oefenen
1/92
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
93 Terms
bij een populatie gebruik je?
z waarde
bij een steekproeg gebruik je?
t waarde
wanneer spreek je over een populatie?
metingen boven 30
wanneer spreek je over een steekproef?
metingen onder 30
hypotheses F toets (H0 en Ha)
H0= varianties zijn gelijk (tweezijdige toets), Ha= de ene variantie is groter dan de andere (eenzijdige toets)
wat toets de f toets?
variantie
wat toets de t toets?
de gemiddelde
hypotheses van t toets
H0= gemiddelde zijn gelijk, Ha- gemiddelde niet gelijk
respons is y bij modellen
y = a+b*x of y= B0+B1*x
predictor
gecontroleerbare variable, risico factor
reponse
y is gemeten variabelen
hoe bepaal je welke lijn het beste past bij gemeten punten?
verticale residuals (x is independent en y is dependent)
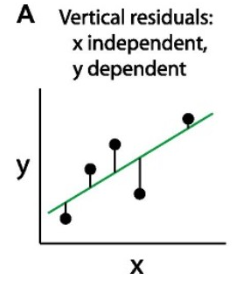
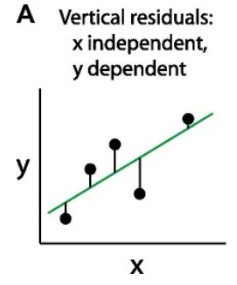
hoe heet de afstand tussen lijn en gemeten punt?
residuals of erros. de lijn minimaliseerd afsand tussen punten en lijn
OLS
ordinary linear regressie model
wat meet OLS?
manier om met least squares methode de parameters te bepalen in regressie model

wat zeggen deze waarde?
95% betrouwbaarheids interval valt binnen (0,03374 en 0,1858) Dit 95% betrouwbaarheids interval bevat niet 0. Dit betekend dat er een significante relatie is tussen concentratie en response

Wat betekend het als het betrouwbaarheids interval 0 bevat?
de conclusie is dan dat er geen verschil is tussen interceptie van 0 en gecalculeerde intercept (98,24833)
confidence interval
bepaald met welke betrouwbaarheid je kunt zeggen in welke interval de ware populatie parameter (zoals intercept en richtingscoefficient) ligt
predicted interval
kijk je naar de kans dat een nieuwe meting binnen bepaald gebied valt
Wanneer is Pi of VI klein?
Als n (aantaal standaarden groot is
als Xh dicht bij gemiddelde x ligt
er een grote range in x aanwezig is
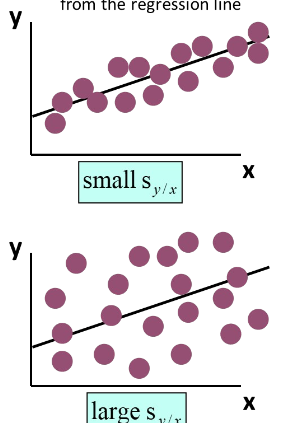
zorgt small of large voor een goed model?
small zorgt voor goede lijn en dus model
waarom is een grotre R² beter?
de kromme lijn gaat beter door punten en verklaard de data dus beter
is correlatie causaliteit (oorzaak gevolg)
nee, misschien speels x slecht kleine rol en is een grote rol voor andere variabele waaraan x gekoppeld is
R² en PI zijn direct gekoppeld (waar/ niet waar)
niet waar
uitbijter
exterme y waarde
leverage point
extreme x waarde
influential point
als punt niet wordt meegenomen in regressie krijg je andere waarde als wanneer deze wel wordt meegenomen (parameters sd, r² ect)
wanneer mag je een waarde verwidjren bij cooks distance?
als deze groter is dan 1
Lack of Fit
test kan achterhlen of een hogere orde model de data beter fit dan rechte lij
wat verwacht je bij een goed model? is lof kleiner/ groter of gelijk aan pe?
kleiner dan
PE
predicted error, voorspellings fout
hypothese lof
H0= er is geen lack of fit, Ha= er is lack of fit
wat heb je nodig om lof te kunnen berekenen
ministens 1 duplo (om PE te bepalen) en meer levels dan [arameters is model
Grafische interpretaties over juistheid gekozen model
LINE (maak scatterplot met Line), zijn punten onafhankelijk van elkaar, Indipendent. is data Normaal verdeeld? en is spreiding van residuen rondom gemiddelde 0 gelijk verdeeld Equivalent verdeedld?
wat test durban watson?
