Looks like no one added any tags here yet for you.
TPT Ltd. decides to migrate its on-premise data infrastructure to the cloud especially for high availability of cloud services and to lower the high costs of storing data on-premise. The infrastructure uses HDFS to store data which can be processed and transformed using Apache Hive and Spark. The company wants to migrate the infrastructure but DevOps team still wants to administrate the infrastructure in the cloud. Which of the following approach should be recommended in this case?
Use Dataproc to process the data. Store data in Google Storage.
TPT Ltd. is a video-on-demand company plans to generate subtitles for its content on the web. With over 20,000 hours of content to be subtitled, their current subtitle team cannot match up with the every-growing video hours that the content team keep adding to the website library. The company is looking for a solution to automate this process since manpower recruitment can be expensive and may take a longer period of time. Choose the best alternative from the following that can help in the automation of video subtitles.
Cloud Speech-to-Text.
Which keyword is used in BigQuery standard SQL when selecting from multiple tables with wildcard by their suffices?
_TABLE_SUFFIX
TPT Ltd. is a dairy products company . The company monitors its employees activities and detect any intruders using their sensors which are installed around different areas in their farms. They use Apache Kafka cluster to gather the events coming from sensors. The Kafka cluster is becoming a bottleneck causing lag in receiving sensor events. It turns out that the sensors are sending more frequent events. Also, with the company expanding more farms, various sensors are being installed thereby causing extra load on the cluster. Which of the following is the most suitable approach to solve this issue?
Use pub/sub to ingest and stream sensor events.
TPT Ltd. is an online learning platform company that plans to generate captions for its videos. The learning platform offers around 2,500 courses with topics related to business, finance, cooking, development and science. Also the platform offers content with different languages such as French, German, Turkish and Thai. This probably can be very challenging for a single team to caption all the available courses. In which case, the company is looking for an approach to meet the requirement and handle the job appropriately. Which of the following Google Cloud products should be used in this case?
Cloud Speech-to-Text.
TPT Ltd. plans to move its data center from its on-premise servers to the cloud. It has been estimated that the company has about 2 Petabytes of data to be moved. The security team is very concerned about the data that needs to be migrated securely. Also, the project manager has a timeline of 6 months for the completion of all migration. Choose the best possible approach that must be used to perform this task.
Appliance Transfer Service.
Rick has a dataflow pipeline which reads a CSV file daily at 6 AM. He applies the necessary cleansing and transformation on it, and then loads it to BigQuery. But due to incomplete data or human error the CSV file might be modified within the day. Due to which he has to manually re-run dataflow pipeline again. Which of the following options should he use to fix the issue by automatically re-running the pipeline, if the file has been modified?
Use Cloud Composer to rerun dataflow and reprocess the file. Create a custom sensor to detect file condition if changed.
TPT Ltd. a coach line bus service company wants to forecast how many passengers they expect to book for tickets on their buses for the upcoming months. This helps the company to understand various factors like how many buses are needed to be in service for maintenance, fuel required and the number of drivers to be available. Since 1968, the company has records of all the booked tickets and allows private sharing of this data for the prediction process. Mike has been asked to build the machine learning model for TPT Ltd. Which of the following techniques he must use to predict the number of passengers?
Regression.
TPT Ltd. plans to migrate its current infrastructure from on-premise to Google cloud. It stores over 280 TB of data on its on-premise HDFS servers. The company plans to move data from HDFS to Google Storage in a secure and efficient manner. Which of the following approach is recommend to meet the requirement?
Use Transfer Appliance Service to migrate the data to Google Storage.
TPT Ltd. is an MNC having multiple Google Storage buckets in different regions all across the world. Such that each branch has its own set of buckets in the region nearest to them to avoid latencies. However this has resulted in a big challenge for the analytics team to reach and do the necessary reports on the data using BigQuery, as they need to create the tables in the same region either to import the data or create external tables to access the data in different regions. Now the head of data management team has decided to sync data daily from different Google Storage buckets scattered in different regions to a single multi-regional bucket to do the required data analysis and reporting. Which of the following service could help to met the requirement?
Storage Transfer Service
You are designing storage for event data as part of building a data pipeline on Google Cloud. Your input data is in CSV format. You want to minimize the cost of querying individual values over time windows. Which storage service and schema design should you use?
Use Cloud Bigtable for storage. Design tall and narrow tables, and use a new row for each single event version.
You are building storage for files for a data pipeline on Google Cloud. You want to support JSON files. The schema of these files will occasionally change. Your analyst teams will use running aggregate ANSI SQL queries on this data. What should you do?
