Why Apache Hudi is a Must-Have for Data Lakehouses
1/37
Earn XP
Description and Tags
What is Open Table Formats. What is Apache Hudi and why it the best for data lakehouse. Differences between Apache Hudi, Apache Iceberg and Delta Lake. Written by albert wong (albert@onehouse.ai). Corrections and PRs can be submitted to https://github.com/alberttwong/notecards
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
38 Terms
What are Open Table Formats?
Data management frameworks like Apache Hudi, Apache Iceberg, and Delta Lake that enhance modern data architectures by providing ACID capabilities and other database features on the data lakes.
Story: Historically, data lakes were often managed like shared drives, where multiple teams could access and modify data. This approach frequently led to data overwrites and loss. To address these issues, strict controls were implemented, often limiting access to a single individual. However, this created data silos as different teams required their own copies of the data for various use cases. These silos necessitated additional pipelines to maintain data freshness, leading to increased complexity and potential data duplication. Data lakehouses offer a solution to these challenges by providing a centralized data repository with granular access controls and efficient data management capabilities. Open table formats provide the fundamental technology for data lakehouses.
Story: Initially, data lakes were primarily used as data archives due to their cost-effectiveness. However, as organizations began to recognize the limitations of traditional databases, which often bundled compute and storage, they sought a more flexible solution. This led to the concept of the data lakehouse. By separating compute and storage, data lakehouses allowed organizations to leverage the cost-efficiency of data lakes while maintaining the performance benefits of databases. Open table formats provide the fundamental technology for data lakehouses.
What are the Use Cases for each open table format?
Iceberg came from Netflix to support BI and dashboards. Designed for read heavy workloads (90% reads and 10% writes). Per https://tableformats.sundeck.io/, Tabular employs 36% of the committers and wrote about ~60% of the codebase.
Hudi came from Uber to store receipts. Designed for read heavy workloads (90% read and 10% writes via copy-on-write tables) and balanced read and write workloads (50% reads and 50% writes via merge-on-read tables). Per https://tableformats.sundeck.io/, Onehouse employs 19% of the committers and wrote about ~20% of the codebase.
Delta Lake came from databricks. Designed for for ai/ml and spark pipelines. Per https://tableformats.sundeck.io/, Databricks employs 100% of the committers and wrote about ~100% of the codebase.
So choose the right format for the workload and right "open".
What are Apache Hudi’s killer features?
The ability to support read heavy workloads AND insert/upserts and streaming updates workloads. The best features of iceberg (designed for read heavy workloads) and delta lake (read heavy and read/write/streaming workloads).
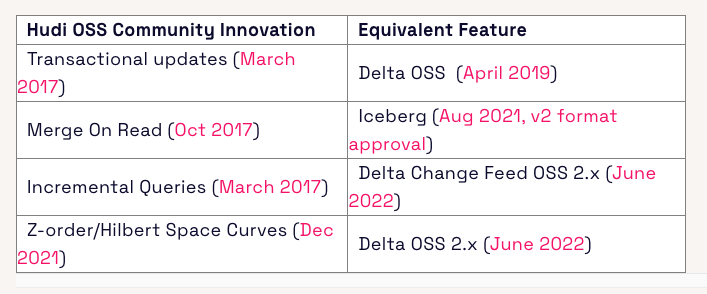
What are innovations that were introduced by the Hudi OSS Community?
Transactional updates, Merge On Read, Incremental Queries, Z-order/Hilbert Space Curves
Futures can be found at https://github.com/apache/hudi/tree/master/rfc
How is Hudi optimized for CDC and streaming use cases?
One of the core use-cases for Apache Hudi is enabling seamless, efficient database ingestion to your lake, and change data capture is a direct application of that. Hudi’s core design primitives support fast upserts and deletes of data that are suitable for CDC and streaming use cases. Here is a glimpse of some of the challenges accompanying streaming and cdc workloads that Hudi handles efficiently out of the box.
