Data Engineering
1/163
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
164 Terms
Data Engineering
The development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning.
Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering.
Data Model
Represents the way data relates to the real world. It reflects how the data must be structured and standardized to best reflect an organization's processes, definitions, workflows, and logic.
A good data model captures how communication and work naturally flow within an organization.
Data Modeling
The process of creating a data model.
Data Mapping
The process of connecting a data field from one source to a data field in another source
Database
An organized collection of data, stored and retrieved digitally from a remote or local computer system.
Data Lake
A centralized repository that stores all structured and unstructured data.
Data Warehouse
A centralized repository used for reporting and analysis. Data is typically highly formatted and structured for analytics use cases.
Besides centralizing and organizing data, a data warehouse separates OLAP from production databases (OLTP)
This separation is critical as businesses grow. Moving data into a separate physical system directs load away from production systems and improves analytics performance.
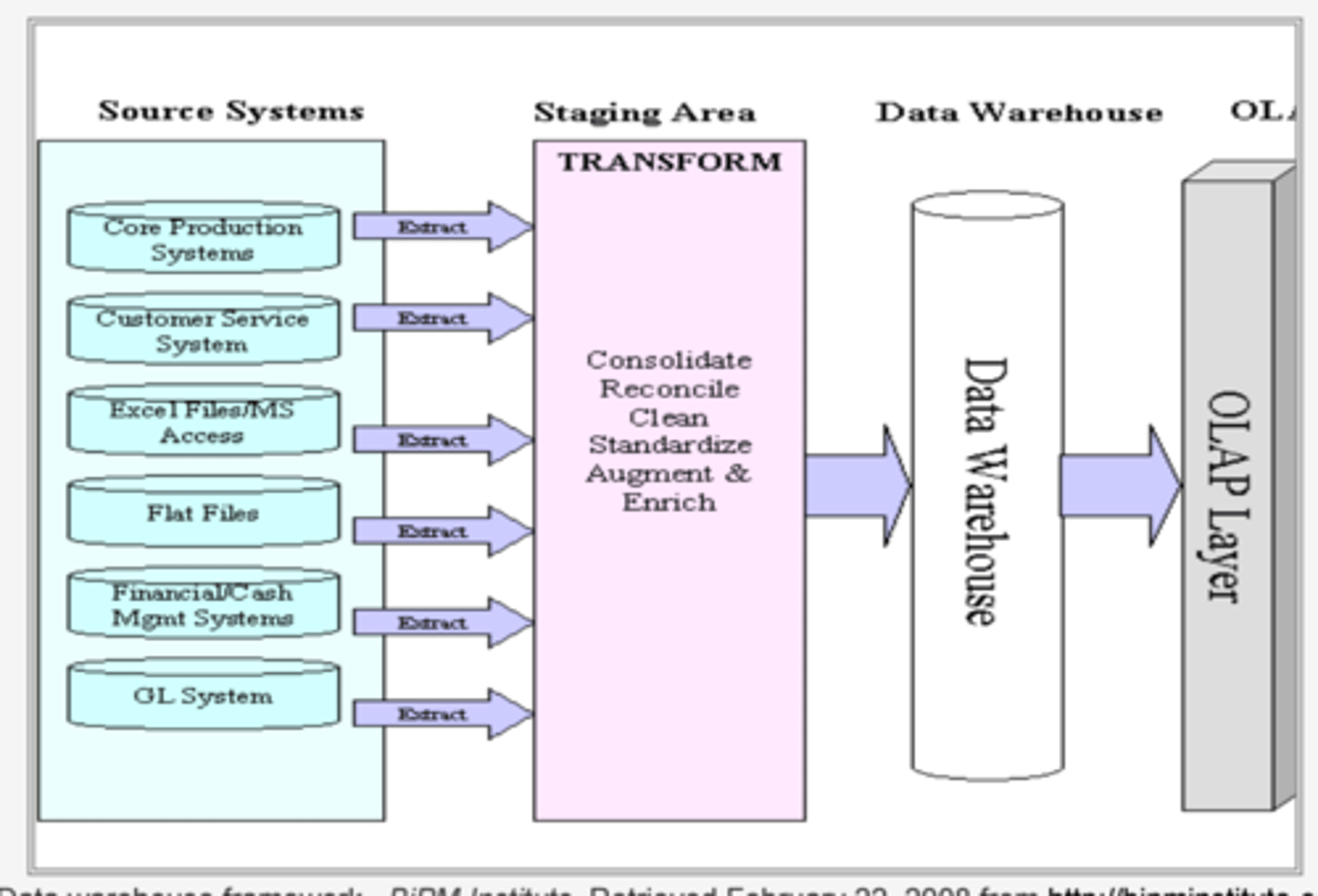
ETL
Extract, Transform, and Load. Used to standardize data across systems, that allow it to be queried.
