
Having three evaluation metrics makes it harder for you to quickly choose between two different algorithms, and will slow down the speed with which your team can iterate. True/False?
A: True
B: False
D
After further discussions, the city narrows down its criteria to:
• "We need an algorithm that can let us know a bird is flying over Peacetopia as accurately as
possible."
• "We want the trained model to take no more than 10 sec to classify a new image."
• "We want the model to fit in 10 MB of memory."
If you had the three following models, which one would you choose?
A: Acc 97%, Runtime 1 sec, Memory 3MB
B: Acc 99%, Runtime 13 sec, Memory 9MB
C: Acc 97%, Runtime 3 sec, Memory 2MB
D: Acc 98%, Runtime 9 sec, Memory 9MB
A
Based on the city's requests, which of the following would you say is true?
A: Accuracy is an optimizing metric; running time and memory size are a satisficing metrics.
B: Accuracy is a satisficing metric; running time and memory size are an optimizing metric.
C: Accuracy, running time and memory size are all optimizing metrics because you want to do well on all three.
D: Accuracy, running time and memory size are all satisficing metrics because you have to do sufficiently well on all three for your system to be acceptable.
C
Before implementing your algorithm, you need to split your data into train/dev/test sets. Which of these do you think is the best choice?
A: Train 6M, Dev 3M, Test 1M
B: Train 3.3M, Dev 3.3M, Test 3.3M
C: Train 9.5M, Dev 250K, Test 250K
D: Train 6M, Dev 1M, Test 1M
B
After setting up your train/dev/test sets, the City Council comes across another 1,000,000 images, called the citizens' data. Apparently, the citizens of Peacetopia are so scared of birds that they volunteered to take pictures of the sky and label them, thus contributing these additional 1,000,000 images. These images are different from the distribution of images the City Council had originally given you, but you think it could help your algorithm.
You should not add the citizens' data to the training set, because this will cause the training and dev/test set distributions to become different, thus hurting dev and test set performance. True/False?
A: True
B: False
CD
One member of the City Council knows a little about machine learning and thinks you should add the 1,000,000 citizens' data images to the test set. You object because:
A: A bigger test set will slow down the speed of iterating because of the computational expense of evaluating models on the test set.
B: The citizens' data images do not have a consistent mapping as the rest of the data (similar to the New York City/Dctroit housing prices example from lecture).
C: This would cause the dev and test set distributions to become different. This is a bad idea because you're not aiming where you want to hit.
D: The test set no longer reflects the distribution of data (security cameras) you most care about.
D
You train a system, and its errors are as follows (error = 100%-Accuracy):
- Training set error 4.0%
- Dev set error 4.5%
This suggests that one good avenue for improving performance is to train a bigger network so as to drive down the 4.0% training error. Do you agree?
Hint: hãy nhớ về human-level performance.
A: Yes, because having 4.0% training error shows you have high bias.
B: Yes, because this shows your bias is higher than your variance.
C: No, because this shows your variance is higher than your bias.
D: No, because there is insufficient information to tell.
B
You ask a few people to label the dataset so as to find out what is human-level performance. You find the following levels of accuracy:
- Bird watching expert #1 0.3% error
- Bird watching expert #2 0.5% error
- Normal person #1 (not a bird watching expert) 1.0% error
- Normal person #2 (not a bird watching expert) 1.2% error
If your goal is to have "human-level performance" be a proxy (or estimate) for Bayes error, how would you define "human-level performance"?
A: 0.0%
B: 0.3%
C: 0.4%
D: 0.75%
A
Which of the following statements do you agree with?
A: A learning algorithm's performance can be better human-level performance, but it can never be better than Bayes error.
B: A learning algorithm's performance can never be better human-level performance, but it can be better than Bayes error.
C: A learning algorithm's performance can never be better than human-level performance nor better than Bayes error.
D: A learning algorithm's performance can be better than human-level performance and better than Bayes error.
BD
You find that a team of ornithologists debating and discussing an image gets an even better 0.1% performance, so you define that as "human-level performance." After working further on your algorithm, you end up with the following:
- Human-level performance 0.1%
- Training set error 2.0%
- Dev set error 2.1%
Based on the evidence you have, which two of the following four options seem the most promising to try? (Check two options.)