Use BigQuery for storage. Select "Automatically detect" in the Schema section.
You use a Hadoop cluster both for serving analytics and for processing and transforming data. The data is currently stored on HDFS in Parquet format. The data processing jobs run for 6 hours each night. Analytics users can access the system 24 hours a day. Phase 1 is to quickly migrate the entire Hadoop environment without a major re-architecture. Phase 2 will include migrating to BigQuery for analytics and to Dataflow for data processing. You want to make the future migration to BigQuery and Dataflow easier by following Google-recommended practices and managed services. What should you do?
Create separate Dataproc clusters to support analytics and data processing, and point both at the same Cloud Storage bucket that contains the Parquet files that were previously stored on HDFS.
You are building a new real-time data warehouse for your company and will use BigQuery streaming inserts. There is no guarantee that data will only be sent in once but you do have a unique ID for each row of data and an event timestamp. You want to ensure that duplicates are not included while interactively querying data. Which query type should you use?
Use the ROW_NUMBER window function with PARTITION by unique ID along with WHERE row equals 1.
You are designing a streaming pipeline for ingesting player interaction data for a mobile game. You want the pipeline to handle out-of-order data delayed up to 15 minutes on a per-player basis and exponential growth in global users. What should you do?
Design a Dataflow streaming pipeline with session windowing and a minimum gap duration of 15 minutes. Use "individual player" as the key. Use Pub/Sub as a message bus for ingestion.
Your company is loading CSV files into BigQuery. The data is fully imported successfully; however, the imported data is not matching byte-to-byte to the source file. What is the most likely cause of this problem?
The CSV data loaded in BigQuery is not using BigQuery's default encoding.
Your company is migrating their 30-node Apache Hadoop cluster to the cloud. They want to re-use Hadoop jobs they have already created and minimize the management of the cluster as much as possible. They also want to be able to persist data beyond the life of the cluster. What should you do?
Create a Dataproc cluster that uses the Cloud Storage connector.
You have 250,000 devices which produce a JSON device status event every 10 seconds. You want to capture this event data for outlier time series analysis. What should you do?
Ship the data into Cloud Bigtable. Use the Cloud Bigtable cbt tool to display device outlier data based on your business requirements.
You are selecting a messaging service for log messages that must include final result message ordering as part of building a data pipeline on Google Cloud. You want to stream input for 5 days and be able to query the current status. You will be storing the data in a searchable repository. How should you set up the input messages?
Use Pub/Sub for input. Attach a timestamp to every message in the publisher.
You want to publish system metrics to Google Cloud from a large number of on-prem hypervisors and VMs for analysis and creation of dashboards. You have an existing custom monitoring agent deployed to all the hypervisors and your on-prem metrics system is unable to handle the load. You want to design a system that can collect and store metrics at scale. You don't want to manage your own time series database. Metrics from all agents should be written to the same table but agents must not have permission to modify or read data written by other agents. What should you do?
Modify the monitoring agent to publish protobuf messages to Pub/Sub. Use a Dataproc cluster or Dataflow job to consume messages from Pub/Sub and write to BigTable.
You are designing storage for CSV files and using an I/O-intensive custom Apache Spark transform as part of deploying a data pipeline on Google Cloud. You intend to use ANSI SQL to run queries for your analysts. How should you transform the input data?
Use BigQuery for storage. Use Dataproc to run the transformations.
You are designing a relational data repository on Google Cloud to grow as needed. The data will be transactionally consistent and added from any location in the world. You want to monitor and adjust node count for input traffic, which can spike unpredictably. What should you do?
Use Cloud Spanner for storage. Monitor CPU utilization and increase node count if more than 70% utilized for your time span.
You have a Spark application that writes data to Cloud Storage in Parquet format. You scheduled the application to run daily using DataProcSparkOperator and Apache Airflow DAG by Cloud Composer. You want to add tasks to the DAG to make the data available to BigQuery users. You want to maximize query speed and configure partitioning and clustering on the table. What should you do?
Use "GoogleCloudStorageToBigQueryOperator" with "schema_object" pointing to a schema JSON in Cloud Storage and "source_format" set to "PARQUET".
You have a website that tracks page visits for each user and then creates a Pub/Sub message with the session ID and URL of the page. You want to create a Dataflow pipeline that sums the total number of pages visited by each user and writes the result to BigQuery. User sessions timeout after 30 minutes. Which type of Dataflow window should you choose?