Normalization
A database data modeling practice that enforces strict control over the relationships of tables and columns within a database. The goal of normalization is to remove the redundancy of data within a database and ensure referential integrity.
There are several levels of normalization, each with its own set of guidelines, known as normal forms.
Denormalization
A database optimization technique applied after normalization in which redundant data is added to one or more tables. This can help avoid costly joins in a relational database.
Denormalized
No normalization. Nested and redundant data is allowed. This is distinct from denormalization.
Normal Forms
Series of guidelines that help to ensure that the design of a database is efficient, organized, and free from data anomalies.
Used to eliminate or reduce redundancy in database tables.
Each form incorporates conditions of prior forms.
The normal forms are:
o First Normal Form (1NF)
o Second Normal Form (2NF)
o Third Normal Form (3NF)
o Boyce-Codd Normal Form (BCNF)
o Fourth Normal Form (4NF)
o Fifth Normal Form (5NF)
Primary Key
An attribute, or combination of attributes, that uniquely identify a record. Each key value occurs at most once; otherwise, a value would map to multiple rows in the table.
The primary key forms a functional dependency with the other attributes in a table.
Candidate Key
An attribute, or combination of attributes, that meet the requirements of a primary key.
Only one candidate key can be a primary key.
A table with no candidate keys does not represent a relation.
Functional Dependency
Occurs when an attribute in a table determines another attribute in the same row.
The attributes are known as the determinant and dependent.
Determinant
Any attribute that you can use to determine the value assigned to another attribute in the same row.
Dependent
Any attribute whose value is dependent on the value assigned to another attribute in the same row.
Partial Dependecy
Occurs when an attribute in a table depends on only a part of the primary key and not the whole key.
Transitive Dependency
Occurs when a non-key attribute depends on another non-key attribute.
First Normal Form (1NF)
Cannot contain multi-valued attributes and there must be a primary key.
Second Normal Form (2NF)
The requirements of 1NF, plus partial dependencies are removed.
Third Normal Form (3NF)
The requirements of 2NF, plus each table contains only relevant fields related to its primary key and has no transitive dependencies.
Boyce-Codd Normal Form (BCNF)
BCNF is a stricter form of 3NF that ensures that each determinant in a table is a candidate key. In other words, BCNF ensures that each non-key attribute is dependent only on the candidate key.
Data Analytics
The broad field of using data and tools to make business decisions.
1. Collecting and ingesting the data
2. Categorizing the data into structured/unstructured forms, which might also define next actions
3. Managing the data, usually in databases, data lakes, and/or data warehouses
4. Storing the data in hot, warm, or cold storage
5. Performing ETL (extract, transform, load)
6. Analyzing the data to extract patterns, trends, and insights
7. Sharing the data to business users or consumers, often in a dashboard or via specific storage
Data Analysis
A subset of data analytics, data analysis consists of cleaning, transforming, and modeling, data to find useful information and draw conclusions.
Data Pipeline
The combination of architecture, systems, and processes that move data through the stages of the data engineering lifecycle.
Data Mart
A more refined subset of a data warehouse designed to serve analytics and reporting, focused on a single suborganization, department, or line of business; every department has its own data mart, specific to its needs.