A: Get a bigger training set to reduce variance
B: Train a bigger model to try to do better on the training set
C: Try increasing regularization
D: Try decreasing regularization
CD
You also evaluate your model on the test set, and find the following:
- Human-level performance 0.1%
- Training set error 2.0%
- Dev set error 2.1%
- Test set error 7.0%
What does this mean? (Check the two best options.)
A: You have underfit to the dev set
B: You should get a bigger test set
C: You have overfit to the dev set
D: You should try to get a bigger dev set
AC
After working on this project for a year, you finally achieve:
- Human-level performance 0.10%
- Training set error 0.05%
- Dev set error 0.05%
What can you conclude? (Check all that apply.)
A: If the test set is big enough for the 0.05% error estimate to be accurate, this implies Bayes error is <= 0.05
B: This is a statistical anomaly (or must be the result of statistical noise) since it should not be possible to surpass human-level performance.
C: It is now harder to measure avoidable bias, thus progress will be slower going forward.
D: With only 0.09% further progress to make, you should quickly be able to close the remaining gap to 0%
C
It turns out Peacetopia has hired one of your competitors to build a system as well. Your system and your competitor both deliver systems with about the same running time and memory size. However, your system has higher accuracy! However, when Peacetopia tries out your and your competitor's systems, they conclude they actually like your competitor's system better, because even though you have higher overall accuracy, you have more false negatives (failing to raise an alarm when a bird is in the air). What should you do?
A: Look at all the models you've developed during the development process and find the one with the lowest false negative error rate.
B: Ask your team to take into account both accuracy and false negative rate during development.
C: Rethink the appropriate metric for this task, and ask your team to tune to the new metric.
D: Pick false negative rate as the new metric, and use this new metric to drive all further development.
A
You've handily beaten your competitor, and your system is now deployed in Peacetopia and is protecting the citizens from birds! But over the last few months, a new species of bird has been slowly migrating into the area, so the performance of your system slowly degrades because your data is being tested on a new type of data.
You have only 1 ,000 images of the new species of bird. The city expects a better system from you within the next 3 months. Which of these should you do first?
A: Use the data you have to define a new evaluation metric (using a new dev/test set) taking into account the new species, and use that to drive further progress for your team.
B: Put the 1 ,000 images into the training set so as to try to do better on these birds.
C: Try data augmentation/data synthesis to get more images of the new type of bird.
D: Add the 1000 images into your dataset and reshuffle into a new train/dev/test split.
ABC
The City Council thinks that having more Cats in the city would help scare off birds. They are so happy with your work on the Bird detector that they also hire you to build a Cat detector. (Wow Cat detectors are just incredibly useful aren't they.) Because of years of working on Cat detectors, you have such a huge dataset of 100,000,000 cat images that training on this data takes about two weeks. Which of the statements do you agree with? (Check all that agree.)
A: Needing two weeks to train will limit the speed at which you can iterate.
B: If 100,000,000 examples is enough to build a good enough Cat detector, you might be better of training with just 10,000,000 examples to gain a ~10x improvement in how quickly you can run experiments, even if each model performs a bit worse because it's trained on less data.
C: Buying faster computers could speed up your teams' iteration speed and thus your team's productivity.
D: Having built a good Bird detector, you should be able to take the same model and hyperparameters and just apply it to the Cat dataset, so there is no need to iterate.
A
You're building a self-driving car bla bla bla...
You are just getting started on this project. What is the first thing you do? Assume each of the steps below would take about an equal amount of time (a few days).
A: Spend a few days training a basic model and see what mistakes it makes.
B: Spend a few days collecting more data using the front-facing camera of your car, to better understand how much data per unit time you can collect
C: Spend a few days checking what is human-level performance for these tasks so that you can get an accurate estimate of Bayes error.
D: Spend a few days getting the internet data, so that you understand better what data is available.
B
Your goal is to detect road signs (stop sign, pedestrian crossing sign, construction ahead sign) and traffic signals (red and green lights) in images. The goal is to recognize which of these objects appear in each image. You plan to use a deep neural network with ReLU units in the hidden layers.
