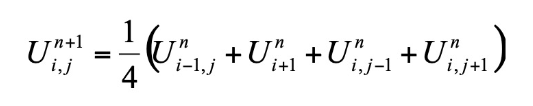3-2 Parallel Computing, Models and their Performance
1/23
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
24 Terms
Bernsteins Conditions
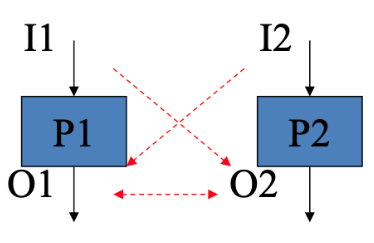
Let P1 be Process 1 and P2 be Process 2
P1 || P2 if and only if all the all variables, registers and memory locations used by both processes are independent of each other
Three Limits to Parallelism and Definitions:
Data Dependencies: one instruction needs the results of a previous instruction as input
Flow Dependencies: the outcome of a subsequent operation is directly affected by the result of a prior operation in the instruction sequence
Resource Dependencies: when two instructions or processes need the same hardware resources (such as memory) to execute
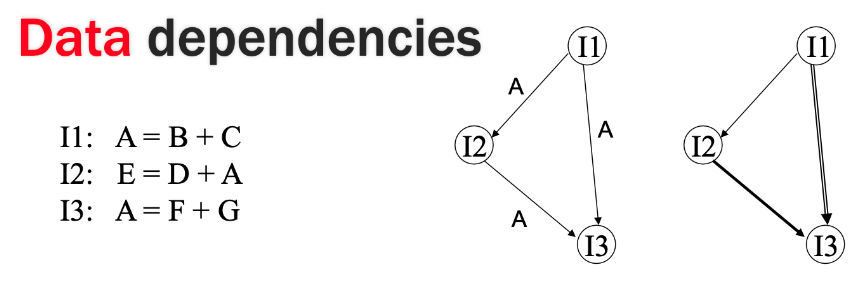
Three Data Dependencies and Definitions
Flow Dependency (RAW): a variable assigned in a statement is used in a later statement
Anti-dependency (WAR): a variable used in a statement is assigned in a subsequent statement
Output Dependency (WAW): a variable assigned in a statement is subsequently re-assigned
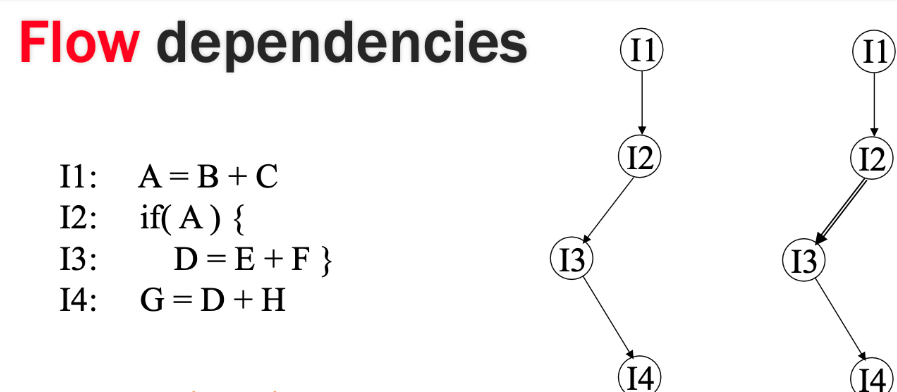
Two Flow Dependencies and Definitions
Data Dependency: one instruction needs the results of a previous instruction as input
Control Dependency: one execution of an instruction depends on the result of a previous condition or decision point in the progam flow.
Example of Resource Dependency
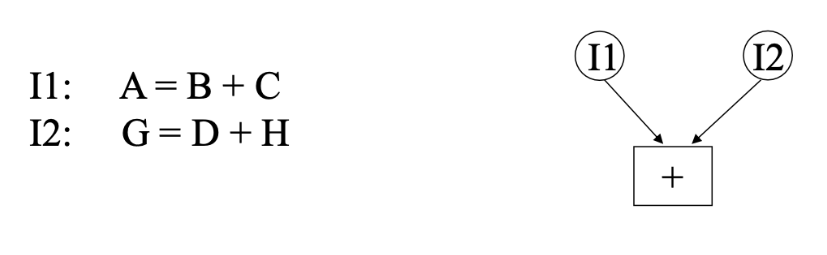
Four Types of Flynn’s Taxonomy
SISD - single instruction, single data
ex: single core processors
SIMD - single instruction, multiple data
ex: GPUs
MISD - multiple instruction, single data
MIMD - multiple instruction, multiple data
ex: multi-core processor, supercomputers
Define Parallel Runtime
the time that elapses from the moment that a parallel computation starts to the moment that the last processor finishes execution
Define Seriel Runtime
the time that elapses from the moment the parallel computation starts to the moment that that the processor finishes execution (assuming the computation is being done on a single processor)
Define Speedup and Give Formula
the ratio of the serial runtime of the best sequential algorithm for solving a problem to the time taken by the parallel algorithm to solve the same problem on p processors
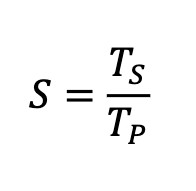
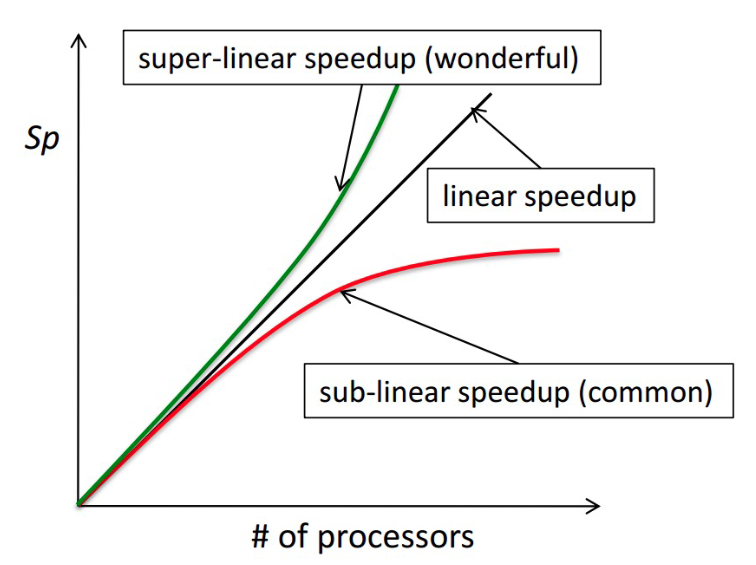
What kind of speedup is desired?