ACID
ACID is an acronym that refers to the set of 4 key properties that define a transaction:
1. Atomicity
2. Consistency
3. Isolation
4. Durability
If a database operation has these ACID properties, it can be called an ACID transaction, and data storage systems that apply these operations are called transactional systems.
ACID transactions ensure the highest possible data reliability and integrity.
Atomicity (ACID)
Each statement in a transaction (to read, write, update or delete data) is treated as a single unit. Either the entire statement is executed, or none of it is executed.
This property prevents data loss and corruption from, for example, if a streaming data source fails mid-stream.
Isolation (ACID)
When multiple users are reading and writing from the same table all at once, isolation of their transactions ensures that the concurrent transactions don't interfere with or affect one another.
Each request can occur as though they were occurring one by one, even though they're actually occurring simultaneously.
Durability (ACID)
Ensures that changes to data made by successfully executed transactions will be saved, even in the event of system failure.
Consistency (ACID)
Ensures that transactions only make changes to tables in predefined, predictable ways.
Ensures that corruption or errors in data do not create unintended consequences for the integrity of a table.
Data Lineage
Describes the recording of an audit trail of data through its lifecycle, tracking both the systems that process the data and the upstream data it depends on.
Helps with error tracking, accountability, and debugging of data and the systems that process it.
OLAP (Online Analytical Processing)
Manipulation of information to create business intelligence in support of strategic decision making.
Optimized for complex data analysis and reporting.
OLTP (Online Transaction Processing)
Capturing and storing data from day-to-day business transactions
Optimized for transactional processing and real-time updates.
Data Enrichment
Process of combining first party data from internal sources with disparate data from other internal systems or third party data from external sources.
Fact Table
Stores quantitative information for analysis and is often denormalized.
Dimension Table
Stores attributes, or dimensions, that describe the objects in a fact table. In data warehousing, a dimension is a collection of reference information about a measurable event.
Star Schema
A dimensional model where a single fact table connects to multiple dimension tables.
Used to denormalize business data into dimensions (like time and product) and facts (like transactions in amounts and quantities) to make querying and working with the data faster and easier.
Increases query speed by avoiding computationally expensive join operations.
Snowflake Schema
A multi-dimensional data model that is an extension of a star schema, where dimension tables are broken down into subdimensions.
Enterprise Architecture
Design of systems to support change in enterprise, achieved by flexible and reversible decisions reached through careful evaluation of trade-offs.
Data Architecture
A subset of enterprise architecture applied to data systems, and inheriting its properties:
o processes
o strategy
o change management
o evaluating trade-offs
Includes documenting an organization's data assets, data mapping, management of data, and more.
Data Engineer
Manages the data engineering lifecycle, beginning with getting data from source systems and ending with serving data for use cases, such as analysis or machine learning.
Data Engineering Lifecycle
A comprehensive process that includes various stages, from data ingestion to deployment, to ensure that data pipelines are reliable, efficient, and secure.
The stages of the data engineering lifecycle are as follows:
1. Generation
2. Storage
3. Ingestion
4. Transformation
5. Serving
The data engineering lifecycle also has a notion of undercurrents—critical ideas across the entire lifecycle. These include:
o security
o data management
o DataOps
o data architecture
o orchestration
o software engineering
DataOps
A set of practices, processes and technologies that combines an integrated and process-oriented perspective on data with automation and methods from agile software engineering to improve quality, speed, and collaboration and promote a culture of continuous improvement in the area of data analytics.
Orchestration
An automated process for accessing raw data from multiple sources, performing data cleaning, transformation, and modeling techniques, and serving it for analytical tasks.
An orchestration engine builds in metadata on job dependencies, generally in the form of a directed acyclic graph (DAG).
The DAG can be run once or scheduled to run at a fixed interval of daily, weekly, every hour, every five minutes, etc.
Generation [Data Engineering Lifecycle]
A source system that generates data used in the data engineering lifecycle.
A data engineer consumes data from a source system but doesn't typically own or control the source system itself.
