MOLECULAR GENETICS by QQTD
1/22
Earn XP
Description and Tags
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
23 Terms
How is chromatin formed?
DNA is wound around 8 histone protein molecules to form a nucleosome. The string of nucleosomes coils to form the chromatin fibre. Chromatin fibres are structures found in the nucleus in which genetic material in the form of deoxyribonucleic acid (DNA) molecule is organised.
Where are chromatin fibres found
Chromatin fibres are structures found in the nucleus in which genetic material in the form of DNA a is organised
What are chromosomes
When a cell prepares for nuclear division, the chromatin fibres coil further and fold up (condenses) to form compact structures called chromosomes.
What are genes
• A gene is a small segment of DNA in a chromosome where its specific sequence of nucleotides codes for one polypeptide with a specific sequence of amino acids. A gene can be regarded as a unit of inheritance.
-there are many genes along the length of a DNA molecule
What are nucleic acids
Nucleic acids form the genetic material of all living organisms and are essential for life.
There are two types of nucleic acids found in living cells, namely
-Deoxyribonucleic acid (DNA)
-Ribonucleic acid (RNA)
Nucleic acids are macromolecules made up of basic units called nucleotides.
Multiple nucleotides are covalently joined together to form a polynucleotide which is an
extremely long molecule.
Compare Purines and Pyrimidines
Purines:
Double ring structures, Larger, Adenine and Guanine
Pyrimidines:
Single ring structures, smaller, Thymine and Cytosine
What does a nucleotide consist of
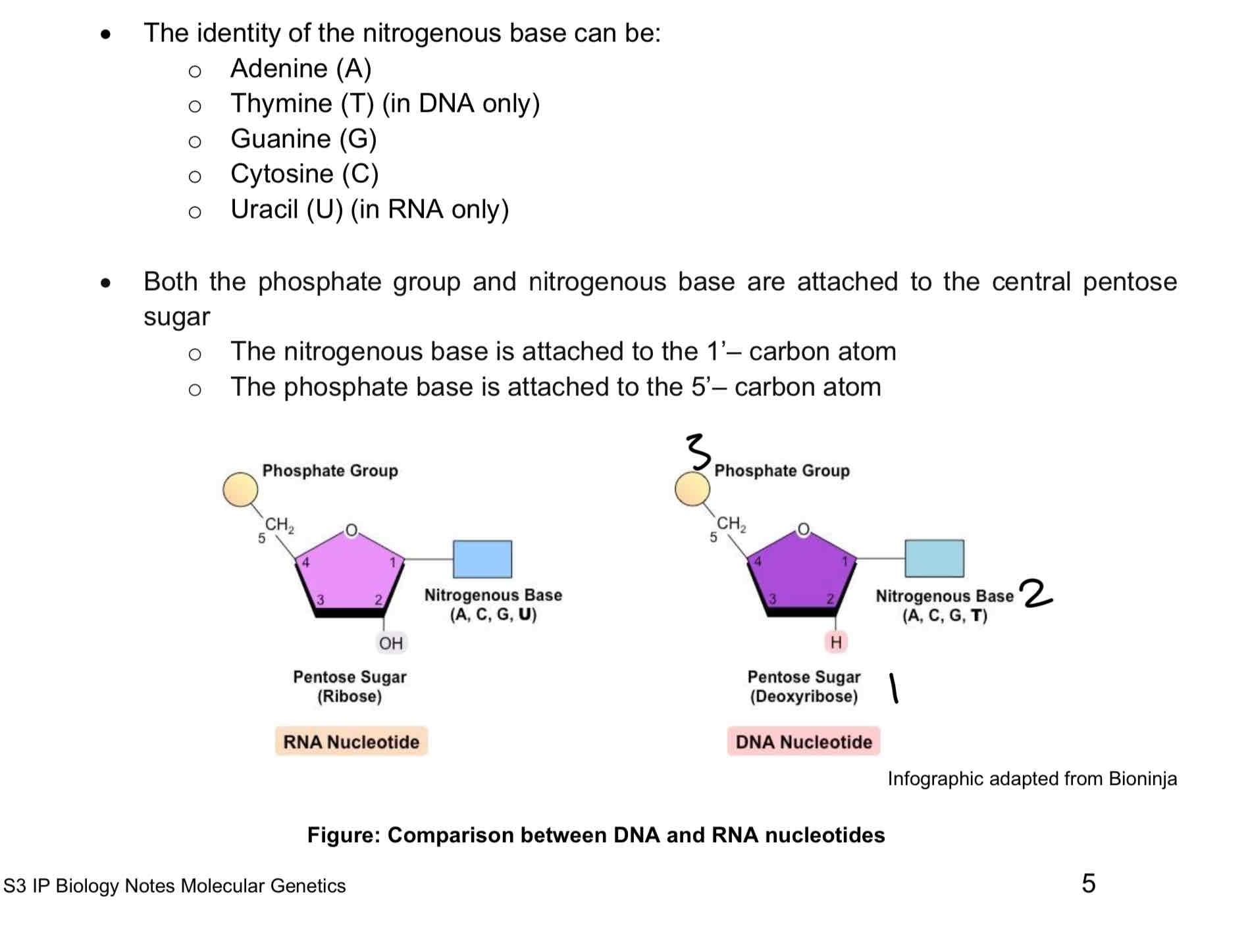
A nucleotide consists of three components: a pentose (5-carbon) sugar, phosphate group and a nitrogenous base.