Session-based windows with a gap duration of 30 minutes
You are designing a basket abandonment system for an ecommerce company. The system will send a message to a user based on these rules: a). No interaction by the user on the site for 1 hour b). Has added more than $30 worth of products to the basket c). Has not completed a transaction. You use Dataflow to process the data and decide if a message should be sent. How should you design the pipeline?
Use a session window with a gap time duration of 60 minutes.
You need to stream time-series data in Avro format, and then write this to both BigQuery and Cloud Bigtable simultaneously using Dataflow. You want to achieve minimal end-to-end latency. Your business requirements state this needs to be completed as quickly as possible. What should you do?
Create a pipeline that groups data using a PCollection and then uses Bigtable and BigQueryIO transforms.
Your company's on-premises Apache Hadoop servers are approaching end-of-life, and IT has decided to migrate the cluster to Dataproc. A like-for-like migration of the cluster would require 50 TB of Google Persistent Disk per node. The CIO is concerned about the cost of using that much block storage. You want to minimize the storage cost of the migration. What should you do?
Put the data into Cloud Storage.
You are designing storage for two relational tables that are part of a 10-TB database on Google Cloud. You want to support transactions that scale horizontally. You also want to optimize data for range queries on non-key columns. What should you do?
Use Cloud Spanner for storage. Add secondary indexes to support query patterns.
Your company is streaming real-time sensor data from their factory floor into Bigtable and they have noticed extremely poor performance. How should the row key be redesigned to improve Bigtable performance on queries that populate real-time dashboards?
Use a row key of the form
You are developing an application on Google Cloud that will automatically generate subject labels for users' blog posts. You are under competitive pressure to add this feature quickly, and you have no additional developer resources. No one on your team has experience with machine learning. What should you do?
Call the Cloud Natural Language API from your application. Process the generated Entity Analysis as labels.
Your company is using WILDCARD tables to query data across multiple tables with similar names. The SQL statement is currently failing with the error shown below. Which table name will make the SQL statement work correctly?
`bigquery-public-data.noaa_gsod.gsod*`
You are working on an ML-based application that will transcribe conversations between manufacturing workers. These conversations are in English and between 30-40 sec long. Conversation recordings come from old enterprise radio sets that have a low sampling rate of 8000 Hz, but you have a large dataset of these recorded conversations with their transcriptions. You want to follow Google-recommended practices. How should you proceed with building your application?
Use Cloud Speech-to-Text API, and send requests in a synchronous mode.
You are developing an application on Google Cloud that will label famous landmarks in users' photos. You are under competitive pressure to develop a predictive model quickly. You need to keep service costs low. What should you do?
Build an application that calls the Cloud Vision API. Pass landmark location as base64-encoded strings.
You are building a data pipeline on Google Cloud. You need to select services that will host a deep neural network machine-learning model also hosted on Google Cloud. You also need to monitor and run jobs that could occasionally fail. What should you do?
Use AI Platform Prediction to host your model. Monitor the status of the Jobs object for 'failed' job states.
You work on a regression problem in a natural language processing domain, and you have 100M labeled examples in your dataset. You have randomly shuffled your data and split your dataset into training and test samples (in a 90/10 ratio). After you have trained the neural network and evaluated your model on a test set, you discover that the root-mean-squared error (RMSE) of your model is twice as high on the train set as on the test set. How should you improve the performance of your model?
Increase the complexity of your model by, e.g., introducing an additional layer or increasing the size of vocabularies or n-grams used to avoid underfitting.
You are using Pub/Sub to stream inventory updates from many point-of-sale (POS) terminals into BigQuery. Each update event has the following information: product identifier "prodSku", change increment "quantityDelta", POS identification "termId", and "messageId" which is created for each push attempt from the terminal. During a network outage, you discovered that duplicated messages were sent, causing the inventory system to over-count the changes. You determine that the terminal application has design problems and may send the same event more than once during push retries. You want to ensure that the inventory update is accurate. What should you do?
Add another attribute orderId to the message payload to mark the unique check-out order across all terminals. Make sure that messages whose "orderId" and "prodSku" values match corresponding rows in the BigQuery table are discarded.
You designed a database for patient records as a pilot project to cover a few hundred patients in three clinics. Your design used a single database table to represent all patients and their visits, and you used self-joins to generate reports. The server resource utilization was at 50%. Since then, the scope of the project has expanded. The database table must now store 100 times more patient records. You can no longer run the reports, because they either take too long or they encounter errors with insufficient compute resources. How should you adjust the database design?
Normalize the master patient-record table into the patients table and the visits table, and create other necessary tables to avoid self-join.