For the output layer, a softmax activation would be a good choice for the output layer because this is a multi-task learning problem. True/False?
A: True
B: False
B
You are carrying out error analysis and counting up what errors the algorithm makes. Which of these datasets do you think you should manually go through and carefully examine, one image at a time?
A: 10,000 randomly chosen images
B: 500 images on which the algorithm made a mistake
C: 10,000 images on which algorithm made a mistake
D: 500 randomly chosen images
B
After working on the data for several weeks, your team ends up with the following data:
- 100,000 labeled images taken using the front-facing camera of your car.
- 900,000 labeled images of roads downloaded from the internet.
Each image's labels precisely indicate the presence of any specific road signs and traffic signals or combinations of them. For example,
y
(i)
=[1,0,0,1,0]
𝑦
(
𝑖
)
=
[
1
,
0
,
0
,
1
,
0
]
means the image contains a stop sign and a red traffic light.
Because this is a multi-task learning problem, you need to have all your
y
(i)
𝑦
(
𝑖
)
vectors fully labeled. If one example is equal to
[0,?,1,1,?]
[
0
,
?
,
1
,
1
,
?
]
then the learning algorithm will not be able to use that example. True/False?
A: True
B: False
B
The distribution of data you care about contains images from your car's front-facing camera; which comes from a different distribution than the images you were able to find and download off the internet. How should you split the dataset into train/dev/test sets?
A: Choose the training set to be the 900,000 images from the internet along with 20,000 images from your car's front-facing camera. The 80,000 remaining images will be split equally in dev and test sets.
B: Choose the training set to be the 900,000 images from the internet along with 80,000 images from your car's front-facing camera. The 20,000 remaining images will be split equally in dev and test sets.
C: Mix all the 100.000 images with the 900,000 images you found online. Shuffle everything. Split the 1,000,000 images dataset into 600,000 for the training set, 200,000 for the dev set and 200,000 for the test set.
D: Mix all the 100,000 images with the 900,000 images you found online. Shuffle everything. Split the 1 images dataset into 980,000 for the training set, 10.000 for the dev set and 10,000 for the test set.
BC
Assume you've finally chosen the following split between of the data:
- Training 940,000 images randomly picked from (900,000 internet images + 60,000 car's front-facing camera images) 8.8%
- Training-Dev 20,000 images randomly picked from (900,000 internet images + 60,000 car's front-facing camera images) 9.1%
- Dev 20,000 images from your car's front-facing camera 14.3%
- Test 20,000 images from the car's front-facing camera 14.8%
You also know that human-level error on the road sign and traffic signals classification task is around 0.5%. Which of the following are True? (Check all that apply).
A: You have a large variance problem because your training error is quite higher than the human-level error.
B: You have a large data-mismatch problem because your model does a lot better on the training-dev set than on the dev set
C: You have a large avoidable-bias problem because your training error is quite a bit higher than the human-level error.
D: Your algorithm overfits the dev set because the error of the dev and test sets are very close.
E: You have a large variance problem because your model is not generalizing well to data from the same training distribution b
C
Based on table from the previous question, a friend thinks that the training data distribution is much easier than the dev/test distribution. What do you think?
A: Your friend is right. (I.e., Bayes error for the training data distribution is probably lower than for the dev/test distribution.)
B: Your friend is wrong. (I.e., Bayes error for the training data distribution is probably higher than for the dev/test distribution.)
C: There's insufficient information to tell if your friend is right or wrong.
C
You decide to focus on the dev set and check by hand what are the errors due to. Here is a table summarizing your discoveries:
- Overall dev set error 14.3%
- Errors due to incorrectly labeled data 4.1%
- Errors due to foggy pictures 8.0%
- Errors due to rain drops stuck on your car's front-facing camera 2.2%
- Errors due to other causes 1.0%
In this table, 4.1%, 8.0%, etc.are a fraction of the total dev set (not just examples your algorithm mislabeled). I.e. about 8.0/14.3 = 56% of your errors are due to foggy pictures.
The results from this analysis implies that the team's highest priority should be to bring more foggy pictures into the training set so as to address the 8.0% of errors in that category. True/False?