Engineers need to have a working understanding of the way source systems work, the way they generate data, the frequency and velocity of the data, and the variety of data they generate.
Engineers also need to keep an open line of communication with source system owners on changes that could break pipelines and analytics
Storage [Data Engineering Lifecycle]
Where and how data is stored. While storage is a stage of the data engineering lifecycle, it frequently touches on other stages, such as ingestion, transformation, and serving.
Storage is one of the most complicated stages of the data lifecycle for a variety of reasons.
First, data architectures in the cloud often leverage several storage solutions. Second, few data storage solutions function purely as storage, with many supporting complex transformation queries.
Third, storage runs across the entire data engineering lifecycle, often occurring in multiple places in a data pipeline, with storage systems crossing over with source systems, ingestion, transformation, and serving.
In many ways, the way data is stored impacts how it is used in all of the stages of the data engineering lifecycle.
Transformation [Data Engineering Lifecycle]
Stage where data is changed from its original form into something useful for downstream use cases.
Logically, transformation is a standalone area of the data engineering lifecycle, but in reality transformation is often entangled in other stages of the lifecycle.
Typically, data is transformed in source systems or in flight during ingestion. For example, a source system may add an event timestamp to a record before forwarding it to an ingestion process. Or a record within a streaming pipeline may be "enriched" with additional fields and calculations before it's sent to a data warehouse.
Data preparation, data wrangling, and cleaning—these transformative tasks add value for end consumers of data.
Serving [Data Engineering Lifecycle]
Data Ingestion [Data Engineering Lifecycle]
The process of moving data from one place to another.
Data ingestion implies data movement from source systems into storage in the data engineering lifecycle, with ingestion as an intermediate step.
Ingestion is the stage where data engineers begin actively designing data pipeline activities.
Data Integration
Combines data from disparate sources into a new dataset.
Serialization
Encoding data from a source and preparing data structures for transmission and intermediate storage stages.
Deserialization
Reverse of serialization, taking data structured in some format, and rebuilding it into an object.
API (Application Programming Interface)
A standard way of exchanging data between systems.
In theory, APIs simplify the data ingestion task for data engineers. In practice, many APIs still expose a good deal of data complexity for engineers to manage.
Even with the rise of various services and frameworks, and services for automating API data ingestion, data engineers must often invest a good deal of energy into maintaining custom API connections
REST (REpresentational State Transfer)
A set of architectural constraints, not a protocol or a standard.
API developers can implement REST in a variety of ways.
When a client request is made via a RESTful API, it transfers a representation of the state of the resource to the requester or endpoint. This information, or representation, is delivered in one of several formats via HTTP: JSON, HTML, plain text, etc.
Something else to keep in mind: Headers and parameters are also important in the HTTP methods of a RESTful API HTTP request, as they contain important identifier information as to the request's metadata, authorization, uniform resource identifier (URI), caching, cookies, and more.
There are request headers and response headers, each with their own HTTP connection information and status codes.
In order for an API to be considered RESTful, it has to conform to these criteria:
o A uniform interface: Resources should be uniquely identifiable through a single URL, and resources should only be manipulated by underlying methods of the network protocol (PUT, DELETE, GET).
o Client-server based: UI and request-gathering concerns are the client's domain. Data access, workload management and security are the server's domain.
o Stateless operations: All client-server operations should be stateless (the state should not be stored).
o Resource caching: All resources should allow caching unless explicitly indicated that caching is not possible.
o Layered system: REST allows for an architecture composed of multiple layers of servers.
o Code on demand: When necessary, servers can send executable code to the client.
SOAP (Simple Object Access Protocol)
A messaging standard that uses an XML data format to declare its request and response messages.
Popular protocol for designing APIs.
JSON (JavaScript Object Notation)
A language-independent data format derived from JavaScript.
Syntax rules are:
o Data is in name/value pairs
o Data is separated by commas
o Curly braces hold objects
o Square brackets hold arrays
JSON is the most generally popular file format to use for APIs because, despite its name, it's language-agnostic, as well as readable by both humans and machines.