Processing of deletes: Deletes are treated no differently than updates and are logged with the same filegroups where the corresponding keys exist. This helps process deletes faster same like regular inserts and updates and Hudi processes deletes at file group level using compaction in MOR tables. This can be very expensive in other open source systems that store deletes as separate files than data files and incur N(Data files)*N(Delete files) merge cost to process deletes every time, soon lending into a complex graph problem to solve whose planning itself is expensive. This gets worse with volume, especially when dealing with CDC style workloads that streams changes to records frequently.
Operational overhead of merging deletes at scale: When deletes are stored as separate files without any notion of data locality, the merging of data and deletes can become a run away job that cannot complete in time due to various reasons (Spark retries, executor failure, OOM, etc.). As more data files and delete files are added, the merge becomes even more expensive and complex later on, making it hard to manage in practice causing operation overhead. Hudi removes this complexity from users by treating deletes similarly to any other write operation.
File sizing with updates: Other open source systems, process updates by generating new data files for inserting the new records after deletion, where both data files and delete files get introduced for every batch of updates. This yields to small file problem and requires file sizing. Whereas, Hudi embraces mutations to the data, and manages the table automatically by keeping file sizes in check without passing the burden of file sizing to users as manual maintenance.
Support for partial updates and payload ordering: Hudi support partial updates where already existing record can be updated for specific fields that are non null from newer records (with newer timestamps). Similarly, Hudi supports payload ordering with timestamp through specific payload implementation where late-arriving data with older timestamps will be ignored or dropped. Users can even implement custom logic and plug in to handle what they want.
Who are major users of Apache Hudi?
Case Study: Walmart
This is an article about Walmart’s migration to a Lakehouse architecture. It discusses the challenges of using a traditional Data Lake and the benefits of using a Lakehouse. The article also details Walmart’s evaluation of different Lakehouse technologies. Ultimately, Walmart chose Apache Hudi to power their Lakehouse. https://medium.com/walmartglobaltech/lakehouse-at-fortune-1-scale-480bcb10391b
Case Study: Notion
This is an article about Notion’s journey through different stages of data scale. It discusses the challenges they faced as their data grew and how they overcame them by adopting a universal data lakehouse architecture. The article also details the benefits of using Hudi, an open source data lakehouse engine. Some of the benefits that Notion experienced include cost savings, performance improvements, and the ability to enable new product features. https://www.onehouse.ai/blog/notions-journey-through-different-stages-of-data-scale
Case Study: Robinhood
This is an article about Robinhood's data lakehouse. It discusses what a data lakehouse is and Robinhood's use of Apache Hudi. The data lakehouse stores more than 50,000 datasets. It ingests data from various sources and makes it available to consumers for different use cases. To support the various use cases, Robinhood built a multi-tiered architecture. https://www.onehouse.ai/blog/scaling-and-governing-robinhoods-data-lakehouse
What is the Read and Write Efficiency of the various formats?
The effectiveness of data retrieval and storage processes in distributed systems, shaped by the architectures of the three technologies.
[Best] Hudi uses copy on write for read heavy workloads and merge on read for insert/upsert workloads. They store the main data file in parquet and the incremental data in avro. Compaction can be inline or async.
[Good] Iceberg uses copy-on-write with limited merge-on-read (delete/update/merge support). They store the main data file in parquet and the incremental data is not in an open format. Compaction is async only.
[Good] Delta uses copy-on-write with limited merge-on-read (delete support). They store the main data file in parquet and the incremental data is not in an open format. Compaction is async only.
What is copy-on-write table strategy mean?
Copy-on-write means that they pay the penalty of the write in the beginning to to get efficiency in the future. This serves read heavy workloads well.
What is merge-on-write table strategy mean?
Merge-on-write means that they each write is very small and fast. The bad is that there are a lot of writes and when you query, you have to look at multiple places. Table services comes in later and then “compacts” them back down to a single file. This serves mixed read and write (streaming) workloads well.
Tell me about merge on read support and history. Also compare it with iceberg and delta.
Apache Hudi has had merge on read since Oct 2017.