Define Efficiency and Give Formula
the ratio of speedup to the number of processors, measures the fraction of time for which a processor is usefully utilized
* perfect speedup means 100% efficiency
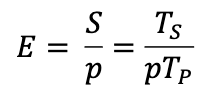
Define Cost and Give Formula
the product of runtime and the number of processors
Define Scalability
a measure of a parallel system’s capacity to increase speedup in porportion to the number of processors
Define Amdahl Law and Give Formula
provides a theoretical limit to the speedup that can be achieved with a parallel processing system
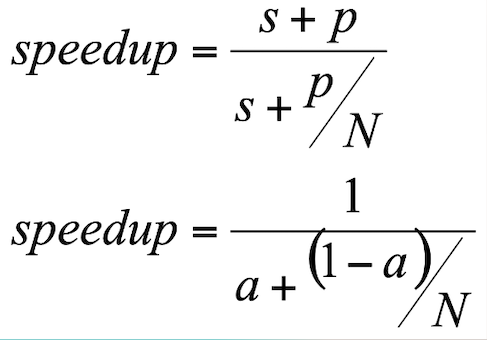
Define Gustafson’s Law and Give Formula
in a parallel program the quantity of data to be processed increase, so compared with the parallel part the sequential part decreases
*less constraints than the Amdahl law

Limitation of Amdahl and Gustafson Laws
define the limits without taking in account the properties of the computer
Define the three components of Bulk Synchronous Parallel (BSP)
Compute: components capable of computing or executing local memory transactions
Communication: a network routing messages between components
Synchronization: a support for synchronization on all or a sub-group of components
*each processor can access his own memory without overhead and have a uniform slow access to remote memory
Define Supersteps and Give Three Steps
a superstep is a sequence of operations that every processing unit in a distributed system executes as a part of a larger algorithm
applications are composed by supersteps separated by global synchronizations
Communication Step, Communication Step, Synchronization Step
Give Formula of Superstep
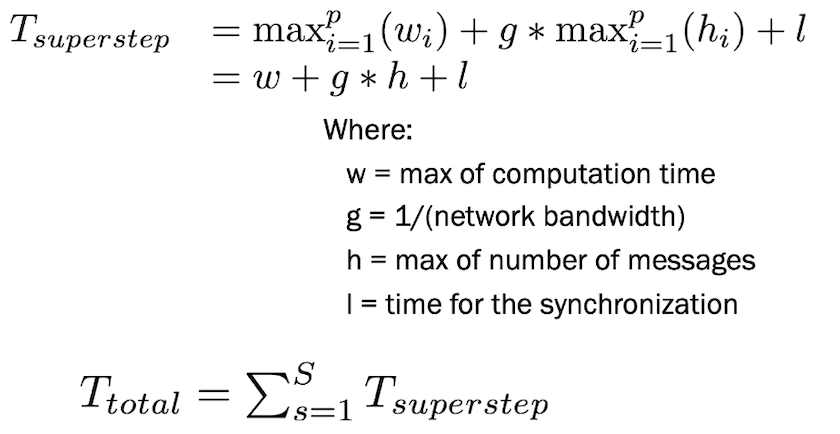
Define LogP Model and List it Four Components
a more realistic model in comparison to BSP with paying attention to realistic characteristics of parallel networks
L: latency of.communication
o: message overhead
g: gap between messages
P: number of processors
Define the Four Elements of the LogP Model
Latency: small message across the network
Overhead: lost time in communication
Gap: between two consecutive messages
P: the number of processors
Give Formula for LopP Superstep
Note: the total time for a message to go from processor A to processor B is L + 2 * o
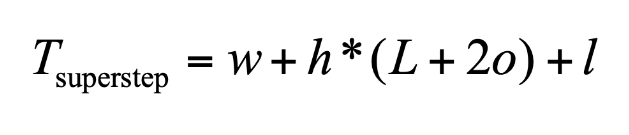
Define the CMM Model
transforms the BSP superstep framework to support high-level programming models
removes the requirement of global synchronization between supersteps, but combines the message exchanges and synchronization properties into the execution of a collective communication
Define Laplace’s Equation