XML (Extensible Markup Language)
A markup language and file format for storing, transmitting, and reconstructing data that is readable by both humans and machines.
A markup language that is designed to carry data, in contrast to HTML, which indicates how to display data.
Markup Language
A markup language is a tag-based system that produces formatted, annotated, and human-readable results Examples include HTML, XML, and LaTeX.
DBMS (Database Management System)
Software responsible for creation, retrieval, updating, and management of a database.
Ensures that data is consistent, organized, and easily accessible by serving as an interface between the database and its end-users or application software.
RDBMS (Relational Database Management System)
Unlike a DBMS, an RDBMS stores data as a collection of tables, and relations can be defined between the common fields of these tables.
Most modern database management systems (MySQL, Microsoft SQL Server, Oracle) are based on RDBMS.
SQL (Structured Query Language)
The standard language for storing, manipulating, and retrieving data in a RDBMS.
Table
An organized collection of data stored as rows and columns in a relational database.
Columns can be referred to as fields and rows can be referred to as records.
Constraint
Used to specify the rules concerning data in a table. Can be applied for single or multiple fields in a table during creation or after using the ALTER TABLE command.
Constraints include
o NOT NULL - Restricts NULL value from being inserted into a column.
o CHECK - Verifies that all values in a field satisfy a condition.
o DEFAULT - Automatically assigns a default value if no value has been specified for the field.
o UNIQUE - Ensures unique values to be inserted into the field.
o INDEX - Indexes a field providing faster retrieval of records.
o PRIMARY KEY - Uniquely identifies each record in a table.
o FOREIGN KEY - Ensures referential integrity for a record in another table.
Foreign Key
An attribute, or collection of attributes, that refer to the primary key of another table.
Foreign key constraint ensures referential integrity in the relation between two tables.
The table with the foreign key constraint is labeled as the child table, and the table containing the primary key is labeled as the referenced or parent table.
Join
A SQL clause used to combine records from two or more tables in a SQL database based on a related column between the two.
The four main joins are:
o (INNER) JOIN - Retrieves records that have matching values in both tables.
o LEFT (OUTER) JOIN - Retrieves all records from the left table and matched records from the right table.
o RIGHT (OUTER) JOIN - Retrieves all records from the right table and matched records from the left table.
o FULL (OUTER) JOIN - Retrieves records from both tables, whether they match or not.
Self-Join
A case where a table is joined to itself based on some relation between its own column(s).
A self-join uses the (INNER) JOIN or LEFT (OUTER) JOIN clause and a table alias is used to assign different names to the table within the query.
Can also include the same table two or more times in the FROM statement (using aliases) and a WHERE clause to retrieve records with matching values.
CROSS JOIN
A cartesian product of the two tables included in the join. The table after join contains the same number of rows as in the cross-product of the number of rows in the two tables.
If a WHERE clause is used in cross join then the query will work like an INNER JOIN.
Index
A data structure that provides a quick lookup of data in a column or columns of a table.
Enhances the speed of operations accessing data from a table at the cost of additional writes and memory to maintain the index.
CREATE INDEX index_name
ON table_name (column_1, column_2);
DROP INDEX index_name;
There are different types of indexes that can be created for different purposes:
o Unique and Non-Unique
o Clustered and Non-Clustered
Unique and Non-Unique [Index]
Unique indexes are indexes that help maintain data integrity by ensuring that no two records in a table have identical key values.
Once a unique index has been defined for a table, uniqueness is enforced whenever keys are added or changed within the index.
Non-unique indexes are used solely to improve query performance by maintaining a sorted order of data values that are used frequently.
Primary Key vs. Unique Index
Things that are the same:
o A primary key implies a unique index.
Things that are different:
o A primary key also implies NOT NULL, but a unique index can be nullable.
o There can be only one primary key, but there can be multiple unique indexes.
o If there is no clustered index defined then the primary key will be the clustered index.