Delta Lake only recently supported merge on read with delete vectors in 2023. Iceberg supported merge on read with delete in Aug 2021. Both don’t really do “compaction” so insert/upsert performance will be bad.
How do you get Performance on the data lakehouse?
Insert, upsert, delete and query performance is related to how well table services are run on the raw table data. These services like compaction (for MOR tables only, merging updates), cleaning (reclaim storage), clustering (reorganizing data), metadata indexing (making looking up data files faster), file sizing (overcome small files problem) can lead to 3x to 10x improvement to all users of the data lakehouse.
Hudi provides all these features in the OSS version. Iceberg and Delta have only some but not all of these features.
What is table services and why are they important?
Databases often employ table services to optimize raw data for performance. This optimization occurs behind the scenes in vertically integrated database solutions like Snowflake or MySQL. However, when separating query engines from data storage, these optimization services must still be executed at the storage level.
Hudi offers features like compaction, clustering, and cleaning to enhance data performance and maintain data quality.
What does Data Versioning in the data lake mean?
The process of maintaining multiple versions of data.
This allows you to just see the latest data values or how the data values have changed over time.
What is the problem with traditional disk data storage solutions? Why s3 object store?
Conventional methods of storing data (block storage like aws ebs) face challenges in scalability, performance, and data management. When you provision a new node, you must shuffle (move/copy) data. Disk resizing may be needed as data grows and may have downtime. With object stores like s3, you don’t need to do any of of this since the node can boot up and point to the data and 1/10 the cost to store (comparing AWS EBS to AWS S3 costs).
What does Schema Evolution mean?
The ability to adapt the structure of data over time without disrupting existing data, a feature that differs across the three technologies.
This means that as the data schema changes over time, you can adopt these changes to your data model.
What does Transaction Management mean?
Hudi, Iceberg, and Delta Lake employ different mechanisms to guarantee data integrity and ACID properties during concurrent operations. This is crucial in data lakehouse environments where multiple applications simultaneously write data to the lake. To prevent data loss from overwrites, these platforms implement strategies that ensure consistent and reliable data management even under heavy workloads.
What does hudi compaction do?
Compaction is a table service employed by Hudi specifically in Merge On Read(MOR) tables to merge updates from row-based log files to the corresponding columnar-based base file periodically to produce a new version of the base file. Compaction is not applicable to Copy On Write(COW) tables and only applies to MOR tables.
What does hudi clustering do?
Short version: Clustering reorganizes data for improved query performance without compromising on ingestion speed.
Long version: Apache Hudi brings stream processing to big data, providing fresh data while being an order of magnitude efficient over traditional batch processing. In a data lake/warehouse, one of the key trade-offs is between ingestion speed and query performance. Data ingestion typically prefers small files to improve parallelism and make data available to queries as soon as possible. However, query performance degrades poorly with a lot of small files. Also, during ingestion, data is typically co-located based on arrival time. However, the query engines perform better when the data frequently queried is co-located together. Clustering reorganizes data for improved query performance without compromising on ingestion speed.
What does hudi cleaning do?
Cleaning is a table service employed by Hudi to reclaim space occupied by older versions of data and keep storage costs in check. Apache Hudi provides snapshot isolation between writers and readers by managing multiple versioned files with MVCC concurrency. These file versions provide history and enable time travel and rollbacks, but it is important to manage how much history you keep to balance your costs. Cleaning service plays a crucial role in manging the tradeoff between retaining long history of data and the associated storage costs.
Hudi enables Automatic Hudi cleaning by default. Cleaning is invoked immediately after each commit, to delete older file slices. It's recommended to leave this enabled to ensure metadata and data storage growth is bounded. Cleaner can also be scheduled after every few commits instead of after every commit by configuring hoodie.clean.max.commits.
Why are indexes important in Hudi?
So we put indexes on the data so that the reader or the writer can find the data faster.
Think of open table formats as the books in a page but you need a table of contents and glossary to get to the page you want or give you a smaller section of the book to look for that data. The index is the table of contents and glossary.
Technically, we provide uniqueness to each row and the index can either point to that row uniqueness or give a range to search.
