Object recognition
1/26
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
27 Terms
Indexing local features problem
With potentially thousands of features per image, and hundreds to millions of images to search, how to efficiently find those that are relevant to a new image?
Inverted File Index idea
For text documents, efficient way to find the pages a word occurs is an index
We want to find all images in which a feature occurs
To use this idea, need to map our features to “visual words”.
Indexing with visual words
Map high dimensional SIFT descriptors to tokens/words by quantising the feature space
Quantise via clustering, let cluster centres be prototype “words”
Determine which word to assign to each new image region by finding the closest cluster centre.
Inverted file index
Database map from visual word to the image it occurs in
Extract words in query
Inverted file index to find relevant frames
Compare word counts
Spatial verification
Need to know visual words are geometrically arranged in a compatible way between two images
Spatial verification strategy
Generalised Hough Transform
Let each matched feature cast a vote on location, scale, orientation of model object
Verify parameters with enough votes
Application of Inverted File Index: Video Google System
Collect all words within query region
Inverted file index to find relevant frames
Compare word counts
Spatial verification
Issues for formation of visual vocabulary
Sampling strategy: where to extract features?
What clustering/quantisation algorithm to use?
Unsupervised vs supervised
What corpus provides features (universal vocabulary)?
Vocabulary size, number of words
Sampling Strategies
Sparse, at interest points
Specific, textured objects, sparse sampling from interest points more reliable.
Dense, uniformly
For object categorisation, dense sampling offers better coverage
Randomly
Multiple interest operators (e.g. Harris and LoG)
Object Categorisation: Task description
Given a small number of training images of a category, recognise up-til-now unknown instances of that category and assign correct label
Visual object categories - defined in humans?
Predominantly visually. Evidence that humans usually start with basic level categorisation before doing identification
Types of object categories
Functional categories (e.g. chairs, something you can sit on)
Ad-hoc categories (e.g. something you can find in an office environment)
Object recognition robustness:
Illumination
Object pose
Clutter
Occlusions
Intra-class appearance
Viewpoint
Bag of Words: Analogy to documents
Can classify a book based on seeing a group of words you expect to be characteristic of a certain class
Not just the occurrence of certain words but the co-occurrence.

Bag of visual words definition
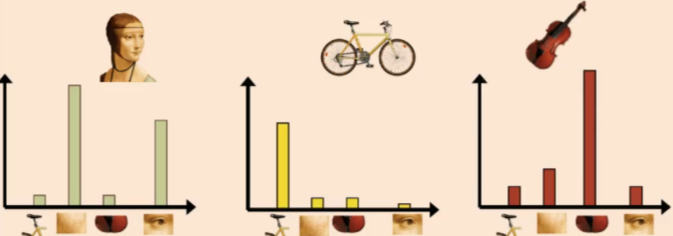
Collection of independent visual words with a histogram representation.
Summarise entire image based on its distribution of word occurences
Analogous to bag of words representation commonly used for documents
First step of training bag of words
Two ways:
Regular grid
Interest point detector
Use SOTA interest point detector
Represent by using SIFT
Comparing bags of words
Build up histograms of word activation - so any histogram comparison measure can be used here
E.g. can rank frames by normalised scalar product between weighted occurence counts
Given bag-of-features representations of images from different classes, how do we train a model to distinguish them?
Extract features from the image
Each of the visual words are labelled with a visual word label
Arrange visual words into a histogram of fixed size that represents your image
Can then either use generative methods or discriminative methods
Discriminative methods
Learn a decision rule (classifier) assigning bag-of-features representations of images to different classes (e.g. SVM)
Discriminative methods tend to have a boundary that gives a yes/no or a separation between classes.
Generative methods
Based on likelihood — “based on my image, what is the likelihood it contains a zebra?”
Discriminative method example: nearest neighbour classification
Assign input vector to one of two or more clases
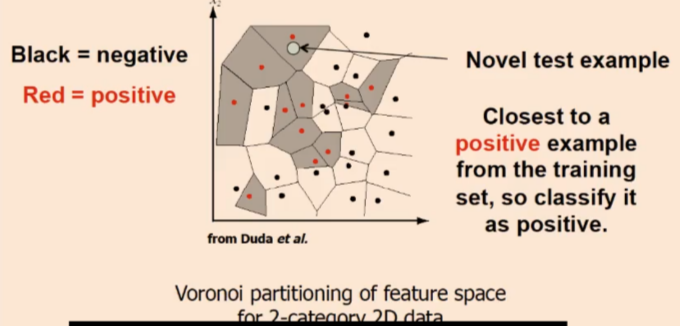
Any decision rule divides input space into decision regions separated by decision boundaries
Assign label of nearest training data point to each test data point
K-nearest neighbour classification will find the k closest points from training data, and labels of k points “vote” to classify
Nearest neighbour method pros
Simple to implement
Flexible to feature/distance choices
Naturally handles multi-class cases
Can do well in practice with enough representative data
Nearest neighbour method cons
Large search problem to find nearest neighbours
Storage of data
Must know we have a meaningful distance function
Generative method example: Naive Bayes Model
Assume each feature given the class
Prior: Boost knowledge with our prior (a certain class is more likely, given where we are)
Naive Bayes classifier assumes that visual words are conditionally independent given object class
Bag-of-words pros
Flexible to geometry/deformations/viewpoint
Compact summary of image content
Provides vector representation of sets
Empirically good recognition results in practice
Methods to add spatial information to BoW
BoW is orderless
Visual ‘phrases’: frequently co-occuring words
Semi-local features: describe configuration, neighbourhood
Let position be part of each feature
Count bags of words only within sub-grids of an image
After matching, verify spatial consistency (e.g. look at neighbours—are they the same too?)
Bag-of-words cons
Basic model ignores geometry — must verify afterwards, or encode via features
Background and foreground mixed when bag covers whole image
Interest points or sampling: no guarantee to capture objective parts
Optimal vocabulary formation remains unclear.