A: True because it is the largest category of errors. As discussed in lecture, we should prioritize the largest category of error to avoid wasting the team's time.
B: True because it is greater than the other error categories added together (8.0 > 4. 1 +2.2+1.0).
C: False because this would depend on how easy it is to add this data and how much you think your team thinks it'll help.
D: False because data augmentation (synthesizing foggy images
A
You can buy a specially designed windshield wiper that help wipe off some of the raindrops on the front-facing camera. Based on the table from the previous question, which of the following statements do you agree with?
A: 2.2% would be a reasonable estimate of the maximum amount this windshield wiper could improve performance.
B: 2.2% would be a reasonable estimate of the minimum amount this windshield wiper could improve performance.
C: 2.2% would be a reasonable estimate of how much this windshield wiper will improve performance.
D: 2.2% would be a reasonable estimate of how much this windshield wiper could worsen performance in the worst case.
C
You decide to use data augmentation to address foggy images. You find 1,000 pictures of fog off the internet, and "add" them to clean images to synthesize foggy days, like this:
Which of the following statements do you agree with? (Check all that apply.)
A: Adding synthesized images that look like real foggy pictures taken from the front- facing camera of your car to training dataset won't help the model improve because it will introduce avoidable-bias.
B: There is little risk of overfitting to the 1 ,000 pictures of fog so long as you are combing it with a much larger (>>1,000) of clean/non-foggy images.
C: So long as the synthesized fog looks realistic to the human eye, you can be confident that the synthesized data is accurately capturing the distribution of real foggy images, since human vision is very accurate for the problem you're solving.
AD
After working further on the problem, you've decided to correct the incorrectly labeled data on the dev set. Which of these statements do you agree with? (Check all that apply).
A: You should also correct the incorrectly labeled data in the test set, so that the dev and test sets continue to come from the same distribution
B: You should correct incorrectly labeled data in the training set as well so as to avoid your training set now being even more different from your dev set.
C: You should not correct the incorrectly labeled data in the test set, so that the dev and test sets continue to come from the same distribution
D: You should not correct incorrectly labeled data in the training set as well so as to avoid your training set now being even more different from your dev set.
A
So far your algorithm only recognizes red and green traffic lights. One of your colleagues in the startup is starting to work on recognizing a yellow traffic light. (Some countries call it an orange light rather than a yellow light; we'll use the US convention of calling it yellow.) Images containing yellow lights are quite rare, and she doesn't have enough data to build a good model. She hopes you can help her out using transfer learning.
What do you tell your colleague?
A: She should try using weights pre-traincd on your dataset, and fine-tuning further with the yellow-light dataset.
B: If she has (say) 10,000 images of yellow lights, randomly sample 10,000 images from your dataset and put your and her data together. This prevents your dataset from "swamping" the yellow lights dataset.
C: You cannot help her because the distribution of data you have is different from hers, and is also lacking the yellow label.
D: Recommend that she try multi-task learning instead of transfer learning using all the data.
D
Another colleague wants to use microphones placed outside the car to better hear if there're other vehicles around you. For example, if there is a police vehicle behind you, you would be able to hear their siren. However, they don't have much to train this audio system. How can you help?
A: Transfer learning from your vision dataset could help your colleague get going faster. Multi-task learning seems significantly less promising.
B: Multi-task learning from your vision dataset could help your colleague get going faster. Transfer learning seems significantly less promising.
C: Either transfer learning or multi-task learning could help our colleague get going faster.
D: Neither transfer learning nor multi-task learning seems promising.
B
To recognize red and green lights, you have been using this approach:
- (A) Input an image (x) to a neural network and have it directly learn a mapping to make a prediction as to whether there's a red light and/or green light (y).
A teammate proposes a different, two-step approach:
- (B) In this two-step approach, you would first (i) detect the traffic light in the image (if any), then (ii) determine the color of the illuminated lamp in the traffic light.
Between these two, Approach B is more of an end-to-end approach because it has distinct steps for the input end and the output end. True/False?
A: True
B: False
A
Approach A (in the question above) tends to be more promising than approach B if you have a ________ (fill in the blank).
A: Large training set
B: Multi-task learning problem.
C: Large bias problem.
D: Problem with a high Bayes error.