What is rollback within Hudi?
Your pipelines could fail due to numerous reasons like crashes, valid bugs in the code, unavailability of any external third-party system (like a lock provider), or user could kill the job midway to change some properties. A well-designed system should detect such partially failed commits, ensure dirty data is not exposed to the queries, and clean them up. Hudi's rollback mechanism takes care of cleaning up such failed writes.
How does Hudi handle data quality?
Data quality refers to the overall accuracy, completeness, consistency, and validity of data. Ensuring data quality is vital for accurate analysis and reporting, as well as for compliance with regulations and maintaining trust in your organization's data infrastructure.
Hudi offers Pre-Commit Validators that allow you to ensure that your data meets certain data quality expectations as you are writing with Hudi Streamer or Spark Datasource writers.
What is incremental processing? Why does Hudi docs/talks keep talking about it?
Incremental processing was first introduced by Vinoth Chandar, in the O'reilly blog, that set off most of this effort. In purely technical terms, incremental processing merely refers to writing mini-batch programs in streaming processing style. Typical batch jobs consume all input and recompute all output, every few hours. Typical stream processing jobs consume some new input and recompute new/changes to output, continuously/every few seconds. While recomputing all output in batch fashion can be simpler, it's wasteful and resource expensive. Hudi brings ability to author the same batch pipelines in streaming fashion, run every few minutes.
While we can merely refer to this as stream processing, we call it incremental processing, to distinguish from purely stream processing pipelines built using Apache Flink or Apache Kafka Streams.
How does Hudi handle encryption.
Since Hudi 0.11.0, Spark 3.2 support has been added and accompanying that, Parquet 1.12 has been included, which brings encryption feature to Hudi.
This feature is currently only available for COW tables due to only Parquet base files present there.
Apache iceberg uses what data strategy for writing data into tables?
Copy on write.
Bonus: Only when you delete/update/merge data Iceberg supports merge-on-read. So when you have to insert data, you have all these small files that can negatively impact read performance. To prevent this, regular compaction is required to reconcile updates and deletes with existing data files.
Apache hudi uses what table strategy for writing data into tables?
Copy on Write and Merge on Read.
Delta lake uses what table strategy for writing data into tables?
Copy on Write.
Bonus: Only when you delete data Delta supports merge-on-read. In roadmap for update/merge. So when you have to insert data, it still uses copy on write.
What does acid mean for a database?
In database systems, the term "acid" refers to a set of properties that ensure data integrity and consistency in transactions. These properties are:
Atomicity: This means that a transaction is treated as a single unit. Either all parts of the transaction are executed successfully, or none of them are. If any part of the transaction fails, the entire transaction is rolled back to its original state. This prevents inconsistent data states.
Consistency: This ensures that the database remains in a consistent state before and after a transaction. The transaction must adhere to all defined constraints and rules of the database schema.
Isolation: This property guarantees that concurrent transactions do not interfere with each other. Each transaction operates as if it were the only one accessing the database. This prevents conflicts and ensures that each transaction sees a consistent view of the data.
Durability: Once a transaction is committed, its changes are made permanent and will not be lost, even in the event of a system failure. This ensures that data is reliable and recoverable.
These ACID properties are essential for maintaining the integrity and reliability of databases, especially in systems that handle critical data or perform complex transactions.
What is separation of compute and storage and why is it a benefit for users?
Separation of compute and storage refers to a database architecture where the processing of data (compute) is decoupled from the physical storage of data. This means that the database engine, responsible for executing queries and managing data, operates on a separate server or cluster from the storage system where the data is physically stored.
Benefits of Separation of Compute and Storage
Scalability:
Independent Scaling: Both compute and storage resources can be scaled independently based on demand. This allows for more granular resource allocation and avoids overprovisioning.
Horizontal Scaling: Compute resources can be easily scaled horizontally by adding more nodes to the cluster, while storage can be scaled by adding more storage devices or expanding existing storage systems.
Flexibility:
Choice of Hardware: Different hardware can be optimized for compute and storage tasks, leading to improved performance and cost-effectiveness.