Clustered and Non-Clustered [Index]
Clustered indexes are indexes whose records are ordered in the database the same as they are in the index.
This is why only one clustered index can exist in a given table.
Clustering can improve most query operations' performance because it creates a linear-access path to data stored in the database.
Data Integrity
Assurance of data accuracy and consistency over its entire lifecycle and is a critical aspect of the design, implementation, and usage of any system which stores, processes, or retrieves data.
Query
A request for data or information from a database table or combination of tables.
A database query can be either a select query or an action query.
Select Query
A query that retrieves records from a table in a database.
Action Query
A query that makes changes to the data in the database, such as adding or altering a table.
Subquery
A query within another query, also known as a nested query or inner query.
It is used to restrict or enhance the data to be queried by the main query, thus restricting or enhancing the output of the main query respectively.
There are two types of subquery - correlated and non-correlated.
Correlated and Non-Correlated [Subquery]
A correlated subquery cannot be considered as an independent query, but it can refer to the column in a table listed in the FROM of the main query.
A non-correlated subquery can be considered as an independent query and the output of the subquery is substituted in the main query.
Common SQL Clauses [SQL]
WHERE: used to filter records that are necessary, based on specific conditions.
ORDER BY: used to sort the records based on some field(s) in ascending
GROUP BY: used to group records with identical data and can be used in conjunction with some aggregation functions to produce summarized results from the database.
HAVING: filters records in combination with the GROUP BY clause. It is different from WHERE, since the WHERE clause cannot filter aggregated records.
UNION, MINUS, INTERSECT
Commands that mimic set theory operations of the same names.
UNION: combines and returns all records retrieved by two or more SELECT statements.
MINUS: returns all records in the first SELECT statement that are not returned by the second SELECT statement
INTERSECT: returns matching records retrieved by the two SELECT statements
View
A virtual table based on the result-set of an SQL statement. A view contains rows and columns, just like a real table. The fields in a view are fields from one or more real tables in the database.
Entity
A thing, place, person or object that is independent of another and stored in a database.
Relationship
Relations or links between entities that have something to do with each other.
Types of Relationships [Relationship]
One-to-One - Each record in one table is associated with exactly one record in the other table.
One-to-Many & Many-to-One - A record in a table is associated with multiple records in the other table.
Many-to-Many - Multiple records in a table are associated with multiple records in another table.
Self-Referencing Relationships: When a record in a table is associated with another record in the same table but a different column.
TRUNCATE vs. DELETE
The TRUNCATE command is used to delete all the rows from the table and free the space containing the table.
The DELETE command deletes only the rows from the table based on the condition given in the WHERE clause or deletes all the rows from the table if no condition is specified. But it does not free the space containing the table.
XHTML (Extensible Hypertext Markup Language)
XHTML is a stricter, more XML-based version of HTML.
It is HTML defined as an XML application.
XHTML is easy to use with other data formats, and it creates more neat code as it is stricter than HTML.
XHTML documents are well-formed and may therefore be parsed using standard XML parsers, unlike HTML, which requires a lenient HTML-specific parser.
HL7 (Health Level Seven International)
A non-profit ANSI-accredited standards development organization that develops standards for health data interoperability.
HL7 has developed frameworks for modelling, exchanging and integrating electronic health data across systems.
HL7 standards can be divided into three versions:
o HL7 Version 2 (v2)
o Version 3 (v3)
o FHIR.
FHIR (Fast Healthcare Interoperability Resources) [HL7]
An HL7 standard designed for exchange of healthcare information.
Combines the best features of HL7 V2, HL7 V3 and CDA product lines while leveraging the latest web standards and applying a tight focus on ease of implementation.
The intended scope of FHIR is broad, covering clinical care, public health, clinical trials, administration and financial aspects.
HL7 V2 [HL7]
The most widely used healthcare messaging standard for exchanging clinical and patient data between systems.
Versions maintain backward compatibility to ensure legacy and modern applications.