Your startup has never implemented a formal security policy. Currently, everyone in the company has access to the datasets stored in BigQuery. Teams have the freedom to use the service as they see fit, and they have not documented their use cases. You have been asked to secure the data warehouse. You need to discover what everyone is doing. What should you do first?
Use Cloud Audit Logs to review data access.
You created a job which runs daily to import highly sensitive data from an on-premises location to Cloud Storage. You also set up a streaming data insert into Cloud Storage via a Kafka node that is running on a Compute Engine instance. You need to encrypt the data at rest and supply your own encryption key. Your key should not be stored in the Google Cloud. What should you do?
Supply your own encryption key, and reference it as part of your API service calls to encrypt your data in Cloud Storage and your Kafka node hosted on Compute Engine.
You are working on a project with two compliance requirements. The first requirement states that your developers should be able to see the Google Cloud billing charges for only their own projects. The second requirement states that your finance team members can set budgets and view the current charges for all projects in the organization. The finance team should not be able to view the project contents. You want to set permissions. What should you do?
Add the finance team members to the Billing Administrator role for each of the billing accounts that they need to manage. Add the developers to the Viewer role for the Project.
Host a deep neural network machine learning model on Google Cloud. Run and monitor jobs that could occasionally fail.
Use AI Platform to host your model. Monitor the status of the Jobs object for 'failed' job states.
Event data in CSV format to be queried for individual values over time windows. Which storage and schema to minimize query costs?
Use Cloud Bigtable. Design tall and narrow tables, and use a new row for each single event version.
Source data is streamed in bursts and must be transformed before use.
Use Pub/Sub to buffer the data, and then use Dataflow for ETL.
Calculate a running average on streaming data that can arrive late and out of order.
Use Pub/Sub and Dataflow with Sliding Time Windows.
Cost-effective backup to Google Cloud of multi-TB databases from another cloud including monthly DR drills.
Use Storage Transfer Service. Transfer to Cloud Storage Nearline bucket.
Promote a Cloud Bigtable solution with a lot of data from development to production and optimize for performance.
Change your Cloud Bigtable instance type from Development to Production, and set the number of nodes to at least 3. Verify that the storage type is SSD.
Three Google Cloud services commonly used together in data engineering solutions.
Pub/Sub, Dataflow, BigQuery
Low-cost one-way one-time migration of two 100-TB file servers to Google Cloud; data will be frequently accessed and only from Germany.
Use Transfer Appliance. Transfer to a Cloud Storage Standard bucket.
A company has migrated their Hadoop cluster to the cloud and is now using Dataproc with the same settings and same methods as in the data center. What would you advise them to do to make better use of the cloud environment?
Store persistent data off-cluster. Start a cluster for one kind of work then shut it down when it is not processing data.
Testing a Machine Learning model with validation data returns 100% correct answers.
The model is overfit. There is a problem.
A company wants to connect cloud applications to an Oracle database in its data center. Requirements are a maximum of 9 Gbps of data and a Service Level Agreement (SLA) of 99%.
Partner Interconnect
A client is using Cloud SQL database to serve infrequently changing lookup tables that host data used by applications. The applications will not modify the tables. As they expand into other geographic regions they want to ensure good performance. What do you recommend?
Read replicas
A Data Analyst is concerned that a BigQuery query could be too expensive.
Use the SELECT clause to limit the amount of data in the query. Partition data by date so the query can be more focused.
250,000 devices produce a JSON device status every 10 seconds. How do you capture event data for outlier time series analysis?
Capture data in Cloud Bigtable. Use the Cloud Bigtable cbt tool to display device outlier data.
You want to minimize costs to run Google Data Studio reports on BigQuery queries by using prefetch caching.
Set up the report to use the Owner's credentials to access the underlying data in BigQuery, and verify that the 'Enable cache' checkbox is selected for the report.
As part of your backup plan, you want to be able to restore snapshots of Compute Engine instances using the fewest steps.
Use the snapshots to create replacement instances as needed.