Data Migration: Data can be easily migrated between different storage systems without affecting the database engine, providing flexibility in data management.
Cost-Efficiency:
Optimized Resource Allocation: By separating compute and storage, resources can be allocated more efficiently based on their specific requirements.
Pay-as-You-Go Models: Many cloud-based database services offer pay-as-you-go pricing models, allowing users to pay only for the resources they consume.
Resiliency:
Fault Tolerance: Failures in one component (compute or storage) do not necessarily impact the entire system. This improves overall resilience and availability.
Data Redundancy: Data can be replicated across multiple storage nodes to ensure durability and protect against data loss.
Performance:
Optimized Workloads: Compute and storage resources can be tailored to specific workloads, improving performance for different types of queries.
Parallel Processing: Data can be distributed across multiple storage nodes, enabling parallel processing and faster query execution.
How are open table formats and sql related?
Open table format is a data storage format but doesn't provide a built-in query interface. To interact with Open table format data using SQL queries, you'll need a compatible SQL query engine like Trino or Spark SQL. These engines are designed to understand Apache Hudi and can provide a SQL interface for querying Hudi data.
Why is writing (specifically inserting) data in storage not good enough to run a data lakehouse?
When writing in storage, different sizes of inserts, updates, delete operations create file and partition skews in the underlying storage. This results in uneven query performance.
By implementing techniques like clustering, compaction, and partitioning, we can improve read and write speeds. Think of this as "defragmenting" your data to enhance its organization and efficiency.*
how are open table formats and data catalogs like unity catalog related?
Imagine open table formats as the pages (data) in a book (data table). Just as you'd use a library catalog to find a specific book, a data catalog serves as a directory for locating data tables stored in open table formats.
Technically, it's a database that maps tables to one or more Parquet or Avro files.
How can open table formats work with ai and ml frameworks?
AI/ML frameworks are typically developed using programming languages. Apache Hudi, a data management platform, offers language-specific libraries to facilitate interaction with Hudi data from various programming environments.
What does Apache xtable give in terms of features to the open table formats?
Apache xtable acts as a cross-table converter, facilitating interoperability between different lakehouse table formats like Apache Hudi, Apache Iceberg, and Delta Lake. With Apache xtable, you have a data lakehouse that can support heavy read workloads (iceberg), heavy read and read/write/streaming workloads (hudi) and ai/ml workloads (delta lake) by having all 3 formats supported and exposed to users.
How is open table formats and onehouse related?
Onehouse provides a managed data lakehouse that focuses on data ingestion to the data lakehouse, serving and storing data in apache hudi/iceberg/delta lake format and day 0, day 1, and day 2 operations of managing the data lakehouse.
Is Hudi an analytical database?
A typical database has a bunch of long running storage servers always running, which takes writes and reads. Hudi's architecture is very different and for good reasons. It's highly decoupled where writes and queries/reads can be scaled independently to be able to handle the scale challenges. So, it may not always seems like a database.
Nonetheless, Hudi is designed very much like a database and provides similar functionality (upserts, change capture) and semantics (transactional writes, snapshot isolated reads).
What are some non-goals for Hudi?
Hudi is not designed for any OLTP use-cases, where typically you are using existing NoSQL/RDBMS data stores. Hudi cannot replace your in-memory analytical database (at-least not yet!). Hudi support near-real time ingestion in the order of few minutes, trading off latency for efficient batching. If you truly desirable sub-minute processing delays, then stick with your favorite stream processing solution.
What do we recommend for a solid data strategy?
Adopt Open Data Formats
Use formats such as Apache Parquet and Apache Avro
Ensure capability across various tools and patterns
Keep your Query Engine Choices Open
Avoid restrictions and lock-in
Support all use cases
Adopt Open Source Data Table Formats
Use Apache Hudi, Apache Iceberg or Delta Lake
Take advantage of Apache xTable for interoperability
Ensure Multi-Catalog Integration
Integrates with all popular data catalogs
Complements open data table formats and services as used in Onehouse and other solutions