It is a molecule formed by atoms of carbon (C), hydrogen (H), oxygen (O), nitrogen (N) and phosphorus (P).
DNA contains the 5-carbon deoxyribose sugar and RNA contains ribose sugar instead.
The phosphate group derived from phosphoric acid gives nucleic acids its acidic property
Identity of nitrogenous base can be: Adenine, Thymine(DNA), Guanine, Cytosine
Both the phosphate group and nitrogenous base are attached to the central pentose sugar
Nitrogenous base is attached to the 1’-carbon atom
Phosphate base is attached to the 5’-carbon atom
Describe the structure of a DNA
Each DNA molecule is a double-stranded molecule that consists of two polynucleotide chains wound around each other to form a double helix.
Each polynucleotide chain/strand
-has a sugar-phosphate backbone with nitrogenous bases projected at right angles from 1’-carbon atom
-consists of nucleotides held together by strong covalent phosphodiester linkages.
The two polynucleotide strands are antiparallel; one strand runs in the 5’ to 3’ direction while the other strand runs in the 3’ to 5’ direction i.e. the opposite direction.
-They are held together by hydrogen bonds between the complementary nitrogenous bases of opposite strands.
-Two hydrogen bonds between nitrogenous bases A and T, three hydrogen bonds between C and G.
The sugar-phosphate backbones of both strands lie on the outside of the DNA molecule whereas the nitrogenous bases point towards the centre of the molecule.
Structure of RNA
Each RNA molecule is usually single-stranded except for the RNA in some viruses.
It is structurally similar to a single strand of DNA molecule with the following exceptions:
-Presence of 5-carbon ribose sugar instead of not deoxyribose
-Presence of uracil nitrogenous base instead of thymine
There are three main types of RNA, namely messenger RNA (mRNA), transfer RNA (tRNA) and ribosomal RNA (rRNA).