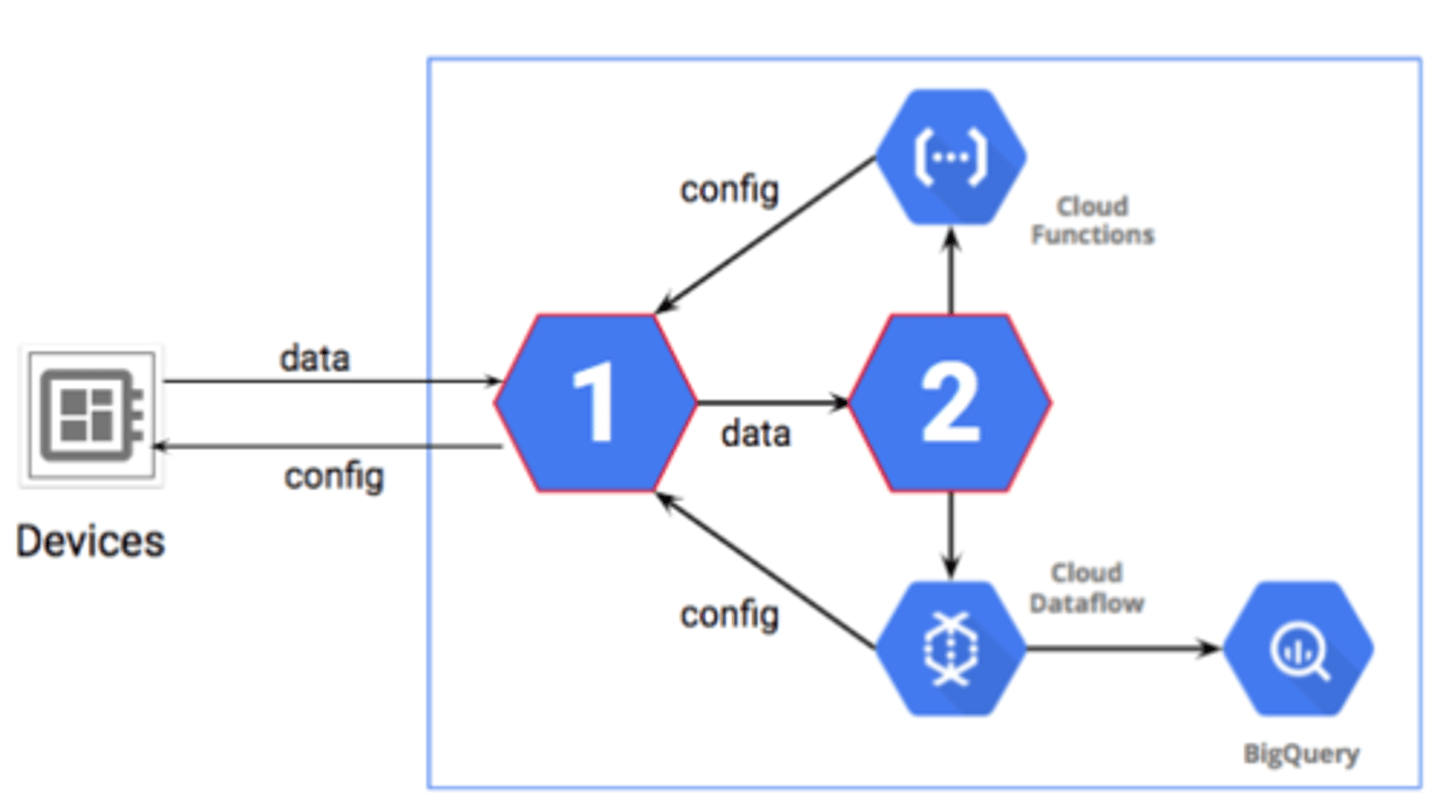
A company has a new IoT pipeline. Which services will make this design work? Select the services that should be used to replace the icons with the number "1" and number "2" in the diagram.
IoT Core, Pub/Sub
An application has the following data requirements. 1. It requires strongly consistent transactions. 2. Total data will be less than 500 GB. 3. The data does not need to be streaming or real time. Which data technology would fit these requirements?
Cloud SQL
Cost-effective way to run non-critical Apache Spark jobs on Dataproc?
Set up a cluster in standard mode with high-memory machine types. Add 10 additional preemptible worker nodes.
Customer wants to maintain investment in an existing Apache Spark code data pipeline.
Dataproc
What is AVRO used for?
Serialization and de-serialization of data so that it can be transmitted and stored while maintaining an object structure.
Storage of JSON files with occasionally changing schema, for ANSI SQL queries.
Store in BigQuery. Select "Automatically detect" in the Schema section.
A client wants to store files from one location and retrieve them from another location. Security requirements are that no one should be able to access the contents of the file while it is hosted in the cloud. What is the best option?
Client-side encryption
BigQuery data is stored in external CSV files in Cloud Storage; as the data has increased, the query performance has dropped.
Import the data into BigQuery for better performance.
A client has been developing a pipeline based on PCollections using local programming techniques and is ready to scale up to production. What should they do?
They should use the Dataflow Cloud Runner.