of correlatie aanwezig is, bepaald of residuen onafhankelijk zijn van elkaar
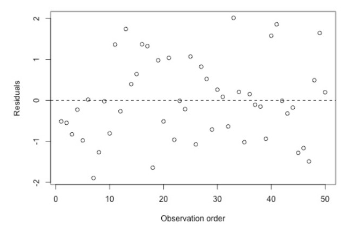
onafhankelijk (I)
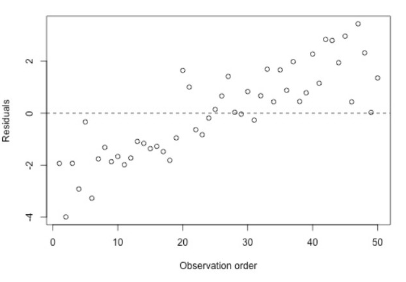
tijdsafhankelijk
positieve seriele correlatie (zelfde stapgroote die elkaar opvolgen)
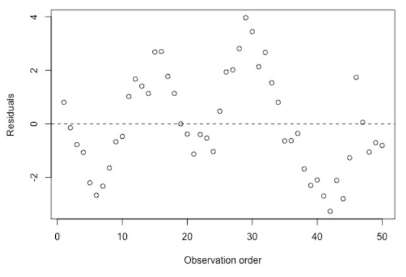
negatieve seriele correlatie (wisseling van tekens + en - ect)
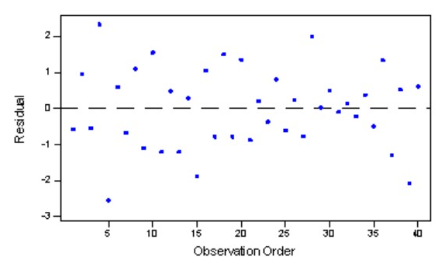
uitbijter
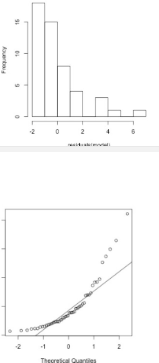
schuin en skew
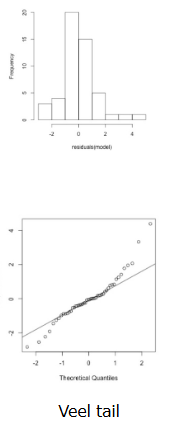
veel tail
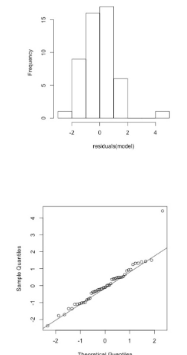
wat doe je al data niet normaal verdeeld is?
-Y transformeren
-Wortel (zwakke correlatie)
-log normaal (kan ook log10)
-1/x (sterke correlatie)
-Box Cox transformatie
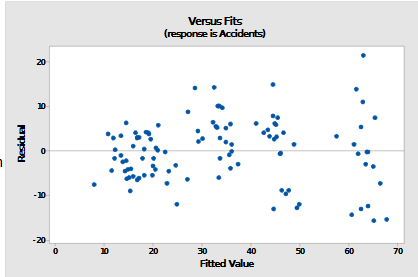
heterocascedaring (variantie neemt toe met de x waarde er wordt neit voldaan aan equal variances)
Waar voldoet heterocascadering niet aan?
linE, variantie neemt toe met de x waarde
hoe los je heterocadastiteit oplossen?
y waarde transformeren
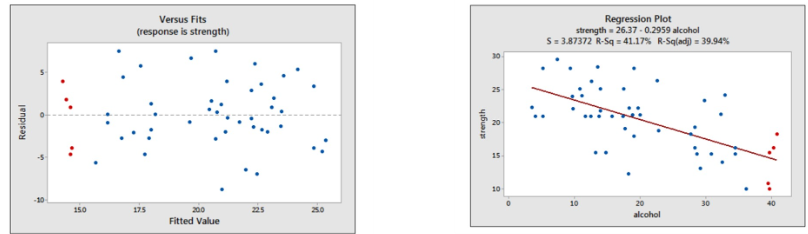
het gaat hier om dezelfde punten (bekijk de rode punten). Residu plot geeft normaal beeld met punten verspreid rondom nul lijn. variantie gelijk. geen uitbijters te zien
variance inflation factor
VIF
VIF
wortel vif is de factor waarmee de SD van die variabele toegenomen tov als er geen correlatie zou zijn geweest
VIF = 1
niet gecorreleerd
VIF < 5
goed weinig tot geen correlatie
VIF > 5
sterk gecorreleerd
regressiemodel bouwen
haal gecorreleerde variabelen weg
bekijk welke gecorreleerd zijn? zie matrixplot, correlatiematrix en VIF waarde
Haal grote VIF weg en p waarde groter dan 0,05
herhaal en bekijk of VIF beter is
interactie tussen de variabelen op de respons
soms is de grootte van de respons afhankelijk van hoe bv de ene variabele is ingesteld tov een andere variabelen
zijn de residuen bij een predictor gebogen?
dan misschien bij die variabele een kwadraat toevoegen
wat gebeurd er als je factoren of interacties weghaalt?
er blijven meer vrijheidsgraden over voor SS error, PE blijft kleiner dus significantie van factore/ interacties. LOF veranderd wel, p waarde dus ook
orthogonale designs geven
onafhankelijke variabelen (geen correlatie met elkaar)