3 ML: Machine Learning
1/15
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
16 Terms
You understand the difference between classification and regression (Classification vs Regression) in supervised learning
Bij classificatie voorspel je categorieën
Bij regressie continue waarden.
Beide gebruiken hypervlakken (hyperplanes) (lineair of niet-lineair).
You know what supervised learning entails (Supervised Learning)
Je traint een model op X en y (train set) en test dan hoe goed het werkt op nieuwe data (test set). (old version)
Je leert de modelparameters op gelabelde trainingsdata (X, y) en controleert de generalisatie door de voorspellingen op een strikt gescheiden, ongeziene testset te vergelijken met de echte labels.
You know what hyperplane is?
Generalization of the concept of a line to higher dimensions
You understand how models are fitted to data (Fitting a model)
Bij supervised learning pas je de parameters van je model aan om patronen in de trainingsdata te herkennen.
Dit kan in één keer (one shot learners)
of iteratief (bijv. neurale netwerken).
You understand the trade-off between model complexity and performance (Bias-Variance Tradeoff)
Te simpele modellen (hoge bias) generaliseren te veel.
Te complexe modellen (hoge variance) overfitten.
Je zoekt balans voor goede generalisatie.
You can explain the difference between training, validation, and test sets (Train/Test/Validation)
Trainingset
Model trainen
Validatieset
Model bijstellen (alleen bij iteratieve modellen)
Testset
Finale evaluatie na het trainen

You know what a decision tree is (Decision Tree)
Tree shaped diagram used to determine a course of action. Each branch of the tree represents a possible decision, occurrence or reaction.
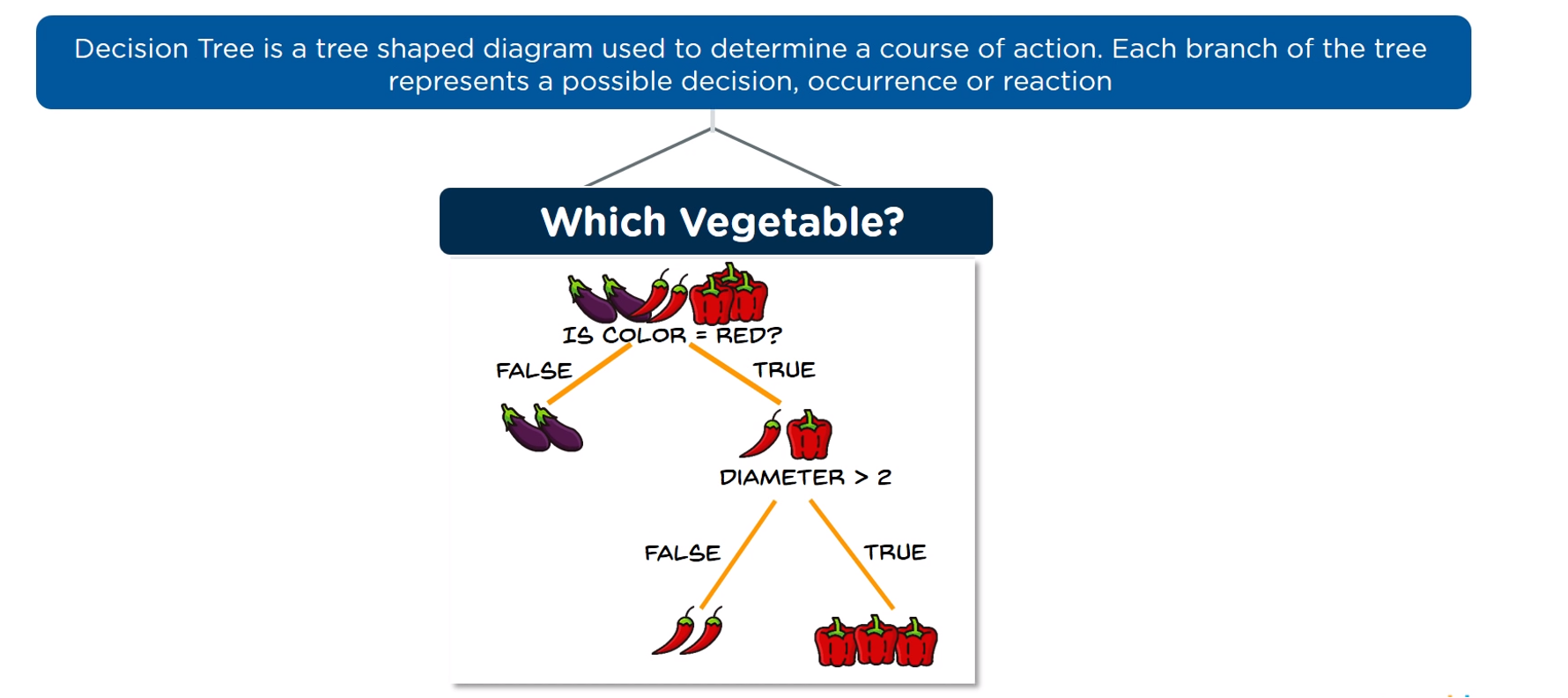
You know how a decision tree works (Decision Tree)
Een decision tree stelt vragen over features en splitst de data herhaaldelijk om zuivere subsets te bekomen. Elke tak eindigt in een leaf node met een klasse.