Provides 80% of the interface foundation; 20% of an interface requires some customization due to the nature of healthcare and its different interactions with patients, healthcare personnel, clinical and operational data across different facilities (hospitals, imaging centers, labs, etc.).
HL7 V3 [HL7]
A new healthcare messaging standard created to address some specific challenges identified in the HL7 V2:
o Implied, rather than consistent, data model.
o Absence of formal methodologies with data modeling, creating inconsistencies and difficulties in understanding.
o Lack of well-defined roles for applications and messages used in different clinical functions.
o Too much flexibility and not enough of a full solution.
It is not backwards compatible with HL7 V2, which limited its adoption.
Developed based on RIM, enabling more reuse, standardization and format consistency.
XML is used as the message syntax for a more human readable, but larger message.
Primarily referenced when implementing CDA for exchanging electronic documents, typically between provider and patient or for public health and quality reporting initiatives.
RIM (Reference Information Model) [HL7]
An object model representing healthcare workflows created as part of HL7 V3.
It is a graphic representation of domains and identifies the life cycle that a message or groups of related messages will carry.
It is a shared model between all domains and, as such, is the model from which all domains create their messages.
Clinical Document Architecture (CDA) [HL7]
An XML-based standard for encoding clinical documents for easy data exchange.
Allows healthcare providers to create digital documents containing patient information that they might wish to send to other healthcare providers or regulatory authorities.
CDA conforms to the HL7 V3 ITS, is based on the HL7 RIM and uses HL7 V3 data types.
Implementation Technology Specification (ITS) [HL7]
Defines how to implement an HL7 standard or model.
Rhapsody Integration Engine
Software solution that provides a platform for integrating and managing healthcare data across different systems and applications.
Facilitates data mapping, routing, and translation between different data formats, and provides workflow tools to automate processes and streamline data exchange.
The system also includes features for monitoring and reporting on interface activity, as well as tools for troubleshooting and resolving issues.
SQL Server Integration Services (SSIS)
A platform for data integration and workflow applications.
A component of the Microsoft SQL Server database software that can be used to perform a broad range of data migration tasks.
Office of the National Coordinator for Health Information Technology (ONC)
ONC is the principal federal entity charged with coordination of nationwide efforts to implement and use the most advanced health information technology and the electronic exchange of health information.
ONC has two strategic objectives:
o Advancing the development and use of health IT capabilities
o Establishing expectations for data sharing
ONC is organizationally located within the Office of the Secretary for HHS.
The position of National Coordinator was created in 2004, by an Executive Order, and legislatively mandated in the HITECH Act of 2009.
21st Century Cures Act (Cures Act)
There are many provisions of the 21st Century Cures Act (Cures Act) that will improve the flow and exchange of electronic health information. ONC is responsible for implementing those parts of Title IV, delivery, related to advancing interoperability, prohibiting information blocking, and enhancing the usability, accessibility, and privacy and security of health IT.
The Cures Act defines interoperability as the ability exchange and use electronic health information without special effort on the part of the user and as not constituting information blocking.
ONC focuses on the following provisions as we implement the Cures Act:
o Section 4001: Health IT Usability
o Section 4002(a): Conditions of Certification
o Section 4003(b): Trusted Exchange Framework and Common o Agreement
o Section 4003(e): Health Information Technology Advisory Committee
o Section 4004: Identifying reasonable and necessary activities that do not constitute information blocking
Affordable Care Act of 2010 (ACA)
Establishes comprehensive health care insurance reforms that aim to increase access to health care, improve quality and lower health care costs, and provide new consumer protections.
Medicare Access and CHIP Reauthorization Act of 2015 (MACRA)
Ended the Sustainable Growth Rate formula and established the Quality Payment Program (QPP).
Under MACRA, the Medicare EHR Incentive Program, commonly referred to as meaningful use, was transitioned to become one of the four components of MIPS, which consolidated multiple, quality programs into a single program to improve care.
Clinicians participating in MIPS earn a performance-based payment adjustment while clinicians participating in an Advanced APM may earn an incentive payment for participating in an innovative payment model.