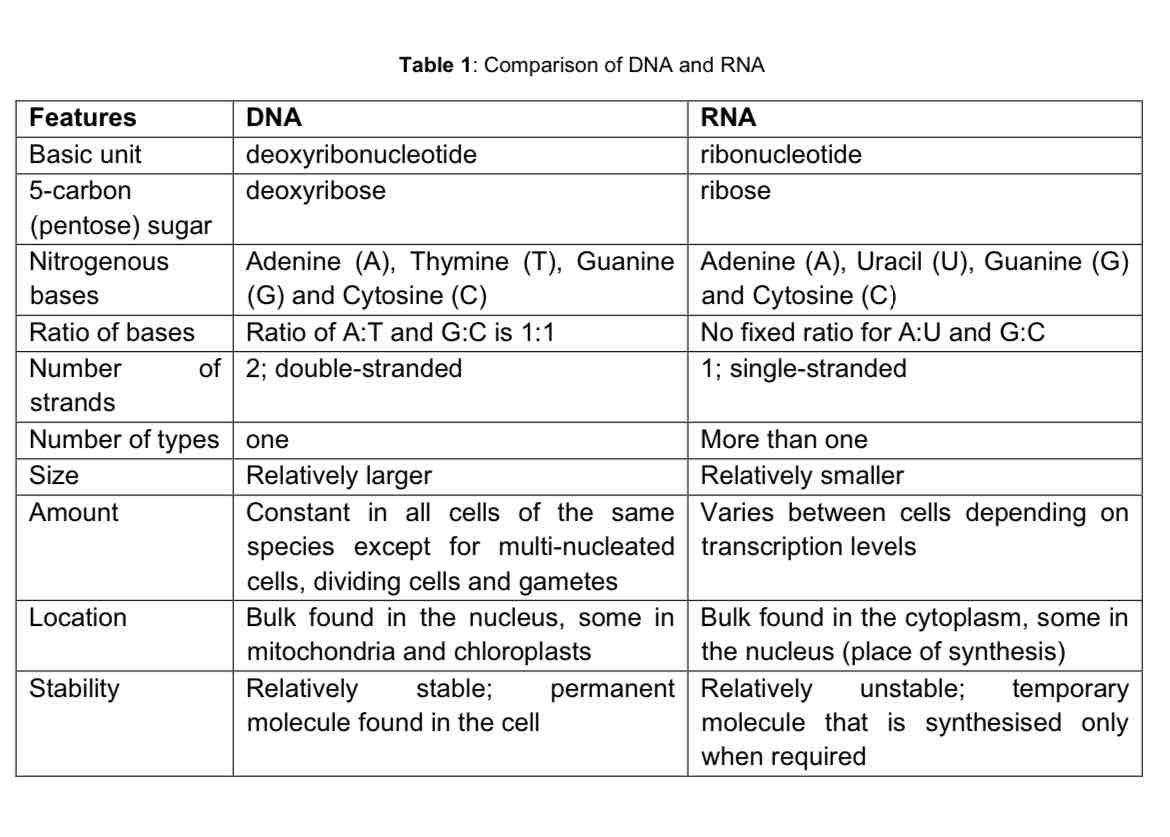
DNA vs RNA
What is the Central Dogma
• The flow of genetic information from DNA through RNA to protein is known as the Central Dogma of Molecular Biology.
-includes Transcription and Translation
Transcription: process where gene on DNA is copied to form a piece of messenger RNA(mRNA) at the NUCLEUS
-relies on only 1 of the 2 DNA strands, called the template strand
-non template strand is also known as CODING STRAND, SAME AS mRNA except T→U
Translation: process by which genetic information on the messenger RNA(mRNA) is read by a
-ribosome reads nitrogenous bases in groups of 3 called CODONS
-1 codon= 1 amino acid → makes a polypeptide chain
What is the genetic code
The sequence of bases in DNA determines the sequence of amino acids in a protein.
The genetic code describes the relationship between the sequence of DNA bases (A, C, G, and T) in a gene and the corresponding protein sequence that it encodes.
Features of the GENETIC CODE
The code is a triplet code- each amino acid in a polypeptide chain is coded for by a sequence of 3 consecutive bases in the DNA, which is in turn transcribed into a sequence of 3 consecutive bases in the mRNA molecule.