You understand what makes a good split in a decision tree (Information Gain)
• Een goede splitsing maximaliseert de informatie-winst
You can explain the risk of overfitting in decision trees (Max Depth, Overfitting)
Beslissingsbomen blijven splitsen tot ze perfect passen op de trainingsdata, wat kan leiden tot overfitting. Dit betekent dat het model te specifiek is en slecht generaliseert naar nieuwe data.
Door een maximale diepte in te stellen of kleine takken te snoeien (pruning), beperk je dit risico.
You can explain how to encode non-numeric data (Encoding)
• Categorische data moet worden gecodeerd via label encoding of one-hot encoding zodat modellen ermee kunnen werken.
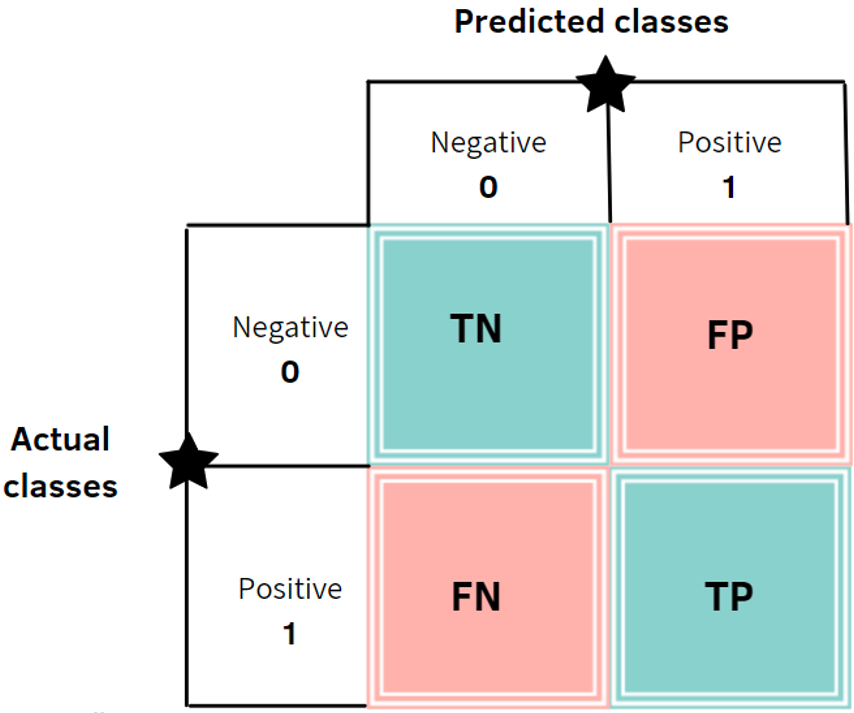
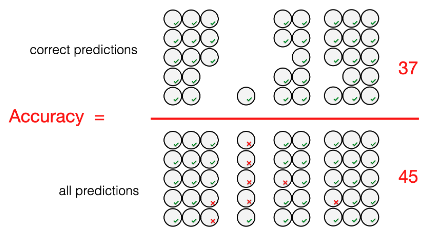
You understand how to evaluate a classifier with accuracy and confusion matrix (Accuracy, CONFUSION MATRIX!!!)
• Accuraatheid toont hoeveel voorspellingen juist waren, maar een confusion matrix toont ook de verdeling van fouten (false positives, false negatives, …).
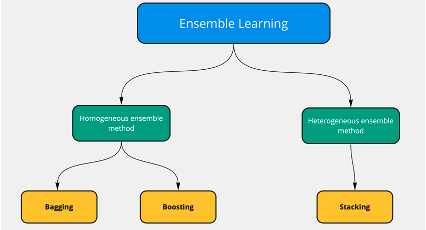
You understand what ensemble learning is (Ensemble Learning)
Combineren van meerdere modellen om tot één sterkere voorspelling te komen.
You can explain how Random Forest works (Random Forest)
Random Forest maakt meerdere decision trees op verschillende bootstrapped datasets en gebruikt majority voting. Dankzij data- en feature bagging wordt overfitting beperkt.
You know what data bagging and feature bagging mean (Random Forest - Bagging)
Data bagging; willekeurige subsets selecteren van de data om de sub-data set aan te maken.
Feature bagging; Op elke node van de boom willekeurig features selecteren om je splitting op te baseren.
You know that out-of-bag samples can be used for validation (Out-Of-Bag)
• Samples die niet geselecteerd zijn in een bootstrapsample vormen out-of-bag data, bruikbaar voor modelvalidatie zonder aparte testset.