The genetic code is read as a sequence of non-overlapping triplets
The genetic code is nearly universal- the same triplet of nucleotides codes for the same amino acid in all organisms
The genetic code is DEGENERATE- more than 1 codon can code for the SAME AMINO ACID
The genetic code has start and stop codons
Start codon: AUG
Stop codon: UAA, UGA, UAG
DNA REPLICATION
Consists of
Conservative
Semi-Conservative
Dispersive
Conservative Model
The parental double helix remains completely intact and an all new copy is made→ both strands of parental strand remain unchanged
Semi- Conservative Model
The two strands of parental molecules separate and each strand functions as a template for synthesis of a new complementary strand
Dispersive Model
Each strand of BOTH DAUGHTER MOLECULES contains a mixture of old and newly synthesised parts
Definition of genetic engineering
Genetic engineering is the process of using recombinant DNA (rDNA) technology to alter the genetic makeup (genome) of an organism. Genes can be transferred from one organism to another organism of the same species or a different species.
Synthesis of human insulin by bacteria:
Disadvantages of extracting animal insulin from the pancreas of animals
-animal insulin is not identical to human insulin
-diseases and allergens can be transferred from animals and humans, resulting in more side effects
How is human insulin synthesised from bacteria
The human insulin gene is isolated from the human chromosome. The ends of the gene are cut by a restriction enzyme to generate sticky ends
A bacterial plasmid (double-stranded DNA in circular form) is isolated from a bacterial plasmid donor.The plasmid is cut by the same restriction enzyme, to generate the same sticky ends.
The sticky ends on the human insulin gene and the bacterial plasmid are complementary to each other and can bind to each other.
The DNA sugar-phosphate backbones between the bacterial plasmid and insulin gene are repaired using DNA ligase, creating a recombinant plasmid (plasmid containing human insulin gene).
The bacterial cell is induced to take up the recombinant plasmid through a process called transformation. Bacterial cells are either heat shocked or applied with an electrical current to make the cell walls and membranes permeable so that the recombinant plasmid can enter the bacterial cell.
After transformation, bacterial cells are plated on an agar-coated petri dish containing antibiotics and incubated at a suitable temperature overnight for screening. The bacterial plasmid often carries an antibiotic resistance gene that confers the bacterium resistance against a particular antibiotic. ONLY Transgenic bacteria that have taken up the recombinant plasmid have anti biotic resistant genes and would grow and form a distinct colony of cells on the antibiotic-containing agar.
Successfully transformed bacteria containing the insulin gene are cultured and multiplied in a fermenter industrially.
Human insulin mRNAs are transcribed from the human insulin DNA on the recombinant DNA plasmid inside the bacterial cells They are then translated by the bacterial ribosomes to synthesise human insulin protein.
Human insulin proteins made by the bacteria are subsequently isolated and purified by crystallisation.
Advantages of human insulin synthesised from bacteria:
Synthesised in larger volumes in fermenter
Cheaper, less money to grow large volume of bacteria
Produces insulin faster than if animal sources were used
Human insulin is produced, so less allergens
Golden rice
-what is it
-issue it’s solving
-benefits
Golden rice is a transgenic plant containing genes from other species of organisms
Beta-carotene gene from corn and soil bacteria.
-Created using genetic engineering and biotechnology methods.
-Beta-carotene is the precursor of vitamin A, and is found in the edible parts of the rice. Beta-carotene is converted to vitamin A in the human body.
Background information
-Philippines is a poor country, people consume diets low in vitamin A.
-Vitamin A deficiency causes blindness.
-White rice (low in vitamin A) is their staple food.
Benefits
-reduces suffering from VITAMIN A DEFICIENCY, REDUCE BLINDNESS
-less ex alternative to vitamin supplements
-cheap source of vit A
Concerns with genetic engineering
-Earlier strains of golden rice had low amounts of vitamin A. Problem solved by developing new strains of rice with higher amounts of vitamin A.
-Use of golden rice will open the door to more widespread use of GMOs (genetically modified organisms), which hold risks that may not be understood.
-Some religious individuals may feel that creation of transgenic organisms is going against laws of nature
o If a transgenic plant contains animal genes, vegetarians may not want to consume it. (not applicable to golden rice)